YARN组件
YARN组件
在生产环境中的大数据集群,所有作业或系统运行所需的资源,都不是直接向操作系统申请,而是交由资源管理器和调度框架代为申请。每个作业或系统所需的资源都是由资源管理和调度框架统一分配、协调。在业界中扮演这一角色的组件有YARN、Mesos等。
YARN的优点
(1)提高系统的资源利用率。
(2)协调不同作业/不同系统的资源,减少不同作业和不同系统之间的资源争抢。
(3)增强系统扩展性。资源管理和调度框架,允许硬件资源的动态伸缩,而不会影响作业的运行。
(4)资源调度与管理工具把控着资源的分配和任务的调度,直接影响程序的运行效率。
作为大数据集群的使用者,基于Hive做业务的开发者要高效地利用资源与调度管理工具,需要知道两方面的内容:
·YARN运行的基本组成和工作原理,能够基本理清程序运行的整体流程,知道哪些过程或者配置可能成为瓶颈,可以先不用了解,但一定要有意识。
·YARN资源调度与分配算法。
YARN基本组成
YARN的基本结构由一个ResourceManager与多个NodeManager组成。ResourceManager负责对NodeManager所持有的资源进行统一管理和调度。当在处理一个作业时ResourceManager会在NodeManager所在节点创建一全权负责单个作业运行和监控的程序ApplicationMaster。
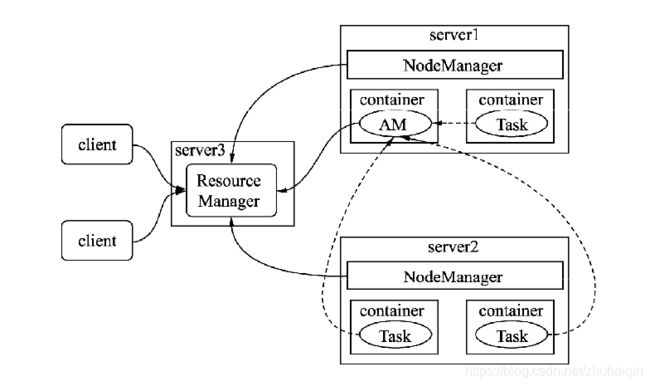
Hive作业在YARN的工作流程
1.ResouceManager(简称RM)
资源管理器负责整个集群资源的调度,该组件由两部分构成:调度器(Scheduler)和ApplicationsMaster(简称ASM)。
调度器会根据特定调度器实现调度算法,结合作业所在的队列资源容量,将资源按调度算法分配给每个任务。分配的资源将用容器(container)形式提供,容器是一个相对封闭独立的环境,已经将CPU、内存及任务运行所需环境条件封装在一起。通过容器可以很好地限定每个任务使用的资源量。YARN调度器目前在生产环境中被用得较多的有两种:能力调度器(Capacity Scheduler)和公平调度器(Fair Scheduler)。
2.ApplicationMaster(简称AM)
每个提交到集群的作业(job)都会有一个与之对应的AM来管理。它负责进行数据切分,并为当前应用程序向RM去申请资源,当申请到资源时会和NodeManager通信,启动容器并运行相应的任务。此外,AM还负责监控任务(task)的状态和执行的进度。
3.NodeManage(简称NM)
NodeManager负责管理集群中单个节点的资源和任务,每个节点对应一个NodeManager,NodeManager负责接收ApplicationMaster的请求启动容器,监控容器的运行状态,并监控当前节点状态及当前节点的资源使用情况和容器的运行情况,并定时回报给ResourceManager。
YARN工作流程
YARN在工作时主要会经历3个步骤:
(1)ResourceManager收集NodeManager反馈的资源信息,将这些资源分割成若干组,在YARN中以队列表示。
(2)当YARN接收用户提交的作业后,会尝试为作业创建一个代理ApplicationMaster。
(3)由ApplicationMaster将作业拆解成一个个任务(task),为每个任务申请运行所需的资源,并监控它们的运行。
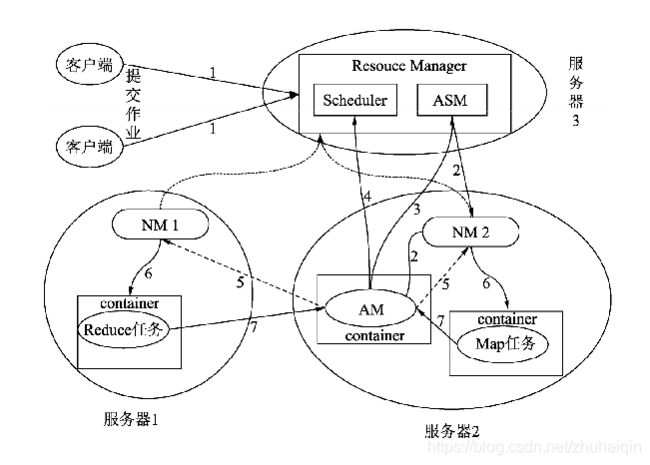
YARN内部组件交互图
YARN在处理任务时的工作流程经历了以下几个步骤:
(1)客户端向YARN提交一个作业(Application)。
(2)作业提交后,RM根据从NM收集的资源信息,在有足够资源的节点分配一个容器,并与对应的NM进行通信,要求它在该容器中启动AM。
(3)AM创建成功后向RM中的ASM注册自己,表示自己可以去管理一个作业(job)。
(4)AM注册成功后,会对作业需要处理的数据进行切分,然后向RM申请资源,RM会根据给定的调度策略提供给请求的资源AM。
(5)AM申请到资源成功后,会与集群中的NM通信,要求它启动任务。
(6)NM接收到AM的要求后,根据作业提供的信息,启动对应的任务。
(7)启动后的每个任务会定时向AM提供自己的状态信息和执行的进度。
(8)作业运行完成后AM会向ASM注销和关闭自己。
YARN资源调度器
资源调度器负责整个集群资源的管理与分配,是YARN的核心组件。开发者提交的Hive任务,所需的资源都需要经过该组件进行分配。如果提交的任务资源始终被抢占,或者被分配的资源很少,都会影响Hive的执行效率。
在YARN中,资源调度器以层次队列方式组织资源

YARN的application queues
这种组织方式,通过对不同队列资源进行分配和调整,可以适应多种对资源需求不同的作业同时使用,从而提高集群资源利用率。例如有些作业耗CPU资源,有些耗内存,可以分别将这种资源提交至各自资源较为充裕的队列。
YARN提供了3种调度器:先来先服务调度器(FIFO Scheduler)、能力调度器(Capacity Scheduler)和公平调度器(Fair Scheduler)。
FIFO即先来先服务,是Hadoop在设计之初使用的调度方式。这种方式不能充分利用集群的硬件资源,在面对资源需求不同的作业而无法提供根据灵活的调度策略,导致作业某些空闲资源被某个正在运行的资源所占用,正在等待的资源的作业无法获取集群资源进行运行。
为了克服单队列的先来先服务的调度先天不足,YARN提供了多用户的多队列的调度器。在生产环境中经常被使用到的是能力调度器和公平调度器。
在YARN中可供分配和管理的资源有内存和CPU资源,在Hadoop 3.0中将GPU、FPGA资源也纳入可管理的资源中。内存和CPU资源可以通过下面的配置选项进行调整:
·yarn.nodemanager.resource.cpu-vcores,默认值为-1。默认表示集群中每个节点可被分配的虚拟CPU个数为8。为什么这里不是物理CPU个数?因为考虑一个集群中所有的机器配置不可能一样,即使同样是16核心的CPU性能也会有所差异,所以YARN在物理CPU和用户之间加了一层虚拟CPU,一个物理CPU可以被划分成多个虚拟的CPU。
·yarn.nodemanager.resource.detect-hardware-capabilities为true,且该配置还是默认值-1,YARN会进行自动给计算可用虚拟CPU。
·yarn.nodemanager.resource.memory-mb,默认值为-1。当该值为-1时,默认表示集群中每个节点可被分配的物理内存是8GB。
·yarn.nodemanager.resource.detect-hardware-capabilities为true,且该配置还是默认值-1,YARN会自动计算可用物理内存。
·yarn.nodemanager.vmem-pmem-ratio,默认值为2.1。该值为可使用的虚拟内存除以物理内存,即YARN中任务的单位物理内存相对应可使用的虚拟内存。例如,任务每分配1MB的物理内存,虚拟内存最大可使用2.1MB。
·yarn.nodemanager.resource.system-reserved-memory-mb,YARN保留的物理内存,给非YARN任务使用,该值一般不生效,只有当yarn.nodemanager.resource.detect-hardware-capabilities为true的状态才会启用,会根据系统的情况自动计算。
如果发现自身集群资源非常充裕,但是程序运行又较为缓慢,整个集群的资源利用率又很低,就需要关注上面的配置是否设置得过低。
用户提交给YARN的作业及所申请的资源,YARN最终是以容器的形式调拨给作业,每个作业分解到子任务运行容器中,YARN分配给容器的相关配置可以通过如下配置项目调整:
yarn.scheduler.minimum-allocation-mb:默认值1024MB,是每个容器请求被分配的最小内存。如果容器请求的内存资源小于该值,会以1024MB进行分配;如果NodeManager可被分配的内存小于该值,则该NodeManager将会被ResouceManager给关闭。
yarn.scheduler.maximum-allocation-mb:默认值8096MB,是每个容器请求被分配的最大内存。如果容器请求的资源超过该值,程序会抛出InvalidResourceRequest Exception的异常。
·yarn.scheduler.minimum-allocation-vcores:默认值1,是每个容器请求被分配的最少虚拟CPU个数,低于此值的请求将被设置为此属性的值。此外,配置为虚拟内核少于此值的NodeManager将被ResouceManager关闭。
·yarn.scheduler.maximum-allocation-vcores:默认值4,是每个容器请求被分配的最少虚拟CPU个数,高于此值的请求将抛出InvalidResourceRequestException的异常。
如果开发者所提交的作业需要处理的数据量较大,需要关注上面配置项的配置。
YARN还能对容器使用的硬件资源进行控制,通过如下的配置:
yarn.nodemanager.resource.percentage-physical-cpu-limit:默认值100。一个节点内所有容器所能使用的物理CPU的占比,默认为100%。即如果一台机器有16核,CPU的使用率最大为1600%,且该比值为100%,则所有容器最多能使用的CPU资源为1600%,如果该比值为50%,则所有容器能使用的CPU资源为800%。
yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage:默认值为false,表示开启CPU的共享模式。共享模式告诉系统容器除了能够使用被分配的CPU资源外,还能使用空闲的CPU资源。