从数据驱动到领域驱动——领域驱动设计中的数据库设计
1.数据驱动到领域驱动
接到需求和任务不管三七二十一,拿起键盘噼里啪啦一把梭,业务流程还没捂热,数据表一二三四就建了出来。粗放的软件开发更关注实现可以直接交付的,领域驱动设计重新捡起了这块,将软件迭代维护的成本大幅降低在模型实现前期。
能够达成这样的目标的原因是以数据驱动设计软件凭借直观凭借经验,容易忽视业务知识的挖掘,遗漏的关键知识会在编码与测试中找补回来,修改破坏表结构的成本是高昂的,表设计锁死了软件的性能与可扩展性。
更糟糕的是,表设计决定的软件设计使得技术人员与业务人员的沟通障碍越来越大,因为不管是数据模型还是建表语句都是研发术语,业务方很难理解。业务方再有需求,技术人员要转换成研发术语,至于能否对得上之前的软件设计,那就听天由命了。不慎再次陷入了需求变更就要修改数据库设计的泥潭,如此往复,软件实现一潭死水,何谈弹性、快速响应业务。
需要大量协作围绕业务开展软件工程的企业软件开发迎来了变革——领域驱动设计打破了这一僵局,开发模式从面向实现面向过程的数据驱动变成了面向领域的领域驱动。
依然是借助领域模型,建立起业务与技术的桥梁,在数据库设计前充分建模领域,根据领域设计数据库。实现与需求绑定在领域模型上,数据库设计作为模型实现部分也是如此。技术人员通过领域模型与领域专家充分求同需求,根据领域模型再去设计数据库,领域知识的沟通与软件实现的扩展性得以有效解决。
补充说明一下,这里所说的数据库设计,从软件工程上讲叫做建立物理数据模型(Physical Data Model, PDM),主要目的是对数据表进行设计。至于数据库的逻辑数据模型,可参考ER图,领域模型图与之类似但是表达能力是强于ER图的。
领域驱动设计重视可视化,同事件风暴与领域建模一样,数据库设计虽然没有UML国际标准,这里依然通过模型图示来展示。
2.数据库设计
2.1 表设计基础
表设计关注的是表名、PK、FK以及字段,字段包括字段名、字段类型以及字段约束。
有了领域模型,再去做表设计会容易很多。
简单地,一个实体建立一张表,实体的属性就是表中的字段,使用没有业务属性的自增id作为主键。
关联关系对应于表关联。多重性的值对应于字段约束,多重性的值不包含0需要添加NOT NULL非空约束。
一对多关联映射为一个外键,这里先采用虚拟外键,关于真正的外键是否建立我们最后一起讨论,绘图就通过虚线箭头表示外键参照关系。
多对多关联则需要在两张表之间一个关联表,使用原来两表的主键形成联合主键。
2.2 审计字段
审计字段,可以用来进行安全审计和错误排查,作为每张表的标配。
提供created_at,created_by,last_updated_at 和 last_updated_by 分别表示一条记录的创建时间、创建人、最后一次修改时间和最后一次修改人。 创建人和最后修改人保存的是用户的 id。
3.如何开展数据库设计
3.1 建表
继续我们的虚拟项目举例,在领域建模后业务方与技术方初步达成业务知识一致,就是这个领域模型,以及对应的统一语言规则表。
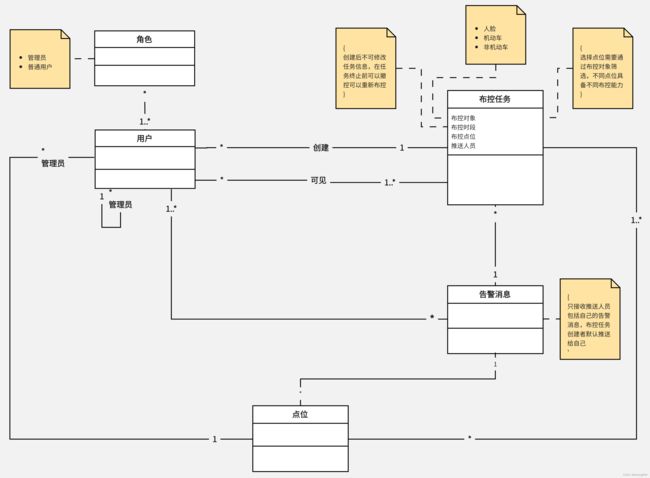
例子作为最小闭环,依然是简单地先就实体建表。根据统一语言及研发规范设计表明,初步得到用户(user)、角色(role)、点位(camera)、布控任务(control_task)和告警消息(alarm_message)这几张表。
用整型自增id作为各表主键,其他字段可以根据实体属性写上一部分,在表关联建立中继续完善。
3.2 建立表关联
根据实体关联建立表关联,一对多关联直接建立外键,多对多增加关联表建立联合主键。关联上的多重性的值决定了属性的非空约束。
比如对于用户创建布控任务这个行为而言,一个用户可以创建任意多个布控任务,但是一个布控任务只能由一个用户创建。在用户表与布控任务表之间建立关联,由布控任务表提供用户id外键指向用户表,并根据多重性约束将用户id的字段约束设置为NOT NULL。
但是对于用户可见布控任务这个行为而言就有所不同了,一个用户可见任意多个布控任务,一个布控任务也可被任意多个用户可见。单一的外键关联已经不能满足表设计要求了,于是在两表之间建立用户布控任务关联表user_control_task。该表使用用户id和布控任务id作为联合主键,并且将用户id作为外键关联用户表,将布控任务id作为外键关联布控任务表。
有了领域模型,数据库设计可以很快完成,如图所示。

4.继续探讨数据库设计
4.1 主键与id
关系型数据库中的主键设计至关重要,作为身份标识需要保证每张表内的唯一性,在领域模型设计中还需要与外键关联实现领域模型之间的导航。
主键既要有业务含义又要保证唯一是看似不可行的。
为了达到数据库设计统一,推荐每张表使用字段名为id的字段,与上文的审计字段一样成为数据库通用设计要求,id字段可为整型自增。相当于约定优于配置,所有技术人员都知道id是主键,没有业务含义。这样做的好处还包括不会因为业务变化导致带有业务含义的主键变化。
另一方面,在数据表提供业务能力时,还希望有一个业务主键,唯一标识业务记录,实现对实体对象生命周期的管理跟踪。与前者不同的是,不仅是主键字段的唯一性,而是整条记录的唯一性。
例子中为了最小闭环方便演示使用了没有业务含义的id作为主键,领域驱动设计中还可以使用值对象,达成上述两个诉求既符合技术要求又有业务含义,JPA中通过@EmbeddedId注解实现。这个在后面介绍聚合与值对象再深入探讨。
4.2 外键与join
企业软件开发中,基本不推荐甚至禁止使用外键,所有外键在应用层程序实现,做数据库设计时表达领域关系保留外键关系,也就是举例中虚线箭头表示的虚拟外键。禁止真实外键原因在于数据级联更新是会导致数据库阻塞,可能会造成数据库级联更新风暴以及写入性能,尤其是云服务中分库分表成为基础设施,外键更没了生存空间,仅仅成为逻辑设计需要。
不能外键关联如何提高数据关联查询效率呢,有一种办法是增加冗余,虽然违反第三范式,但是可以快速支撑业务实现。增加冗余需要重点关注数据一致性的问题,不能是频繁更新字段、不能是唯一索引的字段。
不能外键关联外怎么使用join呢,这也是需要规范限制的。需要被关联的字段必须有索引,比如MySQL使用建立索引的join会使用 Index Nested-Loop Join执行,而被驱动表不使用索引只能使用Block Nested-Loop Join执行,执行效率差距巨大。同时,限制join表数量阿里云给的建议是不超过3,也要尽量保证小表驱动,即经过滤参与join字段的数据量。
随着数字化转型深入,企业架构组织上逐渐分离出数据部门,专门处理海量业务数据,提供数据服务供上层应用使用,这样,应用只需要处理内部的一亩三分地,其余的交给大数据、云等基础设施完成了。
参考
- 极客时间钟敬老师DDD专栏(强烈推荐)