王老师折磨n+1次
为时三天的数据处理,终于完结,还记得上一周被王老师一次又一次的折返,心态崩了呀,每次给老师发处理后的数据,都心跳加速,但每次的返工又在意料之中(自己实在是菜的一批),差点就退出了,也不知道是天注定,还是怎么,在上午问杨老师是否有时间时,老师刚好不在学校,退队的想法也就搁置了几个小时,正是这几个小时,我又看到了希望,也正是这几个小时,王老师下达的任务又来了,我没有机会提出退队,因此便有了接下来的三天(周三~周五/3.15~3.17)。【真的对不住杨老师了,两周没碰杨老师的项目了】

王老师令人窒息的文字和对话:









正是因为第二次处理数据,我学到了很多,我明白了封装成函数的重要性,明白了统一命名规则和逻辑清晰的重要性,明白了一步一检的重要性,记录一下这次的代码吧。
import pandas as pd
#---------------------------------->【0.1】输出运行结果到文件中==》防止电脑掉电
log_file_path=r"D:\大学\王老师实验室\03项目\code\runResultsLogging.txt"
def printToLogFile(file_path,content):
"""
输出运行结果到文件中==》防止电脑掉电
:param file_path: log文件路径
:param content: 内容
:return:
"""
content=str(content)
f=open(file_path,mode='a+')
f.write(content)
f.close()
#---------------------------------->【0.2】读文本文件
def readTxtFile(file_path):
"""
读文本文件内容
:param file_path: 文件路径
:return: 内容
"""
f=open(file_path,mode='r')
content=f.read()
f.close()
return content
#---------------------------------->【0.3】获取当前时间
def getCurTime():
import datetime
return datetime.datetime.now()
#---------------------------------->【0.4】获取指定目录下的所有文件==》为了批量操作
def getFilesName(file_dir):
"""
获取指定目录下的所有文件名称
:param fileDir:指定目录
:return:目录下的所有文件完整路径
"""
import os
for root,dirs,files in os.walk(file_dir):
return files
# print(getFilesName(r"D:\大学\王老师实验室\03项目\data\02\03_csvDataFile"))
#---------------------------------->【1.1】xlsx、tsv转为csv
import pandas as pd
import os
# 原始文件位置
source_path = r"D:\大学\王老师实验室\03项目\data\02\02_processed"
# 保存位置
save_path = r"D:\大学\王老师实验室\03项目\data\02\03_csvDataFile"
if not os.path.exists(save_path):
os.mkdir(save_path)
pathDir = os.listdir(source_path)
Name = []
End = []
# 获得文件的名称和后缀
def getName(workdir):
for filename in os.listdir(workdir):
split_file = os.path.splitext(filename)
# print(split_file[0])
Name.append(split_file[0])
End.append(split_file[1])
return Name, End
name, end = getName(source_path)
# print(name,end)
n=0
for i in range(len(name)):
oldPath=source_path+'\\'+name[i]+end[i]
newPath=save_path+'\\'+name[i]+'.csv'
n+=1
print(n)
if end[i]=='.tsv':
df = pd.read_csv(oldPath,sep='\t')
df.to_csv(newPath, index=False)
elif end[i]=='.xlsx':
df = pd.read_excel(oldPath)
df.to_csv(newPath, index=False)
#---------------------------------->【1.2】检验文件是否转换完全
import os
# 原始文件位置
source_path = r"D:\大学\王老师实验室\03项目\data\02\02_processed"
# 保存位置
save_path = r"D:\大学\王老师实验室\03项目\data\02\03_csvDataFile"
souce_pathDir = os.listdir(source_path)
save_pathDir=os.listdir(save_path)
print("源目录文件个数:",len(souce_pathDir))#23
print("转换后目录文件个数:",len(save_pathDir))#23
#---------------------------------->【2.1】修改Description值:提取GN后面的值(没有GN的空字符串代替)
old_dir=r"D:\大学\王老师实验室\03项目\data\02\03_csvDataFile"
new_dir=r"D:\大学\王老师实验室\03项目\data\02\04_handledDataFile"
def modifyColValue(file_path):
import pandas as pd
file_name=file_path.split('\\')[-1]#文件名
new_file_path=new_dir+"\\"+file_name#将要保存的文件路径
f_data=pd.read_csv(file_path)#所有数据
n=0
for i in range(len(f_data)):
n+=1
desp=f_data['Description'][i]
#正则表达式匹配GN=后面的字符
import re
pattern=r"GN=(\S+)\s"#\S:表示非空字符,\s:表示空字符,+:表示出现次数>=1
gn = re.findall(pattern, desp)#匹配到的基因名字
gn=gn[0] if gn else ''
# print(n,gn,sep=':')
#修改Description
f_data['Description'][i] = gn
print(n)
print(f_data.shape)
f_data.to_csv(new_file_path,index=False)
#修改Data1开头的文件
modifyColValue(old_dir+"\Data1_File1_DDA_noPTM_NB4_A0_9_Abundance.csv")
modifyColValue(old_dir+"\Data1_File2_DDA_PTM_NB4_A0_9_Abundance.csv")
#---------------------------------->【2.2】删除数据文件中的空行数据
def deleteBlankLines(file_path):
df=pd.read_csv(file_path)
print('删除空值:',file_path.split('\\')[-1])
print('删除前行数:',len(df))
#删除第一列为空值所在的行
df.dropna(subset=[df.columns[1]], inplace=True)#1:表示第1列
#保存修改后的csv文件
df.to_csv(file_path, index=False)
df = pd.read_csv(file_path)
print('删除后行数:', len(df))
#---------------------------------->【2.3】合并相同基因的行
def mergeSameRows(file_path):
import pandas as pd
df=pd.read_csv(file_path)
#填充空值为0
df.fillna(0,inplace=True)
#合并相同的行
df=df.groupby("Genes").sum()
new_name=file_path.split('.csv')[0]+"副本"+".csv"
df.to_csv(new_name, index=True)
file_dir=r"D:\大学\王老师实验室\03项目\data\02\04_handledDataFile"#处理完数据存储的目录路径
file_names=getFilesName(file_dir)
for file_name in file_names:
file_full_path=file_dir+"\\"+file_name
deleteBlankLines(file_full_path)
mergeSameRows(file_full_path)
#---------------------------------->【2.4】验证合并的正确性
file_dir=r"D:\大学\王老师实验室\03项目\data\02\04_handledDataFile"
def checkMerge(old_path,new_path):
"""
:param old_path: 老文件路径
:param new_path: 新文件路径
:return:
"""
import pandas as pd
# ①验证原来不同基因个数和后来不同基因个数是否相同
old_data=pd.read_csv(old_path)
new_data=pd.read_csv(new_path)
old_gene=old_data["Genes"]
new_gene=new_data["Genes"]
print('原数据的行和列:',old_data.shape,'; 处理后数据的行和列:',new_data.shape)
print('原来不同基因个数:',len(set(old_gene)))
print('处理后不同基因个数:', len(set(new_gene)))
#②通过验证每列和是否相同,从而验证其正确性
print("每列和是否相同:",all(abs(old_data.iloc[:,1:].sum()-new_data.iloc[:,1:].sum())<1e-4))
all_path=getFilesName(file_dir)
old_path=all_path[::2]
new_path=all_path[1::2]
for i,j in zip(old_path,new_path):
print("开始检查文件:",i)
checkMerge(file_dir+'\\'+i,file_dir+'\\'+j)
print('-'*50)
#---------------------------------->【3.1】观察列名相同部分和不同部分,从而加以区分
file_dir=r"D:\大学\王老师实验室\03项目\data\02\04_handledDataFile"
long_file_names=[
'Data2_File1_DIA_U937_RIGI_0_9.pg_matrix副本.csv',
'Data2_File2_DIA_U937_RIGI_0_9_missedcleavage.pg_matrix副本.csv',
'Data3_File2_Data2_DIA_50_NB4_50_U937_3_AML_celllines副本.csv',
'Data4_File6_DIA_NB4_ATRA_0_9_and_AML_cells_phoshpo副本.csv',
'Data4_File7_DIA_NB4_ATRA_0_9_and_AML_cells_KGG副本.csv',
'Data5_File1_NB4_TRIM25_ISG15_USP18_knockdown副本.csv',
'Data7_File1_siHATRIM27_overexpression_knockdown副本.csv',
'Data9_File1_HL60_ATRA_report.pg_matrix副本.csv'
]
def printColumnNames(file_path):
import pandas as pd
df=pd.read_csv(file_path)
print(file_path.split('\\')[-1],'列名如下:')
for i in list(df):
print(i)
print('-'*50)
for i in range(len(long_file_names)):
print('<---',i,'--->')
printColumnNames(file_dir + '\\' + long_file_names[i])
#---------------------------------->【3.2】处理列名较长的八个文件
new_file_dir=r"D:\大学\王老师实验室\03项目\data\02\05_handledDataFile2"
def shortenLongColumn(file_path):
"""
缩短列名,根据 反斜线后”.raw”前的字符串
:param file_path:文件完整路径
:return:
"""
import pandas as pd
df=pd.read_csv(file_path)
old_col_names=list(df)[1:]#因为第一列名是Genes,勿需处理
new_col_names=[i.split('\\')[-1].split('.raw')[0] for i in old_col_names]
df.columns = ["Genes"]+new_col_names
new_file_path=new_file_dir+'\\'+file_path.split('\\')[-1]
df.to_csv(new_file_path,index=False)
print(file_path.split('\\')[-1],'文件列名为:')
print(df.columns)
print('-'*50)
for i in long_file_names:
shortenLongColumn(file_dir+'\\'+i)
#---------------------------------->【3.3】检验列名是否修改正确
def checkColumnName(old_file_path,new_file_path):
import pandas as pd
old_df=pd.read_csv(old_file_path)
new_df=pd.read_csv(new_file_path)
print('开始检查文件:',old_file_path.split('\\')[-1])
print('老文件列:',len(list(old_df)),'; 新文件列:',len(list(new_df)))
print('-'*50)
for i in long_file_names:
checkColumnName(file_dir+'\\'+i,new_file_dir+'\\'+i)
#---------------------------------->【3.4】将未处理的文件移动到新的目录下(此处已完全预处理结束)
files=getFilesName(file_dir)
need_move_files=[f for f in files if "副本" in f and f not in long_file_names]#需要移动的文件
print("需要移动的文件个数:",len(need_move_files))#23-8=15
print("需要移动的文件为:")
print(need_move_files)
def moveFile(old_file_path,new_file_path):
import pandas as pd
old_df=pd.read_csv(old_file_path)
old_df.to_csv(new_file_path,index=False)
for i in need_move_files:
moveFile(file_dir+'\\'+i,new_file_dir+'\\'+i)
#新目录下的文件个数
print('【检查移动是否成功】新目录下的文件个数:',len(getFilesName(new_file_dir)))
#---------------------------------->【4.1】删除Datax_Filey文件的一行均为0的行
file_dir=r"D:\大学\王老师实验室\03项目\data\02\06_handledDataFile3"
files=getFilesName(file_dir)
def deleteAllZeroRow(file_path):
import pandas as pd
df=pd.read_csv(file_path)
print("删除文件中的值全为0的行:",file_path.split('\\')[-1])
print("原行数:",df.shape[0])
df=df.loc[(df.iloc[:,1:] != 0).any(axis=1)]#留下非0行
# df = df.drop(df[df.sum(axis=1)!=0].index)#留下全0行 ==》用于验证
df.to_csv(file_path,index=False)
df=pd.read_csv(file_path)
print("处理后行数:",df.shape[0])
print('-'*50)
for i in range(len(files)):
print(i)
deleteAllZeroRow(file_dir+'\\'+files[i])
deleteAllZeroRow(r"D:\大学\王老师实验室\03项目\data\02\Data1_File1_DDA_noPTM_NB4_A0_9_Abundance副本.csv")
deleteAllZeroRow(r"D:\大学\王老师实验室\03项目\data\02\Data1_File2_DDA_PTM_NB4_A0_9_Abundance副本.csv")
'''
Data1_File1:5353 4847
Data9:7556 7556
Data10: 7333 7333
'''
printToLogFile(log_file_path,getCurTime())
printToLogFile(log_file_path,'\r\n')
#---------------------------------->【4.2】更新Human_protein_ID.csv
def search_for_gene_size(gene):
import requests
from lxml import etree
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
url = "https://www.genecards.org/cgi-bin/carddisp.pl?gene="
url += gene
res = requests.get(url, headers=header)
tree = etree.HTML(res.text)
i=0
while(1):
try:
protein_size = tree.xpath('//*[@id="proteins-attributes"]/div/dl[1]/dd[1]/text()')[0]
except IndexError as e:
# print('*')
protein_size = tree.xpath('//*[@id="proteins-attributes"]/div/dl[1]/dd[1]/text()')
i+=1
if len(protein_size)!=0 or i>=10:
break
protein_size = ''.join([x for x in protein_size if x.isdigit()])
print(gene,protein_size,sep=' : ')
print('-'*10)
return protein_size
# search_for_gene_size("hCG_2002731")
source_dir = r"D:\大学\王老师实验室\03项目\data\02\06_handledDataFile3"
target_path =r"D:\大学\王老师实验室\03项目\data\02\Human_protein_ID - 副本.csv"
def updateHumanProteinFile(source_path,target_path):
import pandas as pd
# Read csv file
source_pd = pd.read_csv(source_path)
print("源文件行数:",len(source_pd))
printToLogFile(log_file_path, "源文件行数:"+str(len(source_pd)))
target_pd = pd.read_csv(target_path)
print("目标文件行数:", len(target_pd))
printToLogFile(log_file_path, "目标文件行数:" + str(len(target_pd)))
for i in range(len(source_pd)):
flag = 1
# Split according to gene
temp = source_pd['Genes'][i].split(';')
for j in range(len(temp)):
for k in range(len(target_pd['gene'])):
if temp[j] == target_pd['gene'][k]:
flag = 0
break
if flag == 1:#没在目标文件,加入
print(temp[0],sep='\t')
printToLogFile(log_file_path, temp[0]+'\t')
# 加在最后
protein_size=search_for_gene_size(temp[0])
if protein_size:#没找到size的不加入
a = {'ID':' ','gene': [temp[0]],'protein_size':protein_size,'annotation':temp[0]}
df = pd.DataFrame(a)
# mode = 'a'为追加数据,index为每行的索引序号,header为标题
df.to_csv(target_path, mode='a', index=False, header=False)
target_pd = pd.read_csv(target_path)
print("修改后目标文件行数:", len(target_pd))
printToLogFile(log_file_path, "修改后目标文件行数:"+str(len(target_pd)))
files_name=getFilesName(source_dir)
for i in files_name:
print('查找文件:',i)
printToLogFile(log_file_path, '查找文件:'+i)
updateHumanProteinFile(source_dir+'\\'+i,target_path)
deleteBlankLines(target_path)#全部添加完后删除size为空的行
#---------------------------------->【5.1】产生_size_ppm.csv文件
source_dir = r"D:\大学\王老师实验室\03项目\data\02\06_handledDataFile4"
target_dir = r"D:\大学\王老师实验室\03项目\data\02\07_ppmDataFile"
refer_file_path = r'D:\大学\王老师实验室\03项目\data\02\Human_protein_ID - 副本.csv' # Human_protein文件
def outputPpmFiles(source_path):
"""
这是一个最终产生—_size_ppm.csv的文件。
:param source_path: 源文件路径
:return:
"""
import pandas as pd
souce_df = pd.read_csv(source_path)
refer_df = pd.read_csv(refer_file_path)
merge_df = pd.merge(refer_df, souce_df, how='inner', left_on='gene', right_on='gene')
print('列数:',len(merge_df.columns))
printToLogFile(log_file_path, '列数:'+str(len(merge_df.columns)))
print('行数:',len(merge_df.index))
printToLogFile(log_file_path, '行数:' + str(len(merge_df.index)))
print(merge_df.columns)
printToLogFile(log_file_path, merge_df.columns)
#删除特定列 ID、gene、annotation
merge_df=merge_df.drop(columns=['ID','gene','annotation'])
print('列数:', len(merge_df.columns))
printToLogFile(log_file_path, '列数:' + str(len(merge_df.columns)))
print('行数:', len(merge_df.index))
printToLogFile(log_file_path, '行数:' + str(len(merge_df.index)))
print(merge_df.columns)
printToLogFile(log_file_path, merge_df.columns)
#两列相乘
for i in range(2,len(merge_df.columns)):
merge_df.iloc[:,i]=0.01*(merge_df.iloc[:,i]*merge_df['protein_size'])
merge_df.iloc[:, i]=(merge_df.iloc[:,i]/sum(merge_df.iloc[:,i]))*1e6
merge_df = merge_df.drop(columns=['protein_size'])
ppm_name=source_path.split('\\')[-1].split('.csv')[0]+"_size_ppm.csv"
merge_df.to_csv(target_dir+'\\'+ppm_name,index=False)
source_file_name=getFilesName(source_dir)
for f in source_file_name:
outputPpmFiles(source_dir+'\\'+f)
# #---------------------------------->【5.2】检查_size_ppm文件行数少的原因
#可能原因:①源文件没有GN=的(空值);②有重复的GN;③有GN,但是一行全为0的;④Genes爬虫爬不到的;
source_dir=r"D:\大学\王老师实验室\03项目\data\02\03_csvDataFile"
target_dir=r"D:\大学\王老师实验室\03项目\data\02\07_ppmDataFile"
#测试文件
test_source_path=source_dir+'\\'+'Data2_File1_DIA_U937_RIGI_0_9.pg_matrix.csv'
test_target_path=target_dir+'\\'+'Data2_File1_DIA_U937_RIGI_0_9.pg_matrix副本_size_ppm.csv'
#【5.2.1】源文件和目标文件行数差异
def get_DiffRowSourceTarget(source_path,target_path):
"""
获得原文件和目标文件的行数差异
:param source_path: str 原文件地址
:param target_path: str 目标文件地址
:return: int
"""
source_df=pd.read_csv(source_path)
target_df = pd.read_csv(target_path)
source_row=len(source_df)
target_row=len(target_df)
diff_row=source_row-target_row
print('原文件:',source_path.split('\\')[-1],', 行数:',source_row)
print('目标文件:', target_path.split('\\')[-1], ', 行数:', target_row)
print('目标文件比原文件少的行数:',diff_row)
print('-'*50)
return diff_row
# get_DiffRowSourceTarget(test_source_path,test_target_path)
#【5.2.2】源文件没有GN=的行数 ==>只有Data1_File1和Data1_File2检查
def getNoGNRow(file_path):
"""
获得源文件没有基因的行数。
:param file_path: str 文件地址
:return: int
"""
df=pd.read_csv(file_path)
df_description=df['Description']
print('文件:',file_path.split('\\')[-1])
no_gn_col=len([1 for i in df_description if 'GN=' not in i])
print('没有基因的行数:',no_gn_col)
print('-'*50)
return no_gn_col
# getNoGNRow(test_source_path)
def getBlankGene(file_path):
"""用于求除了Data1文件的的空行"""
df=pd.read_csv(file_path)
ge=df['Genes']
print('文件:', file_path.split('\\')[-1])
no_gn_col=ge.isnull().sum()
print('没有基因的行数:',no_gn_col)
print('-'*50)
return no_gn_col
# 测试getBlankGene()函数
f_03_dir=r"D:\大学\王老师实验室\03项目\data\02\03_csvDataFile"
f_03_files_name=getFilesName(f_03_dir)
for i in f_03_files_name:
if 'Data1' not in i:
getBlankGene(f_03_dir+'\\'+i)
#【5.2.3】获取具有重复基因的行数
def getRepetitionGNRow(file_path):
"""
获取具有重复基因的行数
:param file_path: str 文件路径
:return: int
"""
df=pd.read_csv(file_path)
all_genes=df['gene']
no_repe_genes=set(all_genes)
diff_col=len(all_genes)-len(no_repe_genes)
print('文件:',file_path.split('\\')[-1])
print('具有重复基因的行数:',diff_col)
print('-' * 50)
return diff_col
# getRepetitionGNRow(r"D:\大学\王老师实验室\03项目\data\02\04_handledDataFile\Data2_File1_DIA_U937_RIGI_0_9.pg_matrix.csv")
#【5.2.4】获取值全为0的行数
def getValueZeroRow(file_path):
"""
获取值全为0的行数
:param file_path: str 文件路径
:return: int
"""
df=pd.read_csv(file_path)
zero_df = df.loc[(df.iloc[:, 1:] == 0).all(axis=1)]#获取全0行
zero_row=len(zero_df)#行数
print('文件:',file_path.split('\\')[-1])
print('全0行有:',zero_row)
print('-'*50)
return zero_row
# getValueZeroRow(r'D:\大学\王老师实验室\03项目\data\02\04_handledDataFile\Data2_File1_DIA_U937_RIGI_0_9.pg_matrix副本.csv')
#【5.2.5】基因在爬虫中找不到的行数
def getHumanGenes(file_path):
"""
获取Human_protein_ID文件中的基因列表。
:param file_path:
:return:list
"""
df=pd.read_csv(file_path)
all_gene=df['gene']
return all_gene
human_gene=set(getHumanGenes(r'D:\大学\王老师实验室\03项目\data\02\Human_protein_ID - 副本.csv'))
def getNoFoundGNSize(file_path):
"""
获得在网站中搜索不到的基因或没有size值的
:param file_path:str 文件路径
:return:int
"""
df=pd.read_csv(file_path)
df_genes=df["gene"]
unfound_count=0#未发现的基因个数
print('文件:',file_path.split('\\')[-1])
print('未发现的基因有:')
for g in df_genes:
if g not in human_gene:#不在里面再搜索
s=search_for_gene_size(g)
if not s:
# print(g,end='\t')
unfound_count+=1
print('总个数为:',unfound_count)
print('-'*50)
return unfound_count
# getNoFoundGNSize(r'D:\大学\王老师实验室\03项目\data\02\06_handledDataFile4\Data2_File1_DIA_U937_RIGI_0_9.pg_matrix副本.csv')
# #【5.2.6】终极检查ppm
#因为前俩文件不同,所以单独检查
def checkTwoFiles():
f1=source_dir+'\\'+'Data1_File1_DDA_noPTM_NB4_A0_9_Abundance.csv'
ff1=target_dir+'\\'+'Data1_File1_DDA_noPTM_NB4_A0_9_Abundance副本_size_ppm.csv'
a=get_DiffRowSourceTarget(f1,ff1)
b=getNoGNRow(f1)
c=getRepetitionGNRow(r'D:\大学\王老师实验室\03项目\data\02\04_handledDataFile\Data1_File1_DDA_noPTM_NB4_A0_9_Abundance.csv')
d=getValueZeroRow(r'D:\大学\王老师实验室\03项目\data\02\04_handledDataFile\Data1_File1_DDA_noPTM_NB4_A0_9_Abundance副本.csv')
e=getNoFoundGNSize(r'D:\大学\王老师实验室\03项目\data\02\06_handledDataFile4\Data1_File1_DDA_noPTM_NB4_A0_9_Abundance副本.csv')
print('Data1_File1_DDA_noPTM_NB4_A0_9_Abundance.csv文件是否正确:',a==(b+c+d+e))
print('Data1_File1_DDA_noPTM_NB4_A0_9_Abundance.csv文件少的行数:', a - (b+c + d + e))
printToLogFile(log_file_path, 'Data1_File1_DDA_noPTM_NB4_A0_9_Abundance.csv是否正确:' + str(a == (b+c + d + e)) + '\r\n')
printToLogFile(log_file_path, 'Data1_File1_DDA_noPTM_NB4_A0_9_Abundance.csv文件少的行数:' + str(a - (b+c + d + e)) + '\r\n')
printToLogFile(log_file_path, '-' * 50 + '\r\n')
print('-'*100)
print('-'*100)
f2 = source_dir + '\\' + 'Data1_File2_DDA_PTM_NB4_A0_9_Abundance.csv'
ff2 = target_dir + '\\' + 'Data1_File2_DDA_PTM_NB4_A0_9_Abundance副本_size_ppm.csv'
a=get_DiffRowSourceTarget(f2, ff2)
b=getNoGNRow(f2)
c=getRepetitionGNRow(r'D:\大学\王老师实验室\03项目\data\02\04_handledDataFile\Data1_File2_DDA_PTM_NB4_A0_9_Abundance.csv')
d=getValueZeroRow(r'D:\大学\王老师实验室\03项目\data\02\04_handledDataFile\Data1_File2_DDA_PTM_NB4_A0_9_Abundance副本.csv')
e=getNoFoundGNSize(r'D:\大学\王老师实验室\03项目\data\02\06_handledDataFile4\Data1_File2_DDA_PTM_NB4_A0_9_Abundance副本.csv')
print('Data1_File2_DDA_PTM_NB4_A0_9_Abundance.csv文件是否正确:', a == (b + c + d + e))
print('Data1_File2_DDA_PTM_NB4_A0_9_Abundance.csv文件少的行数:', a - (b+c + d + e))
printToLogFile(log_file_path,'Data1_File2_DDA_PTM_NB4_A0_9_Abundance.csv是否正确:' + str(a == (b+c + d + e)) + '\r\n')
printToLogFile(log_file_path, 'Data1_File2_DDA_PTM_NB4_A0_9_Abundance.csv文件少的行数:' + str(a - (b+c + d + e)) + '\r\n')
printToLogFile(log_file_path, '-' * 50 + '\r\n')
print('-' * 100)
print('-' * 100)
checkTwoFiles()
#检查其他的文件
def checkOtherFiles():
souce_other_files_name=[i for i in getFilesName(source_dir) if 'Data1_' not in i]#除去前俩文件
target_other_files_name=[i for i in getFilesName(target_dir) if 'Data1_' not in i]#除去前俩文件
f_04_dir=r"D:\大学\王老师实验室\03项目\data\02\04_handledDataFile"
f_04_other_files_name=[i for i in getFilesName(f_04_dir) if ('副本' not in i)and('Data1_' not in i)]
f_04_other_files_fuben_name = [i for i in getFilesName(f_04_dir) if ('副本.csv' in i) and ('Data1_' not in i)]
f_06_4_dir=r"D:\大学\王老师实验室\03项目\data\02\06_handledDataFile4"
f_06_4_other_files_name=[i for i in getFilesName(f_06_4_dir) if 'Data1_' not in i]
for i in range(len(souce_other_files_name)):
# print(souce_other_files_name[i])
# print(target_other_files_name[i])
# print(f_04_other_files_name[i])
# print(f_04_other_files_fuben_name[i])
# print(f_06_4_other_files_name[i])
# print('-'*50)
f1=source_dir+'\\'+souce_other_files_name[i]
ff1=target_dir+'\\'+target_other_files_name[i]
a=get_DiffRowSourceTarget(f1,ff1)
b=getBlankGene(f1)
c=getRepetitionGNRow(f_04_dir+'\\'+f_04_other_files_name[i])
d=getValueZeroRow(f_04_dir+'\\'+f_04_other_files_fuben_name[i])
e=getNoFoundGNSize(f_06_4_dir+'\\'+f_06_4_other_files_name[i])
print(souce_other_files_name[i],'是否正确:', a == (b+c + d + e))
print(souce_other_files_name[i],'文件少的行数:',a - (b+c + d + e))
printToLogFile(log_file_path,souce_other_files_name[i]+'是否正确:'+str(a == (b+c + d + e))+'\r\n')
printToLogFile(log_file_path,souce_other_files_name[i]+'文件少的行数:'+str(a - (b+c + d + e))+'\r\n')
printToLogFile(log_file_path, '-'*50+'\r\n')
print('-' * 100)
print('-' * 100)
checkOtherFiles()
'''
原文件: Data1_File1_DDA_noPTM_NB4_A0_9_Abundance.csv , 行数: 6341
目标文件: Data1_File1_DDA_noPTM_NB4_A0_9_Abundance副本_size_ppm.csv , 行数: 4785
目标文件比原文件少的行数: 1556
--------------------------------------------------
文件: Data1_File1_DDA_noPTM_NB4_A0_9_Abundance.csv
没有基因的行数: 823 ==>正确
--------------------------------------------------
文件: Data1_File1_DDA_noPTM_NB4_A0_9_Abundance.csv
具有重复基因的行数: 165 ==>正确
--------------------------------------------------
文件: Data1_File1_DDA_noPTM_NB4_A0_9_Abundance副本.csv
全0行有: 506 ==>正确
--------------------------------------------------
文件: Data1_File1_DDA_noPTM_NB4_A0_9_Abundance副本.csv
未发现的基因有:
总个数为: 62 ==>正确
'''
#【】修改文件列名Genes->gene
def modifyColName(file_path):
df=pd.read_csv(file_path)
df.rename(columns={'Genes':'gene'},inplace=True)
df.to_csv(file_path,index=False)
file_dir=r"D:\大学\王老师实验室\03项目\data\02\05_handledDataFile2"
files_path=[i for i in getFilesName(file_dir) if '.csv' in i]
for i in files_path:
modifyColName(file_dir+'\\'+i)
#【】处理分号基因
def handleFenhaoGene(file_path):
print('处理分号基因文件:',file_path.split('\\')[-1])
df=pd.read_csv(file_path)
g=df['gene']
for i in range(len(g)):
if g[i] not in human_gene:#包括单个基因和分号基因
if ';' in g[i]:#分号基因
g_ls=g[i].split(';')#获得列表
print(g[i])
tag=0
for j in g_ls:
if j in human_gene:#在,改原文件gene名字
print(j,'基因在human,但不是第一个,修改')
df['gene'][i] = j#谁在改为谁
tag=1
break
if tag==0:#不在,把第一个加入human
g_first=g_ls[0]#第一个
print(g_first,'基因不在huamn,为第一个,修改')
df['gene'][i] = g_first#没在,改为第一个
p_size=search_for_gene_size(g_first)
if p_size:#没找到size不加入
a = {'ID': ' ', 'gene': [g_first], 'protein_size': p_size, 'annotation': g_first}
df = pd.DataFrame(a)
df.to_csv(r'D:\大学\王老师实验室\03项目\data\02\Human_protein_ID - 副本.csv', mode='a', index=False, header=False)
df.to_csv(file_path,index=False)#因为修改了分号基因的gene,所以需要重新写入
print('-'*50)
file_dir = r"D:\大学\王老师实验室\03项目\data\02\06_handledDataFile4"
files_path = [i for i in getFilesName(file_dir) if '.csv' in i]
for i in files_path:
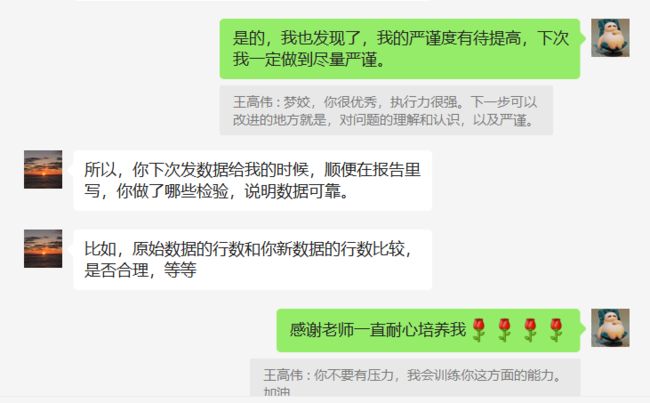
handleFenhaoGene(file_dir + '\\' + i)虽然,我知道一定还是会有错误,所以我发给老师的时候,说话严谨了很多,也给自己找好的后路,其实我依然有预感,这次数据还是错的。
想到这里,我又慌了!!!!!!!!!!!!!
啊啊啊啊啊啊!~~~~~~~~~~~~~~~