YARN 的架构是怎样的?YARN 的核心组件有哪些?
前言
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见1000个问题搞定大数据技术体系
正文
YARN是经典的主从(master/slave)结构,如下图所示。
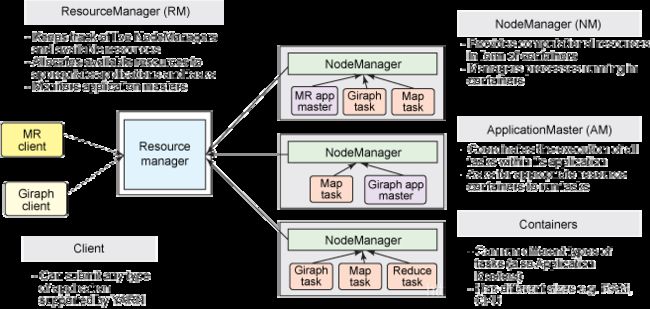
大体上看,YARN服务由一个ResourceManager(RM)和多个NodeManager(NM)构成,ResourceManager为主节点(master),NodeManager为从节点(slave)。
ApplicationMaster可以在 Container(容器)内运行任何类型的任务。
| 组件名 | 作用 |
|---|---|
| ResourceManager | 是Master上一个独立运行的进程,负责集群统一的资源管理、调度、分配等等; |
| ApplicationManager | 相当于这个Application的监护人和管理者,负责监控、管理这个Application的所有Attempt在cluster中各个节点上的具体运行,同时负责向Yarn ResourceManager申请资源、返还资源等; |
| NodeManager | 是Slave上一个独立运行的进程,负责上报节点的状态(磁盘,内存,cpu等使用信息); |
| Container** | 是yarn中分配资源的一个单位,包涵内存、CPU等等资源,YARN以Container为单位分配资源; |
Container 在 Hadoop3.x版本之前只支持内存和 CPU 资源,Hadoop 3.x 开始支持自定义资源类型,极大的增强了资源管理的能力。
上面的组件怎样相互作用的?
ResourceManager 负责对各个 NodeManager 上资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的 ApplicationMaster,它负责向 ResourceManager 申请资源,并要求 NodeManger 启动可以占用一定资源的任务。
由于不同的 ApplicationMaster 被分布到不同的节点上,因此它们之间不会相互影响。
Client 向 ResourceManager 提交的每一个应用程序都必须有一个 ApplicationMaster,它经过 ResourceManager 分配资源后,运行于某一个 Slave 节点的 Container 中,具体做事情的 Task,同样也运行与某一个 Slave 节点的 Container 中。
补充
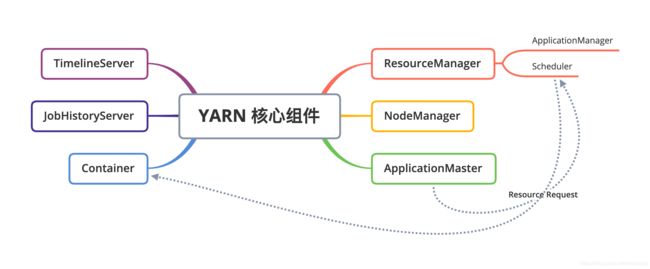
ResourceManager
RM是一个全局的资源管理器,集群只有一个,负责整个系统的资源管理和分配,包括处理客户端请求、启动/监控 ApplicationMaster、监控 NodeManager、资源的分配与调度。
它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(ApplicationManager)。
调度器(Scheduler)
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。需要注意的是,该调度器是一个“纯调度器”,它从事任何与具体应用程序相关的工作,比如不负责监控或者跟踪应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务,这些均交由应用程序相关的ApplicationMaster完成。
调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(Resource Container,简称Container)表示,Container是一个动态资源分配单位,它将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。
应用程序管理器(ApplicationManager)
应用程序管理器主要负责管理整个系统中所有应用程序,接收job的提交请求,为应用分配第一个 Container 来运行 ApplicationMaster,包括应用程序提交、与调度器协商资源以启动 ApplicationMaster、监控 ApplicationMaster 运行状态并在失败时重新启动它等。
ApplicationMaster
管理 YARN 内运行的一个应用程序的每个实例。关于 job 或应用的管理都是由 ApplicationMaster 进程负责的,Yarn 允许我们以为自己的应用开发 ApplicationMaster。
功能
- 数据切分;
- 为应用程序申请资源并进一步分配给内部任务(TASK);
- 任务监控与容错;
- 负责协调来自ResourceManager的资源,并通过NodeManager监视容易的执行和资源使用情况。
可以说,ApplicationMaster 与 ResourceManager 之间的通信是整个 Yarn 应用从提交到运行的最核心部分,是 Yarn 对整个集群进行动态资源管理的根本步骤,Yarn 的动态性,就是来源于多个Application 的 ApplicationMaster 动态地和 ResourceManager 进行沟通,不断地申请、释放、再申请、再释放资源的过程。
NodeManager
NodeManager 整个集群有多个,负责每个节点上的资源和使用。
NodeManager 是一个 slave 服务:它负责接收 ResourceManager 的资源分配请求,分配具体的 Container 给应用。同时,它还负责监控并报告 Container 使用信息给 ResourceManager。通过和ResourceManager 配合,NodeManager 负责整个 Hadoop 集群中的资源分配工作。
功能
- NodeManager 监控本节点上的资源使用情况和各个 Container 的运行状态(cpu和内存等资源)
- 接收及处理来自 ResourceManager 的命令请求,分配 Container 给应用的某个任务;
- 定时地向RM汇报以确保整个集群平稳运行,RM 通过收集每个 NodeManager 的报告信息来追踪整个集群健康状态的,而 NodeManager 负责监控自身的健康状态;
- 处理来自 ApplicationMaster 的请求;
- 管理每个节点上的日志;
- 执行 Yarn 上面应用的一些额外的服务,比如 MapReduce 的 shuffle 过程;
当一个节点启动时,它会向 ResourceManager 进行注册并告知 ResourceManager 自己有多少资源可用。
在运行期,通过 NodeManager 和 ResourceManager 协同工作,这些信息会不断被更新并保障整个集群发挥出最佳状态。
NodeManager 只负责管理自身的 Container,它并不知道运行在它上面应用的信息。负责管理应用信息的组件是 ApplicationMaster
Container
Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当 AM 向 RM 申请资源时,RM 为 AM 返回的资源便是用 Container 表示的。YARN 会为每个任务分配一个 Container,且该任务只能使用该 Container 中描述的资源。
Container 和集群节点的关系是:一个节点会运行多个 Container,但一个 Container 不会跨节点。任何一个 job 或 application 必须运行在一个或多个 Container 中,在 Yarn 框架中,ResourceManager 只负责告诉 ApplicationMaster 哪些 Containers 可以用,ApplicationMaster 还需要去找 NodeManager 请求分配具体的 Container。
需要注意的是,Container 是一个动态资源划分单位,是根据应用程序的需求动态生成的。目前为止,YARN 仅支持 CPU 和内存两种资源,且使用了轻量级资源隔离机制 Cgroups 进行资源隔离。
功能
- 对task环境的抽象;
- 描述一系列信息;
- 任务运行资源的集合(cpu、内存、io等);
- 任务运行环境
Resource Request
Yarn的设计目标就是允许我们的各种应用以共享、安全、多租户的形式使用整个集群。
并且,为了保证集群资源调度和数据访问的高效性,Yarn还必须能够感知整个集群拓扑结构。
为了实现这些目标,ResourceManager的调度器Scheduler为应用程序的资源请求定义了一些灵活的协议,通过它就可以对运行在集群中的各个应用做更好的调度,因此,这就诞生了Resource Request和Container。
一个应用先向ApplicationMaster发送一个满足自己需求的资源请求,然后ApplicationMaster把这个资源请求以resource-request的形式发送给ResourceManager的Scheduler,Scheduler再在这个原始的resource-request中返回分配到的资源描述Container。
每个ResourceRequest可看做一个可序列化Java对象,包含的字段信息如下:
<resource-name, priority, resource-requirement, number-of-containers>
JobHistoryServer
作业历史服务,记录在yarn中调度的作业历史运行情况情况 , 通过下面的命令在集群中的数据节点机器上不需要做任何配置,单独使用命令启动直接启动即可, 启动成功后会出现JobHistoryServer进程(使用jps命令查看,下面会有介绍) , 并且可以从19888端口进行查看日志详细信息
两种方法可以启动JobHistoryServer (Hadoop 3.x)
[hadoop@node1 ~]$ mr-jobhistory-daemon.sh start historyserver
WARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon start" instead.
[hadoop@node1 ~]$ mapred --daemon start historyserver
[hadoop@node1 ~]$
TimelineServer
用来写日志服务数据 , 一般来写与第三方结合的日志服务数据(比如spark等),从官网的介绍看,它是对 JobHistoryServer 功能的有效补充
JobHistoryServer 只能对 mapreduce 类型的作业信息进行记录,除了 JobHistoryServer 能够进行对作业运行过程中信息进行记录之外还有更细粒度的信息记录,比如任务在哪个队列中运行,运行任务时设置的用户是哪个用户。
根据官网的解释,JobHistoryServer 只能记录mapreduce应用程序的记录,TimelineServer 功能更强大,可以记录第三方计算引擎的,但不是替代 JobHistoryServer。 两者是功能间的互补关系。
实践
在三台机器上执行下面的命令依次启动JobHistoryServer
mapred --daemon start historyserver
此时我们在三个节点把JobHistoryServer启动后,在此运行wordcount程序
我们使用官方提供的 WordCount 的例子。
[hadoop@node1 ~]$ hadoop jar /opt/bigdata/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /test/words /test/output
2021-06-17 22:06:18,348 INFO client.RMProxy: Connecting to ResourceManager at node1/172.16.68.201:18040
2021-06-17 22:06:19,108 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1614270487333_0009
2021-06-17 22:06:19,346 INFO input.FileInputFormat: Total input files to process : 1
2021-06-17 22:06:19,844 INFO mapreduce.JobSubmitter: number of splits:1
2021-06-17 22:06:20,026 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1614270487333_0009
2021-06-17 22:06:20,028 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-06-17 22:06:20,253 INFO conf.Configuration: resource-types.xml not found
2021-06-17 22:06:20,253 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-06-17 22:06:20,356 INFO impl.YarnClientImpl: Submitted application application_1614270487333_0009
2021-06-17 22:06:20,403 INFO mapreduce.Job: The url to track the job: http://node1:18088/proxy/application_1614270487333_0009/
2021-06-17 22:06:20,404 INFO mapreduce.Job: Running job: job_1614270487333_0009
2021-06-17 22:06:26,536 INFO mapreduce.Job: Job job_1614270487333_0009 running in uber mode : false
2021-06-17 22:06:26,538 INFO mapreduce.Job: map 0% reduce 0%
2021-06-17 22:06:31,614 INFO mapreduce.Job: map 100% reduce 0%
2021-06-17 22:06:36,653 INFO mapreduce.Job: map 100% reduce 100%
2021-06-17 22:06:36,666 INFO mapreduce.Job: Job job_1614270487333_0009 completed successfully
2021-06-17 22:06:36,763 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=54
FILE: Number of bytes written=470051
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=115
HDFS: Number of bytes written=28
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=2460
Total time spent by all reduces in occupied slots (ms)=2545
Total time spent by all map tasks (ms)=2460
Total time spent by all reduce tasks (ms)=2545
Total vcore-milliseconds taken by all map tasks=2460
Total vcore-milliseconds taken by all reduce tasks=2545
Total megabyte-milliseconds taken by all map tasks=2519040
Total megabyte-milliseconds taken by all reduce tasks=2606080
Map-Reduce Framework
Map input records=2
Map output records=6
Map output bytes=46
Map output materialized bytes=54
Input split bytes=93
Combine input records=6
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=54
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=154
CPU time spent (ms)=1330
Physical memory (bytes) snapshot=546705408
Virtual memory (bytes) snapshot=5198422016
Total committed heap usage (bytes)=368574464
Peak Map Physical memory (bytes)=319201280
Peak Map Virtual memory (bytes)=2592329728
Peak Reduce Physical memory (bytes)=227504128
Peak Reduce Virtual memory (bytes)=2606092288
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=22
File Output Format Counters
Bytes Written=28
此时访问页面:http://node1:18088/cluster(注意在本机配置node1的host)
点击History连接会跳转一个新的页面,在页面下方会看到TaskType中列举的map和reduce,Total表示此次运行的mapreduce程序执行所需要的map和reduce的任务数据.
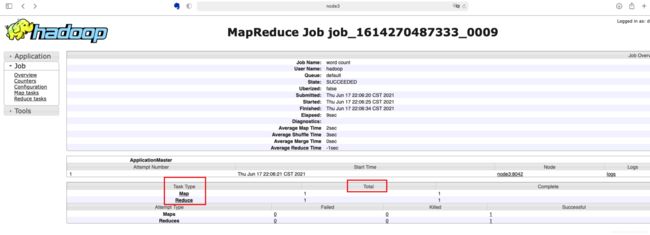
如下图,我们在TaskType列中点击Map连接
如下图我们可以看到map任务的相关信息比如执行状态,启动时间,完成时间。

可以使用同样的方式我们查看reduce任务执行的详细信息,这里不再赘述.
从以上操作中我们可以看到JobHistoryServer就是进行作业运行过程中历史运行信息的记录,方便我们对作业进行分析.