【C++ Primer Plus】第8章 函数探幽
8.1 内联函数
内联函数的运行速度比常规函数稍快,但代价是需要占用更多内存。
要使用这项特性,必须采取下述措施之一:
- 在函数声明前加上关键字inline;
- 在函数定义前加上关键字inline。
// 内联函数,按值传递
#include 8.2 引用变量
- 引用是已定义的变量的别名(另一个名称)。
- 通过将引用变量用作参数,函数将使用原始数据,而不是其副本。
- 这样除指针之外,引用也为函数处理大型结构提供了一种非常方便的途径,同时对于设计类来说,引用也是必不可少的。
8.2.1 创建引用变量
int rats;
int & rodents = rats; // makes rodents an alias for rats
- 其中,&不是地址运算符,而是类型标识符的一部分。
- 就像声明中 的char*指的是指向char的指针一样,int &指的是指向int的引用。
- 上述引用声明允许将rats和rodents互换——它们指向相同的值和内存单元。
// 引用变量
#include out:
a = 10, b = 10, *pa = 10
&a = 0xf091ff614, &b = 0xf091ff614, pa = 0xf091ff614
a = 11, b = 11, *pa = 11
&a = 0xf091ff614, &b = 0xf091ff614, pa = 0xf091ff614
a = 12, b = 12, *pa = 12
&a = 0xf091ff614, &b = 0xf091ff614, pa = 0xf091ff614
可以通过初始化声明来设置引用,但不能通过赋值来设置。
int rats = 101;
int * pt = &rats;
int & rodents = *pt; // 将rodents初始化为*pt使得rodents指向rats。
int bunnies = 50;
pt = &bunnies; // 将pt改为指向bunnies,此时rodents引用的还是rats。
8.2.2 将引用用作函数参数
按引用传递允许被调用的函数能够访问调用函数中的变量。

按指针传递、按引用传递、按值传递,外在区别是声明函数参数的方式不同:
void swapp(int * p, int * q); // 按指针传递,调用函数时传递的是变量地址
void swapr(int & a, int & b); // 按引用传递,调用函数时传递的是变量本身
void swapv(int a, int b); // 按值传递,调用函数时传递的是变量副本
如果程序员的意图是让函数使用传递给它的信息,而不对这些信息进行修改,同时又想使用引用,则应使用常量引用。
double refcube(const double &ra);
传递引用的限制更严格。毕竟,如果ra是一个变量的别名,则实参应是该变量,不能是一个表达式或实数。
对于形参为const引用的C++函数,如果实参不匹配,则其行为类似于按值传递,为确保原始数据不被修改,将使用临时变量来存储值。
如果引用参数是const,则编译器将在下面两种情况下生成临时变量:
- 实参的类型正确,但不是左值;
- 实参的类型不正确,但可以转换为正确的类型。
如果函数调用的参数不是左值或与相应的const引用参数的类型不匹配,则C++将创建类型正确的匿名变量,将函数调用的参数的值传递给该匿名变量,并让参数来引用该变量。
左值是什么呢?
左值参数是可被引用的数据对象,例如,变量、数 组元素、结构成员、引用和解除引用的指针都是左值。非左值包括字面 常量(用引号括起的字符串除外,它们由其地址表示)和包含多项的表 达式。在C语言中,左值最初指的是可出现在赋值语句左边的实体,但 这是引入关键字const之前的情况。现在,常规变量和const变量都可视 为左值,因为可通过地址访问它们。但常规变量属于可修改的左值,而 const变量属于不可修改的左值。
应尽可能将引用形参声明为const:
- 使用const可以避免无意中修改数据的编程错误;
- 使用const使函数能够处理const和非const实参,否则将只能接受非const数据;
- 使用const引用使函数能够正确生成并使用临时变量。
8.2.4 将引用用于结构
使用结构引用参数的方式与使用基本变量引用相同,只需在声明结构参数时使用引用运算符&即可。
struct free_throws
{
std::string name;
int made;
int attempts;
float percent;
};
free_throws one = {"Ifelsa Branch", 13, 14}; // 结构初始化时,如果指定的初始值比成员少,余下的成员(这里只有percent)将被设置为零。
free_throws two, three, four, five, dup;
void set_pc(free_throws & ft); // 在函数中将指向该结构的引用作为参数
void display(const free_throws & ft); // 不希望函数修改传入的结构,可使用const
free_throws & accumulate(free_throws & target, const free_throws & source); // 返回也是引用,返回引用的函数实际上是被引用的变量的别名。
accumulate(dup,five) = four; // 首先将five的数据添加到dup中,再使用four的内容覆盖dup的内容。
// 假设您要使用引用返回值,但又不允许执行像给accumulate()赋值 这样的操作,只需将返回类型声明为const引用:
const free_throws & accumulate(free_throws & target, const free_throws & source);
display(accumulate(team, two));
为何要返回引用?
double m = sqrt(16.0);在第一条语句中,值4.0被复制到一个临时位置,然后被复制给m。cout << sqrt(25.0);在第二条语句中,值5.0被复制到一个临时位置,然后被传递给cout。dup = accumulate(team,five);如果accumulate()返回一个结构,而不是指向结构的引用,将把整 个结构复制到一个临时位置,再将这个拷贝复制给dup。但在返回值为引用时,将直接把team复制到dup,其效率更高。- 返回引用的函数实际上是被引用的变量的别名。
返回引用时最重要的一点是,应避免返回函数终止时不再存在的内存单元引用。 为避免这种问题,最简单的方法是,返回一个作为参数传递给函数的引用。作为参数的引用将指向调用函数使用的数据,因此返回的引用也将指向这些数据。
8.2.5 将引用用于类对象
如果形参类型为const string &,在调用函数时,使用的实参可以是 string对象或C-风格字符串,如用引号括起的字符串字面量、以空字符结尾的char数组或指向 char的指针变量。
string input = "happy";
string version1(const string & s1, const string & s2)
{
string temp;
temp = s2 + s1 + s2;
return temp;
}
// temp是一个新的string对象,只在函数version1( )中有效,该函数执行完毕后,它将不再存在。因此,返回指向temp的引用不可行。
// 该函数的返回类型为string,这意味着temp的内容将被复制到一个临时存储单元中,
// 然后在main( )中,该存储单元的内容被复制到一个名为 result 的string中:
string result = version1(input, "***"); // 实参(input和“***”)的类型分别是string和const char *。
version1()函数实参和形参类型不一致但是程序可以运行的原因:
- 首先,string类定义了一种char *到string的转换功能,这使得可以使用C-风格字符串来初始化string对象。
- 其次,本章前面讨论过的类型为const引用的形参的一 个属性。假设实参的类型与引用参数类型不匹配,但可被转换为引用类型,程序将创建一个正确类型的临时变量,使用转换后的实参值来初始化它,然后传递一个指向该临时变量的引用。
8.2.6 对象、继承和引用
使得能够将特性从一个类传递给另一个类的语言特性被称为继承。
ostream是基类(因为ofstream是建立在它的基础之上的),而ofstream是派生类 (因为它是从ostream派生而来的)。
- 派生类继承了基类的方法,这意味着ofstream对象可以使用基类的特性,如格式化方法precision( )和setf( )。
- 基类引用可以指向派生类对象,而无需进行强制类型转换。 例如,参数类型为ostream &的函数可以接受ostream对象(如cout)或您声明的ofstream对象作为参数。
ostream中的格式化方法:
- 方法setf( )让您能够设置各种格式化状态。
setf(ios_base::fixed); // 将对象置于使用定点表示法的模式;
setf(ios_base::showpoint); // 将对象置于显示小数点的模式,即使小数部分为零。
- 方法precision( )指定显示多少位小数(假定对象处于定点模式下)
- 以上两种设置都将一直保持不变,直到再次调用相应的方法重新设置它们。
- 方法width( )设置下一次输出操作使用的字段宽度,这种设置只在显示下一个值时有效,然后将恢复到默认设置。默认的字段宽度为零,这意味着刚好能容纳下要显示的内容。
// 通过调用同一个函数(只有函数调用参数不同)将数据写入文件和显示到屏幕上
// 该程序要求用户输入望远镜物镜和一些目镜的焦距,然后计算并显示每个目镜的放大倍数。
// 放大倍数等于物镜的焦距除以目镜的焦距,因此计算起来很简单。
#include out:
Focal length of objective: 1800 mm
f.l. eyepiece magnification
1.0 1800
2.0 900
3.0 600
34.0 53
4.0 450
8.2.7 何时使用引用参数
使用引用参数的主要原因有两个:
- 程序员能够修改调用函数中的数据对象。
- 通过传递引用而不是整个数据对象,可以提高程序的运行速度。
对于使用传递的值而不作修改的函数:
- 如果数据对象很小,如内置数据类型或小型结构,则按值传递。
- 如果数据对象是数组,则使用指针,因为这是唯一的选择,并将指针声明为指向const的指针。
- 如果数据对象是较大的结构,则使用const指针或const引用,以提高程序的效率。这样可以节省复制结构所需的时间和空间。
- 如果数据对象是类对象,则使用const引用。类设计的语义常常要求使用引用,这是C++新增这项特性的主要原因。因此,传递类对象参数的标准方式是按引用传递。
对于修改调用函数中数据的函数:
- 如果数据对象是内置数据类型,则使用指针。
- 如果看到诸如fixit(&x)这样的代码(其中x是int),则很明显,该函数将修改x。
- 如果数据对象是数组,则只能使用指针。
- 如果数据对象是结构,则使用引用或指针。
- 如果数据对象是类对象,则使用引用。
8.3 默认参数
- 如何设置默认值呢?必须通过函数原型。
char * left(const char * str, int n = 1); - 可以只有原型指定了默认值。而函数定义与没有默认参数时完全相同。
- 对于带参数列表的函数,必须从右向左添加默认值。
int harpo(int n, int m = 4, int j = 5); // VALID
// int chico(int n, int m = 6, int j); // INVALID
int groucho(int k = 1, int m = 2, int n = 3); // VALID
char * left(const char * str, int n = 1); // 函数原型
char sample[10];
char * ps = left(sample, 4); // 函数调用
char * pa = left(sample); // 函数调用,此时默认n=1
char * left(const char * str, int n){...} // 函数定义
8.4 函数重载
- 函数多态(函数重载)能够使用多个同名的函数。
- 可以通过函数重载来设计一系列函数——**完成相同的工作,但使用不同的参数列表。**其参数列表也称为函数特征标(function signature)
- C++允许定义名称相同的函数,条件是它们的特征标不同。如果参数数目和/或参数类型不同,则特征标也不同。
- 把类型引用和类型本身视为同一个特征标。
- 匹配函数时,并不区分const和非const变量。将非const值赋给const变量是合法的,但反之则是非法的。
// 不同引用类型的重载:
double x = 55.5;
const double y = 32.0;
stove(x); // calls stove(double &)
stove(y); // calls stove(const double &)
stove(x+y); // calls stove(double &&)
// 如果没有定义函数stove(double &&),stove(x+y)将调用函数stove(const double &)。
// 函数重载 和 默认参数 的使用
// 由于新left( )的特征标不同于旧的left( ),因此可以在同一个程序中使用这两个函数。
#include out:
n = 12345678, trip = Hawaii!!
left(n) = 1
left(n,3) = 123
left(trip,5) = Hawai
名称修饰?
对原始名称进行的表面看来无意义的修饰(或矫正,因人而异)将对参数数目和类型进行编码。添加的一组符号随函数特征标而异,而修饰时使用的约定随编译器而异。
有了名称修饰,C++可以准确的跟踪每一个重载函数。
long MyFunctionFoo(int, float);内部表示为:?MyFunctionFoo@@YAXH
8.5 函数模板
函数模板是通用的函数描述,也就是说,它们使用泛型来定义函数,其中的泛型可用具体的类型(如int或double)替换。通过将类型作为参数传递给模板,可使编译器生成该类型的函数。
template <typename AnyType> // 第一行指出,要建立一个模板,并将类型命名为AnyType。
// 关键字 template 和 typename 是必需的,除非可以使用关键字class代替typename。另外,必须使用尖括号。类型名可以任意选择。
void Swap(AnyType &a, AnyType &b)
{
AnyType temp;
temp = a;
a = b;
b = temp;
}
- 模板并不创建任何函数,而只是告诉编译器如何定义函数。
- 如果需要多个将同一种算法用于不同类型的函数,请使用模板。
- 如果不考虑向后兼容的问题,并愿意键入较长的单词,则声明类型参数时,应使用关键字typename而不使用class。
- 在文件的开始位置提供模板函数的原型,并在main( )后面提供模板函数的定义。
- 函数模板不能缩短可执行程序。使用模板的好处是,它使生成多个函数定义更简单、更可靠。
// 函数模板的定义和使用
#include out:
i, j = 10, 20.
Using compiler-generated int swapper:
Now i, j = 20, 10.
x, y = 24.5, 81.7.
Using compiler-generated double swapper:
Now x, y = 81.7, 24.5.
8.5.3 显式具体化
为特定类型提供具体化的模板定义,即具体化函数定义——称为显式具体化(explicit specialization),其中包含所需的代码。
- 对于给定的函数名,可以有非模板函数、模板函数和显式具体化模板函数以及它们的重载版本。
- 显式具体化的原型和定义应以
template<>打头,并通过名称来指出类型。 - 具体化优先于常规模板,而非模板函数优先于具体化和常规模板。 当编译器找到与函数调用匹配的具体化定义时,将使用该定义,而不再寻找模板。
// 下面是用于交换job结构的非模板函数、模板函数和具体化的原型:
struct job
{
char name[40];
double salary;
int floor;
};
void Swap(job &, job &); // non template function prototype
template <typename T>
void Swap(T &, T &); // template prototype
template <> void Swap<job>(job &, job &); // explicit specialization for the job type
在下面的代码中,第一次调用Swap( )时使用通用版本,隐式实例化。而第二次调用使用基于job类型的显式具体化版本。
struct job
{
char name[40];
double salary;
int floor;
};
template <class T> // template
void Swap(T &, T &);
template <> void Swap<job>(job &, job &); // explicit specialization for the job type
int main()
{
double u, v;
...
Swap(u,v); // 隐式实例化:第一次调用Swap( )时使用通用版本
job a, b;
...
Swap(a,b); // 显示具体化:第二次调用使用基于job类型的显式具体化版本 void Swap(job &, job &)
}
8.5.4 实例化和具体化
- 在代码中包含函数模板本身并不会生成函数定义,它只是一个用于生成函数定义的方案。
- 编译器使用模板为特定类型生成函数定义时,得到的是模板实例(instantiation)。
- 隐式实例化、显式实例化和显式具体化统称为具体化(specialization)。
- 它们的相同之处在于,它们表示的都是使用具体类型的函数定义,而不是通用描述(模板定义)。
- 隐式实例化
template <class T>
void Swap (T &, T &); // 模板原型
int i, j;
Swap(i, j); // 隐式实例化
// 函数调用Swap(i, j)导致编译器生成Swap( )的一个实例,该实例使用int类型。
// 模板并非函数定义,但使用int的模板实例是函数定义。
// 因为编译器之所以知道需要进行定义,是由于程序调用Swap( )函数时提供了int参数。
- 显式实例化
template void Swap<int>(int, int); // explicit instantiation
- 显式具体化
template <> void Swap<int>(int &, int &); // explicit specialization
template <> void Swap(int &, int &); // explicit specialization
...
template <class T>
void Swap (T &, T &); // template prototype
template <> void Swap<job>(job &, job &); // explicit specialization for job
int main(void)
{
...
template void Swap<char>(char &, char &); // 显式实例化 for char
short a, b;
...
Swap(a,b); // 隐式实例化
job n, m;
...
Swap(n, m); // 显式具体化:使用为job类型提供的独立定义
char g, h;
...
Swap(g, h); // 使用处理显式实例化时生成的模板具体化
...
}
8.5.5 编译器选择使用哪个函数版本
- 第1步:创建候选函数列表。其中包含与被调用函数的名称相同的函数和模板函数。
- 第2步:使用候选函数列表创建可行函数列表。这些都是参数数目正确的函数,为此有一个隐式转换序列,其中包括实参类型与相应的形参类型完全匹配的情况。例如,使用float参数的函数调用可以将该参数转换为double,从而与double形参匹配,而模板可以为float生成一个实例。
- 第3步:确定是否有最佳的可行函数。如果有,则使用它,否则该函数调用出错。
从最佳到最差的顺序如下所述:
- 先只考虑特征标,而不考虑返回类型。(一些参数因为无法隐式转换排除掉,如整数类型不能被隐式地转换为指针类型。)
- 完全匹配,但常规函数优先于模板。
- 提升转换(例如,char和shorts自动转换为int,float自动转换为double)。
- 标准转换(例如,int转换为char,long转换为double)。
- 用户定义的转换,如类声明中定义的转换。
struct blot {int a; char b[10];};
blot ink = {25, "spots"};
...
recycle(ink);
// 下面的原型都是完全匹配的:
void recycle(blot); // #1 blot-to-blot
void recycle(const blot); // #2 blot-to-(const blot)
void recycle(blot &); // #3 blot-to-(blot &)
void recycle(const blot &); // #4 blot-to-(const blot &)

8.5.6 关键字decltype(C++11)
decltype(expression) var; // make var the same type as expression
decltype(x + y) xpy; // make xpy the same type as x + y
xpy = x + y;
// 合并为一条语句:
decltype(x + y) xpy = x + y;
// 第一步:如果expression是一个没有用括号括起的标识符,则var的类型与该标识符的类型相同,包括const等限定符:
double x = 5.5;
double y = 7.9;
double &rx = x;
const double * pd;
decltype(x) w; // w is type double
decltype(rx) u = y; // u is type double &
decltype(pd) v; // v is type const double *
// 第二步:如果expression是一个函数调用,则var的类型与函数的返回类型相同:
long indeed(int);
decltype (indeed(3)) m; // m is type long
// 第三步:如果expression是一个左值(是用括号括起的标识符),则var为指向其类型的引用。
double xx = 4.4;
decltype((xx)) r2 = xx; // r2 is double &
decltype(xx) w = xx; // w is double (Stage 1 match)
// 第四步:如果前面的条件都不满足,则var的类型与expression的类型相同:
int j = 3;
int &k = j
int &n = j;
decltype(j+6) i1; // i1 type int
decltype(100L) i2; // i2 type long
decltype(k+n) i3; // i3 type int; 虽然k和n都是引用,但表达式k+n不是引用;它是两个int 的和,因此类型为int。
C++11后置返回类型:
- 什么时候用?无法预先知道将x和y相加得到的类型。好像可以将返回类型设置为decltype ( x + y),但不幸的是,此时还未声明参数x和y,它们不在作用域内(编译器看不到它们,也无法使用它们)。必须在声明参数后才能使用decltype。
- 后置返回中auto是一个占位符,表示后置返回类型提供的类型。
// 无法预先知道将x和y相加得到的类型。
// 此时还未声明参数x和y,它们不在作用域内(编译器看不到它们,也无法使用它们)。
// 必须在声明参数后使用decltype。
template<class T1, class T2>
auto gt(T1 x, T2 y) -> decltype(x + y) // decltype在参数声明后面,因此x和y位于作用域内
{
...
return x + y;
}
8.6 总结
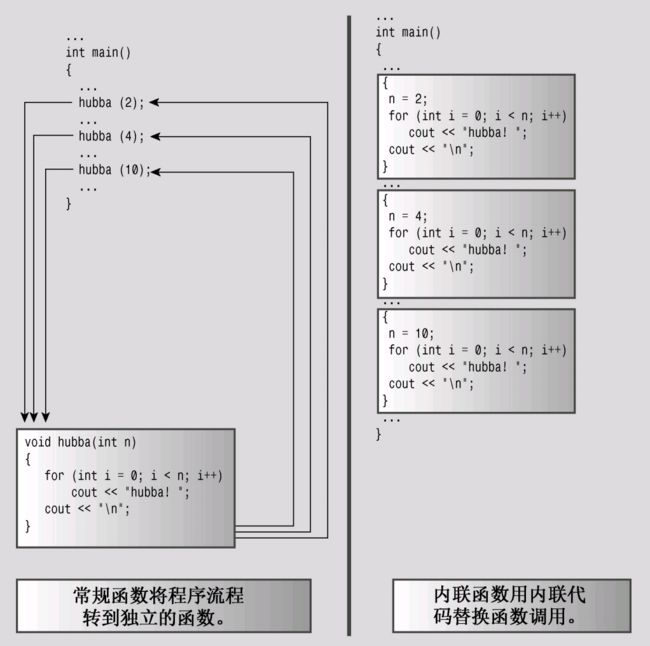
- C++扩展了C语言的函数功能。通过将inline关键字用于函数定义,并在首次调用该函数前提供其函数定义,可以使得C++编译器将该函数视为内联函数。也就是说,编译器不是让程序跳到独立的代码段,以执行函数,而是用相应的代码替换函数调用。只有在函数很短时才能采用内联方式。
- 引用变量是一种伪装指针,它允许为变量创建别名(另一个名称)。引用变量主要被用作处理结构和类对象的函数的参数。通常,被声明为特定类型引用的标识符只能指向这种类型的数据;然而,如果一个类(如ofstream)是从另一个类(如ostream)派生出来的,则基类引用可以指向派生类对象。
- C++原型让您能够定义参数的默认值。如果函数调用省略了相应的参数,则程序将使用默认值;如果函数调用提供了参数值,则程序将使用这个值(而不是默认值)。只能在参数列表中从右到左提供默认参数。因此,如果为某个参数提供了默认值,则必须为该参数右边所有的参数提供默认值。
- 函数的特征标是其参数列表。程序员可以定义两个同名函数,只要其特征标不同。这被称为函数多态或函数重载。通常,通过重载函数来为不同的数据类型提供相同的服务。
- 函数模板自动完成重载函数的过程。只需使用泛型和具体算法来定义函数,编译器将为程序中使用的特定参数类型生成正确的函数定义。
- 具体化优先于常规模板,而非模板函数优先于具体化和常规模板。非模板函数 > 具体化 > 常规模板
8.7 复习题
- 哪种函数适合定义为内联函数?
内联函数的代码量一定要小,内联函数不能出现递归。 - 假设song( )函数的原型如下:
void song(const char * name, int times);
a.如何修改原型,使times的默认值为1?
b.函数定义需要做哪些修改?
c.能否为name提供默认值“O. My Papa”?可以,但是此时times也要设置成默认值,因为对于带参数列表的函数,必须从右向左添加默认值。void song(const char * name = "O. My Papa", int times = 1); - 编写iquote( )的重载版本——显示其用双引号括起的参数。编写3个版本:一个用于int参数,一个用于double参数,另一个用于string参数。
void iquote(int n){std::cout << "\"" << n << "\"\n";}
void iquote(double n){std::cout << "\"" << n << "\"\n";}
void iquote(string n){std::cout << "\"" << n << "\"\n";}
- 指出下面每个目标是否可以使用默认参数或函数重载完成,或者这两种方法都无法完成,并提供合适的原型。
- a. mass(density, volume)返回密度为density、体积为volume的物体的质量,而mass(denstity)返回密度为density、体积为1.0立方米的物体的质量。这些值的类型都为double。
默认参数double mass(double density, double volume = 1.0);
函数重载double mass(double density, double volume);和double mass(double density); - b. repeat(10, “I’m OK”)将指定的字符串显示10次,而repeat(“But you’re kind of stupid”)将指定的字符串显示5次。
不能使用默认参数,因为左侧的参数需要设置成次数,而右侧也必须是一个默认值;
函数重载void repeat(int n, const char *str);和void repeat(const char *str); - c. average(3, 6)返回两个int参数的平均值(int类型),而average(3.0, 6.0)返回两个double值的平均值(double类型)。
可以使用函数模板和函数重载。 - d. mangle(“I’m glad to meet you”)根据是将值赋给char变量还是char* 变量,分别返回字符I和指向字符串“I’m glad to meet you”的指针。
参数都是一个字符串指针,形参都是一样的,不能函数重载。
- a. mass(density, volume)返回密度为density、体积为volume的物体的质量,而mass(denstity)返回密度为density、体积为1.0立方米的物体的质量。这些值的类型都为double。
- 编写返回两个参数中较大值的函数模板。
template <typename AnyType>
AnyType Max(AnyType x, AnyType y)
{
if (x > y)
return x;
else
return y;
// return x > y ? x : y;
}
- 给定复习题7的模板和复习题4的box结构,提供一个模板具体化,它接受两个box参数,并返回体积较大的一个。
struct box
{
char maker[40];
float height;
float width;
float length;
float volume;
};
template <typename AnyType>
AnyType Max(AnyType x, AnyType y)
{
return x > y ? x : y;
}
template <> box Max<box>(box b1, box b2)
{
return b1.volume > b2.volume ? b1 : b2;
}
- 在下述代码(假定这些代码是一个完整程序的一部分)中,v1、v2、v3、v4和v5分别是哪种类型?
int g(int x);
...
float m = 5.5f;
float & rm = m;
decltype(m) v1 = m; // float, v1由m决定
decltype(rm) v2 = m; // float &
decltype((m)) v3 = m; // float &
decltype (g(100)) v4; // int
decltype (2.0 * m) v5; // double, 2.0是double
8.8 编程练习
// 1.编写通常接受一个参数(字符串的地址),并打印该字符串的函数。
// 然而,如果提供了第二个参数(int类型),且该参数不为0,
// 则该函数打印字符串的次数将为该函数被调用的次数
// (注意,字符串的打印次数不等于第二个参数的值,而等于函数被调用的次数)。
#include // 2.CandyBar结构包含3个成员。
// 第一个成员存储candy bar的品牌名称;第二个成员存储candy bar的重量(可能有小数);第三个成员存储 candy bar的热量(整数)。
// 请编写一个程序,它使用一个这样的函数,即将CandyBar的引用、char指针、double和int作为参数,并用最后3个值设置相应的结构成员。
// 最后3个参数的默认值分别为“Millennium Munch”、2.85和350。
// 另外,该程序还包含一个以CandyBar的引用为参数,并显示结构内容的函数。
// 请尽可能使用const。
#include // 3.编写一个函数,它接受一个指向string对象的引用作为参数,并将该string对象的内容转换为大写,为此可使用表6.4描述的函数toupper( )。
// 然后编写一个程序,它通过使用一个循环让您能够用不同的输入来测试这个函数,该程序的运行情况如下:
#include // 4.请提供其中描述的函数和原型,从而完成该程序。
// 注意,应有两个 show( )函数,每个都使用默认参数。请尽可能使用cosnt参数。
// set( )使用 new分配足够的空间来存储指定的字符串。这里使用的技术与设计和实现类时使用的相似。
#include // 6.编写模板函数maxn( ),它将由一个T类型元素组成的数组和一个表示数组元素数目的整数作为参数,并返回数组中最大的元素。
// 在程序对它进行测试,该程序使用一个包含6个int元素的数组和一个包含4个 double元素的数组来调用该函数。
// 程序还包含一个具体化,它将char指针数组和数组中的指针数量作为参数,并返回最长的字符串的地址。
// 如果有多个这样的字符串,则返回其中第一个字符串的地址。
// 使用由5个字符串指针组成的数组来测试该具体化。
#include // 7.修改程序清单 8.14,使其使用两个名为 SumArray()的模板函数来返回数组元素的总和,而不是显示数组的内容。
// 程序应显示thing的总和以及所有debt的总和。
#include