深度学习卷积神经网络CNN之GoogLeNet模型网络模型详解说明(超详细理论篇)
1.GoogLeNet背景
2. GoogLeNet改进史
3. GoogLeNet模型结构
4. 特点(超详细创新、优缺点及新知识点)
一、GoogLeNet背景
GoogLeNet在2014年的ImageNet竞赛中获得了分类任务第1名的好成绩,在大规模视觉挑战赛(ILSVRC-2014)上使用的一种全新卷积神经网络结构,并以6.65%的错误率力压VGGNet等模型取得了ILSVRC-2014在分类任务上的冠军,于2015年在CVPR发表了论文《Going Deeper with Convolutions》,GoogleNet是Google研发的深度网络结构,而叫“GoogLeNet”?答案是为了向LeNet致敬,一语双关因此取名为GoogLeNet。
二、 GoogLeNet改进史
在随后的两年中一直在改进,形成了Inception V2、Inception V3、Inception V4等版本。以下是四篇论文及地址
1.inception-v1:Going deeper with convolutions
https://www.cs.unc.edu/~wliu/papers/GoogLeNet.pdf
2.inception-v2:Batch Normalization: Accelerating Deep Network Training byReducing Internal Covariate Shift
http://proceedings.mlr.press/v37/ioffe15.pdf
3.inception-v3: Rethinking the Inception Architecture for Computer Vision
https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Szegedy_Rethinking_the_Inception_CVPR_2016_paper.pdf
4.Inception-v4: Inception-ResNet and the Impact of Residual Connections on Learning
https://arxiv.org/abs/1602.07261
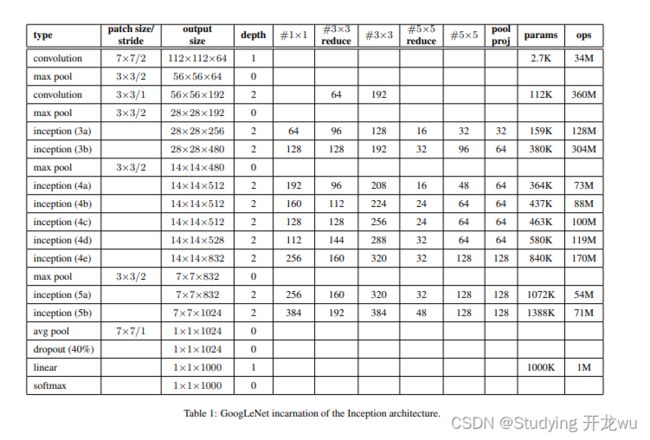
三、GoogLeNet模型结构(论文中给出了表格)
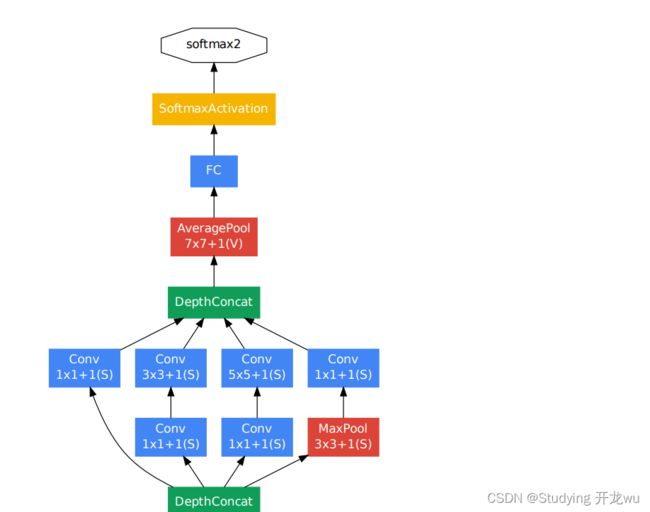

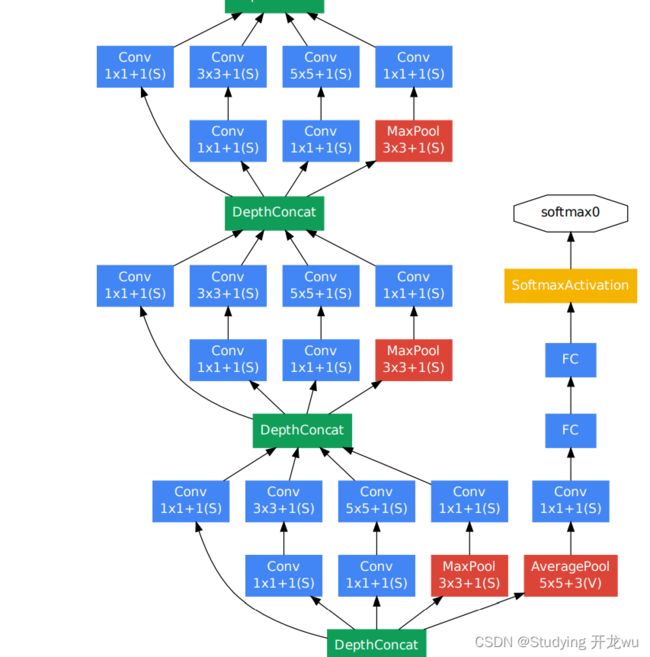
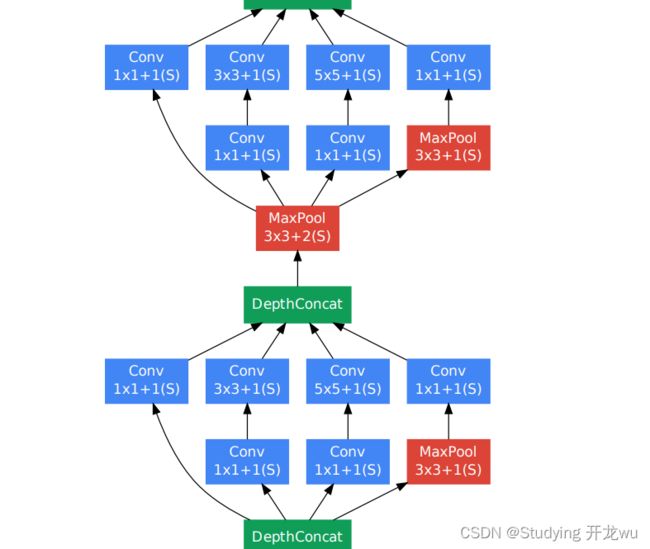
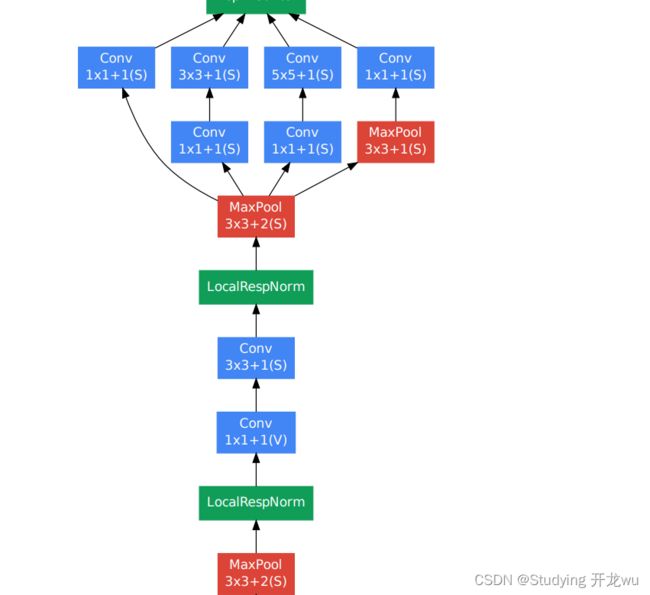
以inception(3a)模块为例(第一个Inception块):
输入:28x28x192
第一个分支: 卷积核尺寸1x1,filters =64,strides = 1,padding = ‘same’,outputsize = 28x28x64
第二个分支:
卷积核尺寸1x1, filters = 96,strides = 1,padding = ‘same’,outputsize = 28x28x96
卷积核尺寸3x3, filters = 128,strides = 1,padding = ‘same’,outputsize = 28x28x128
第三个分支:
卷积核尺寸1x1, filters = 16,strides = 1,padding = ‘same’,outputsize = 28x28x16
卷积核尺寸5x5, filters = 32,strides = 1,padding = ‘same’,outputsize = 28x28x32
第四个分支:
pool_size = 3x3, strides = 1,padding = ‘same’,outputsize = 28x28x192
卷积核尺寸1x1, filters = 32,strides = 1,padding = ‘same’,outputsize = 28x28x32
concatenation outputsize:
28x28x(64+128+32+32) = 28x28x256
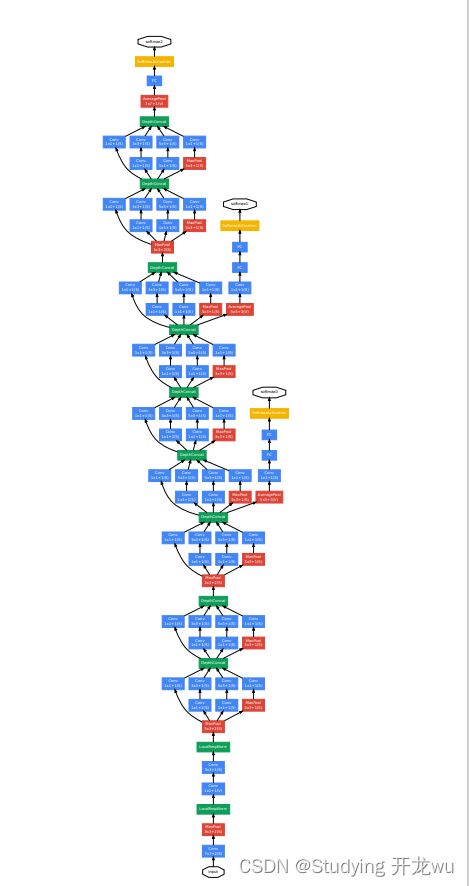
&emspGoogLeNet网络有22层深(包括pool层,有27层深),在分类器之前,采用Network in Network中用Averagepool(平均池化)来代替全连接层的思想,而在avg pool之后,还是添加了一个全连接层,是为了大家做finetune(微调)。
四、特点(以V1主说创新、优缺点及新知识点)
1.提出Inception结构
Inception就是把多个卷积或池化操作,放在一起组装成一个网络模块,设计神经网络时以模块为单位去组装整个网络结构,Inception 最初提出的版本主要思想是利用不同大小的卷积核实现不同尺度的感知
在我们之前模型结构中就说过,提升网络性能的办法就是增加网络深度和宽度,但增加会带来很多问题:
1)参数太多,如果训练数据集有限,很容易产生过拟合;
2)网络越大、参数越多,计算复杂度越大,难以应用;
3)网络越深,容易出现梯度弥散问题(梯度越往后穿越容易消失),难以优化模型。
我们希望在增加网络深度和宽度的同时减少参数,为了减少参数,自然就想到将全连接变成稀疏连接。下面是V1里Inception结构图
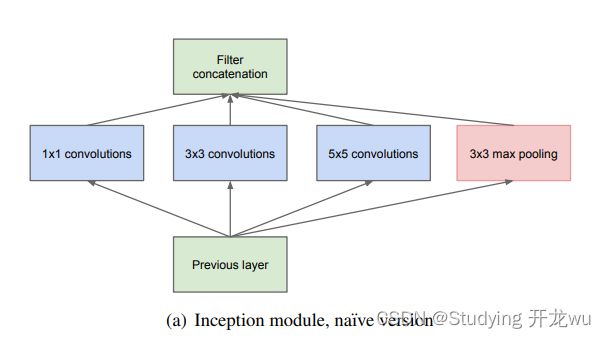
组成结构有四个成分:11卷积,33卷积,55卷积,33最大池化
在以前的网络里,我们一层串行执行这里是并行串起来,比如卷积或者池化,而且卷积操作的卷积核尺寸也是固定大小的。但是,在实际情况下,在不同尺度的图片里,需要不同大小的卷积核,这样才能使性能最好,或者或,对于同一张图片,不同尺寸的卷积核的表现效果是不一样的,因为他们的感受野不同。
举例
假设上图中输入是32×32×256的特征图,该特征图被复制成4份并分别传至下4个部分。我们假设这4个部分对应的滑动窗口的步长均为1,其中,1×1卷积层的Padding为0,滑动窗口维度为1×1×256,要求输出的特征图深度为128;3×3卷积层的Padding为1,滑动窗口维度为3×3×256,要求输出的特征图深度为192;5×5卷积层的Padding为2,滑动窗口维度为5×5×256,要求输出的特征图深度为96;3×3最大池化层的 Padding为1,滑动窗口维度为3×3×256。分别得到这4部分输出的特征图为32×32×128、32×32×192、32×32×96 和 32×32×256,最后在合并层进行合并,得到32×32×672的特征图,合并的方法是将各个部分输出的特征图相加,最后这个Naive Inception单元输出的特征图维度是32×32×672,总的参数量就是1* 1* 256* 128+3* 3* 256* 192+5* 5* 256* 96=1089536
2. 1 * 1的卷积核降维
减少参数量来减少计算量,在受到了模型 “Network in Network”的启发,开发出了在GoogleNet模型中使用的Inception单元(Inception V1),这种方法可以看做是一个额外的1*1卷积层再加上一个ReLU层。
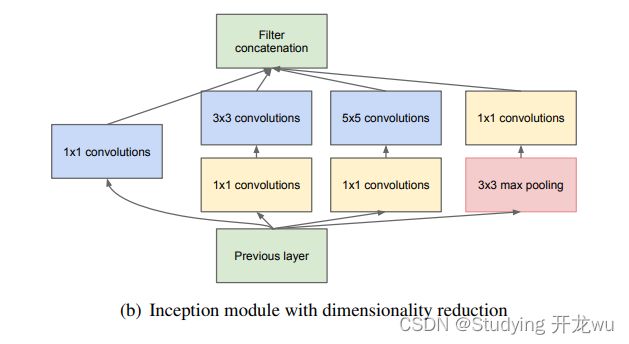
*使用1x1 卷积核主要目的是进行压缩降维,减少参数量,从而让网络更深、更宽,更好的提取特征,这种思想也称为Pointwise Conv,简称PW。
3.两个辅助分类器帮助训练
作用有两点,一是为了避免梯度消失,用于向前传导梯度。反向传播时如果有一层求导为0,链式求导结果则为0。二是将中间某一层输出用作分类,起到模型融合作用。
辅助函数Axuiliary Function:从信息流动的角度看梯度消失,因为是梯度信息在BP过程中能量衰减,无法到达浅层区域,因此在中间开个口子,加个辅助损失函数直接为浅层。
GoogLeNet网络结构中有深层和浅层2个分类器,为了避免梯度消失,两个辅助分类器结构是一模一样的,其组成如下图所示,这两个辅助分类器的输入分别来自Inception(4a)和Inception(4d)。
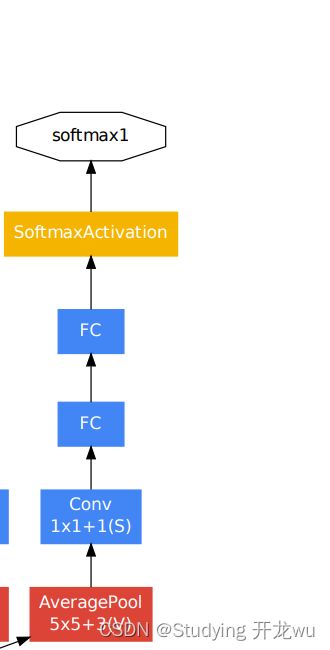
辅助分类器的第一层是一个平均池化下采样层,池化核大小为5x5,stride=3;第二层是卷积层,卷积核大小为1x1,stride=1,卷积核个数是128;第三层是全连接层,节点个数是1024;第四层是全连接层,节点个数是1000(对应分类的类别个数)。
辅助分类器只是在训练时使用,在正常预测时会被去掉。辅助分类器促进了更稳定的学习和更好的收敛,往往在接近训练结束时,辅助分支网络开始超越没有任何分支的网络的准确性,达到了更高的水平。
4.丢弃全连接层,使用平均池化层(大大减少模型参数)
网络最后采用了average pooling(平均池化)来代替全连接层,该想法来自NIN(Network in Network),事实证明这样可以将准确率提高0.6%。