infer源码阅读之yolo.cu
目录
- yolo.cu
-
- 注意事项
- 一、2023/3/30更新
- 前言
- 1.宏定义
- 2.Norm
- 3.后处理
-
- 3.1 affine_project
- 3.2 decode
-
- 3.2.1 decode_common
- 3.2.2 decode_v8
- 3.3 nms
- 3.4 invoker
- 4.预处理
- 5.decode_mask
- 6.AffineMatrix
- 7.InferImpl
-
- 7.1 adjust_memory
- 7.2 preprocess
- 7.3 load
- 7.4 forwards
- 8.其它
- 9.拓展之yolo.hpp
- 结语
- 参考
yolo.cu
注意事项
一、2023/3/30更新
更新yolo.cu剩余部分内容,目前已全部分析完毕!!!
前言
结合ChatGPT进行infer框架源码学习,对https://github.com/shouxieai/infer/blob/main/src/yolo.cu进行简单的分析,按照yolo.cu文件中的自上而下的顺序,从宏定义开始,目前来说只分析了一部分,后续看情况更新吧。有错误欢迎各位批评指正!!!
1.宏定义
代码对应8-24行
#define GPU_BLOCK_THREADS 512
#define checkRuntime(call) \
do { \
auto ___call__ret_code__ = (call); \
if (___call__ret_code__ != cudaSuccess) { \
INFO("CUDA Runtime error %s # %s, code = %s [ %d ]", #call, \
cudaGetErrorString(___call__ret_code__), cudaGetErrorName(___call__ret_code__), \
___call__ret_code__); \
abort(); \
} \
} while (0)
#define checkKernel(...) \
do { \
{ (__VA_ARGS__); } \
checkRuntime(cudaPeekAtLastError()); \
} while (0)
enum class NormType : int { None = 0, MeanStd = 1, AlphaBeta = 2 };
enum class ChannelType : int { None = 0, SwapRB = 1 };
- 宏定义block的线程数为512(kernel两层级结构,第一层次为grid代表启动的所有线程,第二层次是block)
- 宏
checkRuntime的作用是:在执行CUDA函数时,通过cudaGetErrorString和cudaGetErrorName将错误代码转换为可读的字符串,然后在控制台上打印错误信息,并且通过调用abort()函数使程序立即退出 - 宏
checkKernel的作用是:在执行CUDA kernel函数时,先执行kernel函数调用,然后调用cudaPeekAtLastError函数检查kernel函数是否执行成功。如果出错,则调用checkRuntime宏输出错误信息并退出程序
2.Norm
代码对应26-69行
enum class NormType : int { None = 0, MeanStd = 1, AlphaBeta = 2 };
enum class ChannelType : int { None = 0, SwapRB = 1 };
/* 归一化操作,可以支持均值标准差,alpha beta,和swap RB */
struct Norm {
float mean[3];
float std[3];
float alpha, beta;
NormType type = NormType::None;
ChannelType channel_type = ChannelType::None;
// out = (x * alpha - mean) / std
static Norm mean_std(const float mean[3], const float std[3], float alpha = 1 / 255.0f,
ChannelType channel_type = ChannelType::None);
// out = x * alpha + beta
static Norm alpha_beta(float alpha, float beta = 0, ChannelType channel_type = ChannelType::None);
// None
static Norm None();
};
Norm Norm::mean_std(const float mean[3], const float std[3], float alpha,
ChannelType channel_type) {
Norm out;
out.type = NormType::MeanStd;
out.alpha = alpha;
out.channel_type = channel_type;
memcpy(out.mean, mean, sizeof(out.mean));
memcpy(out.std, std, sizeof(out.std));
return out;
}
Norm Norm::alpha_beta(float alpha, float beta, ChannelType channel_type) {
Norm out;
out.type = NormType::AlphaBeta;
out.alpha = alpha;
out.beta = beta;
out.channel_type = channel_type;
return out;
}
Norm Norm::None() { return Norm(); }
- 归一化操作,没啥好说的
3.后处理
3.1 affine_project
代码对应71-79行
const int NUM_BOX_ELEMENT = 8; // left, top, right, bottom, confidence, class,
// keepflag, row_index(output)
const int MAX_IMAGE_BOXES = 1024;
inline int upbound(int n, int align = 32) { return (n + align - 1) / align * align; }
static __host__ __device__ void affine_project(float *matrix, float x, float y, float *ox,
float *oy) {
*ox = matrix[0] * x + matrix[1] * y + matrix[2];
*oy = matrix[3] * x + matrix[4] * y + matrix[5];
}
- box包含8个元素,其中
keep_flag用于做NMS的标志位,row_index(output)不太懂(输出结果中每个目标框所对应的行索引?) - 内联函数
upbound将整数n向上取整到align的倍数 affine_project函数被用来将原始图片中的检测框坐标转换到经过预处理后的特征图中的坐标
3.2 decode
3.2.1 decode_common
代码对应81-127行
static __global__ void decode_kernel_common(float *predict, int num_bboxes, int num_classes,
int output_cdim, float confidence_threshold,
float *invert_affine_matrix, float *parray,
int MAX_IMAGE_BOXES) {
int position = blockDim.x * blockIdx.x + threadIdx.x;
if (position >= num_bboxes) return;
float *pitem = predict + output_cdim * position;
float objectness = pitem[4];
if (objectness < confidence_threshold) return;
float *class_confidence = pitem + 5;
float confidence = *class_confidence++;
int label = 0;
for (int i = 1; i < num_classes; ++i, ++class_confidence) {
if (*class_confidence > confidence) {
confidence = *class_confidence;
label = i;
}
}
confidence *= objectness;
if (confidence < confidence_threshold) return;
int index = atomicAdd(parray, 1);
if (index >= MAX_IMAGE_BOXES) return;
float cx = *pitem++;
float cy = *pitem++;
float width = *pitem++;
float height = *pitem++;
float left = cx - width * 0.5f;
float top = cy - height * 0.5f;
float right = cx + width * 0.5f;
float bottom = cy + height * 0.5f;
affine_project(invert_affine_matrix, left, top, &left, &top);
affine_project(invert_affine_matrix, right, bottom, &right, &bottom);
float *pout_item = parray + 1 + index * NUM_BOX_ELEMENT;
*pout_item++ = left;
*pout_item++ = top;
*pout_item++ = right;
*pout_item++ = bottom;
*pout_item++ = confidence;
*pout_item++ = label;
*pout_item++ = 1; // 1 = keep, 0 = ignore
}
-
函数参数
predict是一个num_bboxes * output_cdim的一维数组,存储了网络输出的所有预测框num_boxes表示预测框的数量num_classes表示类别的数量output_cdim表示每个预测框的维度,即[cx,cy,w,h,obj_conf,num_classes],其中num_classes代表每个类别的预测概率,它不是一个维度,例如COCO数据集,num_claasses=80,此时output_cdim维度为85维confidence_threshold表示过滤预测框的置信度阈值invert_affine_matrix是一个大小为6的一维数组,存储了仿射变化矩阵的逆矩阵,用于将预测框的坐标从网络输出的特征图坐标系转换为原图坐标系parray是一个一维数组,用于存储解码后的预测框信息(首地址是框的数量?)MAX_IMAGE_BOXES表示每张图片最多保留的预测框数量
-
核函数
decode_kernel_common用于常用目标检测算法中预测框解码操作,每个线程处理一个框的解码 -
position表示当前线程要处理的预测框编号 -
如下图所示,
*predict为所有预测框的首地址,pitem为当前线程要处理的预测框在predict中的起始位置

-
atomicAdd()是CUDA提供的原子操作函数之一,对指定内存地址进行原子加操作,并返回加操作后的结果。具体以下面的代码来说,对parray指向的内存地址中的值加1,并返回加1的值作为index的值。这个过程是原子的,意味着在多个线程同时执行这段代码时,不会出现数据竞争等问题。在这里,index表示当前所处理的边界框在所有边界框中的索引值。为了避免超过最大边界框数量,会在index超过MAX_IMAGE_BOXES时直接返回,不再处理该边界框。int index = atomicAdd(parray, 1); if (index >= MAX_IMAGE_BOXES) return; -
下面代码主要完成预测框的解码,即将中心点、宽高形式=>左上、右下形式,并利用仿射变换逆矩阵将其映射回原坐标上。
float cx = *pitem++; float cy = *pitem++; float width = *pitem++; float height = *pitem++; float left = cx - width * 0.5f; float top = cy - height * 0.5f; float right = cx + width * 0.5f; float bottom = cy + height * 0.5f; affine_project(invert_affine_matrix, left, top, &left, &top); affine_project(invert_affine_matrix, right, bottom, &right, &bottom); -
将预测框完成解码后就需要将其解码后的框信息保存下来,保存的首地址是
*parray,parray的第一个元素是保存下来的框的数量,后面才是一个个框的信息,如下图所示。

3.2.2 decode_v8
代码对应129-171行
static __global__ void decode_kernel_v8(float *predict, int num_bboxes, int num_classes,
int output_cdim, float confidence_threshold,
float *invert_affine_matrix, float *parray,
int MAX_IMAGE_BOXES) {
int position = blockDim.x * blockIdx.x + threadIdx.x;
if (position >= num_bboxes) return;
float *pitem = predict + output_cdim * position;
float *class_confidence = pitem + 4;
float confidence = *class_confidence++;
int label = 0;
for (int i = 1; i < num_classes; ++i, ++class_confidence) {
if (*class_confidence > confidence) {
confidence = *class_confidence;
label = i;
}
}
if (confidence < confidence_threshold) return;
int index = atomicAdd(parray, 1);
if (index >= MAX_IMAGE_BOXES) return;
float cx = *pitem++;
float cy = *pitem++;
float width = *pitem++;
float height = *pitem++;
float left = cx - width * 0.5f;
float top = cy - height * 0.5f;
float right = cx + width * 0.5f;
float bottom = cy + height * 0.5f;
affine_project(invert_affine_matrix, left, top, &left, &top);
affine_project(invert_affine_matrix, right, bottom, &right, &bottom);
float *pout_item = parray + 1 + index * NUM_BOX_ELEMENT;
*pout_item++ = left;
*pout_item++ = top;
*pout_item++ = right;
*pout_item++ = bottom;
*pout_item++ = confidence;
*pout_item++ = label;
*pout_item++ = 1; // 1 = keep, 0 = ignore
*pout_item++ = position;
}
-
核函数
decode_kernel_v8用于yolov8目标检测算法中预测框解码操作(yolov8基于anchor-free),每个线程处理一个框的解码 -
由于yolov8是anchor-free,不再拥有objecness分支,只有解耦的分类和回归分支,因此其
predict有略微的不同,可看下图
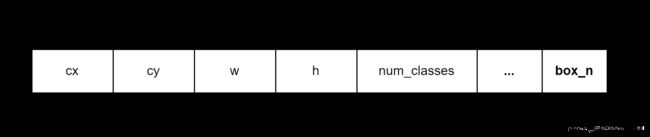
-
yolov8保存的框信息相比常规的检测算法也多了一个元素即
position(啥意思呢),其它保持一致,可看下图

3.3 nms
代码对应173-211行
static __device__ float box_iou(float aleft, float atop, float aright, float abottom, float bleft,
float btop, float bright, float bbottom) {
float cleft = max(aleft, bleft);
float ctop = max(atop, btop);
float cright = min(aright, bright);
float cbottom = min(abottom, bbottom);
float c_area = max(cright - cleft, 0.0f) * max(cbottom - ctop, 0.0f);
if (c_area == 0.0f) return 0.0f;
float a_area = max(0.0f, aright - aleft) * max(0.0f, abottom - atop);
float b_area = max(0.0f, bright - bleft) * max(0.0f, bbottom - btop);
return c_area / (a_area + b_area - c_area);
}
static __global__ void fast_nms_kernel(float *bboxes, int MAX_IMAGE_BOXES, float threshold) {
int position = (blockDim.x * blockIdx.x + threadIdx.x);
int count = min((int)*bboxes, MAX_IMAGE_BOXES);
if (position >= count) return;
// left, top, right, bottom, confidence, class, keepflag
float *pcurrent = bboxes + 1 + position * NUM_BOX_ELEMENT;
for (int i = 0; i < count; ++i) {
float *pitem = bboxes + 1 + i * NUM_BOX_ELEMENT;
if (i == position || pcurrent[5] != pitem[5]) continue;
if (pitem[4] >= pcurrent[4]) {
if (pitem[4] == pcurrent[4] && i < position) continue;
float iou = box_iou(pcurrent[0], pcurrent[1], pcurrent[2], pcurrent[3], pitem[0], pitem[1],
pitem[2], pitem[3]);
if (iou > threshold) {
pcurrent[6] = 0; // 1=keep, 0=ignore
return;
}
}
}
}
-
box_iou()为device函数,用于计算两个框的IoU值 -
fast_nms_kernel()为CUDA核函数,用于NMS非极大值抑制,函数首先获取当前线程在检测框集合中的位置,然后从bboxes中取出检测框数量。如果当前位置大于等于检测框的数量,则直接返回。接着,函数会遍历整个检测框集合,对于每个框,判断它是否与当前框重复,如果重复则计算它们的IoU,如果IoU大于阈值,则将该框的keepflag置为0,表示该框将被忽略。(相比于CPU版的NMS应该是少套了一层循环的,按理来说是可以提速的) -
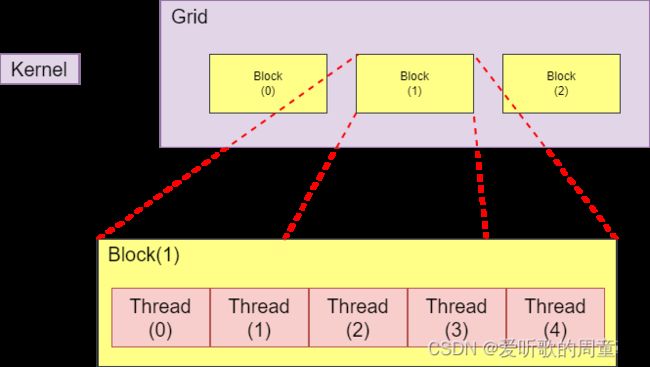
postition可以根据1-Dim Layout计算得出,示例图如下所示,position = blockDim.x * blockIdx.x + threadIdx.x,其中blockDim.x代表每个块中的线程数(图中是5),blockIdx.x代表当前块的索引(图中是1),threadIdx.x代表当前线程在块内的索引(图中的0-5)
3.4 invoker
代码对应213-242行
static dim3 grid_dims(int numJobs) {
int numBlockThreads = numJobs < GPU_BLOCK_THREADS ? numJobs : GPU_BLOCK_THREADS;
return dim3(((numJobs + numBlockThreads - 1) / (float)numBlockThreads));
}
static dim3 block_dims(int numJobs) {
return numJobs < GPU_BLOCK_THREADS ? numJobs : GPU_BLOCK_THREADS;
}
static void decode_kernel_invoker(float *predict, int num_bboxes, int num_classes, int output_cdim,
float confidence_threshold, float nms_threshold,
float *invert_affine_matrix, float *parray, int MAX_IMAGE_BOXES,
Type type, cudaStream_t stream) {
auto grid = grid_dims(num_bboxes);
auto block = block_dims(num_bboxes);
if (type == Type::V8 || type == Type::V8Seg) {
checkKernel(decode_kernel_v8<<<grid, block, 0, stream>>>(
predict, num_bboxes, num_classes, output_cdim, confidence_threshold, invert_affine_matrix,
parray, MAX_IMAGE_BOXES));
} else {
checkKernel(decode_kernel_common<<<grid, block, 0, stream>>>(
predict, num_bboxes, num_classes, output_cdim, confidence_threshold, invert_affine_matrix,
parray, MAX_IMAGE_BOXES));
}
grid = grid_dims(MAX_IMAGE_BOXES);
block = block_dims(MAX_IMAGE_BOXES);
checkKernel(fast_nms_kernel<<<grid, block, 0, stream>>>(parray, MAX_IMAGE_BOXES, nms_threshold));
}
decode_kernel_invoker为host函数用于调用一些后处理的核函数,包括调用之前的decode_kernel_common或decode_kernel_v8预测框decode解码核函数以及fast_nms_kernel即NMS非极大值抑制核函数stream变量是用来指定CUDA流的,是实现并行计算的重要机制之一。
4.预处理
代码对应244-337行
static __global__ void warp_affine_bilinear_and_normalize_plane_kernel(
uint8_t *src, int src_line_size, int src_width, int src_height, float *dst, int dst_width,
int dst_height, uint8_t const_value_st, float *warp_affine_matrix_2_3, Norm norm) {
int dx = blockDim.x * blockIdx.x + threadIdx.x;
int dy = blockDim.y * blockIdx.y + threadIdx.y;
if (dx >= dst_width || dy >= dst_height) return;
float m_x1 = warp_affine_matrix_2_3[0];
float m_y1 = warp_affine_matrix_2_3[1];
float m_z1 = warp_affine_matrix_2_3[2];
float m_x2 = warp_affine_matrix_2_3[3];
float m_y2 = warp_affine_matrix_2_3[4];
float m_z2 = warp_affine_matrix_2_3[5];
float src_x = m_x1 * dx + m_y1 * dy + m_z1;
float src_y = m_x2 * dx + m_y2 * dy + m_z2;
float c0, c1, c2;
if (src_x <= -1 || src_x >= src_width || src_y <= -1 || src_y >= src_height) {
// out of range
c0 = const_value_st;
c1 = const_value_st;
c2 = const_value_st;
} else {
int y_low = floorf(src_y);
int x_low = floorf(src_x);
int y_high = y_low + 1;
int x_high = x_low + 1;
uint8_t const_value[] = {const_value_st, const_value_st, const_value_st};
float ly = src_y - y_low;
float lx = src_x - x_low;
float hy = 1 - ly;
float hx = 1 - lx;
float w1 = hy * hx, w2 = hy * lx, w3 = ly * hx, w4 = ly * lx;
uint8_t *v1 = const_value;
uint8_t *v2 = const_value;
uint8_t *v3 = const_value;
uint8_t *v4 = const_value;
if (y_low >= 0) {
if (x_low >= 0) v1 = src + y_low * src_line_size + x_low * 3;
if (x_high < src_width) v2 = src + y_low * src_line_size + x_high * 3;
}
if (y_high < src_height) {
if (x_low >= 0) v3 = src + y_high * src_line_size + x_low * 3;
if (x_high < src_width) v4 = src + y_high * src_line_size + x_high * 3;
}
// same to opencv
c0 = floorf(w1 * v1[0] + w2 * v2[0] + w3 * v3[0] + w4 * v4[0] + 0.5f);
c1 = floorf(w1 * v1[1] + w2 * v2[1] + w3 * v3[1] + w4 * v4[1] + 0.5f);
c2 = floorf(w1 * v1[2] + w2 * v2[2] + w3 * v3[2] + w4 * v4[2] + 0.5f);
}
if (norm.channel_type == ChannelType::SwapRB) {
float t = c2;
c2 = c0;
c0 = t;
}
if (norm.type == NormType::MeanStd) {
c0 = (c0 * norm.alpha - norm.mean[0]) / norm.std[0];
c1 = (c1 * norm.alpha - norm.mean[1]) / norm.std[1];
c2 = (c2 * norm.alpha - norm.mean[2]) / norm.std[2];
} else if (norm.type == NormType::AlphaBeta) {
c0 = c0 * norm.alpha + norm.beta;
c1 = c1 * norm.alpha + norm.beta;
c2 = c2 * norm.alpha + norm.beta;
}
int area = dst_width * dst_height;
float *pdst_c0 = dst + dy * dst_width + dx;
float *pdst_c1 = pdst_c0 + area;
float *pdst_c2 = pdst_c1 + area;
*pdst_c0 = c0;
*pdst_c1 = c1;
*pdst_c2 = c2;
}
static __global__ void warp_affine_bilinear_and_normalize_plane_kernel(
uint8_t *src, int src_line_size, int src_width, int src_height, float *dst, int dst_width,
int dst_height, uint8_t const_value_st, float *warp_affine_matrix_2_3, Norm norm) {
int dx = blockDim.x * blockIdx.x + threadIdx.x;
int dy = blockDim.y * blockIdx.y + threadIdx.y;
if (dx >= dst_width || dy >= dst_height) return;
float m_x1 = warp_affine_matrix_2_3[0];
float m_y1 = warp_affine_matrix_2_3[1];
float m_z1 = warp_affine_matrix_2_3[2];
float m_x2 = warp_affine_matrix_2_3[3];
float m_y2 = warp_affine_matrix_2_3[4];
float m_z2 = warp_affine_matrix_2_3[5];
float src_x = m_x1 * dx + m_y1 * dy + m_z1;
float src_y = m_x2 * dx + m_y2 * dy + m_z2;
float c0, c1, c2;
if (src_x <= -1 || src_x >= src_width || src_y <= -1 || src_y >= src_height) {
// out of range
c0 = const_value_st;
c1 = const_value_st;
c2 = const_value_st;
} else {
int y_low = floorf(src_y);
int x_low = floorf(src_x);
int y_high = y_low + 1;
int x_high = x_low + 1;
uint8_t const_value[] = {const_value_st, const_value_st, const_value_st};
float ly = src_y - y_low;
float lx = src_x - x_low;
float hy = 1 - ly;
float hx = 1 - lx;
float w1 = hy * hx, w2 = hy * lx, w3 = ly * hx, w4 = ly * lx;
uint8_t *v1 = const_value;
uint8_t *v2 = const_value;
uint8_t *v3 = const_value;
uint8_t *v4 = const_value;
if (y_low >= 0) {
if (x_low >= 0) v1 = src + y_low * src_line_size + x_low * 3;
if (x_high < src_width) v2 = src + y_low * src_line_size + x_high * 3;
}
if (y_high < src_height) {
if (x_low >= 0) v3 = src + y_high * src_line_size + x_low * 3;
if (x_high < src_width) v4 = src + y_high * src_line_size + x_high * 3;
}
// same to opencv
c0 = floorf(w1 * v1[0] + w2 * v2[0] + w3 * v3[0] + w4 * v4[0] + 0.5f);
c1 = floorf(w1 * v1[1] + w2 * v2[1] + w3 * v3[1] + w4 * v4[1] + 0.5f);
c2 = floorf(w1 * v1[2] + w2 * v2[2] + w3 * v3[2] + w4 * v4[2] + 0.5f);
}
if (norm.channel_type == ChannelType::SwapRB) {
float t = c2;
c2 = c0;
c0 = t;
}
if (norm.type == NormType::MeanStd) {
c0 = (c0 * norm.alpha - norm.mean[0]) / norm.std[0];
c1 = (c1 * norm.alpha - norm.mean[1]) / norm.std[1];
c2 = (c2 * norm.alpha - norm.mean[2]) / norm.std[2];
} else if (norm.type == NormType::AlphaBeta) {
c0 = c0 * norm.alpha + norm.beta;
c1 = c1 * norm.alpha + norm.beta;
c2 = c2 * norm.alpha + norm.beta;
}
int area = dst_width * dst_height;
float *pdst_c0 = dst + dy * dst_width + dx;
float *pdst_c1 = pdst_c0 + area;
float *pdst_c2 = pdst_c1 + area;
*pdst_c0 = c0;
*pdst_c1 = c1;
*pdst_c2 = c2;
}
static void warp_affine_bilinear_and_normalize_plane(uint8_t *src, int src_line_size, int src_width,
int src_height, float *dst, int dst_width,
int dst_height, float *matrix_2_3,
uint8_t const_value, const Norm &norm,
cudaStream_t stream) {
dim3 grid((dst_width + 31) / 32, (dst_height + 31) / 32);
dim3 block(32, 32);
checkKernel(warp_affine_bilinear_and_normalize_plane_kernel<<<grid, block, 0, stream>>>(
src, src_line_size, src_width, src_height, dst, dst_width, dst_height, const_value,
matrix_2_3, norm));
}
-
warp_affine_bilinear_and_normalize_plane_kernel为CUDA核函数,其功能是实现warpAffine和双线性插值的高性能预处理,这个相信都非常熟悉了,具体可参考YOLOv5推理详解及预处理高性能实现 -
warp_affine_bilinear_and_normalize_plane为host函数,目的是调用其对应的核函数
5.decode_mask
代码对应339-377行
static __global__ void decode_single_mask_kernel(int left, int top, float *mask_weights,
float *mask_predict, int mask_width,
int mask_height, unsigned char *mask_out,
int mask_dim, int out_width, int out_height) {
// mask_predict to mask_out
// mask_weights @ mask_predict
int dx = blockDim.x * blockIdx.x + threadIdx.x;
int dy = blockDim.y * blockIdx.y + threadIdx.y;
if (dx >= out_width || dy >= out_height) return;
int sx = left + dx;
int sy = top + dy;
if (sx < 0 || sx >= mask_width || sy < 0 || sy >= mask_height) {
mask_out[dy * out_width + dx] = 0;
return;
}
float cumprod = 0;
for (int ic = 0; ic < mask_dim; ++ic) {
float cval = mask_predict[(ic * mask_height + sy) * mask_width + sx];
float wval = mask_weights[ic];
cumprod += cval * wval;
}
float alpha = 1.0f / (1.0f + exp(-cumprod));
mask_out[dy * out_width + dx] = alpha * 255;
}
static void decode_single_mask(float left, float top, float *mask_weights, float *mask_predict,
int mask_width, int mask_height, unsigned char *mask_out,
int mask_dim, int out_width, int out_height, cudaStream_t stream) {
// mask_weights is mask_dim(32 element) gpu pointer
dim3 grid((out_width + 31) / 32, (out_height + 31) / 32);
dim3 block(32, 32);
checkKernel(decode_single_mask_kernel<<<grid, block, 0, stream>>>(
left, top, mask_weights, mask_predict, mask_width, mask_height, mask_out, mask_dim, out_width,
out_height));
}
- 实例分割的结果包括预测框的信息和对应的掩码图像,预测框的信息与目标检测相似,而掩码图像中的每个像素通常包含三个值,对应于三个掩码通道。这些掩码值经过sigmoid函数处理,以保证它们的范围在0~1之间。这些值反映了该像素在目标掩码中属于每个通道的概率。然后使用一组权重(mask_weights)将每个通道的掩码值缩放到合适的范围内,以生成每个像素的最终值。
- 解码操作是将模型输出的掩码信息转换为可视化的二值图像,即将掩码图像中的掩码值映射到像素值上。这样做的目的是方便可视化和后续的处理。
decode_single_mask_kernel为核函数,用于在GPU上对一个掩码图像进行解码操作。输入参数包括待解码的掩码图像、掩码权重、输出的掩码图像尺寸以及待解码的掩码图像在原始图像中的位置。输出参数是解码后的掩码图像。具体实现如下:- 将掩码图像中的像素坐标(dx,dy)转化为原始图像中的位置(sx,sy),如果(sx,sy)不在掩码图像中,则掩码值为0(
mask_out为一维数组,通过索引可以方便计算像素在一维速度中的位置)。其中dx和dy表示该线程的索引位置,代表了需要处理的输出掩码图像中的一个像素点。sx和sy表示该像素点在输入掩码图像中的位置。 - 对于每个掩码通道,计算其掩码值与对应权重的乘积,并将所有通道的结果相加
- 将所有通道的结果累加之后进行sigmoid激活,并将激活值乘以255作为输出的掩码值。
- 将掩码图像中的像素坐标(dx,dy)转化为原始图像中的位置(sx,sy),如果(sx,sy)不在掩码图像中,则掩码值为0(
decode_single_mask为host函数,目的是为了调用decode_single_mask_kernel核函数进行解码操作。- 对于
mask_out和mask_predict中的索引一头雾水,下面画了两张图简单说明下(也不知道画错没有) - 下面这张图用来说明
mask_predict掩码图像在内存中的存储方式,可以看到,我们平时看到的图像是二维的,但是在内存中,这个三通道掩码图像是连续存储的,即先存储第一个通道的所有像素值,然后是第二个通道的所有像素值,最后是第三个通道的所有像素值。那么如果我想要知道某个像素的某个通道的值,需要通过索引即dx和dy以及图像的宽高,并通过公式(ic * height + dy) * width + dx计算获得,其中ic是指三通道掩码图像的第i个通道。 - 我又想到了一种比较好的理解方式。首先我们假设图片是单通道,通过
dx和dy要获取其某个像素的值,计算方式是不是dy * width + dx,这里其实就是获取所有像素的b通道的值。假设图片是双通道,由于图片在内存中的存储是连续的,即将所有b通道的值存储完了才轮到g通道,如果要获取g通道的值,是不是得在原有dy * width +dx的基础上加上width * height的索引,即(1 * height + dy) * width + dx,其中width * height表示所有b通道,同理假设图片是三通道,如果要获取r通道的值,那么就要在dy * width + dx 加上 width * height的基础上再加上width * height,即(2 * height + dy) * width + dx,其中第二个width * height表示所有g通道,那么综上最终的索引就是(ic * height + dy) * width + dx,其中ic指三通道掩码图像的第i个通道。(罗里吧嗦一大堆,估计也就我自己能看懂了)
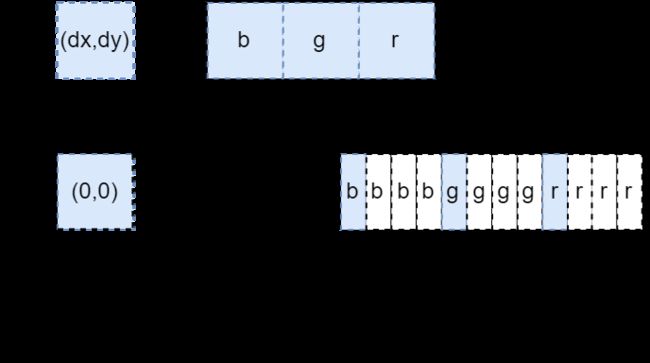
- 下面这张图用来说明
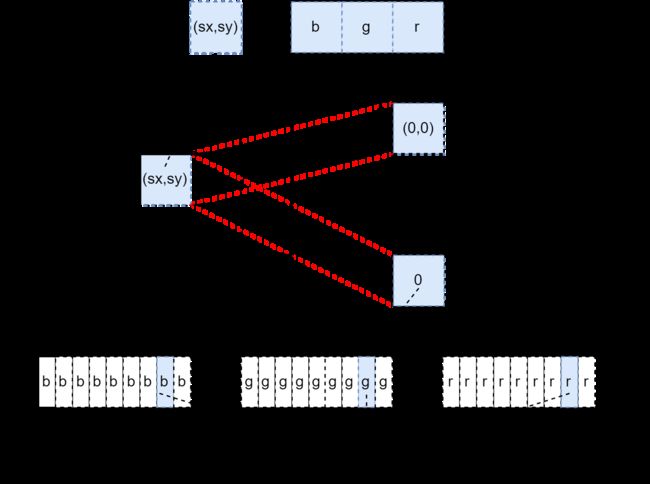
mask_out和mask_predict中的索引计算。对于mask_out比较好理解,它是单通道的,故没有ic这一说法,可以带入到上图中的公式得到dy * out_width +dx。对于mask_predict也比较好理解,就是将上图公式中的dy和dx替换为sy和sx,因为存在一个偏移,导致原点不再是(0,0),而是(left,top),因此其计算公式最终为(ic * mask_height + sy) * mask_width + sx
6.AffineMatrix
代码对应379-424行
const char *type_name(Type type) {
switch (type) {
case Type::V5:
return "YoloV5";
case Type::V3:
return "YoloV3";
case Type::V7:
return "YoloV7";
case Type::X:
return "YoloX";
case Type::V8:
return "YoloV8";
default:
return "Unknow";
}
}
struct AffineMatrix {
float i2d[6]; // image to dst(network), 2x3 matrix
float d2i[6]; // dst to image, 2x3 matrix
void compute(const std::tuple<int, int> &from, const std::tuple<int, int> &to) {
float scale_x = get<0>(to) / (float)get<0>(from);
float scale_y = get<1>(to) / (float)get<1>(from);
float scale = std::min(scale_x, scale_y);
i2d[0] = scale;
i2d[1] = 0;
i2d[2] = -scale * get<0>(from) * 0.5 + get<0>(to) * 0.5 + scale * 0.5 - 0.5;
i2d[3] = 0;
i2d[4] = scale;
i2d[5] = -scale * get<1>(from) * 0.5 + get<1>(to) * 0.5 + scale * 0.5 - 0.5;
double D = i2d[0] * i2d[4] - i2d[1] * i2d[3];
D = D != 0. ? double(1.) / D : double(0.);
double A11 = i2d[4] * D, A22 = i2d[0] * D, A12 = -i2d[1] * D, A21 = -i2d[3] * D;
double b1 = -A11 * i2d[2] - A12 * i2d[5];
double b2 = -A21 * i2d[2] - A22 * i2d[5];
d2i[0] = A11;
d2i[1] = A12;
d2i[2] = b1;
d2i[3] = A21;
d2i[4] = A22;
d2i[5] = b2;
}
};
-
type_name函数用于将目标检测网络枚举值转换成对应字符串名称 -
AffineMatrix结构体用于仿射变换矩阵的计算,仿射变换矩阵 M M M及其逆矩阵 M − 1 M^{-1} M−1相信大家都非常熟悉了,具体可参考YOLOv5推理详解及预处理高性能实现
7.InferImpl
代码对应于441-682行
infer的实现类
infer类的定义在yolo.hpp中,具体内容可参考下面:
class Infer {
public:
virtual BoxArray forward(const Image &image, void *stream = nullptr) = 0;
virtual std::vector<BoxArray> forwards(const std::vector<Image> &images,
void *stream = nullptr) = 0;
};
公有变量:
-
trt_:指向trt::Infer类的智能指针,用于保存加载的engine -
engine_file_:存储tensorRT引擎文件的路径 -
type_:模型类型,包含V5、X、V3、V7、V8、V8Seg -
confidence_threshold_:置信度阈值,用于过滤低置信度的检测结果 -
nms_threshold_:非极大值抑制阈值,用于剔除重叠的检测框 -
preprocess_buffers_:预处理后的输入图像数据的内存缓存 -
input_buffer_、bbox_predict_、output_boxarray_、segment_predict_:网络的输入数据内存缓存、模型预测结果、输出的边界框数组、分割预测结果 -
network_input_width_、network_input_height_:网络输入宽高 -
normalize_:用于指定图像预处理时是否进行归一化 -
box_head_dims_、segment_head_dims_:检测框和分割结果的维度信息- 针对yolov8n-seg.pt,
box_head_dims_维度为[1,8400,116],segment_head_dims_维度为[1,32,160,160]
- 针对yolov8n-seg.pt,
-
num_classes_:类别数量 -
has_segment_:标识模型是否存在分割 -
isdynamic_model_:标识模型是否存在动态shape -
box_segment_cache_:检测和分割结果的内存缓存,用于缓存检测结果以加速后续的处理
公有方法:
adjust_memory:根据输入图像大小自适应调整输入和输出内存缓冲区的大小preprocess:图像预处理load:模型加载forward:单张图片的推理forwards:多张图片的推理
7.1 adjust_memory
代码对应于462-478行
void adjust_memory(int batch_size) {
// the inference batch_size
size_t input_numel = network_input_width_ * network_input_height_ * 3;
input_buffer_.gpu(batch_size * input_numel);
bbox_predict_.gpu(batch_size * bbox_head_dims_[1] * bbox_head_dims_[2]);
output_boxarray_.gpu(batch_size * (32 + MAX_IMAGE_BOXES * NUM_BOX_ELEMENT));
output_boxarray_.cpu(batch_size * (32 + MAX_IMAGE_BOXES * NUM_BOX_ELEMENT));
if (has_segment_)
segment_predict_.gpu(batch_size * segment_head_dims_[1] * segment_head_dims_[2] *
segment_head_dims_[3]);
if ((int)preprocess_buffers_.size() < batch_size) {
for (int i = preprocess_buffers_.size(); i < batch_size; ++i)
preprocess_buffers_.push_back(make_shared<trt::Memory<unsigned char>>());
}
}
adjust_memory方法主要实现内存的分配input_numel为网络单张图要求的的内存大小,如640x640x3;input_buffer_为batch张图的内存;box_predict为网络预测结果的内存大小,如[batch,25200,85];output_boxarray_内存空间中32应该是一些辅助信息的存储空间(具体?)segment_predcit_为网络分割结果的内存大小,如[batch,32,160,160].(是这样吗?)- yolov8n.pt [1,8400,116] [1,32,160,160]
- 116 = 4(cx,cy,w,h) + 32(seg) + 80(num_classes)
- 最后调整预处理缓冲区
preprocess_buffers_的大小,使其至少能够存储batch个图像的数据
7.2 preprocess
void preprocess(int ibatch, const Image &image,
shared_ptr<trt::Memory<unsigned char>> preprocess_buffer, AffineMatrix &affine,
void *stream = nullptr) {
affine.compute(make_tuple(image.width, image.height),
make_tuple(network_input_width_, network_input_height_));
size_t input_numel = network_input_width_ * network_input_height_ * 3;
float *input_device = input_buffer_.gpu() + ibatch * input_numel;
size_t size_image = image.width * image.height * 3;
size_t size_matrix = upbound(sizeof(affine.d2i), 32);
uint8_t *gpu_workspace = preprocess_buffer->gpu(size_matrix + size_image);
float *affine_matrix_device = (float *)gpu_workspace;
uint8_t *image_device = gpu_workspace + size_matrix;
uint8_t *cpu_workspace = preprocess_buffer->cpu(size_matrix + size_image);
float *affine_matrix_host = (float *)cpu_workspace;
uint8_t *image_host = cpu_workspace + size_matrix;
// speed up
cudaStream_t stream_ = (cudaStream_t)stream;
memcpy(image_host, image.bgrptr, size_image);
memcpy(affine_matrix_host, affine.d2i, sizeof(affine.d2i));
checkRuntime(
cudaMemcpyAsync(image_device, image_host, size_image, cudaMemcpyHostToDevice, stream_));
checkRuntime(cudaMemcpyAsync(affine_matrix_device, affine_matrix_host, sizeof(affine.d2i),
cudaMemcpyHostToDevice, stream_));
warp_affine_bilinear_and_normalize_plane(image_device, image.width * 3, image.width,
image.height, input_device, network_input_width_,
network_input_height_, affine_matrix_device, 114,
normalize_, stream_);
}
preprocess方法的作用是对图像进行预处理操作- 首先调用AffineMatrix的compute方法,计算仿射变换矩阵
i2d及其逆矩阵d2i - 然后分配内存,准备输入数据和输出数据。首先计算输入数据的元素个数,然后根据元素个数在GPU上分配输入缓冲区的内存,接着在GPU上分配内存来存储变换矩阵和输入图像
- 为了在GPU上进行计算,需要将数据从CPU内存(host)复制到GPU内存(device),通过调用
cudaMemcpyAsync()进行复制 - 最后调用
warp_affine_bilinear_and_normalize_plane函数对图像进行仿射变换和归一化操作 stream是CUDA流对象,用于异步执行GPU操作
7.3 load
代码对应于513-553行
bool load(const string &engine_file, Type type, float confidence_threshold, float nms_threshold) {
trt_ = trt::load(engine_file);
if (trt_ == nullptr) return false;
trt_->print();
this->type_ = type;
this->confidence_threshold_ = confidence_threshold;
this->nms_threshold_ = nms_threshold;
auto input_dim = trt_->static_dims(0);
bbox_head_dims_ = trt_->static_dims(1);
has_segment_ = type == Type::V8Seg;
if (has_segment_) {
bbox_head_dims_ = trt_->static_dims(2);
segment_head_dims_ = trt_->static_dims(1);
}
network_input_width_ = input_dim[3];
network_input_height_ = input_dim[2];
isdynamic_model_ = trt_->has_dynamic_dim();
if (type == Type::V5 || type == Type::V3 || type == Type::V7) {
normalize_ = Norm::alpha_beta(1 / 255.0f, 0.0f, ChannelType::SwapRB);
num_classes_ = bbox_head_dims_[2] - 5;
} else if (type == Type::V8) {
normalize_ = Norm::alpha_beta(1 / 255.0f, 0.0f, ChannelType::SwapRB);
num_classes_ = bbox_head_dims_[2] - 4;
} else if (type == Type::V8Seg) {
normalize_ = Norm::alpha_beta(1 / 255.0f, 0.0f, ChannelType::SwapRB);
num_classes_ = bbox_head_dims_[2] - 4 - segment_head_dims_[1];
} else if (type == Type::X) {
// float mean[] = {0.485, 0.456, 0.406};
// float std[] = {0.229, 0.224, 0.225};
// normalize_ = Norm::mean_std(mean, std, 1/255.0f, ChannelType::SwapRB);
normalize_ = Norm::None();
num_classes_ = bbox_head_dims_[2] - 5;
} else {
INFO("Unsupport type %d", type);
}
return true;
}
-
load方法主要是调用tensorRT的load函数,加载engine_file对应的引擎文件,并将返回的指针保持在成员变量trt_中,如果加载失败,则返回false -
调用print函数(该函数的实现在infer.cu中),打印引擎文件的基本信息,如下面所示(yolov8n.pt输入和输出的基本情况)
[infer.cu:393]: Infer 0x559db77c50 [StaticShape] [infer.cu:405]: Inputs: 1 [infer.cu:409]: 0.images : shape {1x3x640x640} [infer.cu:412]: Outputs: 1 [infer.cu:416]: 0.output0 : shape {1x8400x84} -
根据engine中的网络结构,设置一些成员变量的值,包括
type_、confidence_threshold_、nms_threshold_、input_dim… -
根据
type的值即不同的网络模型,进行不同的归一化操作并计算出num_classes_- V5/V3/V7:
Norm::alpha_beta+num_classes_ = bbox_head_dims_[2] - 5 = 85 -5 = 80 - V8:
Norm::alpha_beta+num_classes_ = bbox_head_dims_[2] - 4 = 84 -4 = 80 - V8Seg:
Norm::alpha_beta+num_classes_ = bbox_head_dims_[2] - 4 - segment_head_dims_[1] = 116 - 4 - 32 = 80 - X:
Norm::None()+num_classes_ = bbox_head_dims_[2] - 5 = 85 -5 = 80
- V5/V3/V7:
7.4 forwards
代码对应于555-681行
virtual BoxArray forward(const Image &image, void *stream = nullptr) override {
auto output = forwards({image}, stream);
if (output.empty()) return {};
return output[0];
}
virtual vector<BoxArray> forwards(const vector<Image> &images, void *stream = nullptr) override {
int num_image = images.size();
if (num_image == 0) return {};
auto input_dims = trt_->static_dims(0);
int infer_batch_size = input_dims[0];
if (infer_batch_size != num_image) {
if (isdynamic_model_) {
infer_batch_size = num_image;
input_dims[0] = num_image;
if (!trt_->set_run_dims(0, input_dims)) return {};
} else {
if (infer_batch_size < num_image) {
INFO(
"When using static shape model, number of images[%d] must be "
"less than or equal to the maximum batch[%d].",
num_image, infer_batch_size);
return {};
}
}
}
adjust_memory(infer_batch_size);
vector<AffineMatrix> affine_matrixs(num_image);
cudaStream_t stream_ = (cudaStream_t)stream;
for (int i = 0; i < num_image; ++i)
preprocess(i, images[i], preprocess_buffers_[i], affine_matrixs[i], stream);
float *bbox_output_device = bbox_predict_.gpu();
vector<void *> bindings{input_buffer_.gpu(), bbox_output_device};
if (has_segment_) {
bindings = {input_buffer_.gpu(), segment_predict_.gpu(), bbox_output_device};
}
if (!trt_->forward(bindings, stream)) {
INFO("Failed to tensorRT forward.");
return {};
}
for (int ib = 0; ib < num_image; ++ib) {
float *boxarray_device =
output_boxarray_.gpu() + ib * (32 + MAX_IMAGE_BOXES * NUM_BOX_ELEMENT);
float *affine_matrix_device = (float *)preprocess_buffers_[ib]->gpu();
float *image_based_bbox_output =
bbox_output_device + ib * (bbox_head_dims_[1] * bbox_head_dims_[2]);
checkRuntime(cudaMemsetAsync(boxarray_device, 0, sizeof(int), stream_));
decode_kernel_invoker(image_based_bbox_output, bbox_head_dims_[1], num_classes_,
bbox_head_dims_[2], confidence_threshold_, nms_threshold_,
affine_matrix_device, boxarray_device, MAX_IMAGE_BOXES, type_, stream_);
}
checkRuntime(cudaMemcpyAsync(output_boxarray_.cpu(), output_boxarray_.gpu(),
output_boxarray_.gpu_bytes(), cudaMemcpyDeviceToHost, stream_));
checkRuntime(cudaStreamSynchronize(stream_));
vector<BoxArray> arrout(num_image);
int imemory = 0;
for (int ib = 0; ib < num_image; ++ib) {
float *parray = output_boxarray_.cpu() + ib * (32 + MAX_IMAGE_BOXES * NUM_BOX_ELEMENT);
int count = min(MAX_IMAGE_BOXES, (int)*parray);
BoxArray &output = arrout[ib];
output.reserve(count);
for (int i = 0; i < count; ++i) {
float *pbox = parray + 1 + i * NUM_BOX_ELEMENT;
int label = pbox[5];
int keepflag = pbox[6];
if (keepflag == 1) {
Box result_object_box(pbox[0], pbox[1], pbox[2], pbox[3], pbox[4], label);
if (has_segment_) {
int row_index = pbox[7];
int mask_dim = segment_head_dims_[1];
float *mask_weights = bbox_output_device +
(ib * bbox_head_dims_[1] + row_index) * bbox_head_dims_[2] +
num_classes_ + 4;
float *mask_head_predict = segment_predict_.gpu();
float left, top, right, bottom;
float *i2d = affine_matrixs[ib].i2d;
affine_project(i2d, pbox[0], pbox[1], &left, &top);
affine_project(i2d, pbox[2], pbox[3], &right, &bottom);
float box_width = right - left;
float box_height = bottom - top;
float scale_to_predict_x = segment_head_dims_[3] / (float)network_input_width_;
float scale_to_predict_y = segment_head_dims_[2] / (float)network_input_height_;
int mask_out_width = box_width * scale_to_predict_x + 0.5f;
int mask_out_height = box_height * scale_to_predict_y + 0.5f;
if (mask_out_width > 0 && mask_out_height > 0) {
if (imemory >= (int)box_segment_cache_.size()) {
box_segment_cache_.push_back(std::make_shared<trt::Memory<unsigned char>>());
}
int bytes_of_mask_out = mask_out_width * mask_out_height;
auto box_segment_output_memory = box_segment_cache_[imemory];
result_object_box.seg =
make_shared<InstanceSegmentMap>(mask_out_width, mask_out_height);
unsigned char *mask_out_device = box_segment_output_memory->gpu(bytes_of_mask_out);
unsigned char *mask_out_host = result_object_box.seg->data;
decode_single_mask(left * scale_to_predict_x, top * scale_to_predict_y, mask_weights,
mask_head_predict + ib * segment_head_dims_[1] *
segment_head_dims_[2] *
segment_head_dims_[3],
segment_head_dims_[3], segment_head_dims_[2], mask_out_device,
mask_dim, mask_out_width, mask_out_height, stream_);
checkRuntime(cudaMemcpyAsync(mask_out_host, mask_out_device,
box_segment_output_memory->gpu_bytes(),
cudaMemcpyDeviceToHost, stream_));
}
}
output.emplace_back(result_object_box);
}
}
}
if (has_segment_) checkRuntime(cudaStreamSynchronize(stream_));
return arrout;
}
forwards方法用于多张图像的推理- 检查模型输入维度中的batch大小与图像数量是否匹配,如果不匹配,则根据模型是否支持动态batch进行调整
- 调用
adjust_memory方法实现内存的分配 - 对每个输入图像进行预处理操作,得到仿射矩阵
affine_matrixs和预处理缓冲区preprocess_buffers_ - 设置tensorRT的输入和输出绑定,并执行前向传递
forward - 根据输出结果调用
decode_kernel_invoker解码每张图像中的目标框和类别信息 - 将结果从device上copy到host上,并将每张图像推理的结果以
BoxArray的形式保存到arrout容器后返回
8.其它
代码对应于684-738行
Infer *loadraw(const std::string &engine_file, Type type, float confidence_threshold,
float nms_threshold) {
InferImpl *impl = new InferImpl();
if (!impl->load(engine_file, type, confidence_threshold, nms_threshold)) {
delete impl;
impl = nullptr;
}
return impl;
}
shared_ptr<Infer> load(const string &engine_file, Type type, float confidence_threshold,
float nms_threshold) {
return std::shared_ptr<InferImpl>(
(InferImpl *)loadraw(engine_file, type, confidence_threshold, nms_threshold));
}
std::tuple<uint8_t, uint8_t, uint8_t> hsv2bgr(float h, float s, float v) {
const int h_i = static_cast<int>(h * 6);
const float f = h * 6 - h_i;
const float p = v * (1 - s);
const float q = v * (1 - f * s);
const float t = v * (1 - (1 - f) * s);
float r, g, b;
switch (h_i) {
case 0:
r = v, g = t, b = p;
break;
case 1:
r = q, g = v, b = p;
break;
case 2:
r = p, g = v, b = t;
break;
case 3:
r = p, g = q, b = v;
break;
case 4:
r = t, g = p, b = v;
break;
case 5:
r = v, g = p, b = q;
break;
default:
r = 1, g = 1, b = 1;
break;
}
return make_tuple(static_cast<uint8_t>(b * 255), static_cast<uint8_t>(g * 255),
static_cast<uint8_t>(r * 255));
}
std::tuple<uint8_t, uint8_t, uint8_t> random_color(int id) {
float h_plane = ((((unsigned int)id << 2) ^ 0x937151) % 100) / 100.0f;
float s_plane = ((((unsigned int)id << 3) ^ 0x315793) % 100) / 100.0f;
return hsv2bgr(h_plane, s_plane, 1);
}
-
Infer和InferImpl两个类分别为接口类(抽象类)和实现类(具体类),如load方法,Infer只提供说明具体实现是通过InferImpl类实现。这两个类的实现可以看作是RAII(资源获取即初始化)和接口模式的结合。(好专业的名字) -
RAII是一种C++编程技术,通过在对象构造函数中获取资源,在析构函数中释放资源,以保证资源被正确管理和释放。在这里
InferImpl类作为资源的实现类,通过load方法获取资源(即加载tensorRT引擎文件),然后在析构函数中释放资源。 -
接口模式则是一种设计模式,它将抽象类和实现类分离,通过接口类暴露一组公共接口,让用户可以方便地调用实现类地方法。在这里,
Infer类作为接口类,暴露出load、forward和其它公共接口,而InferImpl类则作为实现类,实现了具体的逻辑和算法。 -
hsv2bgr函数用于将hsv色域转换到bgr色域 -
random_color函数是随机颜色的生成,可作为绘制矩形框的颜色
9.拓展之yolo.hpp
#ifndef __YOLO_HPP__
#define __YOLO_HPP__
#include Type为枚举类,用于实现模型的选择如V5、V8等等- 结构体
InstanceSegmentMap用于表示实例分割的结果。其中,width和height表示分割结果的宽高,data指向一个unsigne char类型的数据,存储了分割结果的像素信息。 - 结构体
Box描述了预测框的基本信息 - 结构体
Image描述了一张图片的信息 - 后面就是类
Infer以及一些函数如load、hsv2bgr、random_color的定义
结语
博主在这里结合自身的学习情况对infer框架中的yolo.cu源码进行了简单的分析,更多细节需要各位看官自己去挖掘啦。感谢各位看到最后,创作不易,读后有收获的看官请帮忙点个⭐️。
参考
- infer
- yolo.cu