Flink的并行度及Slot
一个Flink程序Application由多个任务组成(source、transformation和sink),一个任务由多个并行实例(线程)来执行,一个任务的并行度实例(线程数)数目被称为该任务的并行度。
并行度的设置方式:
a、Operrator Level(算子层次)
b、Execution Environment Level(执行环境层次)
c、Client Level(客户端层次)
d、System Level(系统层次)并行度的优先级Operrator Level>Execution Environment Level>Client Level>System Level
1、算子层次并行度设置
Flink支持针对单独的某个Operator设置并行度,一个算子、数据源和sink的并行度可以通过setParallelism()方法来单独指定
DataStream sum=dataStreamSource.rescale().map(new MapFunction(){
@Override
public String map(String value) throws Exception{
return value;
}
}).setParallelism(4).timeWindowAll(Time.seconds(10)).sum(0);//每10秒的数据计算一次 2、执行环境层次并行度:
执行层次的默认并行度可以通过调用env.setParallesm()方法来指定,这样设置并行度是针对Job的,假设我们想以并行度等于3来执行所有算子,数据源和sink,可以通过下面方式设置:
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);3、客户端层次设置并行度 我们可以在客户端提交Flink job的时候指定任务的并行度,对CLI客户端,我们可以通过-p来指定并行度
flink run -p 10 WordCount.jar4、系统层次并行度设置
在系统级可以通过修改flink-conf.yaml文件中的parallelism.default参数来设置全局的默认并行度,即所有执行环境的默认并行度
parallelism.default:2Flink Slot:
Flink集群是由JobManager(JM)、TaskManager(TM)两大组件组成的,每个JM/TM都是运行在一个独立的JVM进程中。JM相当于Master,是集群的管理节点,TM相当于Worker,是集群的工作节点,每个TM最少持有1个Slot,Slot是Flink执行Job时的最小资源分配单位,在Slot中运行着具体的Task任务。
对TM而言:它占用着一定数量的CPU和Memory资源,具体可通过
taskmanager.numberOfTaskSlots,taskmanager.heap.size来配置,实际上taskmanager.numberOfTaskSlots只是指定TM的Slot数量,并不能隔离指定数量的CPU给TM使用。在不考虑Slot Sharing(下文详述)的情况下,一个Slot内运行着一个SubTask(Task实现Runable,SubTask是一个执行Task的具体实例),所以官方建议taskmanager.numberOfTaskSlots配置的Slot数量和CPU相等或成比例。当然,我们可以借助Yarn等调度系统,用Flink On Yarn的模式来为Yarn Container分配指定数量的CPU资源,以达到较严格的CPU隔离(Yarn采用Cgroup做基于时间片的资源调度,每个Container内运行着一个JM/TM实例)。而
taskmanager.heap.size用来配置TM的Memory,如果一个TM有N个Slot,则每个Slot分配到的Memory大小为整个TM Memory的1/N,同一个TM内的Slots只有Memory隔离,CPU是共享的。对Job而言:一个Job所需的Slot数量大于等于Operator配置的最大Parallelism数,在保持所有Operator的
slotSharingGroup一致的前提下Job所需的Slot数量与Job中Operator配置的最大Parallelism相等。
注意:一个Tm内的slot只有内存上隔离,CPU是共享的。
Flink On Yarn的Job提交过程,从图中我们可以了解到每个JM/TM实例都分属于不同的Yarn Container,且每个Container内只会有一个JM或TM实例;通过对Yarn的学习我们可以了解到,每个Container都是一个独立的进程,一台物理机可以有多个Container存在(多个进程),每个Container都持有一定数量的CPU和Memory资源,而且是资源隔离的,进程间不共享,这就可以保证同一台机器上的多个TM之间是资源隔离的(Standalone模式下,同一台机器下若有多个TM,是做不到TM之间的CPU资源隔离的)。
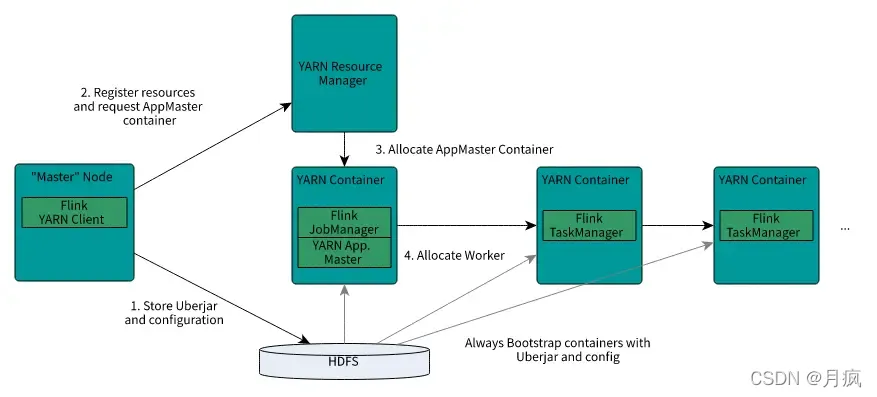
Flink Job运行图,图中有两个TM,各自有3个Slot,2个Slot内有Task在执行,1个Slot空闲。若这两个TM在不同Container或容器上,则其占用的资源是互相隔离的。在TM内多个Slot间是各自拥有 1/3 TM的Memory,共享TM的CPU、网络(Tcp:ZK、 Akka、Netty服务等)、心跳信息、Flink结构化的数据集等。

Task Slot的内部结构图,Slot内运行着具体的Task,它是在线程中执行的Runable对象(每个虚线框代表一个线程),这些Task实例在源码中对应的类是
org.apache.flink.runtime.taskmanager.Task。每个Task都是由一组Operators Chaining在一起的工作集合,Flink Job的执行过程可看作一张DAG图,Task是DAG图上的顶点(Vertex),顶点之间通过数据传递方式相互链接构成整个Job的Execution Graph。

Operator Chain
Operator Chain是指将Job中的Operators按照一定策略(例如:single output operator可以chain在一起)链接起来并放置在一个Task线程中执行。Operator Chain默认开启,可通过
StreamExecutionEnvironment.disableOperatorChaining()关闭,Flink Operator类似Storm中的Bolt,在Strom中上游Bolt到下游会经过网络上的数据传递,而Flink的Operator Chain将多个Operator链接到一起执行,减少了数据传递/线程切换等环节,降低系统开销的同时增加了资源利用率和Job性能。实际开发过程中需要开发者了解这些原理,并能合理分配Memory和CPU给到每个Task线程。注: 【一个需要注意的地方】Chained的Operators之间的数据传递默认需要经过数据的拷贝(例如:kryo.copy(...)),将上游Operator的输出序列化出一个新对象并传递给下游Operator,可以通过
ExecutionConfig.enableObjectReuse()开启对象重用,这样就关闭了这层copy操作,可以减少对象序列化开销和GC压力等,具体源码可阅读org.apache.flink.streaming.runtime.tasks.OperatorChain与org.apache.flink.streaming.runtime.tasks.OperatorChain.CopyingChainingOutput。官方建议开发人员在完全了解reuse内部机制后才使用该功能,冒然使用可能会给程序带来bug。
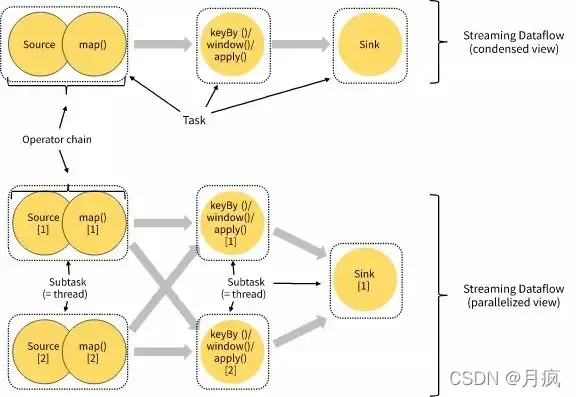
图的上半部分是StreamGraph视角,有Task类别无并行度,如图:Job Runtime时有三种类型的Task,分别是
Source->Map、keyBy/window/apply、Sink,其中Source->Map是Source()和Map()chaining在一起的Task;图的下半部分是一个Job Runtime期的实际状态,Job最大的并行度为2,有5个SubTask(即5个执行线程)。若没有Operator Chain,则Source()和Map()分属不同的Thread,Task线程数会增加到7,线程切换和数据传递开销等较之前有所增加,处理延迟和性能会较之前差。补充:在slotSharingGroup用默认或相同组名时,当前Job运行需2个Slot(与Job最大Parallelism相等)。
Slot Sharing
Slot Sharing是指,来自同一个Job且拥有相同
slotSharingGroup(默认:default)名称的不同Task的SubTask之间可以共享一个Slot,这使得一个Slot有机会持有Job的一整条Pipeline,这也是上文提到的在默认slotSharing的条件下Job启动所需的Slot数和Job中Operator的最大parallelism相等的原因。通过Slot Sharing机制可以更进一步提高Job运行性能,在Slot数不变的情况下增加了Operator可设置的最大的并行度,让类似window这种消耗资源的Task以最大的并行度分布在不同TM上,同时像map、filter这种较简单的操作也不会独占Slot资源,降低资源浪费的可能性。
图的左下角是一个
soure-map-reduce模型的Job,source和map是4 parallelism,reduce是3 parallelism,总计11个SubTask;这个Job最大Parallelism是4,所以将这个Job发布到左侧上面的两个TM上时得到图右侧的运行图,一共占用四个Slot,有三个Slot拥有完整的source-map-reduce模型的Pipeline,如右侧图所示;注:map的结果会shuffle到reduce端,右侧图的箭头只是说Slot内数据Pipline,没画出Job的数据shuffle过程。

包含
source-map[6 parallelism]、keyBy/window/apply[6 parallelism]、sink[1 parallelism]三种Task,总计占用了6个Slot;由左向右开始第一个slot内部运行着3个SubTask[3 Thread],持有Job的一条完整pipeline;剩下5个Slot内分别运行着2个SubTask[2 Thread],数据最终通过网络传递给Sink完成数据处理。

参考:Flink Slot详解与Job Execution Graph优化 - SegmentFault 思否