极客星球 | 联邦学习与产品化之路
一、 背景——联邦学习与fate简介
1、联邦学习
联邦学习(Federated Learning)是一种新兴的人工智能基础技术,由谷歌最先提出于2016年,原用于解决安卓手机终端用户在本地更新模型的问题。其设计目标是在保障大数据交换时的信息安全、保护终端数据和个人数据隐私、保证合法合规的前提下,在多参与方或多计算结点之间开展高效率的机器学习,目标是在保证数据隐私安全及合法合规的基础上实现共同建模,提升AI模型的效果。总的来说,联邦学习本质上是一种分布式机器学习技术或机器学习框架。
2、FATE
Federated AI Technology Enabler(简称FATE) 是由微众银行AI团队,于2019年2月推出的全球首个工业级别联邦学习框架,可以让企业和机构在保护数据安全和数据隐私的前提下进行AI协作。FATE项目使用多方安全计算 (MPC) 以及同态加密 (HE) 技术构建底层安全计算协议,以此支持不同种类的机器学习的安全计算,包括逻辑回归、基于树的算法、深度学习和迁移学习等。
FATE技术架构的底层是Tensorflow / Pytorch(深度学习)、EggRoll /Spark(分布式计算框架)和多方联邦通信网络,上层为联邦安全协议,并在安全协议的基础上构建联邦学习算法库。
Federatedml模块包括许多常见机器学习算法联邦化实现。所有模块均采用去耦的模块化方法开发,以增强模块的可扩展性。具体包括:
- 联邦统计: 包括隐私交集计算,并集计算,皮尔逊系数等;
- 联邦特征工程:包括联邦采样,联邦特征分箱,联邦特征选择等;
- 联邦机器学习算法:包括横向和纵向的联邦LR, GBDT, DNN,迁移学习等;
- 模型评估:提供对二分类,多分类,回归评估,联邦和单边对比评估;
- 安全协议:提供了多种安全协议,以进行更安全的多方交互计算。
二、Fate产品化
1、Fate操作方式
1)配置Json + fate_client命令行
为了让任务模型的构建更加灵活,目前 FATE 使用了一套自定的域特定语言 (DSL:domain-specific language) 来描述任务。在 DSL中,各种模块可以通向一个有向无环图(DAG)组织起来。通过各种方式,用户可以根据自身的需要,灵活地组合各种算法模块。
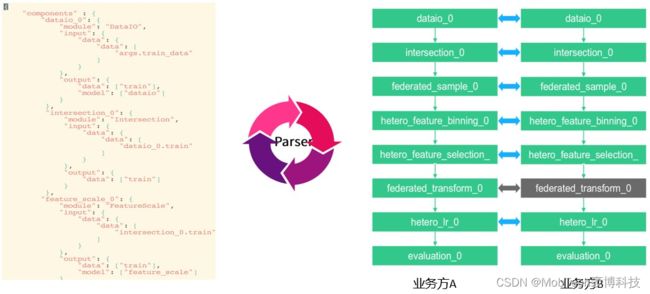
FATE构建联邦学习Pipeline是通过自定义dsl和conf两个配置文件来实现的:
- dsl文件:用来描述任务模块,将任务模块以有向无环图(DAG)的形式组合在一起。
- conf文件:设置各个组件的参数,比如输入模块的数据表名;算法模块的学习率、batch大小、迭代次数等。
执行示例:

2)pipeline代码行
pipeline是一个更高级的接口,它将上面提交任务的方式以及很多fate flow client命令进行了封装,使用pipeline建模就像传统方式一样在python里添加需要的模块、定义模块的参数,然后运行,而不用更改dsl的json文件,然后使用命令行提交任务。

2、产品化需求
1)任务配置繁琐
以上fate提交任务的两种方式,由于Fate内部模块众多,且不同的模块对应的参数不同,只有对fate框架比较熟悉的技术人员才能使用,有一定的技术门槛,对普通业务人员不友好
2)不支持component复用
在1.7以下的版本中,fate并不支持不同component的独立运行、阶段复用,只能数据预处理、数据对齐、特征工程、模型训练等步骤一次性执行结束。如果中间任何一个环节出现问题,整个任务必须重新从头执行;如果想使用相同的数据、不同的训练参数重新训练,也必须修改好对应的json后重新提交,执行完整流程。
这对于使用者来说,会带来不必要的时间浪费,如果双方的数据量较大,这个问题会更加明显。
3)缺失权限控制
这部分包括两个方面:
- 对外:在原生Fate中,当双方配置相应的party_id、ip、port后,单方可以无限次发起任务,也可以使用枚举攻击获取另一方数据(例如手机号MD5枚举),会给合作方的硬件资源、数据安全等带来危害;
- 对内:缺少不同项目以及相关数据之间的权限控制,容易造成管理混乱
4)部署较为繁琐
现阶段的客户多愿意采用本地部署的方式而非云部署,官方虽然提供了各种本地部署指导以及ansible自动化部署脚本,但对于技术人员来讲,部署依然较为繁琐;如果不同合作方涉及多个不同的操作系统,部署会更加复杂,也会带来较多的稳定性隐患。
三、产品化难点
1、component/步骤解耦
通过研读fate源码,发现各个component衔接的核心在于如何读取上一个component的数据、Model输出;而控制输入的模块则由dsl定义,在原生fate中,对应的是上一个component的代号【同一job内,job_id固定】,不能人为指定。
因此,要实现解耦/复用,需要重新定义DSL中模块输入的参数,并在fate_flow中修改对应的解析逻辑,使后续的component可以读取上一个component的输出。
核心逻辑如下:
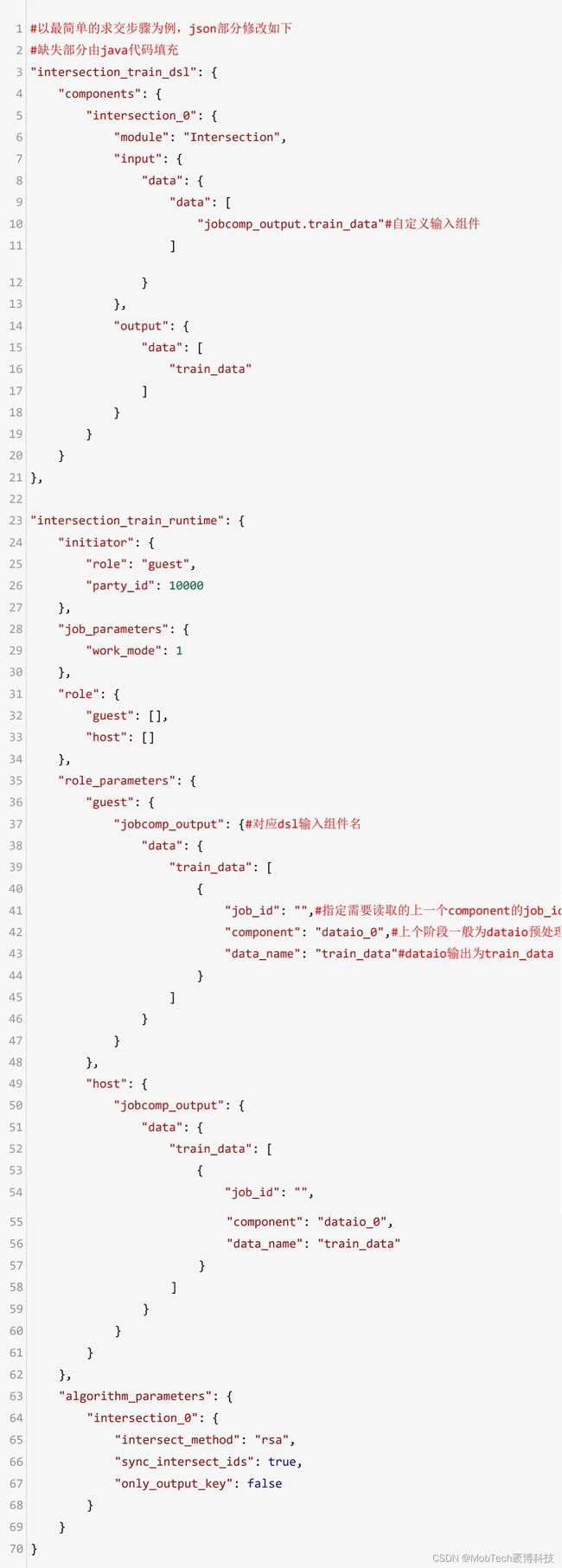
java端提交job信息到fate,fate端解析json获取对应的job_id、component、data_name;
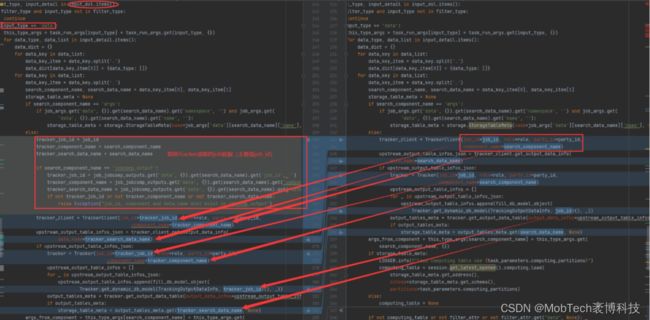
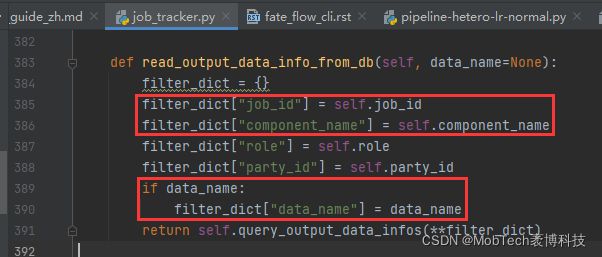
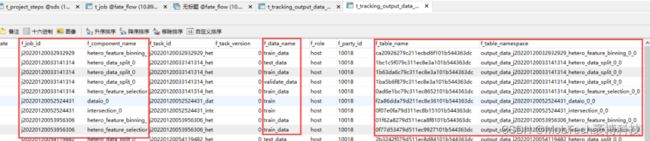
tracker组件从底层库表读取对应component输出的库表
2、通信信道安全性【信通院认证必选项】
1)双端口
在最早的求交产品中,我们将任务相关的信息使用单独的web程序通过指定的端口进行通信,与fate自身的端口是相互独立的。但是这样一来,如果要满足认证所需的安全性,web端通信的数据加密需要单独开发,技术难度较大,整个系统也需要定义两套不同的加解密系统,系统设计会出现不必要的冗余模块,因此被弃用。
2)统一TLS通道
Fate的eggroll模块已经实现TLS双向通信加密功能,只需要添加双方的公私钥文件,并在配置中开启即可。
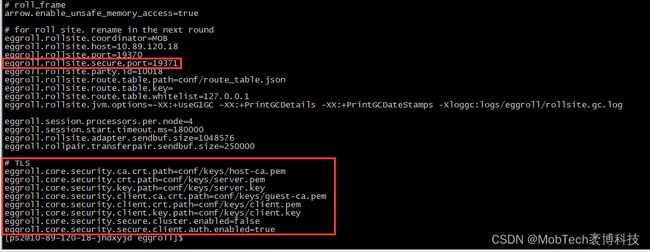
因此可以利用fate中已有的proxy_app模块,通过eggroll定义好的grpc通信通道进行信息传递;
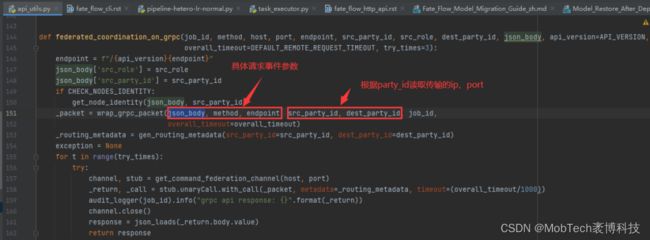
由于只涉及请求事件信息传递,因此还需要在java端增加相应的解析执行模块,来完成具体的信息同步、数据入库、状态更新等动作。
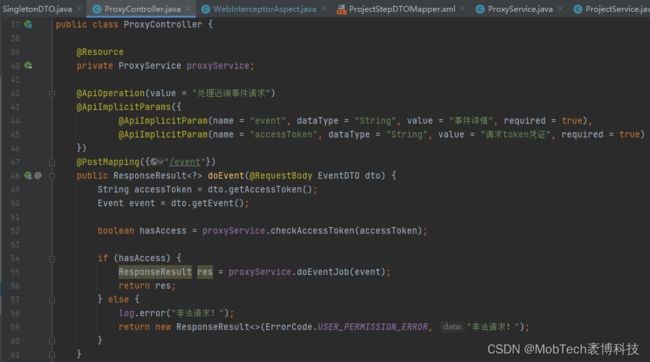
3、兼顾数据安全的项目合作机制
1)配置全局合作Token
在信通院版本的开发中,为了缩短开发周期,我们使用了全局Token方式,对于某一合作方,我们将双方协定好的token配置在数据库中,后续任务根据这一token进行权限认证(数据读取、job执行权限);如果合作解除,任意一方删除token或取消对应库表的授权即可;这样初步达到了权限控制的目的。
但是这种方式仍存在对方可通过枚举窃取数据的弊端,例如通过手机号枚举获取我方全库数据id。
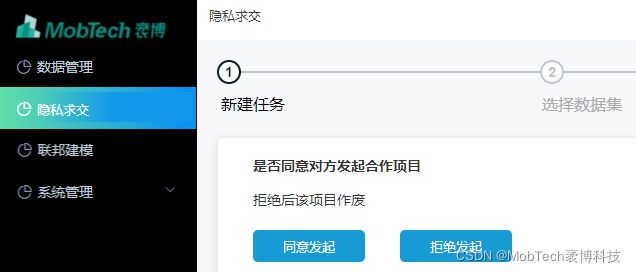
2)会话式项目合作Token
这种方式执行合作前,需要先通过对话式的通信创建任务,每个任务分配一个合作Token,并限定合作所涉及的库表,这样就从根本上杜绝了枚举攻击的可能。
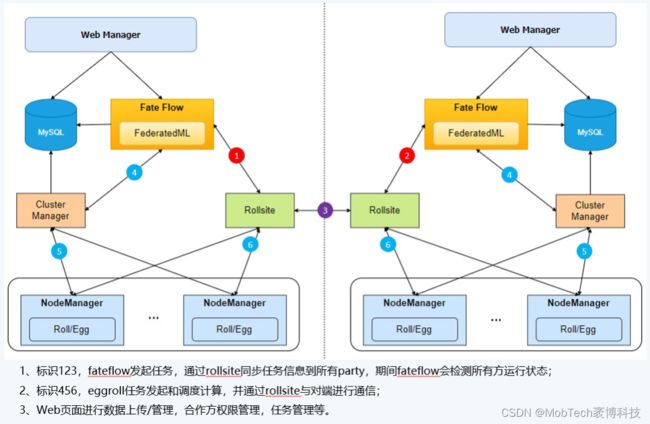
全局通信流程如下:
1)在项目创建阶段,通过proxy_app + Java Hook代理的方式实现请求信息传送、双方库表等信息互通更新;
2)在job执行阶段,先通过代理同步job信息,然后在各方本地通过job_id获取对应项目的token进行权限验证【同步启动状态刷新线程】;
3)具体的job、项目状态更新由后台异步线程完成。

四、产品介绍
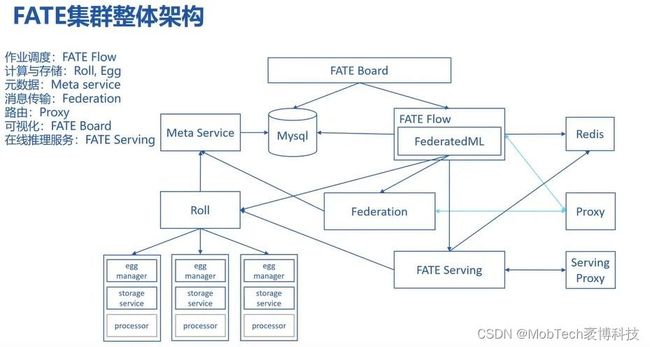
1、整体架构
在Fate原生架构基础上,新增了web管理界面,用于数据、任务的提交及相关信息展示、管理
2、产品功能模块
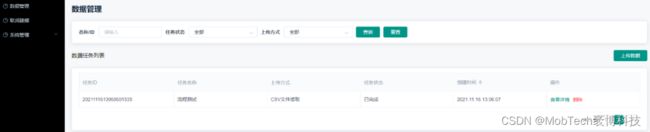
1)数据管理
数据集的上传、管理等
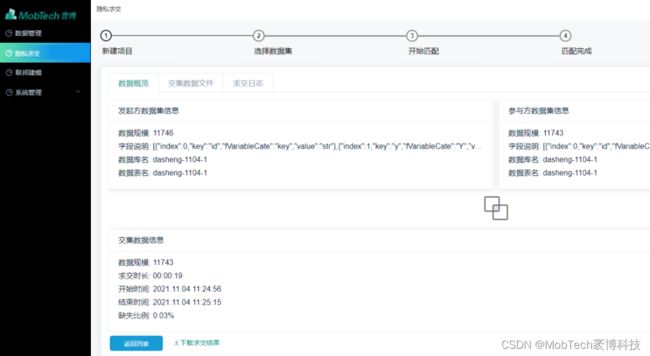
2)求交
支持原始数据直接求交,下载数据交集
3)联邦建模
完整的数据预处理、数据匹配(求交)、特征工程、模型训练流程
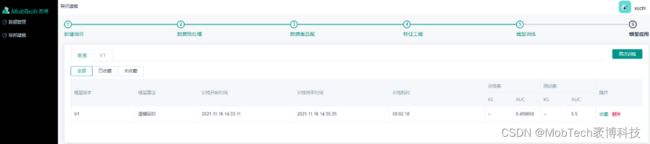
可以调整参数多次训练

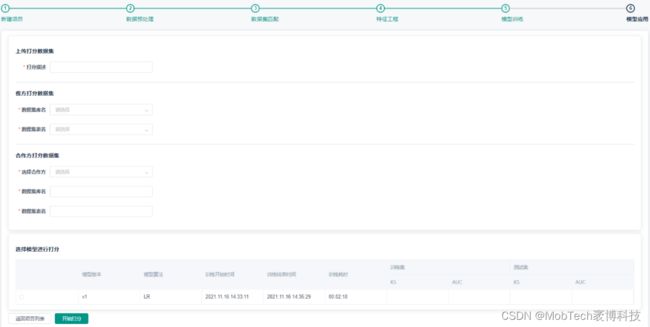
4)模型应用
使用训练好的模型进行批量打分
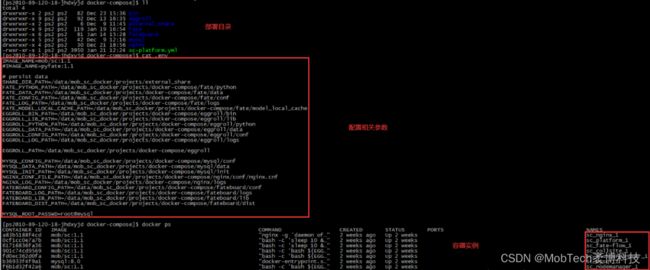
5)Docker容器化部署
部署前导入打包好的Docker镜像,解压部署包,修改env中的参数,即可使用docker-compose启动项目实例