Bert、GPT、ELmo对比解析及文本分类应用
BERT
BERT全称是Bidirectional Encoder Representations from Transformers,取了核心单词的首字母而得名,从名字我们能看出该模型两个核心特质:依赖于Transformer以及双向,下面来看论文中的一结构对比图:
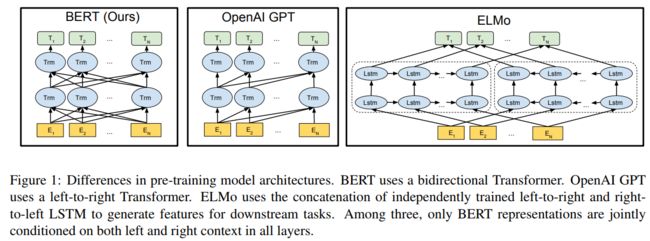
论文在最一开始就与另外两个pretrain模型:ELMo和OpenAI GPT做了对比,从结构上我们可以看出ELMo的基础是使用了LSTM,而OpenAI GPT和BERT使用了Transformer作为基本模型。注意BERT一些核心的创新点:
- 相较于OpenAI GPT模型而言,其为双向Transformer;
- 而同是双向,ELMo由于是基于LSTM,BERT基于Transformer,并且核心的是两者的目标函数是不一致的:
OpenAI GPT:P(wi|w1,...,wi−1)P(wi|w1,...,wi−1)
ELMo:P(wi|w1,...,wi−1)和P(wi|wi+1,...,wn)P(wi|w1,...,wi−1)和P(wi|wi+1,...,wn)
BERT:P(wi|w1,...,wi−1,wi+1,...,wn)P(wi|w1,...,wi−1,wi+1,...,wn)
即传统意义双向类似ELMo模型,根据上下文,每个词会得到left-to-right和right-to-left两种表示,我们可以将两者concat在一起作为该词的表示,再进行下游的任务操作。而直觉上,如果我们能有一个更加深入的双向模型,直接能够给出词的上下文表示。遗憾的是,不可能训练像普通LM一样的深度双向模型,因为这会产生一些循环,在这些循环中,单词可以间接地“看到自己”,并且预测变得微不足道(其实这点有待进一步商榷)。
所以BERT采用了一些非常简单的trick来实现,
利用自编码器,从输入中掩盖了一部分的单词并且必须从上下文重构这些单词。即所谓Masked LM,其实就是通常意义上的“完形填空”。
关于双向的设计思路,BERT作者在https://www.reddit.com/r/MachineLearning/comments/9nfqxz/r_bert_pretraining_of_deep_bidirectional/进行过详细论述,感兴趣读者可以移步看看。
Embedding
在前文Transformer我们已经详细阐述过了一句话进入模型的Embedding过程,BERT除了token embedding和position embedding,由于还需要以两个句子作为输入,还添加了segment embedding,如下图:

- Token Embeddings是词向量(中文进入就是字符向量),第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
预训练
BERT为了能够在大规模语料上进行无监督学习,非常巧妙的设计了两个预训练任务:一个是随机遮蔽(mask)掉一个句子中的词,利用上下文进行预测;另一个是预测下一个句子(类似QA场景)。
(1) Task #1: Masked LM
Input:
the man [MASK1] to [MASK2] store
Label:
[MASK1] = went; [MASK2] = store
该任务就是BERT为了做到双向深度上下文表示设计的预训练trick任务,而在mask单词的时候,作者也采用了一些技巧,随机mask掉15%的token,最终的损失函数只计算mask掉的token。而对于被mask掉的词也并非简单粗暴的将全部替换成[MASK]标签完事,会遵循如下步骤:
- 80%即大部分情况下,被mask掉的词会被[MASK]标签代替;
- 10%的情况下,将该词用一个随机的词替换掉;
- 10%的情况下,保留该词在原位置。
这样做的目的是偏向代表实际观察到的词。另外模型在预训练时,Transformer编码器并不知道哪些词被mask掉了,所以模型对每个词都会关注。同时,因为随机替换仅发生在所有词的1.5%(即15%*10%),对模型的语言理解能力影响很小。
(2) Task #2: Next Sentence Prediction
Input:
the man went to the store [SEP] he bought a gallon of milk
Label:
IsNext
Input:
the man went to the store [SEP] penguins are flightless birds
Label:
NotNext
由于在LM的下游任务还会涉及到问答(Question Answering (QA) )和推理( Natural Language Inference (NLI))的任务,这需要LM有理解句子间关系的能力,所以作者新增了一个预训练任务,输入句子A和B,预测B是否为A的下一个句子,以50%的概率配对A和B,即50%B是真的,50%B是随机选取的一个句子。
所以作者提示在选取预训练语料时,要尽可能选取document-level的语料而非segment-level混合在一起的语料。
文本分类试验
利用BERT我在文本分类任务上进行了尝试,语料集是用户评论内容,目标是预测用户评论内容的情感极性,分为正中负三类。
BERT源码拉下来后需要进行一些简单调整,比如将TPUEstimator换成普通的estimator,改变一些模型指标计算方式等。
笔者首先利用1000W左右的评论语料对BERT的中文预训练模型进行了迁移学习,之后通过500W语料分别在text-cnn、lstm concat cnn以及lstm concat cnn with bert上进行了训练对比。(注:这里lstm concat cnn是笔者在该任务上试验后选取的效果较好的模型结构)
指标情况如下:
Text_cnn
Avg acc: 0.8802
sentence num:13530, tags all num:13530, neg num:5539, neu num:1398, pos num:6593
precision recall f1-score support
0 0.88 0.96 0.92 5539
1 0.54 0.22 0.31 1398
2 0.91 0.95 0.93 6593
avg / total 0.86 0.88 0.86 13530
LSTM concat CNN
precision recall f1-score support
0 0.92 0.96 0.94 5539
1 0.60 0.43 0.50 1398
2 0.93 0.95 0.94 6593
avg / total 0.89 0.90 0.89 13530
0.8997782705099778
3.9ms/条
LSTM concat CNN with BERT
precision recall f1-score support
0 0.92 0.96 0.94 5539
1 0.67 0.35 0.46 1398
2 0.90 0.97 0.94 6593
avg / total 0.89 0.90 0.89 13530
0.9000739098300073
29.365628ms/条
笔者在实验过程中发现的几点需要注意:
- 直接用BERT进行fine-tune的效果,在中文语料上效果一般,因为中文是以字作为embedding来考虑的,丢失了太多的词语信息;
- 将BERT作为辅助上下文,添加在别的模型中,效果会有所提升,但效果有限;
- 添加BERT后,CPU做inference速度较慢,需要考虑计算成本
鉴于第3点,笔者尝试了将BERT中的字向量完全抽出来,作为辅助输入到模型中,但是这种方式的效果不是很好,直觉上BERT需要依赖上下文来求得当前token的embedding,单独抽出来失去了其双向深度编码的优势。
后续笔者准备尝试下百度的https://github.com/PaddlePaddle/LARK/tree/develop/ERNIE,其考虑了中文的词语信息,更适合中文场景,BERT只能进行纯字的embedding在中文场景效果提升有限。
另外还有更好的想法欢迎大家留言一起讨论~
参考文献
- Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]//Advances in neural information processing systems. 2014: 3104-3112.
- Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
- Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017: 5998-6008.
- Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
- https://github.com/google-research/bert