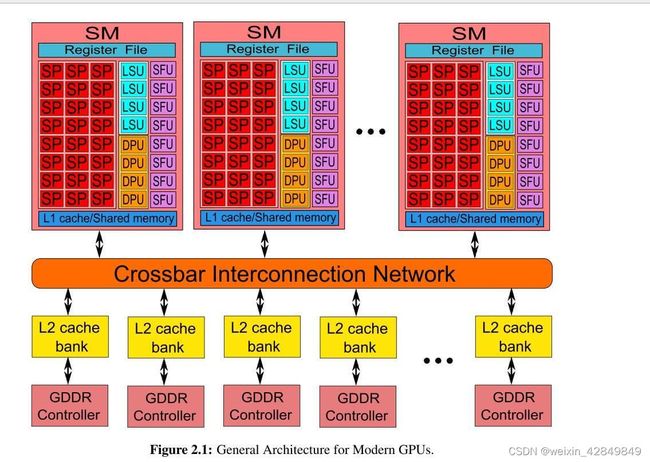
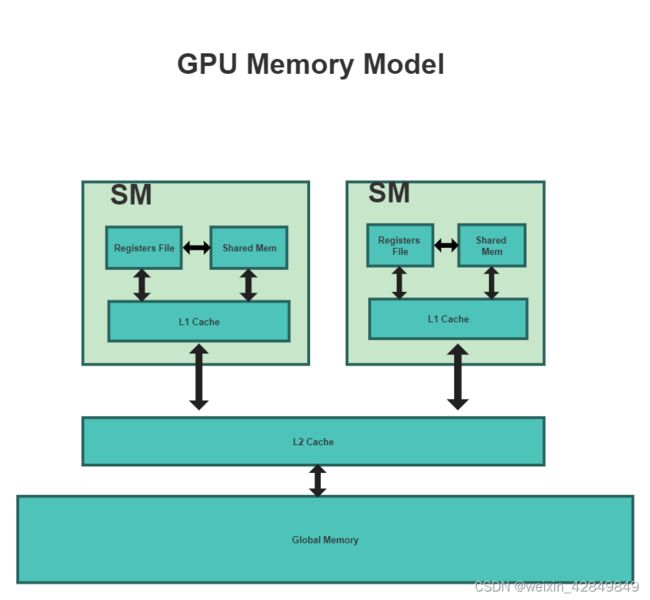
- cuda编程python接口_使用Python写CUDA程序的方法
weixin_39822184
cuda编程python接口
使用Python写CUDA程序有两种方式:*Numba*PyCUDAnumbapro现在已经不推荐使用了,功能被拆分并分别被集成到accelerate和Numba了。例子numbaNumba通过及时编译机制(JIT)优化Python代码,Numba可以针对本机的硬件环境进行优化,同时支持CPU和GPU的优化,并且可以和Numpy集成,使Python代码可以在GPU上运行,只需在函数上方加上相关的指
- Python成第四个支持CUDA的编程语言
Python成第四个支持CUDA的编程语言3月19日NVIDIA的GTC2013图形技术大会将开幕,在此之前会有很多宣传造势内容,其中最重大也是最主要的就是NVIDIA老总黄仁勋的开幕词了,其他合作伙伴也会发布各自的演讲。ContinuumAnalytics联合NVIDIA宣布将会引入新的PythonCUDA编译器——NumbaPro,Python也成为继C、C++以及Fortan之后的第四个支持
- 从 0 到 1 搞定nvidia 独显推流:硬件视频编码环境安装完整学习笔记
lxmyzzs
图像算法之音视频编解码音视频学习笔记
笔记用于安装和配置一套完整的媒体处理工具链,包括NVIDIA编码头文件、带CUDA加速的FFmpeg以及ZLMediaKit流媒体服务框架,适用于需要进行视频编解码、流媒体推流/拉流等场景的开发与部署。标题核心组件及版本说明nv-codec-headers来源:Gitee仓库jario-jin/nv-codec-headers版本:n11.1.5.0(对应NVIDIAVideoCodecSDK接口
- 【Python 语法】Python 神经网络项目常用语法
一杯水果茶!
人生苦短我用Pythonpython
基础1.导入模块和包2.修改系统路径(sys.path.append)3.命令行参数解析(argparse模块)4.assert确保正确性5.main()脚本入口点6.辅助函数生成器函数`cycle(dl)`一、常用函数1.`.cuda()`/`.cpu()`和`torch.device`2.`torch.zeros`、`torch.randn`、`torch.arrange`、`torch.po
- 深度学习-常用环境配置
瑶山
AIlinux人工智能windowsCUDAPyTorch
目录Miniconda安装安装NVIDIA显卡驱动安装CUDA和cnDNNCUDAcuDNNPyTorch安装手动下载测试Miniconda安装最新版Miniconda搭建Python环境_miniconda创建python虚拟环境-CSDN博客安装NVIDIA显卡驱动直接进NVIDIA官网:NVIDIAGeForce驱动程序-N卡驱动|NVIDIA在这里有GeForce驱动程序,立即下载,这是下
- 数字图像处理与Python语言实现-Box模糊CUDA实现
视觉与物联智能
数字图像处理与Python实现python深度学习计算机视觉图像处理CUDA
Box模糊CUDA实现文章目录Box模糊CUDA实现1、Box模糊的基本原理2、算法优化:滑动窗口技术3、参数对模糊效果的影响4、Box模糊的优缺点5、与高斯模糊的对比6、实际应用场景7、算法实现7.1PyCUDA实现7.2CuPy实现7.3C++与CUDA实现8、总结在图像处理领域,**Box模糊(方框模糊或均值模糊)**是一种基础且高效的模糊算法,其核心思想是通过对像素邻域内的颜色值取平均值来
- 2018 MacBook Pro 安装cuda+cuDNN+pytorch
2018MacBookPro安装cuda+cuDNN+pytorch根据CSDN上的两篇文章和知乎上的一篇文章,前前后后折腾了好几天,在一个小姐姐的帮助下终于装上了。我的环境系统版本:macOS10.13.6(17G10021)GPUDriverVersion:387.10.10.10.40.133CUDADriverVersion:410.130CUDA:cuda_10.0.130cuDNN:c
- mac的m芯片上跑cuda程序
xinxuann
macos
config里parser.add_argument('--device',type=str,default='mps')main里device=torch.device(cfg['device'])train里x_batch=x_batch.astype('float32')y_batch=y_batch.astype('float32')aux_batch=aux_batch.astype('
- CUDA在不受支持的macOS系统上使用(BigSur)
ilovefifa2020
macosgithub经验分享大数据功能测试pythonc++
CUDA与WebDriver在macOS系统上不是同一个东西,CUDA是一个图形库,用于使用GPU在某些软件中进行计算或渲染,只安装CUDA不能使Maxwell和Pascal核心显卡工作,必须同时安装WebDriver,其他核心(如Fermi、kepler)等可以在不安装WebDriver的情况下让CUDA工作。果粉众所周知,CUDA与WebDriver只能在支持的macOS系统HighSierr
- 解读一个大学专业——信号与图像处理
专业定义与核心内容维度内容定义研究如何采集、处理、分析和理解一维信号(语音、雷达、脑电)和二维/三维图像(医学、遥感、工业视觉)。关键词数字信号处理(DSP)、图像处理、计算机视觉、模式识别、压缩感知、深度学习、GPU加速、嵌入式系统。技术栈MATLAB/Python+OpenCV/PyTorch+DSP/FPGA+GPU(CUDA)第五届先进算法与信号、图像处理国际学术会议(AASIP2025)
- autodl云计算平台 使用ollama 部署lightrag 加入streamlit界面
42fourtytoo
云计算深度学习pytorch学习
1到autodl的算力市场里开一台机器镜像选择:PyTorch2.3.0、Python3.12(ubuntu22.04)、Cuda12.1我本来选择的Cuda12.4,但版本过高疑似会使ollama不使用GPU而只用CPU,后来换个镜像就好了2下载lightrag从lightrag的GitHub界面下载zip开机,上传zip,解压到autodl-tmp/lightrag下安装依赖,在文件夹下:pi
- 英伟达:要取代我?其实CUDA也支持RISC-V
EEPW电子产品世界
risc-v
第五届RISC-V中国峰会于2025年7月16至19日在上海张江科学会堂隆重举办,在峰会的圆桌讨论中,主持人曾经提出这样一个问题:你认为RISC-V未来会取代GPU吗?在现场观众投票中,支持会取代的现场观众占据将近半数。不过在随后的主题演讲中,英伟达副总裁FransSijstermanns特别提到了英伟达在自家的计算平台实现了RISC-V应用处理器部署。在做这次演讲准备的时候,FransSijst
- python3.9安装tensorflow-gpu 2.6.0和torch-gpu版本各依赖包的版本对应关系
首先使用的cuDNN(8.1)、CUDA(11.2)、tensorflow-gpu(2.6.0)、python(3.9)之间对应版本Window环境下安装pytorch下载地址tensorflow官网CUDA下载官网cuDNN下载官网注意:cuDNN需要注册absl-py0.15.0astunparse1.6.3cachetools5.3.2certifi2023.7.22charset-norm
- 深度学习方法生成抓取位姿与6D姿态估计的完整实现
ZPC8210
ROS深度学习人工智能
如何将GraspNet等深度学习模型与6D姿态估计集成到ROS2和MoveIt中,实现高精度的机器人抓取系统。1.系统架构text[RGB-D传感器]→[物体检测与6D姿态估计]→[GraspNet抓取位姿生成]→[MoveIt运动规划]→[执行抓取]2.环境配置2.1安装依赖bash#安装PyTorch(根据CUDA版本选择)pip3installtorchtorchvisiontorchaud
- pytorch的学习笔记
wyn20001128
算法
一cuda 2006年,NVIDIA公司发布了CUDA(ComputeUnifiedDeviceArchitecture),是一种新的操作GPU计算的硬件和软件架构,是建立在NVIDIA的GPUs上的一个通用并行计算平台和编程模型,它提供了GPU编程的简易接口,基于CUDA编程可以构建基于GPU计算的应用程序。 CPU是用于负责逻辑性比较强的计算,GPU专注于执行高度线程化的并行处理任务。所以
- bash方式启动模型训练
BILLY BILLY
深度学习基础开发必备工具自动驾驶
export\PATHPYTHONPATH=/workspace/mmlab/mmdetection/:/workspace/mmlab/mmsegmentation/:/workspace/mmlab/mmdeploy/:${env:PYTHONPATH}\CUDA_VISIBLE_DEVICES=0\DATA_ROOT_1=/mnt/data/…/\DATA_ROOT_2=/mnt/data/
- QuACK:用纯 Python 把 H100 推到“光速”
吴脑的键客
人工智能python开发语言gpu算力
FlashAttention的共同作者TriDao与普林斯顿大学的两位博士生最近联合推出了一个名为QuACK的新内核库。这一创新的内核库引起了广泛关注,尤其是在高性能计算领域。QuACK的开发背景QuACK的开发完全基于Python和CuTe-DSL,令人瞩目的是,它不涉及任何CUDAC++代码。这一设计理念打破了传统的编程框架,使得开发者能够在更友好的环境中进行高效的GPU编程。性能优势在强大的
- COLMAP 编译全流程问题与解决方案汇总【含Ceres/absl/CUDA/GCC/CMake 报错详解】
逐云者123
三维重建算法工程与架构colmap三维重建编译
CeresSolver&COLMAP编译全流程问题与解决方案汇总【含absl/CUDA/GCC/CMake报错详解】适配环境:Ubuntu24.04+GCC12/13+CUDA12.6+Conda+RTX4090本文总结了从源码编译CeresSolver+COLMAP(无GUI)全流程中遇到的所有实际问题、报错信息、成因分析与解决办法,适用于从事3DGS/SfM/三维视觉方向的开发者。包含对abs
- Android 异构计算与 OpenCL/CUDA/OpenVX 的协同方式实战解析
观熵
国产NPU×Android推理优化android人工智能
Android异构计算与OpenCL/CUDA/OpenVX的协同方式实战解析关键词Android异构计算、OpenCL、CUDA、OpenVX、GPU加速、NPU调度、HSA架构、神经网络推理、计算图编排、SoC协同处理、AI芯片编程摘要随着国产SoC平台持续迭代,Android系统中异构计算模式已从传统CPU+GPU并行计算,扩展到集成NPU、DSP、ISP等多核单元的复杂协同体系。在AI推理
- vllm本地部署bge-reranker-v2-m3模型API服务实战教程
雷 电法王
大模型部署linuxpythonvscodelanguagemodel
文章目录一、说明二、配置环境2.1安装虚拟环境2.2安装vllm2.3对应版本的pytorch安装2.4安装flash_attn2.5下载模型三、运行代码3.1启动服务3.2调用代码验证一、说明本文主要介绍vllm本地部署BAAI/bge-reranker-v2-m3模型API服务实战教程本文是在Ubuntu24.04+CUDA12.8+Python3.12环境下复现成功的二、配置环境2.1安装虚
- 【医学影像】无痛安装mamba
周树皮
医学影像python
去年编辑的一个帖子。摆了一段时间后重新回归,发送一下作为状态分界线。很癫狂的体验,man,whatcanisay!issue查看我的狗急跳墙状态1.确定版本cudanvcc-Vpythonpython--versiontorchpipshowtorch2.下载对应版本wheelcausal-conv1d:https://github.com/Dao-AILab/causal-conv1d/rele
- jetson agx orin 刷机、cuda、pytorch配置指南【亲测有效】
jetsonagxorin刷机指南注意事项刷机具体指南cuda环境配置指南Anconda、Pytorch配置注意事项1.使用设备自带usbtoc的传输线时,注意c口插到orin左侧的口,右侧的口不支持数据传输;2.刷机时需准备ubuntu系统,可以是虚拟机,注意安装SDKManager刷机时,JetPack版本要选对,JetPack6.0的对应ubuntu22,cuda12版本,对应pytorch
- Yolov5-obb(旋转目标poly_nms_cuda.cu编译bug记录及解决方案)
关于在执行pythonsetup.pydevelop#or"pipinstall-v-e."时poly_nms_cuda.cu报错问题。前面步骤严格按照install.md环境1.pytorch版本较低时(我的是1.10):poly_nms_cuda.cu文件添加”#defineeps1e-8“,删除“constdoubleeps=1E-8;”这句2.pytorch版本较高时(我用的是1.27)h
- 使用 Docker 搭建 Python(Flask/CUDA AI)开发环境——AI教你学Docker
使用Docker搭建Python(Flask/CUDAAI)开发环境及常用中间件配置详解本指南适用于用Docker快速搭建Python(FlaskWeb应用或包含CUDA的AI开发环境)开发环境,并集成常用中间件服务如MySQL、Redis、Kafka。适合个人开发、本地测试和小团队协作。一、项目目录结构建议project-root/├──app/#Python应用源码目录│├──Dockerfi
- jetson orin nano安装GPU版本的pytorch过程
小鲈鱼-
pytorch人工智能python
一、安装jetpack组件和安装CUDA/cuDNN可以参考下面这个博客「解析」JetsonOrinNX安装CUDA/cuDNN_jetsoncuda-CSDN博客二、安装Pytorch和torchaudio可以直接看官方给的步骤https://pytorch.org/audio/main/build.jetson.html
- NVIDIA GeForce RTX 3090显卡详细介绍
山顶望月川
人工智能
一、详细参数(一)核心参数芯片厂商:NVIDIA显卡芯片:GeForceRTX3090显示芯片系列:NVIDIARTX30系列制作工艺:8纳米核心代号:GA102-300核心频率:基础频率1400MHz,加速频率1700MHzCUDA核心:10496个(二)显存规格显存频率:19500MHz显存类型:GDDR6X显存容量:24GB显存位宽:384bit最大分辨率:7680×4320(三)显卡接口接
- 【华为昇腾|CUDA】服务器A6000显卡部署LLM实战记录
刘阿宾
技能备忘服务器语言模型华为gpu算力kylin
安装驱动https://www.nvidia.cn/drivers/lookup/搜索对应gpu的kylin版本即可先使用wget下载rpm包rpm-i安装最后使用dnfinstallnvidia-driver即可上面安装的是驱动仓库安装CUDAkylin服务器参考配置同上,先wget,后rpm-i,最后dnfinstallcuda即可安装Ollamaollama官方提供aarch64docker
- 英伟达终为 CUDA 添加原生 Python 支持,他有什么目的?
朱卫军 AI
python开发语言
CUDA原来只支持C/C++/Fortran,在2025的CES上宣布支持原生Python其实是不得已而为之,一方面现在Python的AI开发者数量过于庞大,达到数千万级别,而CUDA仅几百万,CUDA想扩大自己的用户圈子,只能拉Python入伙。另一方面,Python生态的计算库实在太强大,比如numpy,几乎垄断了数组计算,还有像scipy、keras等,已经成为机器学习的主流工具,CUDA必
- Jetson Orin NX Super安装TensorRT-LLM
u013250861
#LLM/部署&推理elasticsearch大数据搜索引擎
根据图片中显示的JetsonOrinNXSuper系统环境(JetPack6.2+CUDA12.6+TensorRT10.7),以下是针对该平台的TensorRT-LLM安装优化方案:一、环境适配调整基于你的实际配置:JetPack6.2(含CUDA12.6,TensorRT10.7)Python3.10.12aarch64架构需选择适配的TensorRT-LLM版本。由于官方预编译包可能未覆盖此
- 在 WSL2 中配置 CUDA 环境变量的两种方法(含多版本支持)
新子y
python人工智能linux
通过编辑~/.bashrc文件添加export语句来配置CUDA环境变量,然后用source~/.bashrc刷新环境。✅一:更完整的环境变量设置exportPATH=/home/yyf/.local/bin:$PATHexportCUDA_HOME=/usr/local/cuda-12.6exportPATH=$CUDA_HOME/bin:$PATHexportLD_LIBRARY_PATH=$
- 对股票分析时要注意哪些主要因素?
会飞的奇葩猪
股票 分析 云掌股吧
众所周知,对散户投资者来说,股票技术分析是应战股市的核心武器,想学好股票的技术分析一定要知道哪些是重点学习的,其实非常简单,我们只要记住三个要素:成交量、价格趋势、振荡指标。
一、成交量
大盘的成交量状态。成交量大说明市场的获利机会较多,成交量小说明市场的获利机会较少。当沪市的成交量超过150亿时是强市市场状态,运用技术找综合买点较准;
- 【Scala十八】视图界定与上下文界定
bit1129
scala
Context Bound,上下文界定,是Scala为隐式参数引入的一种语法糖,使得隐式转换的编码更加简洁。
隐式参数
首先引入一个泛型函数max,用于取a和b的最大值
def max[T](a: T, b: T) = {
if (a > b) a else b
}
因为T是未知类型,只有运行时才会代入真正的类型,因此调用a >
- C语言的分支——Object-C程序设计阅读有感
darkblue086
applec框架cocoa
自从1972年贝尔实验室Dennis Ritchie开发了C语言,C语言已经有了很多版本和实现,从Borland到microsoft还是GNU、Apple都提供了不同时代的多种选择,我们知道C语言是基于Thompson开发的B语言的,Object-C是以SmallTalk-80为基础的。和C++不同的是,Object C并不是C的超集,因为有很多特性与C是不同的。
Object-C程序设计这本书
- 去除浏览器对表单值的记忆
周凡杨
html记忆autocompleteform浏览
&n
- java的树形通讯录
g21121
java
最近用到企业通讯录,虽然以前也开发过,但是用的是jsf,拼成的树形,及其笨重和难维护。后来就想到直接生成json格式字符串,页面上也好展现。
// 首先取出每个部门的联系人
for (int i = 0; i < depList.size(); i++) {
List<Contacts> list = getContactList(depList.get(i
- Nginx安装部署
510888780
nginxlinux
Nginx ("engine x") 是一个高性能的 HTTP 和 反向代理 服务器,也是一个 IMAP/POP3/SMTP 代理服务器。 Nginx 是由 Igor Sysoev 为俄罗斯访问量第二的 Rambler.ru 站点开发的,第一个公开版本0.1.0发布于2004年10月4日。其将源代码以类BSD许可证的形式发布,因它的稳定性、丰富的功能集、示例配置文件和低系统资源
- java servelet异步处理请求
墙头上一根草
java异步返回servlet
servlet3.0以后支持异步处理请求,具体是使用AsyncContext ,包装httpservletRequest以及httpservletResponse具有异步的功能,
final AsyncContext ac = request.startAsync(request, response);
ac.s
- 我的spring学习笔记8-Spring中Bean的实例化
aijuans
Spring 3
在Spring中要实例化一个Bean有几种方法:
1、最常用的(普通方法)
<bean id="myBean" class="www.6e6.org.MyBean" />
使用这样方法,按Spring就会使用Bean的默认构造方法,也就是把没有参数的构造方法来建立Bean实例。
(有构造方法的下个文细说)
2、还
- 为Mysql创建最优的索引
annan211
mysql索引
索引对于良好的性能非常关键,尤其是当数据规模越来越大的时候,索引的对性能的影响越发重要。
索引经常会被误解甚至忽略,而且经常被糟糕的设计。
索引优化应该是对查询性能优化最有效的手段了,索引能够轻易将查询性能提高几个数量级,最优的索引会比
较好的索引性能要好2个数量级。
1 索引的类型
(1) B-Tree
不出意外,这里提到的索引都是指 B-
- 日期函数
百合不是茶
oraclesql日期函数查询
ORACLE日期时间函数大全
TO_DATE格式(以时间:2007-11-02 13:45:25为例)
Year:
yy two digits 两位年 显示值:07
yyy three digits 三位年 显示值:007
- 线程优先级
bijian1013
javathread多线程java多线程
多线程运行时需要定义线程运行的先后顺序。
线程优先级是用数字表示,数字越大线程优先级越高,取值在1到10,默认优先级为5。
实例:
package com.bijian.study;
/**
* 因为在代码段当中把线程B的优先级设置高于线程A,所以运行结果先执行线程B的run()方法后再执行线程A的run()方法
* 但在实际中,JAVA的优先级不准,强烈不建议用此方法来控制执
- 适配器模式和代理模式的区别
bijian1013
java设计模式
一.简介 适配器模式:适配器模式(英语:adapter pattern)有时候也称包装样式或者包装。将一个类的接口转接成用户所期待的。一个适配使得因接口不兼容而不能在一起工作的类工作在一起,做法是将类别自己的接口包裹在一个已存在的类中。 &nbs
- 【持久化框架MyBatis3三】MyBatis3 SQL映射配置文件
bit1129
Mybatis3
SQL映射配置文件一方面类似于Hibernate的映射配置文件,通过定义实体与关系表的列之间的对应关系。另一方面使用<select>,<insert>,<delete>,<update>元素定义增删改查的SQL语句,
这些元素包含三方面内容
1. 要执行的SQL语句
2. SQL语句的入参,比如查询条件
3. SQL语句的返回结果
- oracle大数据表复制备份个人经验
bitcarter
oracle大表备份大表数据复制
前提:
数据库仓库A(就拿oracle11g为例)中有两个用户user1和user2,现在有user1中有表ldm_table1,且表ldm_table1有数据5千万以上,ldm_table1中的数据是从其他库B(数据源)中抽取过来的,前期业务理解不够或者需求有变,数据有变动需要重新从B中抽取数据到A库表ldm_table1中。
- HTTP加速器varnish安装小记
ronin47
http varnish 加速
上午共享的那个varnish安装手册,个人看了下,有点不知所云,好吧~看来还是先安装玩玩!
苦逼公司服务器没法连外网,不能用什么wget或yum命令直接下载安装,每每看到别人博客贴出的在线安装代码时,总有一股羡慕嫉妒“恨”冒了出来。。。好吧,既然没法上外网,那只能麻烦点通过下载源码来编译安装了!
Varnish 3.0.4下载地址: http://repo.varnish-cache.org/
- java-73-输入一个字符串,输出该字符串中对称的子字符串的最大长度
bylijinnan
java
public class LongestSymmtricalLength {
/*
* Q75题目:输入一个字符串,输出该字符串中对称的子字符串的最大长度。
* 比如输入字符串“google”,由于该字符串里最长的对称子字符串是“goog”,因此输出4。
*/
public static void main(String[] args) {
Str
- 学习编程的一点感想
Cb123456
编程感想Gis
写点感想,总结一些,也顺便激励一些自己.现在就是复习阶段,也做做项目.
本专业是GIS专业,当初觉得本专业太水,靠这个会活不下去的,所以就报了培训班。学习的时候,进入状态很慢,而且当初进去的时候,已经上到Java高级阶段了,所以.....,呵呵,之后有点感觉了,不过,还是不好好写代码,还眼高手低的,有
- [能源与安全]美国与中国
comsci
能源
现在有一个局面:地球上的石油只剩下N桶,这些油只够让中国和美国这两个国家中的一个顺利过渡到宇宙时代,但是如果这两个国家为争夺这些石油而发生战争,其结果是两个国家都无法平稳过渡到宇宙时代。。。。而且在战争中,剩下的石油也会被快速消耗在战争中,结果是两败俱伤。。。
在这个大
- SEMI-JOIN执行计划突然变成HASH JOIN了 的原因分析
cwqcwqmax9
oracle
甲说:
A B两个表总数据量都很大,在百万以上。
idx1 idx2字段表示是索引字段
A B 两表上都有
col1字段表示普通字段
select xxx from A
where A.idx1 between mmm and nnn
and exists (select 1 from B where B.idx2 =
- SpringMVC-ajax返回值乱码解决方案
dashuaifu
AjaxspringMVCresponse中文乱码
SpringMVC-ajax返回值乱码解决方案
一:(自己总结,测试过可行)
ajax返回如果含有中文汉字,则使用:(如下例:)
@RequestMapping(value="/xxx.do") public @ResponseBody void getPunishReasonB
- Linux系统中查看日志的常用命令
dcj3sjt126com
OS
因为在日常的工作中,出问题的时候查看日志是每个管理员的习惯,作为初学者,为了以后的需要,我今天将下面这些查看命令共享给各位
cat
tail -f
日 志 文 件 说 明
/var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一
/var/log/secure 与安全相关的日志信息
/var/log/maillog 与邮件相关的日志信
- [应用结构]应用
dcj3sjt126com
PHPyii2
应用主体
应用主体是管理 Yii 应用系统整体结构和生命周期的对象。 每个Yii应用系统只能包含一个应用主体,应用主体在 入口脚本中创建并能通过表达式 \Yii::$app 全局范围内访问。
补充: 当我们说"一个应用",它可能是一个应用主体对象,也可能是一个应用系统,是根据上下文来决定[译:中文为避免歧义,Application翻译为应
- assertThat用法
eksliang
JUnitassertThat
junit4.0 assertThat用法
一般匹配符1、assertThat( testedNumber, allOf( greaterThan(8), lessThan(16) ) );
注释: allOf匹配符表明如果接下来的所有条件必须都成立测试才通过,相当于“与”(&&)
2、assertThat( testedNumber, anyOf( g
- android点滴2
gundumw100
应用服务器android网络应用OSHTC
如何让Drawable绕着中心旋转?
Animation a = new RotateAnimation(0.0f, 360.0f,
Animation.RELATIVE_TO_SELF, 0.5f, Animation.RELATIVE_TO_SELF,0.5f);
a.setRepeatCount(-1);
a.setDuration(1000);
如何控制Andro
- 超简洁的CSS下拉菜单
ini
htmlWeb工作html5css
效果体验:http://hovertree.com/texiao/css/3.htmHTML文件:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>简洁的HTML+CSS下拉菜单-HoverTree</title>
- kafka consumer防止数据丢失
kane_xie
kafkaoffset commit
kafka最初是被LinkedIn设计用来处理log的分布式消息系统,因此它的着眼点不在数据的安全性(log偶尔丢几条无所谓),换句话说kafka并不能完全保证数据不丢失。
尽管kafka官网声称能够保证at-least-once,但如果consumer进程数小于partition_num,这个结论不一定成立。
考虑这样一个case,partiton_num=2
- @Repository、@Service、@Controller 和 @Component
mhtbbx
DAOspringbeanprototype
@Repository、@Service、@Controller 和 @Component 将类标识为Bean
Spring 自 2.0 版本开始,陆续引入了一些注解用于简化 Spring 的开发。@Repository注解便属于最先引入的一批,它用于将数据访问层 (DAO 层 ) 的类标识为 Spring Bean。具体只需将该注解标注在 DAO类上即可。同时,为了让 Spring 能够扫描类
- java 多线程高并发读写控制 误区
qifeifei
java thread
先看一下下面的错误代码,对写加了synchronized控制,保证了写的安全,但是问题在哪里呢?
public class testTh7 {
private String data;
public String read(){
System.out.println(Thread.currentThread().getName() + "read data "
- mongodb replica set(副本集)设置步骤
tcrct
javamongodb
网上已经有一大堆的设置步骤的了,根据我遇到的问题,整理一下,如下:
首先先去下载一个mongodb最新版,目前最新版应该是2.6
cd /usr/local/bin
wget http://fastdl.mongodb.org/linux/mongodb-linux-x86_64-2.6.0.tgz
tar -zxvf mongodb-linux-x86_64-2.6.0.t
- rust学习笔记
wudixiaotie
学习笔记
1.rust里绑定变量是let,默认绑定了的变量是不可更改的,所以如果想让变量可变就要加上mut。
let x = 1; let mut y = 2;
2.match 相当于erlang中的case,但是case的每一项后都是分号,但是rust的match却是逗号。
3.match 的每一项最后都要加逗号,但是最后一项不加也不会报错,所有结尾加逗号的用法都是类似。
4.每个语句结尾都要加分