ELK日志监控系统搭建
ELK日志监控系统搭建
一、安装Elasticsearch: https://es.xiaoleilu.com/index.html
1、下载elasticsearch安装文件,官网下载地址:https://www.elastic.co/cn/downloads
2、解压elasticsearch压缩包至目录/opt/apps/elasticsearch
3、elasticsearch用root账户运行会报错,因此创建账号elastic
groupadd elastic
useradd –g elastic elastic
chown –R elastic /opt/apps/elasticsearch
chgrp –R elastic /opt/apps/elasticsearch
3、Elasticsearch运行依赖java,如果未安装jre,需要安装jre
4、系统配置修改:
4.1、vim /etc/sysctl.conf, 添加如下配置: vm.max_map_count=655360 并执行命令:sysctl –p
4.2、 vim /etc/security/limits.conf, 添加如下配置:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
5、启动elasticsearch: 记得不要用root账号启动, /opt/apps/elasticsearch/elasticsearch/bin/elasticsearch &
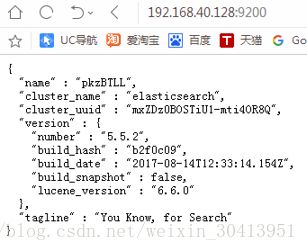
6、启动成功之后可以访问http://192.168.40.128:9200/,如果显示如下内容,这说明es启动成功,如果没有,请根据es启动日志寻找错误
完整配置文件:
Master:
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ———————————- Cluster ———————————–
#
# Use a descriptive name for your cluster:
#
cluster.name: prj-logcollection
#
# ———————————— Node ————————————
#
# Use a descriptive name for the node:
#
node.name: es-node1
#
# Add custom attributes to the node:
#
node.attr.rack: r1
node.master: true
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
path.logs: /opt/apps/elasticsearch/elasticsearch-run.logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 192.168.3.16
#
# Set a custom port for HTTP:
#
http.port: 9200
#
# 设置节点之间交互的tcp端口,默认是9300
transport.tcp.port: 9300
http.enabled: true
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.zen.ping.unicast.hosts: ["192.168.3.18"] #slave
#
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1):
#
discovery.zen.minimum_master_nodes: 1
#discovery.zen.ping.multicast.enabled: true
#
# For more information, consult the zen discovery module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
#
http.cors.enabled: true
http.cors.allow-origin: "*"
#index.number_of_shards: 8
#index.number_of_replicas: 2
#-----------------------------------------------------------------------------------------------
slave:
# ----------------------------------- Paths ------------------------------------
# Path to log files:
path.logs: /opt/apps/elasticsearch/elasticsearch-run.logs
# ----------------------------------- Memory -----------------------------------
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 192.168.3.18
#
# Set a custom port for HTTP:
#
http.port: 9200
# 设置节点之间交互的tcp端口,默认是9300
transport.tcp.port: 9300
http.enabled: true
# --------------------------------- Discovery ----------------------------------
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
discovery.zen.ping.unicast.hosts: ["192.168.3.18"]
discovery.zen.minimum_master_nodes: 1
http.cors.enabled: true
http.cors.allow-origin: "*"
二、安装Logstash: https://kibana.logstash.es/content/logstash/
1、在需要采集日志的server上安装logstash(tar.gz),官网下载地址:https://www.elastic.co/cn/downloads
2、解压logstash压缩包至目录/opt/apps/logstash
3、Logstash运行依赖java,如果未安装jre,需要安装jre
4、修改logstash配置文件 vim /opt/apps/logstash/config/logstash.yml
node.name: logstash-node-1 //踩过的雷,ELK的配置文件中“:”后面需要空一格
保存并退出
5、根据需要匹配的日志格式新建自定义patterns
Patterns定义好之后开始配置启动配置文件:vim /opt/apps/logstash/config/logstash-ebk.config
这里需要定义三个部分: input(指定日志源) filter(定义匹配规则,和过滤处理日志数据), output(指定输出地方)
配置如下
input {
file {
path => "/home/jack/logs/log.*"
type => "error_log"
start_position => "beginning"
codec => multiline {
pattern => “^\d{2}:\d{1,2}:\d{1,2}\.\d{1,4}“ //用于匹配头部,合并被冲散的日志
negate => true
what => "previous"
}
}
//filebeat
beats {
port => "5044"
}
}
filter {
if [type] == "RPOD_EBK_LOG" {
grok {
patterns_dir => "/opt/apps/logstash/config/self_patterns"
match => {
"message" => "%{STIME:timestamp}\s{1}%{SUER:user}\s{1}%{SLOGLEVEL:loglevel}\s{1,3}%{SCLASS:class}\s{1,3}-\s{1}%{SMESSAGE:msg}"
}
}
}
if [type] == "ACCESS_LOG" {
grok {
patterns_dir => "/opt/apps/logstash/config/self_patterns"
match => {
"message" => "%{SWIP:remoteIp}\s{1,3}%{SANAME:loginNick}\s{1,3}%{SATIME:timestamp}\s{1,3}%{SAMSG:msg}\s{1,3}%{SNUMUMBER:responseCode}\s{1,3}%{SNUMUMBER:dataSize}"
}
}
mutate {
split => ["remoteIp",","]
add_field => {
"client_ip" => "%{[remoteIp][0]}"
}
remove_field => ["remoteIp"]
add_field => {
"remote_ip" => "%{[client_ip]}"
}
remove_field => ["client_ip"]
}
mutate {
remove_field => ["message"]
gsub => ["timestamp","\[",""]
gsub => ["timestamp","\]",""]
}
date {
match => ["timestamp","dd/MMM/YYYY:HH:mm:ss Z"]
target => "@timestamp"
}
#geopoint{
# source => "remote_ip"
#}
geoip {
source => "remote_ip"
}
mutate {
split => ["msg"," "]
add_field => {
"method" => "%{[msg][0]}"
}
add_field => {
"requesturltemp" => "%{[msg][1]}"
}
# remove_field => ["msg"]
}
mutate {
split => ["requesturltemp","?"]
add_field => {
"requesturl" => "%{[requesturltemp][0]}"
}
add_field => {
"params" => "%{[requesturltemp][1]}"
}
remove_field => ["requesturltemp"]
}
}
}
output {
if [type] == "ERROR_LOG" {
if "ERROR" in [loglevel] {
elasticsearch {
hosts => ["192.168.3.175:9200"] //es master 地址
index => "prod-ebk-info-%{+YYYY.MM.dd}" //index不能有大写字母
document_type => "%{type}"
flush_size => 500
idle_flush_time => 150
sniffing => true
template => "/opt/apps/logstash/config/logstash-template.json"
template_overwrite => true
}
}
}
if [type] == "ACCESS_LOG" {
if [tags] and "_grokparsefailure" in [tags] {
#DO NOTHING
} else {
elasticsearch {
hosts => ["192.168.3.175:9200"]
index => "access-%{+YYYY.MM.dd}"
document_type => "%{type}"
flush_size => 500
idle_flush_time => 300
sniffing => true
template => "/opt/apps/logstash/config/logstash-template.json"
template_overwrite => true
}
}
}
}
三、安装filebeat
过程与logstash安装过程一样,此处省略,安装包在elastic官方网站上可以找到;以下是配置文件
filebeat:
spool_size: 1024 # 最大可以攒够 1024 条数据一起发送出去 此处设置需根据服务实际log数量设置,设置不当会给服务器带来额外负载
idle_timeout: "10s" # 否则每n 秒钟也得发送一次
registry_file: ".filebeat" # 文件读取位置记录文件,会放在当前工作目录下。所以如果你换一个工作目录执行 filebeat 会导致重复传输!
prospectors:
- input_type: log # 输入类型log
paths: # 监控日志路径
- /home/jack/prj/logs/prj.*
- /home/admin/prj/.default/logs/prj1.*
include_lines: ["\\s\\S*ERROR"]
exclude_files: ["\\s\\S*INFO"]
ignore_older: "5m"
scan_frequency: "6000s"
backoff: "19s"
tail_files: false
harvester_buffer_size: 16384
document_type: RPOD_LOG
multiline.pattern: ^\d{2}:\d{1,2}:\d{1,2}\.\d{1,4}
multiline.negate: true
multiline.match: before
- input_type: log
paths:
- /home/jack/prj/.default/logs/localhost_access_log.*
ignore_older: "5m"
scan_frequency: "6000s"
backoff: "19s"
tail_files: false
harvester_buffer_size: 16384
#log开头正则匹配
multiline.pattern: ^(25[0-5]|2[0-4][0-9]|[0-1]{1}[0-9]{2}|[1-9]{1}[0-9]{1}|[1-9])\.(25[0-5]|2[0-4][0-9]|[0-1]{1}[0-9]{2}|[1-9]{1}[0-9]{1}|[1-9]|0)\.(25[0-5]|2[0-4][0-9]|[0-1]{1}[0-9]{2}|[1-9]{1}[0-9]{1}|[1-9]|0)\.(25[0-5]|2[0-4][0-9]|[0-1]{1}[0-9]{2}|[1-9]{1}[0-9]{1}|[0-9])
multiline.negate: true
multiline.match: before
document_type: PROD_ACCESS_LOG
# Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme"
output.logstash:
# The Logstash hosts
hosts: ["192.168.16.15:5044"]
#worker: 1
#loadbalance: true
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
四、 Kibana安装 文档地址: https://kibana.logstash.es/content/kibana/
1、下载Kibana安装文件,官网下载地址:https://www.elastic.co/cn/downloads
2、解压Kibana压缩包至目录/opt/apps/kibana
3、修改kibana配置文件,vim /opt/apps/kibana/config/kibana.yml
server.host: “192.168.40.128“
elasticsearch.url: http://192.168.40.128:9200
kibana.index: “.kibana“
4、启动kibana:/opt/apps/kibana/bin/kibana &
5、启动成功之后,在浏览器访问:http://192.168.40.128:5601
五、启动
**es启动顺序,slave-->master 脚本:**
#!/bin/sh
nohup ./bin/elasticsearch > ./elasticsearch.log >/dev/null 2>&1 &
**es停止脚本:**
pid=`ps -ef|grep elasticsearch | grep -v "$0" | grep -v "grep" | awk '{print $2}'`
echo $pid
kill -9 $pid
**filebeat启动脚本:**
#!/bin/sh
nohup ./filebeat -c filebeat.yml -e >/dev/null 2>&1 &
**filebeat停止脚本:**
#! /bin/sh
pid=`ps -ef|grep filebeat | grep -v "$0" | grep -v "grep" | awk '{print $2}'`
echo $pid
kill -9 $pid
**logstash启动脚本**
#!/bin/sh
nohup ./bin/logstash -f ./config/logstash_log.config >/dev/null 2>&1 &
**kibana启动脚本**
#!/bin/sh
nohup ./bin/kibana > ./kibana.log 2>&1 &
**kibana停止脚本**
#! /bin/sh
pid=`fuser -n tcp 5601| grep -v "$0" | grep -v "grep" | awk '{print $0}'`
echo $pid
kill -9 $pid
六、Kibana使用高德地图
修改配置
1. 编辑kibana配置文件kibana.yml,最后面添加
tilemap.url: ‘http://webrd02.is.autonavi.com/appmaptile?lang=zh_cn&size=1&scale=1&style=7&x={x}&y={y}&z={z}’
2. 在logstash服务器下载IP地址归类查询库
wget http://geolite.maxmind.com/download/geoip/database/GeoLite2-City.mmdb.gz & gunzip GeoLite2-City.mmdb.gz
3. 编辑logstash配置文件
filter {
geoip {
source => “message”
target => “geoip”
database => “/usr/local/logstash-5.1.1/config/GeoLite2-City.mmdb”
add_field => [“[geoip][coordinates]”,”%{[geoip][longitude]}”]
add_field => [“[geoip][coordinates]”,”%{[geoip][latitude]}”]
}
}
• geoip: IP查询插件
• source: 需要通过geoip插件处理的field,一般为ip,这里因为通过控制台手动输入的是ip所以直接填message,生成环境中如果查询nginx访问用户,需先将客户端ip过滤出来,然后这里填clientip即可
• target: 解析后的Geoip地址数据,应该存放在哪一个字段中,默认是geoip这个字段
• database: 指定下载的数据库文件
• add_field: 这里两行是添加经纬度,地图中地区显示是根据经纬度来识别