基于 Flink、ClickHouse 的舆情分析系统:系统架构设计说明书
文章目录
-
-
- 1. 引言
-
- 1.1 编写目的
- 1.2 项目信息
- 1.3 项目背景
- 1.4 阅读对象
- 1.5 术语与缩略语
- 1.6 参考资料
- 2. 范围
-
- 2.1 软件名称
- 2.2 软件功能
- 3. 总体设计
-
- 3.1 架构设计目标和约束
-
- 3.1.1 架构设计目标
- 3.1.2 开发环境
- 3.2 系统架构设计
- 3.3 系统流程
- 3.4 系统模块划分与模块接口
-
- 3.4.1 模块描述
- 3.4.2 模块接口设计
- 4. 运行设计
-
- 4.1 子系统设计
-
- 4.1.1 分析子系统
- 4.1.2 后台子系统
- 4.1.3 前端子系统
- 4.1.4 爬虫子系统
- 4.2 数据存储
-
- 4.2.1 数据存储软件
- 4.2.2 数据存储模型
- 5. 特性设计
-
- 5.1.1 内存占用
- 5.1.2 响应速度
- 5.2 可维护性与可扩展性
- 5.3 可交互性
- 5.4 可靠性
- 5.5 安全性
- 6. 部署
-
- 6.1 部署模式
- 6.2 许可协议
-
1. 引言
1.1 编写目的
编写此文档的目的是确认微博舆情分析系统的基本架构,指导系统的基本架构。
1.2 项目信息
- 项目名称:舆情分析系统
- 项目提出者:指导教师
- 开发者:东北大学软件学院大数据班T09实训项目组(lzf、lcx)
- 用户:舆情分析员、系统管理员
1.3 项目背景
互联网的飞速发展促进了很多新媒体的发展,不论是知名的大 V,明星还是围观群众都可以通过手机在微博,朋友圈或者点评网站上发表状态,分享自己的所见所想,使得“人人都有了麦克风”。不论是热点新闻还是娱乐八卦,传播速度远超我们的想象。可以在短短数分钟内,有数万计转发,数百万的阅读。如此海量的信息可以得到爆炸式的传播,如何能够实时的把握民情并作出对应的处理对很多企业来说都是至关重要的,而这一切也意味着传统的舆情系统升级成为大数据舆情采集和分析系统。
1.4 阅读对象
- 本系统的设计人员:主要是舆情分析系统开发小组成员。
- 本系统的开发人员:主要是舆情分析系统开发小组成员。
- 本系统的测试人员:主要是舆情分析系统开发小组成员。
1.5 术语与缩略语
1.6 参考资料
- 《舆情分析系统-软件需求规格说明书》
- 中移舆情架构图:https://ecloud.10086.cn/home/product-introduction/pa
- 系统架构设计说明书:
https://wenku.baidu.com/view/5afd18a42a4ac850ad02de80d4d8d15abe23006e.html
2. 范围
2.1 软件名称
- 英文名称:POAS(Public Opinion Analysis System)
- 中文名称:舆情分析系统
2.2 软件功能
- 参考《舆情分析系统-软件需求规格说明书》
3. 总体设计
3.1 架构设计目标和约束
3.1.1 架构设计目标
架构设计的目标是为了解决目前或者未来软件系统由于复杂度可能带来的问题。就目前而言,架构设计主要是为了识别、梳理用例模型交互、功能模块实现、接口设计和概念模型设计等涉及到的复杂点,再针对这些复杂点制定处理方案,从而通过设计来增强效用、减少成本,降低复杂度。而就未来而言,系统架构设计将随着业务发展不断演变、完善,以解决未来软件系统由于复杂度可能带来的问题。
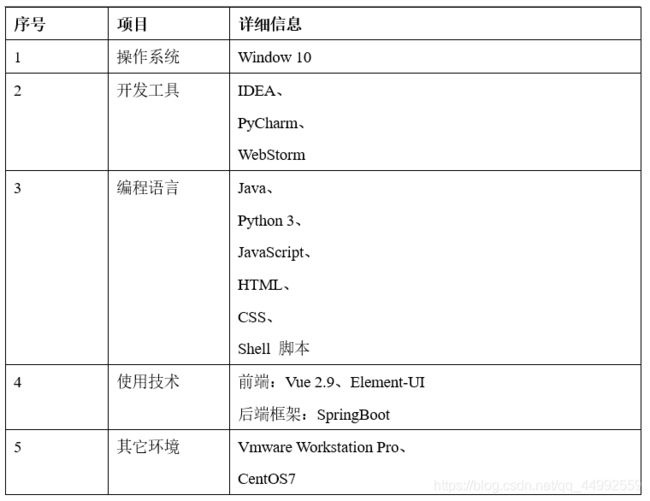
3.1.2 开发环境
3.1.3 运行环境

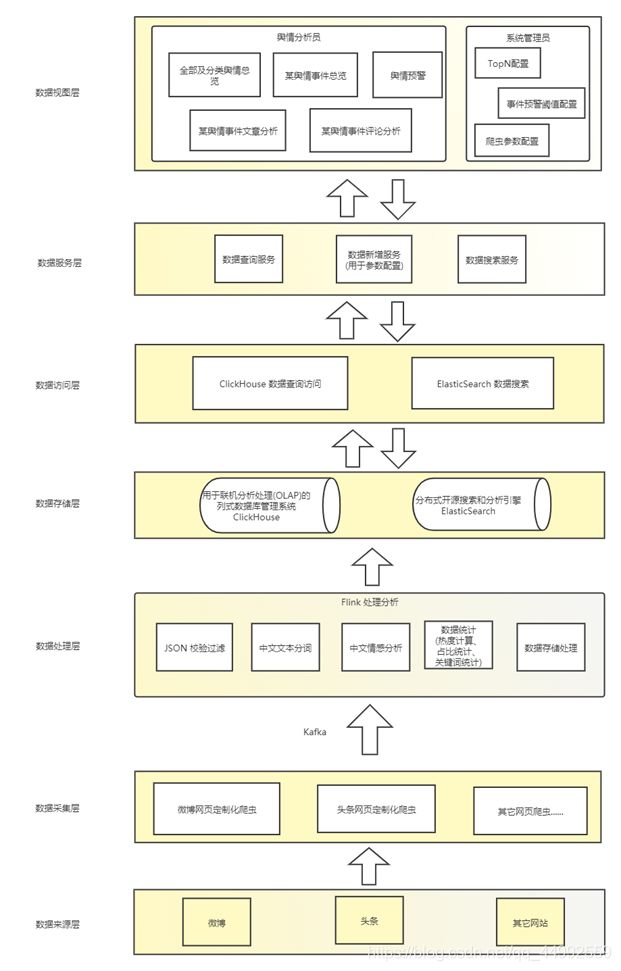
3.2 系统架构设计
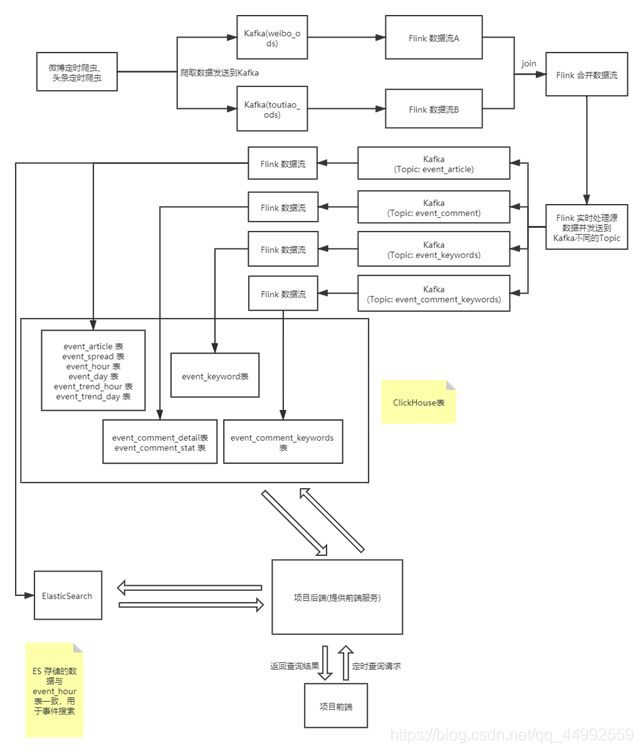
3.3 系统流程
3.4 系统模块划分与模块接口
3.4.1 模块描述
- 数据采集模块
数据采集模块主要是通过网页爬虫定时对目标网站的新闻文章数据进行爬取,爬取的间隔参数可以通过系统管理页面配置。 - 实时处理分析与数据存储模块
实时处理分析与数据存储模块接收数据采集模块采集到的数据,通过Flink代码处理原始数据到不同的下游Topic,再根据需求对数据进行实时处理、实时分析,最终存入ClickHouse与ElasticSearch。 - 数据查询搜索模块
数据查询搜索模块负责搜索查询ClickHouse与ElasticSearch存储的数据,提供接口让前端进行查询并展示。 - 前端展示模块
接收后端的查询到的数据,对数据进行可视化展示。 - 登录模块
登录模块负责舆情分析员与管理员的登录,舆情分析员登录后可查看舆情分析报表,管理员登录后可以配置相关参数。
3.4.2 模块接口设计
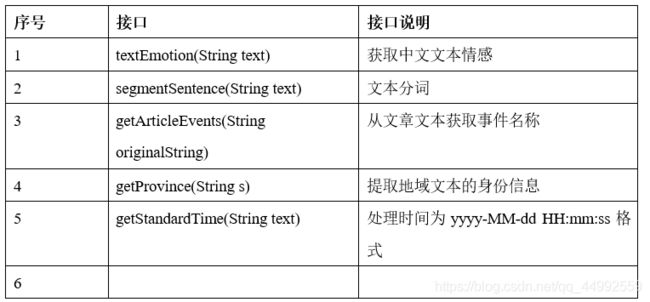
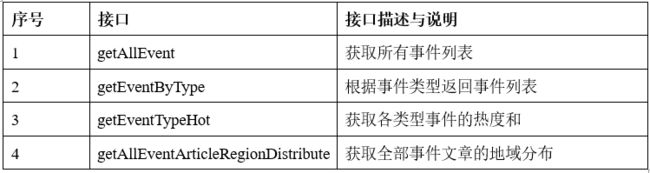
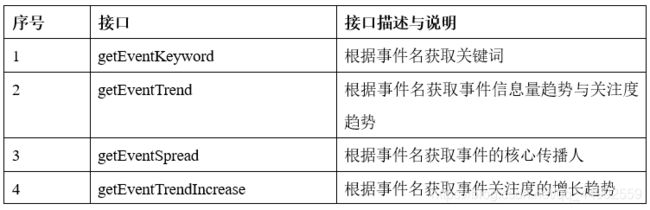
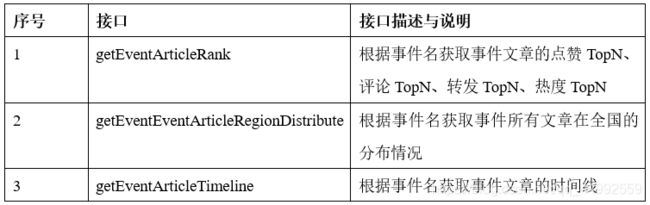
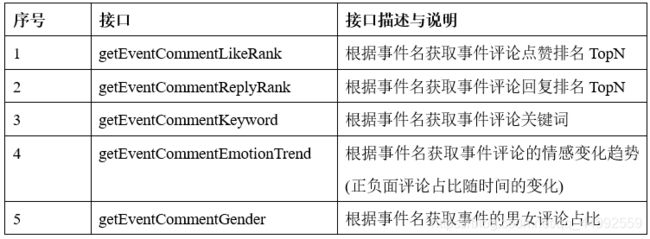
实时处理分析与数据存储模块的接口主要是模块代码的使用接口,主要涉及的接口有textEmotion()接口、segmentSentence()接口、getArticleEvents()接口、getProvince()接口、getStandardTime()接口以及存储数据到ClickHouse与ElasticSearch的第三方接口,这些接口的作用说明如下表所示:
数据查询搜索模块的接口主要是控制层提供的前端舆情展示的查询搜索接口、登录接口、管理员的参数配置接口以及数据层提供的数据查询访问接口(ClickHouse SQL),控制层接口设计清单如下表所示:
-
舆情首页
-
舆情事件搜索页

-
舆情事件总览页
-
舆情事件文章分析页
-
舆情事件评论分析页
-
舆情事件预警页
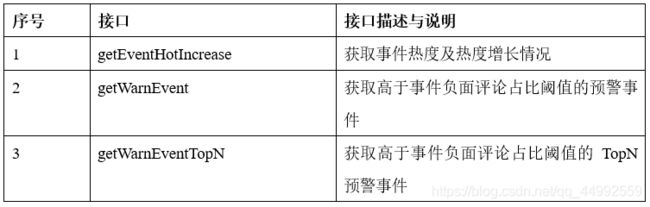
-
管理员配置页
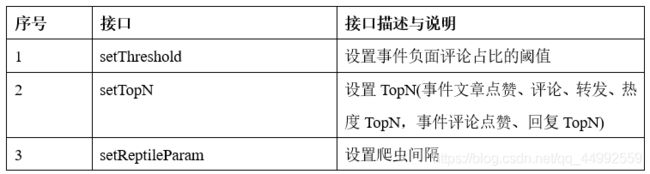
-
其它
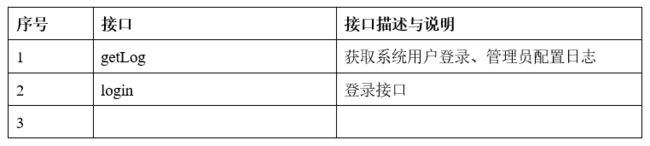
4. 运行设计
4.1 子系统设计
4.1.1 分析子系统
主要由Flink编写的代码组成,每个代码文件为一个Flink的任务,通过构建并提交Flink任务到Flink集群来进行舆情数据(通过Kafka的Topic获取)的处理分析,并将数据存入到ClickHouse与ElasticSearch。
4.1.2 后台子系统
主要是通过SpringBoot、MyBatis、clickhouse-jdbc、spring-boot-starter-data-elasticsearch编写的控制层、服务层、数据层代码来提供前端的数据查询与搜索服务,后台子系统通过查询由分析子系统写入到ClickHouse表的数据以及ElasticSearch的index的数据从而将数据返回给前端子系统。
4.1.3 前端子系统
通过Vue.js、Element-UI(基于 Vue 2.0 的桌面端组件库)、echarts(基于JavaScript的数据可视化图表库)、echarts-wordcloud、DataV(Vue 大屏数据展示组件库)等前端技术构建起来的舆情事件展示的前端系统。前端子系统定时发送http查询或搜索请求到后台子系统并将后台子系统返回的数据渲染到前端图表。
4.1.4 爬虫子系统
通过Python爬虫技术爬取微博网页、头条网页的舆情数据到Kafka的Topic,Topic的数据由分析子系统的Flink代码获取并处理。
4.2 数据存储
4.2.1 数据存储软件
舆情分析系统的数据采用ClickHouse表与ElasticSearch存储,其中ElasticSearch存储ClickHouse表的其中一个,用于事件搜索。
4.2.2 数据存储模型
系统的数据采用ClickHouse表存储。
event_article 表

event_day 与 event_hour 表
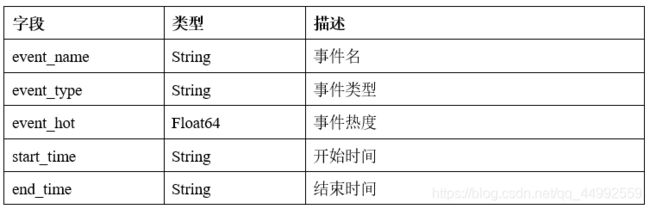
event_trend 表
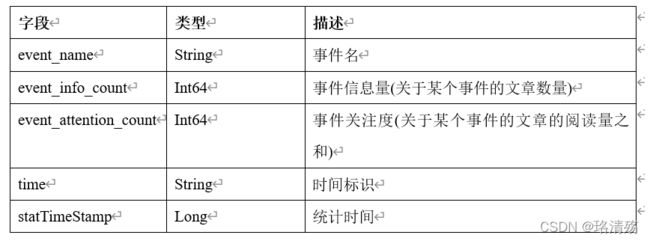
event_spread 表
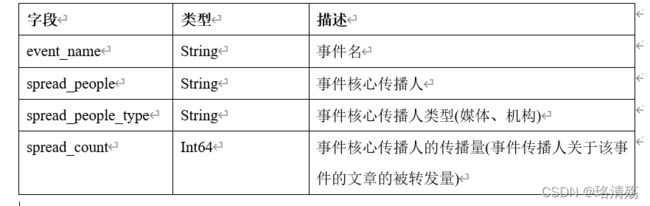
event_keyword 表

event_comment_detail 表
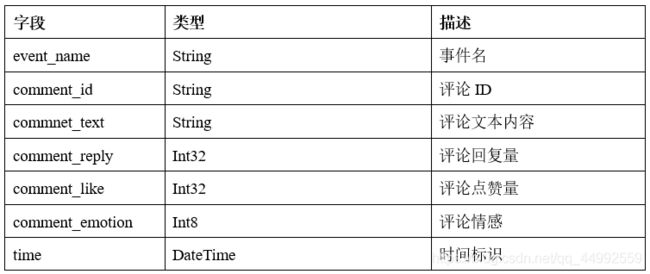
event_comment_stat 表

event_comment_keyword 表

user 表

topn 表

threshold 表

reptile_param 表

ElasticSearch的数据与event_hour 表的数据保持一致。
logs 表

5. 特性设计
5.1 性能
5.1.1 内存占用
内存占用约8G左右。
5.1.2 响应速度
在网络正常的情况下用户点击网页后页面的跳转时间<=1s,页面数据的加载时间<=5s;若页面的数据量较大而导致的页面加载时间长的话,页面必须提供网页加载提示。
5.2 可维护性与可扩展性
系统基于大数据生态组件构建,鉴于大数据组件的横向扩展能力,系统的可扩展性有一定保证。系统代码的开发需要满足代码开发规范,需要做好充分的注释、注意代码的可复用性、注意功能模块之间解耦能力,使得系统能够以较低成本进行二次开发、进行功能扩展、进行系统维护。
5.3 可交互性
系统的人机交互符合人的认知心理学基本原理,并且需要降低系统工作人员的学习成本,必要的话还要提供系统使用的帮助文档。
5.4 可靠性
在系统发生故障后,需要保证系统可以在较短时间内重建其性能水平并恢复直接受影响数据的能力,并且使系统故障率保持在一定的水平下。
5.5 安全性
系统需要保证数据的安全,防止数据的泄漏等。
6. 部署
6.1 部署模式
采用Nginx 前后端分离方式部署前后端项目,采用Flink本地模式部署分析模块(分析子系统)代码。
6.2 许可协议
许可协议方式和版权加密控制方式。