Day512.用户与权限管理&逻辑架构 -mysql
用户与权限管理
一、用户管理
1、登录MySQL服务器
启动MySQL服务后,可以通过mysql命令来登录MySQL服务器,命令如下:
mysql –h hostname|hostIP –P port –u username –p DatabaseName –e "SQL语句"
# 下面详细介绍命令中的参数:
# -h参数 后面接主机名或者主机IP,hostname为主机,hostIP为主机IP。
# -P参数 后面接MySQL服务的端口,通过该参数连接到指定的端口。MySQL服务的默认端口是3306,不使用该参数时自动连接到3306端口,port为连接的端口号。
# -u参数 后面接用户名,username为用户名。
# -p参数 会提示输入密码。
# DatabaseName参数 指明登录到哪一个数据库中。如果没有该参数,就会直接登录到MySQL数据库中,然后可以使用USE命令来选择数据库。
# -e参数 后面可以直接加SQL语句。登录MySQL服务器以后即可执行这个SQL语句,然后退出MySQL服务器
举例:
mysql -uroot -p -hlocalhost -P3306 mysql -e "select host,user from user"
2、创建用户
CREATE USER语句的基本语法形式如下:
CREATE USER 用户名 [IDENTIFIED BY '密码'][,用户名 [IDENTIFIED BY '密码']];
- 用户名参数表示新建用户的账户,由
用户(User)和主机名(Host)构成; - “[ ]”表示可选,也就是说,可以指定用户登录时需要密码验证,也可以不指定密码验证,这样用户可以直接登录。不过,不指定密码的方式不安全,不推荐使用。如果指定密码值,这里需要使用IDENTIFIED BY指定明文密码值。
- CREATE USER语句可以同时创建多个用户。
举例:
CREATE USER zhang3 IDENTIFIED BY '123123'; # 默认host是 %
CREATE USER 'kangshifu'@'localhost' IDENTIFIED BY '123456';
3、修改用户
修改用户名:
UPDATE mysql.user SET USER='li4' WHERE USER='wang5';
FLUSH PRIVILEGES;

4、删除用户
方式1:使用DROP方式删除(推荐)
使用DROP USER语句来删除用户时,必须用于DROP USER权限。DROP USER语句的基本语法形式
如下:
DROP USER user[,user]…;
举例:
DROP USER li4 ; # 默认删除host为%的用户
DROP USER 'kangshifu'@'localhost';

方式2:使用DELETE方式删除
DELETE FROM mysql.user WHERE Host=’hostname’ AND User=’username’;
执行完DELETE命令后要使用FLUSH命令来使用户生效,命令如下:
FLUSH PRIVILEGES;
举例:
DELETE FROM mysql.user WHERE Host='localhost' AND User='Emily';
FLUSH PRIVILEGES;
注意:
不推荐通过DELETE FROM USER u WHERE USER='li4'进行删除,系统会有残留信息保留。而drop user命令会删除用户以及对应的权限,执行命令后你会发现mysql.user表和mysql.db表的相应记录都消失了。
5、设置当前用户密码
旧的写法如下 :
# 修改当前用户的密码:(MySQL5.7测试有效)
SET PASSWORD = PASSWORD('123456');
这里介绍 推荐的写法 :
使用ALTER USER命令来修改当前用户密码用户可以使用ALTER命令来修改自身密码,如下语句代表修改当前登录用户的密码。基本语法如下:
SET PASSWORD='new_password';
该语句会自动将密码加密后再赋给当前用户。
6、修改其它用户密码
使用ALTER语句来修改普通用户的密码可以使用ALTER USER语句来修改普通用户的密码。基本语法形式如下:
ALTER USER user [IDENTIFIED BY '新密码']
[,user[IDENTIFIED BY '新密码']]…;
使用SET命令来修改普通用户的密码使用root用户登录到MySQL服务器后,可以使用SET语句来修改普通用户的密码。SET语句的代码如下:
SET PASSWORD FOR 'username'@'hostname'='new_password';
- 使用
UPDATE语句修改普通用户的密码(不推荐)
UPDATE MySQL.user SET authentication_string=PASSWORD("123456")
WHERE User = "username" AND Host = "hostname";
7、MySQL8密码管理(了解)
- 密码过期策略
在MySQL中,数据库管理员可以 手动设置 账号密码过期,也可以建立一个 自动 密码过期策略。
过期策略可以是 全局的,也可以为 每个账号 设置单独的过期策略。
ALTER USER user PASSWORD EXPIRE;
练习:
ALTER USER 'kangshifu'@'localhost' PASSWORD EXPIRE;
方式①:使用SQL语句更改该变量的值并持久化
SET PERSIST default_password_lifetime = 180; # 建立全局策略,设置密码每隔180天过期
方式②:配置文件my.cnf中进行维护
[mysqld]
default_password_lifetime=180 #建立全局策略,设置密码每隔180天过期
手动设置指定时间过期方式2:单独设置
每个账号既可延用全局密码过期策略,也可单独设置策略。在 CREATE USER 和 ALTER USER 语句上加入 PASSWORD EXPIRE 选项可实现单独设置策略。下面是一些语句示例。
#设置kangshifu账号密码每90天过期:
CREATE USER 'kangshifu'@'localhost' PASSWORD EXPIRE INTERVAL 90 DAY;
ALTER USER 'kangshifu'@'localhost' PASSWORD EXPIRE INTERVAL 90 DAY;
#设置密码永不过期:
CREATE USER 'kangshifu'@'localhost' PASSWORD EXPIRE NEVER;
ALTER USER 'kangshifu'@'localhost' PASSWORD EXPIRE NEVER;
#延用全局密码过期策略:
CREATE USER 'kangshifu'@'localhost' PASSWORD EXPIRE DEFAULT;
ALTER USER 'kangshifu'@'localhost' PASSWORD EXPIRE DEFAULT;
2. 密码重用策略
- 手动设置密码重用方式1:全局
- 方式①:使用SQL
SET PERSIST password_history = 6; #设置不能选择最近使用过的6个密码 SET PERSIST password_reuse_interval = 365; #设置不能选择最近一年内的密码
- 方式②:my.cnf配置文件
[mysqld] password_history=6 password_reuse_interval=365 - 手动设置密码重用方式2:单独设置
#不能使用最近5个密码:
CREATE USER 'kangshifu'@'localhost' PASSWORD HISTORY 5;
ALTER USER 'kangshifu'@'localhost' PASSWORD HISTORY 5;
#不能使用最近365天内的密码:
CREATE USER 'kangshifu'@'localhost' PASSWORD REUSE INTERVAL 365 DAY;
ALTER USER 'kangshifu'@'localhost' PASSWORD REUSE INTERVAL 365 DAY;
#既不能使用最近5个密码,也不能使用365天内的密码
CREATE USER 'kangshifu'@'localhost'
PASSWORD HISTORY 5
PASSWORD REUSE INTERVAL 365 DAY;
ALTER USER 'kangshifu'@'localhost'
PASSWORD HISTORY 5
PASSWORD REUSE INTERVAL 365 DAY;
二、权限管理
1、权限列表
MySQL到底都有哪些权限呢?
mysql> show privileges;
(1)
CREATE和DROP权限,可以创建新的数据库和表,或删除(移掉)已有的数据库和表。如果将MySQL数据库中的DROP权限授予某用户,用户就可以删除MySQL访问权限保存的数据库。
(2)SELECT、INSERT、UPDATE和DELETE权限允许在一个数据库现有的表上实施操作。
(3)SELECT权限只有在它们真正从一个表中检索行时才被用到。
(4)INDEX权限允许创建或删除索引,INDEX适用于已有的表。如果具有某个表的CREATE权限,就可以在CREATE TABLE语句中包括索引定义。
(5)ALTER权限可以使用ALTER TABLE来更改表的结构和重新命名表。
(6)CREATE ROUTINE权限用来创建保存的程序(函数和程序),ALTER ROUTINE权限用来更改和删除保存的程序,EXECUTE权限用来执行保存的程序。
(7)GRANT权限允许授权给其他用户,可用于数据库、表和保存的程序。
(8)FILE权限使用户可以使用LOAD DATA INFILE和SELECT … INTO OUTFILE语句读或写服务器上的文件,任何被授予FILE权限的用户都能读或写MySQL服务器上的任何文件(说明用户可以读任何数据库目录下的文件,因为服务器可以访问这些文件)。
2、 授予权限的原则
权限控制主要是出于安全因素,因此需要遵循以下几个 经验原则 :
1、只授予能
满足需要的最小权限,防止用户干坏事。比如用户只是需要查询,那就只给select权限就可以了,不要给用户赋予update、insert或者delete权限。
2、创建用户的时候限制用户的登录主机,一般是限制成指定IP或者内网IP段。
3、为每个用户设置满足密码复杂度的密码。
4、定期清理不需要的用户,回收权限或者删除用户。
3、授予权限
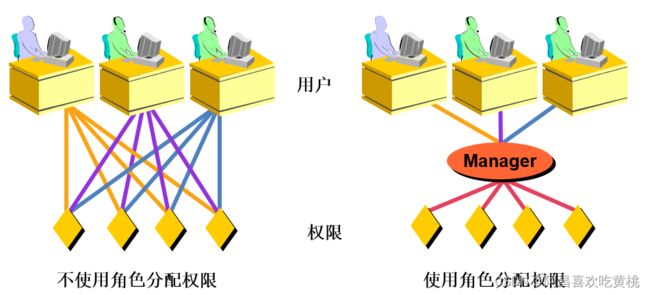
给用户授权的方式有 2 种,分别是通过把 角色赋予用户给用户授权 和 直接给用户授权 。用户是数据库的使用者,我们可以通过给用户授予访问数据库中资源的权限,来控制使用者对数据库的访问,消除安全隐患。
授权命令:
GRANT 权限1,权限2,…权限n ON 数据库名称.表名称 TO 用户名@用户地址 [IDENTIFIED BY ‘密码口令’];
- 该权限如果发现没有该用户,则会直接新建一个用户。
- 给li4用户用本地命令行方式,授予atguigudb这个库下的所有表的插删改查的权限。
GRANT SELECT,INSERT,DELETE,UPDATE ON atguigudb.* TO li4@localhost ;
- 授予通过网络方式登录的joe用户 ,对所有库所有表的全部权限,密码设为123。注意这里唯独不包括grant的权限
GRANT ALL PRIVILEGES ON *.* TO joe@'%' IDENTIFIED BY '123';
我们在开发应用的时候,经常会遇到一种需求,就是要根据用户的不同,对数据进行横向和纵向的分组。
- 所谓横向的分组,就是指用户可以接触到的数据的范围,比如可以看到哪些表的数据;
- 所谓纵向的分组,就是指用户对接触到的数据能访问到什么程度,比如能看、能改,甚至是删除。
4、查看权限
- 查看
当前用户权限
SHOW GRANTS;
# 或
SHOW GRANTS FOR CURRENT_USER;
# 或
SHOW GRANTS FOR CURRENT_USER();
- 查看某用户的全局权限
SHOW GRANTS FOR 'user'@'主机地址' ;
5、收回权限
收回权限就是取消已经赋予用户的某些权限。收回用户不必要的权限可以在一定程度上保证系统的安全性。MySQL中使用 REVOKE语句 取消用户的某些权限。使用REVOKE收回权限之后,用户账户的记录将从db、host、tables_priv和columns_priv表中删除,但是用户账户记录仍然在user表中保存(删除user表中的账户记录使用DROP USER语句)。
注意:在将用户账户从user表删除之前,应该收回相应用户的所有权限。
- 收回权限命令
REVOKE 权限1,权限2,…权限n ON 数据库名称.表名称 FROM 用户名@用户地址;
- 举例
#收回全库全表的所有权限
REVOKE ALL PRIVILEGES ON *.* FROM joe@'%';
#收回mysql库下的所有表的插删改查权限
REVOKE SELECT,INSERT,UPDATE,DELETE ON mysql.* FROM joe@localhost;
- 注意: 须用户重新登录后才能生效
三、权限表
1、user表
user表是MySQL中最重要的一个权限表, 记录用户账号和权限信息 ,有49个字段。如下图:

这些字段可以分成4类,分别是范围列(或用户列)、权限列、安全列和资源控制列。
- 范围列(或用户列)
- host : 表示连接类型
%表示所有远程通过 TCP方式的连接IP 地址如 (192.168.1.2、127.0.0.1) 通过制定ip地址进行的TCP方式的连接机器名通过制定网络中的机器名进行的TCP方式的连接::1IPv6的本地ip地址,等同于IPv4的 127.0.0.1localhost本地方式通过命令行方式的连接 ,比如mysql -u xxx -p xxx 方式的连接。
- user : 表示用户名,同一用户通过不同方式链接的权限是不一样的。
- password : 密码
- 所有密码串通过 password(明文字符串) 生成的密文字符串。MySQL 8.0 在用户管理方面增加了角色管理,默认的密码加密方式也做了调整,由之前的
SHA1改为了SHA2,不可逆 。同时加上 MySQL 5.7 的禁用用户和用户过期的功能,MySQL 在用户管理方面的功能和安全性都较之前版本大大的增强了。 - mysql 5.7 及之后版本的密码保存到
authentication_string字段中不再使用password 字
段。
- 所有密码串通过 password(明文字符串) 生成的密文字符串。MySQL 8.0 在用户管理方面增加了角色管理,默认的密码加密方式也做了调整,由之前的
- host : 表示连接类型
- 权限列
- Grant_priv字段
表示是否拥有GRANT权限 - Shutdown_priv字段
表示是否拥有停止MySQL服务的权限 - Super_priv字段
表示是否拥有超级权限 - Execute_priv字段
表示是否拥有EXECUTE权限。拥有EXECUTE权限,可以执行存储过程和函数。 - Select_priv , Insert_priv等
为该用户所拥有的权限。
- Grant_priv字段
- 安全列
- 安全列只有6个字段,其中两个是ssl相关的(ssl_type、ssl_cipher),用于
加密;两个是x509相关的(x509_issuer、x509_subject),用于标识用户;另外两个Plugin字段用于验证用户身份的插件,该字段不能为空。如果该字段为空,服务器就使用内建授权验证机制验证用户身份。
- 安全列只有6个字段,其中两个是ssl相关的(ssl_type、ssl_cipher),用于
- 资源控制列
- 资源控制列的字段用来 限制用户使用的资源 ,包含4个字段,分别为:
- ①max_questions,用户每小时允许执行的查询操作次数;
- ②max_updates,用户每小时允许执行的更新操作次数;
- ③max_connections,用户每小时允许执行的连接操作次数;
- ④max_user_connections,用户允许同时建立的连接次数。
查看字段:
- 资源控制列的字段用来 限制用户使用的资源 ,包含4个字段,分别为:
DESC mysql.user;
查看用户, 以列的方式显示数据:
SELECT * FROM mysql.user \G;
查询特定字段:
SELECT host,user,authentication_string,select_priv,insert_priv,drop_priv
FROM mysql.user;
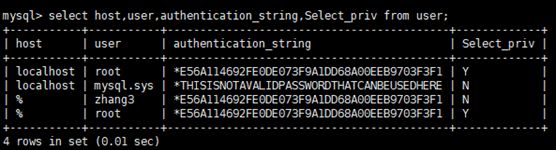
2、db表
使用DESCRIBE查看db表的基本结构:
DESCRIBE mysql.db;
- 用户列
db表用户列有3个字段,分别是Host、User、Db。这3个字段分别表示主机名、用户名和数据库名。表示从某个主机连接某个用户对某个数据库的操作权限,这3个字段的组合构成了db表的主键。 - 权限列
Create_routine_priv和Alter_routine_priv这两个字段决定用户是否具有创建和修改存储过程的权限。
3、tables_priv表和columns_priv表
tables_priv表用来 对表设置操作权限 ,columns_priv表用来对表的 某一列设置权限 。tables_priv表和columns_priv表的结构分别如图:
desc mysql.tables_priv;
tables_priv表有8个字段,分别是Host、Db、User、Table_name、Grantor、Timestamp、Table_priv和
Column_priv,各个字段说明如下:
Host 、 Db 、 User 和 Table_name四个字段分别表示主机名、数据库名、用户名和表名。- Grantor表示修改该记录的用户。
- Timestamp表示修改该记录的时间。
Table_priv表示对象的操作权限。包括Select、Insert、Update、Delete、Create、Drop、Grant、References、Index和Alter。- Column_priv字段表示对表中的列的操作权限,包括Select、Insert、Update和References。
desc mysql.columns_priv;
4、procs_priv表
procs_priv表可以对 存储过程和存储函数设置操作权限 ,表结构如图:
desc mysql.procs_priv;

四、访问控制(了解)
1、连接核实阶段
当用户试图连接MySQL服务器时,服务器基于用户的身份以及用户是否能提供正确的密码验证身份来确定接受或者拒绝连接。即客户端用户会在连接请求中提供用户名、主机地址、用户密码,MySQL服务器接收到用户请求后,会使用user表中的host、user和authentication_string这3个字段匹配客户端提供信息。
服务器只有在user表记录的Host和User字段匹配客户端主机名和用户名,并且提供正确的密码时才接受
连接。如果连接核实没有通过,服务器就完全拒绝访问;否则,服务器接受连接,然后进入阶段2等待用户请求。
2、请求核实阶段
一旦建立了连接,服务器就进入了访问控制的阶段2,也就是请求核实阶段。对此连接上进来的每个请求,服务器检查该请求要执行什么操作、是否有足够的权限来执行它,这正是需要授权表中的权限列发挥作用的地方。这些权限可以来自user、db、table_priv和column_priv表。
确认权限时,MySQL首先 检查user表 ,如果指定的权限没有在user表中被授予,那么MySQL就会继续 检查db表 ,db表是下一安全层级,其中的权限限定于数据库层级,在该层级的SELECT权限允许用户查看指定数据库的所有表中的数据;如果在该层级没有找到限定的权限,则MySQL继续 检查tables_priv表 以及 columns_priv表 ,如果所有权限表都检查完毕,但还是没有找到允许的权限操作,MySQL将 返回错误信息 ,用户请求的操作不能执行,操作失败。
提示: MySQL通过向下层级的顺序(从user表到columns_priv表)检查权限表,但并不是所有的权限都要执行该过程。例如,一个用户登录到MySQL服务器之后只执行对MySQL的管理操作,此时只涉及管理权限,因此MySQL只检查user表。另外,如果请求的权限操作不被允许,MySQL也不会继续检查下一层级的表。
五、角色管理
1、角色的理解
引入角色的目的是 方便管理拥有相同权限的用户 。恰当的权限设定,可以确保数据的安全性,这是至关重要的。
2、创建角色
创建角色使用 CREATE ROLE 语句,语法如下:
CREATE ROLE 'role_name'[@'host_name'] [,'role_name'[@'host_name']]...
角色名称的命名规则和用户名类似。如果 host_name省略,默认为% , role_name不可省略 ,不可为空。
练习:我们现在需要创建一个经理的角色,就可以用下面的代码:
CREATE ROLE 'manager'@'localhost';
3、给角色赋予权限
创建角色之后,默认这个角色是没有任何权限的,我们需要给角色授权。给角色授权的语法结构是:
GRANT privileges ON table_name TO 'role_name'[@'host_name'];
上述语句中privileges代表权限的名称,多个权限以逗号隔开。可使用SHOW语句查询权限名称,下图列出了部分权限列表。
SHOW PRIVILEGES\G;

练习1:
我们现在想给经理角色授予商品信息表、盘点表和应付账款表的只读权限,就可以用下面的代码来实现:
GRANT SELECT ON demo.settlement TO 'manager';
GRANT SELECT ON demo.goodsmaster TO 'manager';
GRANT SELECT ON demo.invcount TO 'manager';
4、查看角色的权限
赋予角色权限之后,我们可以通过 SHOW GRANTS 语句,来查看权限是否创建成功了:
mysql> SHOW GRANTS FOR 'manager';
+-------------------------------------------------------+
| Grants for manager@% |
+-------------------------------------------------------+
| GRANT USAGE ON *.* TO `manager`@`%` |
| GRANT SELECT ON `demo`.`goodsmaster` TO `manager`@`%` |
| GRANT SELECT ON `demo`.`invcount` TO `manager`@`%` |
| GRANT SELECT ON `demo`.`settlement` TO `manager`@`%` |
+-------------------------------------------------------+
只要你创建了一个角色,系统就会自动默认给你一个“ USAGE ”权限,意思是 连接登录数据库的权限 。代码的最后三行代表了我们给角色“manager”赋予的权限,也就是对商品信息表、盘点表和应付账款表的只读权限。
结果显示,库管角色拥有商品信息表的只读权限和盘点表的增删改查权限。
5、回收角色的权限
角色授权后,可以对角色的权限进行维护,对权限进行添加或撤销。添加权限使用GRANT语句,与角色授权相同。撤销角色或角色权限使用REVOKE语句。
修改了角色的权限,会影响拥有该角色的账户的权限。
撤销角色权限的SQL语法如下:
REVOKE privileges ON tablename FROM 'rolename';
练习1:撤销school_write角色的权限。
(1)使用如下语句撤销school_write角色的权限。
REVOKE INSERT, UPDATE, DELETE ON school.* FROM 'school_write';
(2)撤销后使用SHOW语句查看school_write对应的权限,语句如下。
SHOW GRANTS FOR 'school_write';
6、删除角色
当我们需要对业务重新整合的时候,可能就需要对之前创建的角色进行清理,删除一些不会再使用的角色。
删除角色的操作很简单,你只要掌握语法结构就行了。
DROP ROLE role [,role2]...
注意, 如果你删除了角色,那么用户也就失去了通过这个角色所获得的所有权限 。
练习:执行如下SQL删除角色school_read。
DROP ROLE 'school_read';
7、给用户赋予角色
角色创建并授权后,要赋给用户并处于 激活状态 才能发挥作用。给用户添加角色可使用GRANT语句,语法形式如下:
GRANT role [,role2,...] TO user [,user2,...];
在上述语句中,role代表角色,user代表用户。可将多个角色同时赋予多个用户,用逗号隔开即可。
练习:给kangshifu用户添加角色school_read权限。
(1)使用GRANT语句给kangshifu添加school_read权限,SQL语句如下
GRANT 'school_read' TO 'kangshifu'@'localhost';
(2)添加完成后使用SHOW语句查看是否添加成功,SQL语句如下。
SHOW GRANTS FOR 'kangshifu'@'localhost';
(3)使用kangshifu用户登录,然后查询当前角色,如果角色未激活,结果将显示NONE。SQL语句如下。
SELECT CURRENT_ROLE();
8、激活角色
方式1:使用set default role 命令激活角色
举例:
SET DEFAULT ROLE ALL TO 'kangshifu'@'localhost';
举例:使用 SET DEFAULT ROLE 为下面4个用户默认激活所有已拥有的角色如下:
SET DEFAULT ROLE ALL TO
'dev1'@'localhost',
'read_user1'@'localhost',
'read_user2'@'localhost',
'rw_user1'@'localhost';
方式2:将activate_all_roles_on_login设置为ON
- 默认情况:
mysql> show variables like 'activate_all_roles_on_login';
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| activate_all_roles_on_login | OFF |
+-----------------------------+-------+
1 row in set (0.00 sec)
- 设置:
SET GLOBAL activate_all_roles_on_login=ON;
这条 SQL 语句的意思是,对 所有角色永久激活 。运行这条语句之后,用户才真正拥有了赋予角色的所有权限。
9、撤销用户的角色
撤销用户角色的SQL语法如下:
REVOKE role FROM user;
练习:撤销kangshifu用户的school_read角色。
(1)撤销的SQL语句如下
REVOKE 'school_read' FROM 'kangshifu'@'localhost';
(2)撤销后,执行如下查询语句,查看kangshifu用户的角色信息
SHOW GRANTS FOR 'kangshifu'@'localhost';
执行发现,用户kangshifu之前的school_read角色已被撤销。
10、设置强制角色(mandatory role)
方式1:服务启动前设置
[mysqld]
mandatory_roles='role1,role2@localhost,r3@%.atguigu.com'
方式2:运行时设置
SET PERSIST mandatory_roles = 'role1,role2@localhost,r3@%.example.com'; #系统重启后仍然有效
SET GLOBAL mandatory_roles = 'role1,role2@localhost,r3@%.example.com'; #系统重启后失效
逻辑架构
一、逻辑架构剖析
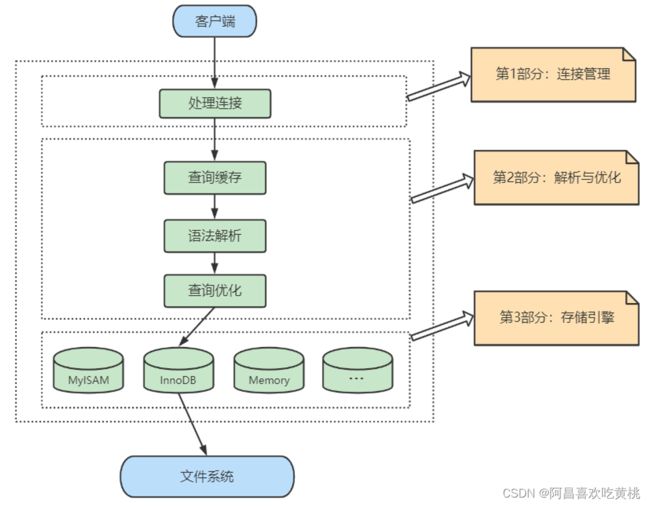
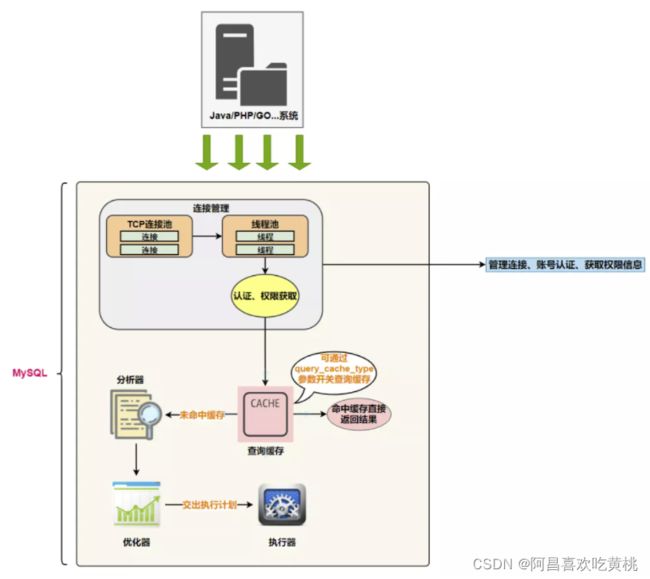
1、服务器处理客户端请求
那服务器进程对客户端进程发送的请求做了什么处理,才能产生最后的处理结果呢?这里以查询请求为例展示:

2、Connectors
3、第1层:连接层
系统(客户端)访问 MySQL 服务器前,做的第一件事就是建立 TCP 连接。
经过三次握手建立连接成功后, MySQL 服务器对 TCP 传输过来的账号密码做身份认证、权限获取。
- 用户名或密码不对,会收到一个Access denied for user错误,客户端程序结束执行
- 用户名密码认证通过,会从权限表查出账号拥有的权限与连接关联,之后的权限判断逻辑,都将依赖于此时读到的权限
TCP 连接收到请求后,必须要分配给一个线程专门与这个客户端的交互。所以还会有个线程池,去走后
面的流程。每一个连接从线程池中获取线程,省去了创建和销毁线程的开销。
4、 第2层:服务层
-
SQL Interface: SQL接口
- 接收用户的SQL命令,并且返回用户需要查询的结果。比如SELECT … FROM就是调用SQLInterface
- MySQL支持DML(数据操作语言)、DDL(数据定义语言)、存储过程、视图、触发器、自定义函数等多种SQL语言接口
-
Parser: 解析器
- 在解析器中对 SQL 语句进行
语法分析、语义分析。将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的。如果在分解构成中遇到错误,那么就说明这个SQL语句是不合理的。 - 在SQL命令传递到解析器的时候会被解析器验证和解析,并为其创建
语法树,并根据数据字典丰富查询语法树,会验证该客户端是否具有执行该查询的权限。创建好语法树后,MySQL还会对SQl查询进行语法上的优化,进行查询重写。
- 在解析器中对 SQL 语句进行
-
Optimizer: 查询优化器
- SQL语句在语法解析之后、查询之前会使用查询优化器确定 SQL 语句的执行路径,生成一个
执行计划。 - 这个执行计划表明应该
使用哪些索引进行查询(全表检索还是使用索引检索),表之间的连接顺序如何,最后会按照执行计划中的步骤调用存储引擎提供的方法来真正的执行查询,并将查询结果返回给用户。 - 它使用“
选取-投影-连接”策略进行查询。例如:
SELECT id,name FROM student WHERE gender = '女';这个SELECT查询先根据WHERE语句进行
选取,而不是将表全部查询出来以后再进行gender过滤。 这个SELECT查询先根据id和name进行属性投影,而不是将属性全部取出以后再进行过滤,将这两个查询条件连接起来生成最终查询结果。 - SQL语句在语法解析之后、查询之前会使用查询优化器确定 SQL 语句的执行路径,生成一个
-
Caches & Buffers: 查询缓存组件
- MySQL内部维持着一些Cache和Buffer,比如Query Cache用来缓存一条SELECT语句的执行结果,如果能够在其中找到对应的查询结果,那么就不必再进行查询解析、优化和执行的整个过程了,直接将结果反馈给客户端。
- 这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等 。
- 这个查询缓存可以在
不同客户端之间共享。 - 从MySQL 5.7.20开始,不推荐使用查询缓存,并在
MySQL 8.0中删除。
小故事:
如果我问你9+8×16-3×2×17的值是多少,你可能会用计算器去算一下,最终结果35。如果再问你一遍9+8×16-3×2×17的值是多少,你还用再傻呵呵的再算一遍吗?我们刚刚已经算过了,直接说答案就好了。
5、第3层:引擎层
插件式存储引擎层( Storage Engines),真正的负责了MySQL中数据的存储和提取,对物理服务器级别维护的底层数据执行操作,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。
MySQL 8.0.25默认支持的存储引擎如下:

6、存储层
所有的数据,数据库、表的定义,表的每一行的内容,索引,都是存在 文件系统 上,以文件 的方式存在的,并完成与存储引擎的交互。当然有些存储引擎比如InnoDB,也支持不使用文件系统直接管理裸设备,但现代文件系统的实现使得这样做没有必要了。在文件系统之下,可以使用本地磁盘,可以使用DAS、NAS、SAN等各种存储系统。
7、小结
以上简化如下:

简化为三层结构:
- 连接层:客户端和服务器端建立连接,客户端发送 SQL 至服务器端;
- SQL 层(服务层):对 SQL 语句进行查询处理;与数据库文件的存储方式无关;
- 存储引擎层:与数据库文件打交道,负责数据的存储和读取。

二、SQL执行流程
1、MySQL 中的 SQL执行流程

MySQL的查询流程:
- 查询缓存:Server 如果在查询缓存中发现了这条 SQL 语句,就会直接将结果返回给客户端;如果没有,就进入到解析器阶段。需要说明的是,因为查询缓存往往效率不高,所以在 MySQL8.0 之后就抛弃了这个功能。
大多数情况查询缓存就是个鸡肋,为什么呢?
SELECT employee_id,last_name FROM employees WHERE employee_id = 101;
查询缓存是提前把查询结果缓存起来,这样下次不需要执行就可以直接拿到结果。需要说明的是,在MySQL 中的查询缓存,不是缓存查询计划,而是查询对应的结果。这就意味着查询匹配的 鲁棒性大大降低 ,只有 相同的查询操作才会命中查询缓存 。两个查询请求在任何字符上的不同(例如:空格、注释、大小写),都会导致缓存不会命中。因此 MySQL 的 查询缓存命中率不高 。
同时,如果查询请求中包含某些系统函数、用户自定义变量和函数、一些系统表,如 mysql 、information_schema、 performance_schema 数据库中的表,那这个请求就不会被缓存。以某些系统函数举例,可能同样的函数的两次调用会产生不一样的结果,比如函数 NOW,每次调用都会产生最新的当前时间,如果在一个查询请求中调用了这个函数,那即使查询请求的文本信息都一样,那不同时间的两次查询也应该得到不同的结果,如果在第一次查询时就缓存了,那第二次查询的时候直接使用第一次查询的结果就是错误的!
此外,既然是缓存,那就有它 缓存失效的时候 。MySQL的缓存系统会监测涉及到的每张表,只要该表的结构或者数据被修改,如对该表使用了INSERT 、 UPDATE 、 DELETE 、 TRUNCATE TABLE 、 ALTER TABLE 、 DROP TABLE 或 DROP DATABASE 语句,那使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除!对于 更新压力大的数据库 来说,查询缓存的命中率会非常低。
- 解析器:在解析器中对 SQL 语句进行
语法分析、语义分析。

分析器先做“词法分析”。
你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。 MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语
句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”。
接着,要做“语法分析”。根据词法分析的结果,语法分析器(比如:Bison)会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。
select department_id,job_id,avg(salary) from employees group by department_id;
如果SQL语句正确,则会生成一个这样的语法树:

- 优化器:在优化器中会确定 SQL 语句的执行路径,比如是根据
全表检索,还是根据索引检索等。
举例:如下语句是执行两个表的 join:
select * from test1 join test2 using(ID)
where test1.name='zhangwei' and test2.name='mysql高级课程';
- 方案1:可以先从表 test1 里面取出 name='zhangwei’的记录的 ID 值,再根据 ID 值关联到表 test2
再判断 test2 里面 name的值是否等于 ‘mysql高级课程’。- 方案2:可以先从表 test2 里面取出 name=‘mysql高级课程’ 的记录的 ID 值,再根据 ID 值关联到 test1,再判断 test1 里面 name的值是否等于 zhangwei。这两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案。优化器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段。
在查询优化器中,可以分为 逻辑查询 优化阶段和 物理查询 优化阶段
- 执行器:
截止到现在,还没有真正去读写真实的表,仅仅只是产出了一个执行计划。于是就进入了执行器阶段。
在执行之前需要判断该用户是否具备权限。如果没有,就会返回权限错误。如果具备权限,就执行 SQL查询并返回结果。在 MySQL8.0 以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
select * from test where id=1;
比如:表 test 中,ID 字段没有索引,那么执行器的执行流程是这样的:
调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是1,如果不是则跳过,如果是则将这行存在结果集中;调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
至此,这个语句就执行完成了。对于有索引的表,执行的逻辑也差不多。
SQL 语句在 MySQL 中的流程是:SQL语句→查询缓存→解析器→优化器→执行器。

2、MySQL8中SQL执行原理
profiling 为记录你执行sql的记录
①确认profiling 是否开启
mysql> select @@profiling;
mysql> show variables like 'profiling';
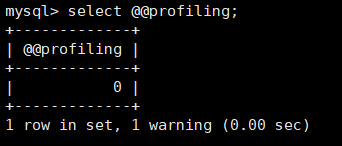
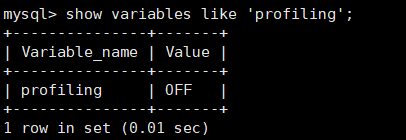
profiling=0 代表关闭,我们需要把 profiling 打开,即设置为 1:
mysql> set profiling=1;
②多次执行相同SQL查询
然后我们执行一个 SQL 查询(你可以执行任何一个 SQL 查询):
mysql> select * from employees;
③查看profiles
查看当前会话所产生的所有 profiles:
mysql> show profiles; # 显示最近的几次查询

④查看profile
显示执行计划,查看程序的执行步骤:
mysql> show profile;

当然你也可以查询指定的 Query ID,比如:
mysql> show profile for query 7;
查询 SQL 的执行时间结果和上面是一样的。
此外,还可以查询更丰富的内容:
mysql> show profile cpu,block io for query 6;
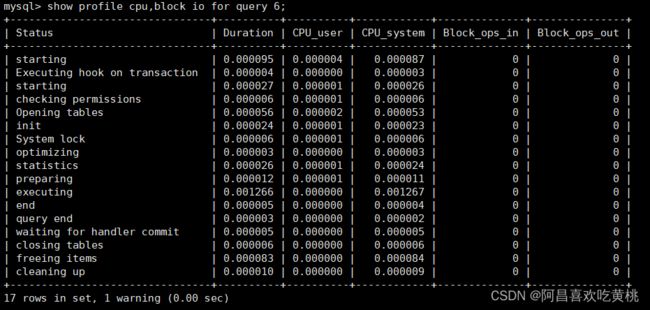
mysql> show profile cpu,block io for query 7;

3、MySQL5.7中SQL执行原理
上述操作在MySQL5.7中测试,发现前后两次相同的sql语句,执行的查询过程仍然是相同的。
不是会使用缓存吗?这里我们需要 显式开启查询缓存模式 。在MySQL5.7中如下设置:
① 配置文件中开启查询缓存
在 /etc/my.cnf 中新增一行:
query_cache_type=1
②重启mysql服务
systemctl restart mysqld
③开启查询执行计划
由于重启过服务,需要重新执行如下指令,开启profiling。
mysql> set profiling=1;
④执行语句两次
mysql> select * from locations;
mysql> select * from locations;
⑤查看profiles

⑥查看profile
显示执行计划,查看程序的执行步骤:
mysql> show profile for query 1;

mysql> show profile for query 2;

结论不言而喻。执行编号2时,比执行编号1时少了很多信息,从截图中可以看出查询语句直接从缓存中获取数据。
4、SQL语法顺序
随着Mysql版本的更新换代,其优化器也在不断的升级,优化器会分析不同执行顺序产生的性能消耗不同而动态调整执行顺序。
需求:查询每个部门年龄高于20岁的人数且高于20岁人数不能少于2人,显示人数最多的第一名部门信息
下面是经常出现的查询顺序:

5、Oracle中的SQL执行流程(了解)
Oracle 中采用了共享池 来判断 SQL 语句是否存在缓存和执行计划,通过这一步骤我们可以知道应该采用硬解析还是软解析。
我们先来看下 SQL 在 Oracle 中的执行过程:

从上面这张图中可以看出,SQL 语句在 Oracle 中经历了以下的几个步骤。
1.语法检查:检查 SQL 拼写是否正确,如果不正确,Oracle 会报语法错误。
2.语义检查:检查 SQL 中的访问对象是否存在。比如我们在写 SELECT 语句的时候,列名写错了,系统就会提示错误。语法检查和语义检查的作用是保证 SQL 语句没有错误。
3.权限检查:看用户是否具备访问该数据的权限。
4.共享池检查:共享池(Shared Pool)是一块内存池,最主要的作用是缓存 SQL 语句和该语句的执行计划。Oracle 通过检查共享池是否存在 SQL 语句的执行计划,来判断进行软解析,还是硬解析。那软解析和硬解析又该怎么理解呢?
在共享池中,Oracle 首先对 SQL 语句进行 Hash 运算 ,然后根据 Hash 值在库缓存(Library Cache)中查找,如果 存在 SQL 语句的执行计划,就直接拿来执行,直接进入“执行器”的环节,这就是 软解析 。
如果没有找到 SQL 语句和执行计划,Oracle 就需要创建解析树进行解析,生成执行计划,进入“优化器”这个步骤,这就是 硬解析 。
5. 优化器:优化器中就是要进行硬解析,也就是决定怎么做,比如创建解析树,生成执行计划。
6. 执行器:当有了解析树和执行计划之后,就知道了 SQL 该怎么被执行,这样就可以在执行器中执
行语句了。
共享池是 Oracle 中的术语,包括了库缓存,数据字典缓冲区等。我们上面已经讲到了库缓存区,它主要
缓存 SQL 语句和执行计划。而 数据字典缓冲区 存储的是 Oracle 中的对象定义,比如表、视图、索引等对象。当对 SQL 语句进行解析的时候,如果需要相关的数据,会从数据字典缓冲区中提取。
库缓存 这一个步骤,决定了 SQL 语句是否需要进行硬解析。为了提升 SQL 的执行效率,我们应该尽量避免硬解析,因为在 SQL 的执行过程中,创建解析树,生成执行计划是很消耗资源的。
你可能会问,如何避免硬解析,尽量使用软解析呢?在 Oracle 中, 绑定变量 是它的一大特色。绑定变量就是在 SQL 语句中使用变量,通过不同的变量取值来改变 SQL 的执行结果。这样做的好处是能 提升软解析的可能性 ,不足之处在于可能会导致生成的执行计划不够优化,因此是否需要绑定变量还需要视情况而定。
举个例子,我们可以使用下面的查询语句:
SQL> select * from player where player_id = 10001;
你也可以使用绑定变量,如:
SQL> select * from player where player_id = :player_id;
这两个查询语句的效率在 Oracle 中是完全不同的。
如果你在查询 player_id = 10001 之后,还会查询10002、10003 之类的数据,那么每一次查询都会创建一个新的查询解析。而第二种方式使用了绑定变量,那么在第一次查询之后,在共享池中就会存在这类查询的执行计划,也就是软解析。
因此,我们可以通过使用绑定变量来减少硬解析,减少 Oracle 的解析工作量。但是这种方式也有缺点,使用动态 SQL 的方式,因为参数不同,会导致 SQL 的执行效率不同,同时 SQL 优化也会比较困难。
Oracle的架构图:

小结:
Oracle 和 MySQL 在进行 SQL 的查询上面有软件实现层面的差异。Oracle 提出了共享池的概念,通共享池来判断是进行软解析,还是硬解析。
三、数据库缓冲池(buffer pool)
InnoDB 存储引擎是以页为单位来管理存储空间的,我们进行的增删改查操作其实本质上都是在访问页
面(包括读页面、写页面、创建新页面等操作)。而磁盘 I/O 需要消耗的时间很多,而在内存中进行操
作,效率则会高很多,为了能让数据表或者索引中的数据随时被我们所用,DBMS 会申请 占用内存来作为数据缓冲池 ,在真正访问页面之前,需要把在磁盘上的页缓存到内存中的 Buffer Pool之后才可以访问。
这样做的好处是可以让磁盘活动最小化,从而 减少与磁盘直接进行 I/O 的时间 。
要知道,这种策略对提升 SQL 语句的查询性能来说至关重要。如果索引的数据在缓冲池里,那么访问的成本就会降低很多。
1、缓冲池 vs 查询缓存
缓冲池和查询缓存是一个东西吗?不是。
①缓冲池(Buffer Pool)
首先我们需要了解在 InnoDB 存储引擎中,缓冲池都包括了哪些。
在 InnoDB 存储引擎中有一部分数据会放到内存中,缓冲池则占了这部分内存的大部分,它用来存储各种数据的缓存,如下图所示:

从图中,你能看到 InnoDB 缓冲池包括了数据页、索引页、插入缓冲、锁信息、自适应 Hash 和数据字典信息等。
缓存池的重要性:
缓存原则:
“ 位置 * 频次 ”这个原则,可以帮我们对 I/O 访问效率进行优化。
首先,位置决定效率,提供缓冲池就是为了在内存中可以直接访问数据。
其次,频次决定优先级顺序。因为缓冲池的大小是有限的,比如磁盘有 200G,但是内存只有 16G,缓冲池大小只有 1G,就无法将所有数据都加载到缓冲池里,这时就涉及到优先级顺序,会 优先对使用频次高的热数据进行加载 。
缓冲池的预读特性:
②查询缓存
那么什么是查询缓存呢?
查询缓存是提前把 查询结果缓存 起来,这样下次不需要执行就可以直接拿到结果。需要说明的是,在MySQL 中的查询缓存,不是缓存查询计划,而是查询对应的结果。
因为命中条件苛刻,而且只要数据表发生变化,查询缓存就会失效,因此命中率低。
2、缓冲池如何读取数据
缓冲池管理器会尽量将经常使用的数据保存起来,在数据库进行页面读操作的时候,首先会判断该页面是否在缓冲池中,如果存在就直接读取,如果不存在,就会通过内存或磁盘将页面存放到缓冲池中再进行读取。缓存在数据库中的结构和作用如下图所示:
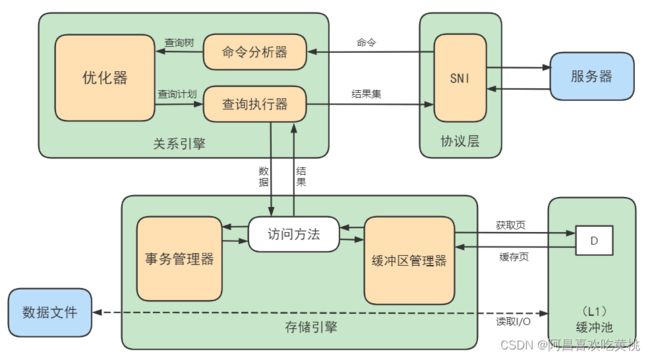
如果我们执行 SQL 语句的时候更新了缓存池中的数据,那么这些数据会马上同步到磁盘上吗?
3、 查看/设置缓冲池的大小
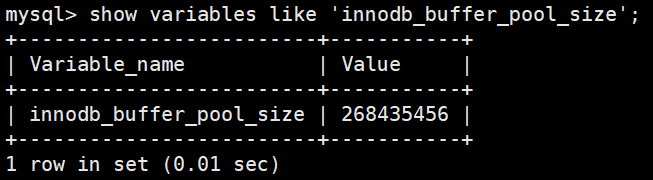
如果你使用的是 InnoDB 存储引擎,可以通过查看 innodb_buffer_pool_size 变量来查看缓冲池的大小。命令如下:
show variables like 'innodb_buffer_pool_size';

你能看到此时 InnoDB 的缓冲池大小只有 134217728/1024/1024=128MB。我们可以修改缓冲池大小,比如改为256MB,方法如下:
set global innodb_buffer_pool_size = 268435456;

或者配置文件:
[server]
innodb_buffer_pool_size = 268435456
然后再来看下修改后的缓冲池大小,此时已成功修改成了 256 MB:
4、多个Buffer Pool实例(缓冲池)
[server]
innodb_buffer_pool_instances = 2
这样就表明我们要创建2个 Buffer Pool实例。
我们看下如何查看缓冲池的个数,使用命令:
show variables like 'innodb_buffer_pool_instances';

那每个 Buffer Pool 实例实际占多少内存空间呢?其实使用这个公式算出来的:
innodb_buffer_pool_size/innodb_buffer_pool_instances
也就是总共的大小除以实例的个数,结果就是每个Buffer Pool实例占用的大小。
5、引申问题
Buffer Pool是MySQL内存结构中十分核心的一个组成,你可以先把它想象成一个黑盒子。
黑盒下的更新数据流程
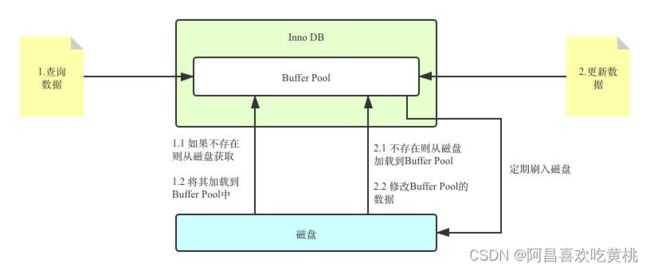
我更新到一半突然发生错误了,想要回滚到更新之前的版本,该怎么办?
连数据持久化的保证、事务回滚都做不到还谈什么崩溃恢复?
答案:Redo Log & Undo Log