Azkaban知识点入门
一 azkaban的简介
1.1 调度系统背景
1. 一个完整的大数据分析系统通常都是由大量任务单元组成:shell脚本程序,mapreduce程序、hive脚本、spark程序等。
2. 各任务单元之间存在时间先后及前后依赖关系:先后关系、依赖关系、定时执行。
3. 为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行。
任务流程图:
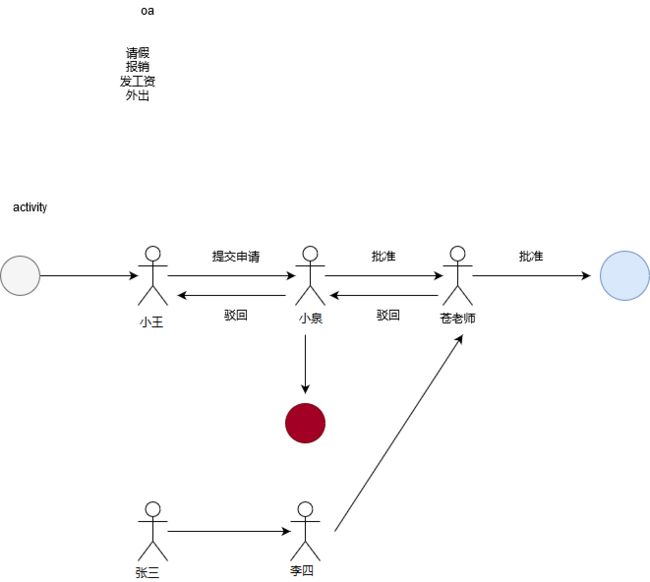
azkaban的作用其实就是将我们搭建数据的流程串联起来,并设置自动定时运行。
官网:https://azkaban.github.io/
Azkaban is a batch workflow job scheduler created at LinkedIn to run Hadoop jobs. Azkaban resolves the ordering through job dependencies and provides an easy to use web user interface to maintain and track your workflows.
1.2 azkaban的特点
兼容Hadoop的任何版本
易于使用的web UI
简单的web和http工作流上传
项目工作区
调度的工作流
模块化和pluginable
身份验证和授权
跟踪用户操作
邮件提醒失败和成功
SLA警报和自动杀死
重新尝试失败的作业
1.3 常见调度系统
简单的任务调度:直接使用linux的crontab来定义、shell和python脚本实现
现成开源任务调度: oozie、azkaban和airflow等
复杂的任务调度:自研调度平台
1.4 azkaban和oozie的比较
azkaban和oozie相对来说是市面上最流行的两种调度器。总体来说,ooize相比azkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器azkaban是很不错的候选对象。具体对比如下:
- 功能
两者均可以调度mapreduce,pig,java,脚本工作流任务
两者均可以定时执行工作流任务
- 工作流定义
Azkaban使用Properties文件定义工作流
Oozie使用XML文件定义工作流
- 工作流传参
Azkaban支持直接传参,例如${input}
Oozie支持参数和EL表达式,例如${fs:dirSize(myInputDir)}
- 定时执行
Azkaban的定时执行任务是基于时间的
Oozie的定时执行任务基于时间和输入数据
- 资源管理
Azkaban有较严格的权限控制,如用户对工作流进行读/写/执行等操作
Oozie暂无严格的权限控制
- 工作流执行
Azkaban有两种运行模式,分别是solo server mode(executor server和web server部署在同一台节点)和multi server mode(executor server和web server可以部署在不同节点)
Oozie作为工作流服务器运行,支持多用户和多工作流
- 工作流管理
Azkaban支持浏览器以及ajax方式操作工作流
Oozie支持命令行、HTTP REST、Java API、浏览器操作工作流
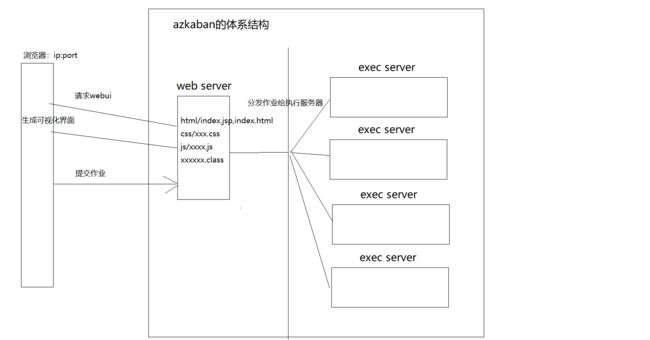
1.5 Azkaban的系统架构
主要由三个组件组成:
- WebServer :暴露Restful API,提供分发作业和调度作业功能;
- ExecServer :对WebServer 暴露 API ,提供执行作业的功能;
- MySQL :数据存储,实现Web 和 Exec之间的数据共享和部分状态的同步。
二 azkaban的安装方式
2.1 源码安装(网速的好的试试)
1、下载源码包
官网地址为:https://github.com/azkaban/azkaban/archive/3.57.0.tar.gz
2、将源码包上传服务器并解压源码包
[root@qianfeng01 home]# tar -zxvf /home/azkaban-3.57.0.tar.gz -C /home/
3、执行编译
编译参考官网地址:https://azkaban.readthedocs.io/en/latest/getStarted.html#building-from-source
- 清空编译
[root@qianfeng01 home]# cd ./azkaban-3.57.0
[root@qianfeng01 home]# ./gradlew clean
结果如下:
- 编译并安装插件
root@qianfeng01 home]# ./gradlew installDist
结果如下:
- 编译但不运行测试
root@qianfeng01 home]# ./gradlew build -x test
编译结果如下:
到此为止编译成功。
4、编译成功后,在根目录下{azkaban-solo-server、azkaban-web-server、azkaban-exec-server}/build/distributions目录下都会生成相应的压缩包,并将其copy到/home/azkaban3.57.0目录下用于安装使用。
[root@qianfeng01 azkaban-3.57.0]# mkdir /home/azkaban3.57.0
[root@qianfeng01 azkaban-3.57.0]# cp ./azkaban-exec-server/build/distributions/azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz /home/azkaban3.57.0
[root@qianfeng01 azkaban-3.57.0]# cp ./azkaban-solo-server/build/distributions/azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz /home/azkaban3.57.0
[root@qianfeng01 azkaban-3.57.0]# cp ./azkaban-web-server/build/distributions/azkaban-web-server-0.1.0-SNAPSHOT.tar.gz /home/azkaban3.57.0
[root@qianfeng01 azkaban-3.57.0]# cp ./azkaban-db/build/distributions/azkaban-db-0.1.0-SNAPSHOT.tar.gz /home/azkaban3.57.0
注意:
编译过程中,如有错误,需要再次运行编译命令。
编译过程中,如果包不能下载,则可以考虑手动下载放到服务器对应的位置即可。
2.2 Solo Server安装
2.2.1 Solo Server简介
这种Solo Server服务是azkaban的单机版,即是单实例,它安装简单,便于学习。他的优点如下:
- 安装简单:不需要mysql实例,它内置h2来做存储。
- 启动简单:web server和executor server都运行在相同进程中。
- 功能齐全:它包含所有azkaban的特征。你可以使用azkaban用这种通用方法并为其安装插件。
2.2.2 安装步骤
1)找到azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz包,上传到linux,并解压到/usr/local/
[root@qianfeng01 azkaban3.57.0]# tar -zxvf azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz -C /usr/local
2)更名操作
[root@qianfeng01 local]# mv azkaban-solo-server-0.1.0-SNAPSHOT/ azkaban-solo
3)配置环境变量
[root@qianfeng01 local]# vi /etc/profile
......省略.........
export AZKABAN_SOLO=/usr/local/azkaban-solo
export PATH=$AZKABAN_SOLO/bin:$PATH
[root@qianfeng01 local]# source /etc/profile
4)配置用户
[root@qianfeng01 azkaban-solo]# vi ./conf/azkaban-users.xml
在第4行添加内容如下:
<user password="admin" roles="metrics,admin" username="admin"/>
到此为止,soloserver的安装配置完成。
5)启动azkaban
[root@qianfeng01 azkaban-solo]# start-solo.sh
如果没有配置环境变量
[root@qianfeng01 azkaban-solo]# ./bin/start-solo.sh
注意:启动azkaban必须在bin的父目录,也就是家里启动。
2.2.3 测试
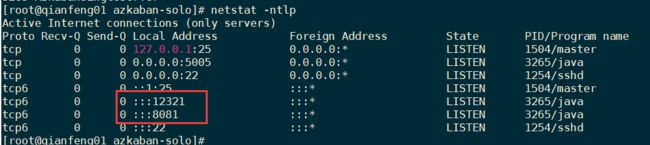
1)查看azkaban的端口号:web-server的port是8081, exec-server的port是12321
2)访问webui
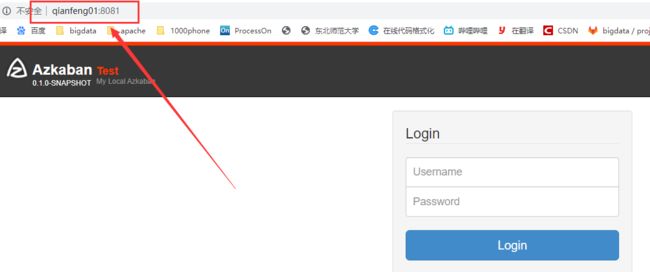
出现此页面,说明安装成功
2.3 Multi exec Server 安装
2.3.1 服务规划
qianfeng01 web server
qianfeng02 exec server
qianfeng03 exec server
2.3.2 mysql中配置azkaban的元数据库
1)解压azkaban-db-0.1.0-SNAPSHOT.tar.gz
[root@qianfeng01 ~]# tar -zxvf azkaban-db-0.1.0-SNAPSHOT.tar.gz

2)找到create-all脚本
找到上图所示脚本文件:create-all-sql-0.1.0-SNAPSHOT.sql 传到有mysql数据库的机器qianfeng03上
[root@qianfeng01 azkaban-db-0.1.0-SNAPSHOT]# scp create-all-sql-0.1.0-SNAPSHOT.sql qianfeng03:~/
3)加载create-all脚本
在qianfeng03上进入mysql,使用source指令执行脚本
mysql> create database azkaban;
mysql> use azkaban;
mysql> source /root/create-all-sql-0.1.0-SNAPSHOT.sql
注意:一定要对azkaban这个库做远程授权
mysql> grant all privileges on *.* to root@'%' identified by '123123' with grant option;
mysql> show grants for root@'%';
4) 修改mysql的配置
(建议修改,如果在重启服务时,报错,就不要修改了)
[root@qianfeng03 azkaban]# vi /etc/my.cnf
在[mysqld]下添加
max_allowed_packet=1024M
[root@qianfeng03 ~]# systemctl restart mysqld
2.3.3 安装azkaban-web-server
1) 上传并解压
上传azkaban-web-server-0.1.0-SNAPSHOT.tar.gz 到qianfeng01上,并解压
tar -zxvf azkaban-web-server-0.1.0-SNAPSHOT.tar.gz -C /usr/local
2) 更名
mv azkaban-web-server-0.1.0-SNAPSHOT.tar.gz azkaban-web
3) 导入mysql驱动包
进入azkaban-web目录下,创建extlib目录,并上传mysql的驱动jar包
[root@qianfeng01 azkaban-web]# mkdir extlib
[root@qianfeng01 azkaban-web]# cp /usr/local/hive/lib/mysql-connector-java-5.1.28-bin.jar ./extlib/
4) 生成秘钥
[root@qphone01 azkaban-web]# keytool -keystore keystore -alias jetty -genkey -keyalg RSA
输入密钥库口令:
再次输入新口令:
您的名字与姓氏是什么?
[Unknown]:
您的组织单位名称是什么?
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的省/市/自治区名称是什么?
[Unknown]:
该单位的双字母国家/地区代码是什么?
[Unknown]:
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=Unknown是否正确?
[否]: y
输入 <jetty> 的密钥口令
(如果和密钥库口令相同, 按回车):
---除了输入密码,其他直接回车,到问你是否正确时,输入y
5) 配置azkaban.properties
# Azkaban Personalization Settings
azkaban.name=Test
azkaban.label=My Local Azkaban
azkaban.color=#FF3601
azkaban.default.servlet.path=/index
web.resource.dir=/usr/local/azkaban-web/web
default.timezone.id=Asia/Shanghai
# Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager
user.manager.xml.file=/usr/local/azkaban-web/conf/azkaban-users.xml
# Loader for projects
executor.global.properties=/usr/local/azkaban-exec/conf/global.properties
azkaban.project.dir=projects
# Velocity dev mode
velocity.dev.mode=false
# Azkaban Jetty server properties.
jetty.use.ssl=false
jetty.maxThreads=25
jetty.ssl.port=8443
jetty.port=8081
jetty.keystore=keystore
jetty.password=123456
jetty.keypassword=123456
jetty.truststore=keystore
jetty.trustpassword=123456
# Azkaban Executor settings
# mail settings
mail.sender=
mail.host=
# User facing web server configurations used to construct the user facing server URLs. They are useful when there is a reverse proxy between Azkaban web servers and users.
# enduser -> myazkabanhost:443 -> proxy -> localhost:8081
# when this parameters set then these parameters are used to generate email links.
# if these parameters are not set then jetty.hostname, and jetty.port(if ssl configured jetty.ssl.port) are used.
# azkaban.webserver.external_hostname=myazkabanhost.com
# azkaban.webserver.external_ssl_port=443
# azkaban.webserver.external_port=8081
job.failure.email=
job.success.email=
lockdown.create.projects=false
cache.directory=cache
# JMX stats
jetty.connector.stats=true
executor.connector.stats=true
# Azkaban mysql settings by default. Users should configure their own username and password.
database.type=mysql
mysql.port=3306
mysql.host=qianfeng03
mysql.database=azkaban
mysql.user=root
mysql.password=@Mm123456
mysql.numconnections=100
#Multiple Executor
azkaban.use.multiple.executors=true
#azkaban.executorselector.filters=StaticRemainingFlowSize,MinimumFreeMemory,CpuStatus
azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus
azkaban.executorselector.comparator.NumberOfAssignedFlowComparator=1
azkaban.executorselector.comparator.Memory=1
azkaban.executorselector.comparator.LastDispatched=1
azkaban.executorselector.comparator.CpuUsage=1
6) 配置azkaban-users.xml
添加admin用户
<azkaban-users>
<user groups="azkaban" password="azkaban" roles="admin" username="azkaban"/>
<user password="metrics" roles="metrics" username="metrics"/>
<user password="admin" roles="metrics,admin" username="admin"/>
<role name="admin" permissions="ADMIN"/>
<role name="metrics" permissions="METRICS"/>
azkaban-users>
2.3.4 安装azkaban-exec-server
先安装一台qianfeng02,然后scp到qianfeng03
1) 上传并解压 azkaban-exec的安装包
找到azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz,上传并解压
[root@qianfeng02 ~]# tar -zxvf azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz -C /usr/local
2) 更名操作
[root@qianfeng02 ~]# cd /usr/local/
[root@qianfeng02 local]# mv azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz azkaban-exec
3) 加载mysql的驱动包
进入azkaban-exec目录下,创建extlib目录,将mysql的驱动包导入到此目录下
[root@qianfeng02 local]# cd azkaban-exec
[root@qianfeng02 azkaban-exec]# mkdir extlib
4) 修改azkaban.properties
[root@qianfeng02 azkaban-exec]# vi conf/azkaban.properties
修改为下面的内容(注意和你的机器的路径,密码要匹配)
# Azkaban Personalization Settings
azkaban.name=Test
azkaban.label=My Local Azkaban
azkaban.color=#FF3601
azkaban.default.servlet.path=/index
web.resource.dir=/usr/local/azkaban-web/web
default.timezone.id=Asia/Shanghai
# Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager
user.manager.xml.file=/usr/local/azkaban-web/conf/azkaban-users.xml
# Loader for projects
executor.global.properties=/usr/local/azkaban-exec/conf/global.properties
azkaban.project.dir=projects
# Velocity dev mode
velocity.dev.mode=false
# Azkaban Jetty server properties.
jetty.use.ssl=false
jetty.maxThreads=25
jetty.port=8081
# Where the Azkaban web server is located
azkaban.webserver.url=http://qianfeng01:8081
# mail settings
mail.sender=
mail.host=
# User facing web server configurations used to construct the user facing server URLs. They are useful when there is a reverse proxy between Azkaban web servers and users.
# enduser -> myazkabanhost:443 -> proxy -> localhost:8081
# when this parameters set then these parameters are used to generate email links.
# if these parameters are not set then jetty.hostname, and jetty.port(if ssl configured jetty.ssl.port) are used.
# azkaban.webserver.external_hostname=myazkabanhost.com
# azkaban.webserver.external_ssl_port=443
# azkaban.webserver.external_port=8081
job.failure.email=
job.success.email=
lockdown.create.projects=false
cache.directory=cache
# JMX stats
jetty.connector.stats=true
executor.connector.stats=true
# Azkaban plugin settings
azkaban.jobtype.plugin.dir=/usr/local/azkaban-exec/plugins/jobtypes/
# Azkaban mysql settings by default. Users should configure their own username and password.
#azkaban.executorselector.filters=StaticRemainingFlowSize,MinimumFreeMemory,CpuStatus
azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus
database.type=mysql
mysql.port=3306
mysql.host=qianfeng03
mysql.database=azkaban
mysql.user=root
mysql.password=@Mm123456
mysql.numconnections=100
# Azkaban Executor settings
executor.port=12321
executor.maxThreads=50
executor.flow.threads=30
5)修改插件文件
[root@qianfeng02 azkaban-exec]# vi ./plugins/jobtypes/commonprivate.properties
set execute-as-user
execute.as.user=false
memCheck.enabled=false #添加内存检查关闭 ,否则报错不足3G
到此为止,azkaban-exec配置好了,就差qianfeng03了,我们可以scp到另一台机器上
[root@qianfeng02 azkaban-exec]# cd ..
[root@qianfeng02 local]# scp -r azkaban-exec qianfeng03:/usr/local/
6)启动测试(建议先重启虚拟机)
zkaban启动的顺序为,先启动executor,再启动web。否则web工程会因为找不到executor而启动失败。
先启动两个exec
[root@qianfeng02 ~]# cd /usr/local/azkaban-exec
[root@qianfeng02 azkaban-exec]# ./bin/start-exec.sh
[root@qianfeng03 ~]# cd /usr/local/azkaban-exec
[root@qianfeng03 azkaban-exec]# ./bin/start-exec.sh
然后查看元数据表executors
登录你的mysql
查看executors表里的两个active是不是1,如果不是,请修改为1

然后再启动web-server
[root@qianfeng01 ~]# cd /usr/local/azkaban-web
[root@qianfeng01 azkaban-web]# ./bin/start-web.sh
然后开心的启动webui吧,xxxxx:8081
7)注意事项
不过已经帮你们写到前面的安装步骤里了
1、azkaban job Preparing
解决方法:
修改 web-server conf/azkaban.properties 配置。
# execute 主机过滤器配置, 去掉 MinimumFreeMemory
# MinimumFreeMemory 过滤器会检查 executor 主机空余内存是否会大于 6G,如果不足 6G,则 web-server 不会将任务交由该主机执行
azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus
2、 运行job时,azkaban的web后台报错 Free memory amount minus Xmx (2836204 - 0 kb) is less than low mem threshold (3145728 kb), memory request declined
解决方法:
[root@qphone02 executor]# vi ./plugins/jobtypes/commonprivate.properties
# set execute-as-user
execute.as.user=false
memCheck.enabled=false #添加内存检查关闭 ,否则报错不足3G
三 azkaban的flow1.0
1. azkaban的job流文件,后缀是.job
1) type属性 必须赋值
值有:command,java,pig
2. azkaban执行的job必须要提前打包,打包的格式必须是zip格式
3. 流文件里的书写格式:
1)一定要注意行末不要有空格
2)编码集的问题,如果在window上实在不行,可以上传到linux进行zip压缩,然后下载到windows上,再上传到azkaban上
3.1 azkaban的第一个简单案例
1)创建文件helloworld.job,添加一下内容
type=command
command=echo "hello world"
2)打包成zip包
3)上传到azkaban
4)点击运行
绿色:成功
灰色:未运行
蓝色:正在运行
红色:运行失败
3.2 azkaban 调度shell指令
1)创建文件echo.sh
#!/bin/bash
echo "hello nihao" >> /root/0821.log
- 创建文件echo.job
type=command
command=/usr/bin/bash echo.sh
- 打包两个文件到echo.zip里
4)上传,并测试
5)查看linux的/root/下的0821.log文件
3.3 azkaban 调度mapreduce案例
1)创建文件mapreduce.job (建议在linux上做)
type=command
command=/usr/local/hadoop/bin/hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.6.jar wordcount /input /output/01
2)获取一个mapreduce案例的jar包,比如单词统计的案例(可以是我们自定义的)
3)将jar包和mapreduce.job文件进行打包成mapreduce.zip
[root@qianfeng01 ~]# zip -r mymr.zip mapreduce.job hadoop-mapreduce-examples-2.6.0-cdh5.7.6.jar
4)下载到windows上,然后上传到azkaban上进行测试
5)查看hdfs上的目录内容
[root@qianfeng01 ~]# hdfs dfs -cat /output/01/*
3.4 azkaban 设置工作流
1)创建b.sh
#!/bin/bash
echo hello_bbb >/root/b.log
sleep 30s
2)创建jobB.job
type=command
command=/bin/bash b.sh
- 创建a.sh
#!/bin/bash
echo hello_aaa >/root/a.log
- 创建jobA.job
type=command
dependencies=jobB
command=/bin/bash a.sh
- 打包,上传,测试
3.5 azkaban定时任务
1)创建一个sh脚本:testcrond.sh
#!/bin/bash
echo "aaaaa" >>/root/crond.log
2)创建一个job文件:testcrond.job
type=command
command=/usr/bin/bash testcrond.sh
-
打包,上传到azkaban上
-
点击run job 进入页面后,不点击execute, 点击schedule, 可以设置时间
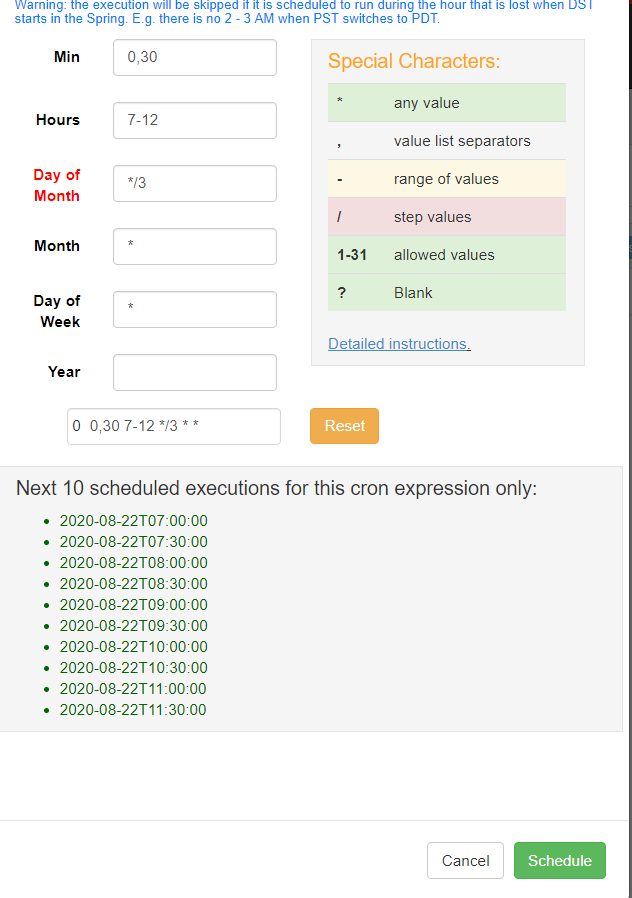
设置完后,点击schedule按钮


3.6 azkaban调度hive脚本
1)创建一个hql脚本:create_table.hql
use ods_db_news;
create table if not exists test1(
sid int,
sname string
)
row format delimited
fields terminated by ',';
2)创建一个job文件:create_table.job
type=command
command=/usr/local/hive/bin/beeline -u jdbc:hive2://qianfeng02:10000 -n root -f create_table.hql
3)打包,上传执行,然后查看吧
四 azkaban的flow2.0
4.1 Flow 2.0 的产生
Azkaban 目前同时支持 Flow 1.0 和 Flow2.0 ,但是官方文档上更推荐使用 Flow 2.0,因为 Flow 1.0 会在将来的版本被移除。Flow 2.0 的主要设计思想是提供 1.0 所没有的流级定义。用户可以将属于给定流的所有 job / properties 文件合并到单个流定义文件中,其内容采用 YAML 语法进行定义,同时还支持在流中再定义流,称为为嵌入流或子流。
4.2 基本结构
项目 zip 将包含多个流 YAML 文件,一个项目 YAML 文件以及可选库和源代码。Flow YAML 文件的基本结构如下:
1. 所有的workflow都是在一个文件里写的
2. 文件以流名称为后缀的,如:my-flow-name.flow;
3. 包含 DAG 中的所有节点;
4. 每个节点可以是不同的类型,比如可以是flow,hive,hadoopjava,pig,noop,command
5. 每个节点可以拥有 name, type, config, dependsOn 和 nodes sections 等属性;
6. 通过列出 dependsOn 指定依赖关系
7. 包含与流相关的其他配置
8. flow1.0里的属性都移植到config下,config下是以键值对的形式书写的。
注意:还需要单独写一个xxxx.project文件指定azkaban使用的是workflow2.0版本
azkaban-flow-version: 2.0
4.3 YAML语法
想要使用 Flow 2.0 进行工作流的配置,首先需要了解 YAML 。YAML 是一种简洁的非标记语言,有着严格的格式要求的,如果你的格式配置失败,上传到 Azkaban 的时候就会抛出解析异常。
4.3.1 基本规则
1. 大小写敏感
2. 使用缩进表示层级关系 ;
3. 缩进长度没有限制,只要元素对齐就表示这些元素属于一个层级;
4. 使用#表示注释 ;
5. 字符串默认不用加单双引号,但单引号和双引号都可以使用,双引号表示不需要对特殊字符进行转义;
6. YAML 中提供了多种常量结构,包括:整数,浮点数,字符串,NULL,日期,布尔,时间。
4.3.2 对象的写法
# value 与 : 符号之间必须要有一个空格
key: value
4.3.3 map的写法:
# 写法一 同一缩进的所有键值对属于一个map
key:
key1: value1
key2: value2
# 写法二
{key1: value1, key2: value2}
4.3.4 数组的写法
# 写法一 使用一个短横线加一个空格代表一个数组项
- a
- b
- c
# 写法二
[a,b,c]
4.3.5 单双引号
s1: '内容\n 字符串'
s2: "内容\n 字符串"
转换后:
{ s1: '内容\\n 字符串', s2: "内容\n 字符串" }
4.3.6 特殊符号
一个 YAML 文件中可以包括多个文档,使用 `---` 进行分割。
4.3.7 配置引用
Flow 2.0 建议将公共参数定义在 `config` 下,并通过 `${}` 进行引用。
4.4 案例介绍
4.4.1 简单案例调度
1)编写一个xxxx.flow文件,比如simple.flow (注意字符集,TAB键等问题)
nodes:
- name: jobA
type: command
config:
command: echo "this is a simple test"
2)编写版本文件:xxx.project ,比如叫same.project
azkaban-flow-version: 2.0
3)打包成xxx.zip文件,上传,测试
4.4.2 多任务调度
1)编写一个xxxx.flow文件,比如multi.flow (注意字符集,TAB键等问题)
nodes:
- name: jobE
type: command
config:
command: echo "This is job E"
# jobE depends on jobD
dependsOn:
- jobD
- name: jobD
type: command
config:
command: echo "This is job D"
# jobD depends on jobA、jobB、jobC
dependsOn:
- jobA
- jobB
- jobC
- name: jobA
type: command
config:
command: echo "This is job A"
- name: jobB
type: command
config:
command: echo "This is job B"
- name: jobC
type: command
config:
command: echo "This is job C"
2)编写版本文件:xxx.project ,比如叫same.project
azkaban-flow-version: 2.0
3)打包成xxx.zip文件,上传,测试
4.4.3 内嵌流调度
1)编写一个xxxx.flow文件,比如embedded.flow (注意字符集,TAB键等问题)
nodes:
- name: jobC
type: command
config:
command: echo "This is job C"
dependsOn:
- embedded_flow
- name: embedded_flow
type: flow
config:
prop: value
nodes:
- name: jobB
type: command
config:
command: echo "This is job B ${prop}"
dependsOn:
- jobA
- name: jobA
type: command
config:
command: echo "This is job A"
2)编写版本文件:xxx.project ,比如叫same.project
azkaban-flow-version: 2.0
3)打包成xxx.zip文件,上传,测试
五 azkaban的高级应用
1、支持权限的设置
2、支持插件的应用和自定义
tip:azkaban的插件机制使得可以非常方便的增加插件类型,从而支持运行更多的作业类型。azkaban的hadoop插件可以从以下仓库中找到:git clone https://github.com/azkaban/azkaban-plugins.git
5.1 执行权限
Every user is validated through the UserManager to prevent invalid users from being added. Groups and Proxy users are also check to make sure they are valid and to see if the admin is allowed to add them to the project.
每个用户都通过UserManager进行验证,以防止添加无效用户。还要检查组和代理用户,以确保它们是有效的,并查看管理员是否被允许将它们添加到项目中。
The following permissions can be set for users and groups:
可以为用户和组设置以下权限:
| Permission | Description |
|---|---|
| ADMIN | 允许用户对该项目做任何事情,以及添加权限和删除项目。 |
| READ | 用户可以查看作业、流和执行日志。 |
| WRITE | 项目文件可以上传,作业文件可以修改。 |
| EXECUTE | 允许用户执行、暂停、取消作业。 |
| SCHEDULE | 允许用户从计划中添加、修改和删除流。 |
5.3 azkaban的优化
5.3.1 webserver配置优化
| 参数 | 描述 | 默认值 |
|---|---|---|
| job.max.Xms | 每个job可以申请的初始化最大内存空间,如果job需要更多的空间,azkaban Server不会启动这个job。该参数在项目upload时候执行。 | 默认1G |
| job.max.Xmx | 每个job可以申请的最大内存空间,如果job需要更多的空间 azkaban server不会启动这个job。该参数在项目upload时候执行。 | 默认2G |
每个job初始化和申请的运行空间大小,如果太小速度慢或者引起oom(outOfMemory),如果太大容易引起资源浪费。
报错oom:适当提升大小。
5.3.2 executor配置优化
提高executor的任务并行度,来快速运行任务。每个flow中可以包含多个job。
| 参数 | 描述 | 默认值 |
|---|---|---|
| executor.flow.threads | 当前可以运行flow的数量 | 默认30 |
| flow.num.job.threads | 每个flow中并发运行的job数 | 默认10 |
flow.num.job.threads如果将其设置为20,将可以并发运行20个job。
|
| WRITE | 项目文件可以上传,作业文件可以修改。 |
| EXECUTE | 允许用户执行、暂停、取消作业。 |
| SCHEDULE | 允许用户从计划中添加、修改和删除流。 |
5.3 azkaban的优化
5.3.1 webserver配置优化
| 参数 | 描述 | 默认值 |
|---|---|---|
| job.max.Xms | 每个job可以申请的初始化最大内存空间,如果job需要更多的空间,azkaban Server不会启动这个job。该参数在项目upload时候执行。 | 默认1G |
| job.max.Xmx | 每个job可以申请的最大内存空间,如果job需要更多的空间 azkaban server不会启动这个job。该参数在项目upload时候执行。 | 默认2G |
每个job初始化和申请的运行空间大小,如果太小速度慢或者引起oom(outOfMemory),如果太大容易引起资源浪费。
报错oom:适当提升大小。
5.3.2 executor配置优化
提高executor的任务并行度,来快速运行任务。每个flow中可以包含多个job。
| 参数 | 描述 | 默认值 |
|---|---|---|
| executor.flow.threads | 当前可以运行flow的数量 | 默认30 |
| flow.num.job.threads | 每个flow中并发运行的job数 | 默认10 |
flow.num.job.threads如果将其设置为20,将可以并发运行20个job。