机器学习与知识发现_知识图谱与机器学习|KG入门 -- Part1 Data Fabric
语义和Data Fabric的新进展如何帮助我们更好地进行机器学习

介绍
如果你在网上搜索机器学习,你会找到大约20500万个结果。确实是这样,但是要找到适合每个用例的描述或定义并不容易,然而会有一些非常棒的描述或定义。在这里,我将提出机器学习的另一种定义,重点介绍一种新的范式——Data Fabric[1]。
1 什么是Data Fabric?

讨论Data Fabric时,我们应该提到几个词:图(graphs)、知识图谱(knowledge-graph)、本体(ontology)、语义(semantics)、链接数据(linked-data)。在你对这些定义有所了解后,我们可以说:
Data Fabric是支持企业所有数据的平台,它作为一个统一的框架来管理、描述、组合和访问数据。该平台由企业知识图谱构成以创建统一的数据环境。
我们把这个定义拆分成几部分。我们首先需要的是一个知识图谱。
知识图谱由数据和信息组成,还包含大量不同数据之间的链接。这里的关键是,在这个新模型下,我们不是在寻找可能的答案,而是在寻找确定的答案。我们想要的是事实——这些事实来自哪里并不那么重要。这里的数据可以代表概念、对象、事物、人,以及你头脑中的任何东西。图中填充了概念之间的关系和联系。
知识图谱还允许你为图中的关系创建结构。有了它,就可以建立一个框架来研究数据及其与其他数据的关系。
在这种情况下,我们可以向我们的数据湖(Data Lake)提出这个问题:这里存在什么?
数据湖的概念也很重要,因为我们需要一个地方来存储数据、管理数据并运行我们的任务。但我们需要一个智能数据湖,一个能理解我们拥有什么以及如何使用它的地方,这是拥有Data Fabric的好处之一。
Data Fabric应该是统一的,这意味着我们应该努力将组织中的所有数据组织在一个地方并真正地管理它。
2 什么是机器学习?
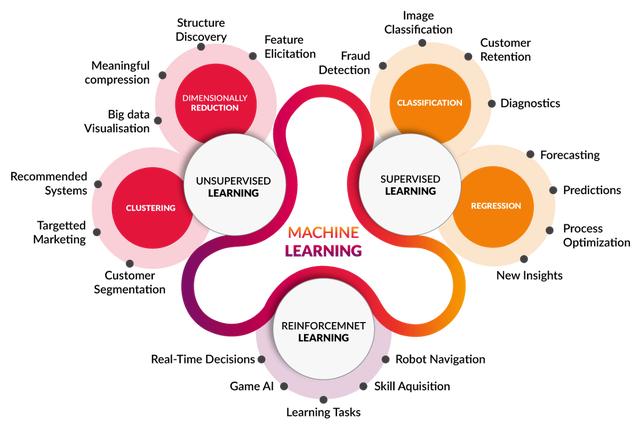
机器学习已经存在很长时间了,有很多关于它的描述、书籍、文章和博客,所以我不会用太多的章节来描述它,而只是把一些观点说清楚。
- 机器学习不是魔法
- 机器学习是数据科学工作流程的一部分
- 机器学习需要数据的存在,至少现在是这样。
在这之后,让我给机器学习一个有点像借用来的和个性化的定义:
机器学习是一种自动的过程,通过使用算法来理解数据中的模式和一些数据表示,这些算法能够提取那些模式,而无需专门为此编写程序,从而创建能够解决特定(或多个)问题的模型。
你可以同意也可以不同意这个定义,现在的文献中有很多很好的定义,我只是觉得这个很简单,对我想表达的东西很有用。
3 在Data Fabric中进行机器学习
在爱因斯坦的引力理论(广义相对论)中,他从数学上提出质量可以使时空变形,而这种变形就是我们所理解的引力。我知道如果你不熟悉这个理论,听起来会很奇怪。我来解释一下。
在没有引力的狭义相对论的平行时空中,力学定律呈现出一种特别简单的形式:只要没有外力作用于一个物体上,它将沿着一条直线通过时空:沿着一条直线,以一个恒定的速度(牛顿力学第一定律)。
但是当我们有质量和加速度时,我们可以说我们处于重力之下。像Wheeler所说:
Spacetime tells matter how to move; matter tells spacetime how to curve.(时空告诉物质如何运动;物质告诉时空如何弯曲。)
在上图中,“立方体”是时空结构的一种表现,当物体在其中移动时,它会变形,“线”移动的方式会告诉我们,一个靠近的物体会如何靠近那个物体。所以重力像是下面这样的:
所以当我们有质量时,我们可以在时空中做一个“凹痕”,在那之后,当我们接近那个凹痕时,我们看到的是重力。我们必须离物体足够近才能感觉到它。
这正是我所提到的机器学习在Data Fabric中的作用。我知道听起来很疯狂,所以让我解释一下。
假设我们创建了一个Data Fabric,对我来说,最好的工具是Anzo。

你可以使用Anzo构建所谓的“企业知识图谱”,当然也创建了你的Data Fabric。
图的节点和边灵活地捕获了每个数据源的高分辨率孪生体——结构化或非结构化。该图可以帮助用户快速、交互式地回答任何问题,允许用户与数据进行对话,从而发现问题的“洞察力”(insights)。
顺便说一下,我是这样描绘一个“洞察力”(insight)的:

如果我们有Data Fabric:

我所建议的是一种“洞察力”(insight)可以被认为是它的一个凹痕。而发现这种“洞察力”(insight)的自动过程,就是机器学习。

所以现在我们可以说:
机器学习是一种自动发现Data Fabric中隐藏的“洞察力”(insight)的过程,它使用的算法能够发现这些“洞察力”(insight),而无需专门为此编写程序,从而创建模型来解决特定(或多个)问题。
使用fabric生成的“洞察力”(insight)本身就是新数据,作为fabric的一部分而变得明确。也就是说“洞察力”(insight)可以扩增图,可能会产生进一步的“洞察力”(insight)。
在Data Fabric中,我们遇到了一个问题,试图在数据中找到那些隐藏的“洞察力”(insight),使用机器学习我们可以发现它们。这在现实生活中会是什么样子?
Cambridge Semantics研究人员也用Anzo给出了答案,使用Anzo进行机器学习的解决方案用一个现代化的数据平台取代了这种单调乏味、容易出错的工作,该数据平台旨在快速集成、协调和将来自所有相关数据源的数据转换为优化的机器学习特性数据集。
Data Fabric提供了高级数据转换功能,这是快速有效的特性工程所必需的,可以帮助将关键的业务信号从无关的噪声中分离出来。
记住,数据是第一位的,这个新的范示使用内置的图形数据库和语义数据层集成和协调所有相关的数据源——结构化和非结构化数据都是如此。Data Fabric传递数据的业务上下文和含义,使业务用户更容易理解和正确使用数据。
重现性(reproducibility)对于数据科学和机器学习非常重要,因此我们需要通过管理数据集目录以及数据集成等方面,像数据质量处理,来轻松地重用和协调结构化和非结构化数据,这就是Data Fabric所提供的。它还保留了包含机器学习数据集的数据的端到端的起源,因此在生产中使用模型时很容易找出所需的数据转换。
在接下来的文章中,我将给出一个关于如何在这个新框架中进行机器学习的具体例子。
4 总结
机器学习并不新鲜,但它有一个新的范式,也许这就是这个领域的未来(这么说可能有点乐观)。在Data Fabric内部,提出了本体、语义、层次、知识图谱等新概念;但所有这些都可以改善我们思考和进行机器学习的方式。
在这个范式中,我们通过使用算法来发现Data Fabric中隐藏的“洞察力”(insight),这些算法能够发现这些“洞察力”(insight),而无需专门为此编写程序,从而创建模型来解决特定(或多个)问题。
下一篇我们将为大家介绍Data Fabric上的深度学习。