Pytorch : 模型部署
Pytorch部署
将模型导出为torchscript,参考链接
libtorch C++
组成部分
根据 PyTorch 官方文档 的介绍,PyTorch的C++ API可以粗略分为以下五个部分:
- ATen:基础的张量和数学计算库,其他的部分都以此为基础。
- Autograd:多 ATen 的扩展,包含自动微分功能。
- C++ Frontend:用于训练和验证机器学习模型的高层架构。
- TorchScript:TorchScipt JIT 编译器 / 解释器的接口。
- C++ Extensions:一系列使用 C++ 和 CUDA 例程扩展 Python API 的方法。
ATen
ATen 是一个基础的张量库,几乎所有 PyTorch 中的 Python 和 C++ 接口的以此为基础。ATen 提供了一个核心的 Tensor 类,并定义了它的几百种操作。大部分这些操作既可以在 CPU 上进行,也可以在 GPU 上进行。Tensor 类可以根据其类型动态地调度它们。一个 ATen 的小例子:
#include 对Tensor逐元素访问的高效方法
官方教程
Autograd
Autograd 是 PyTorch 的 C++ API 的一部分,它通过增加自动求导功能扩展增强了 Tensor 类。自动求导系统记录了 Tensor 的操作来形成一张自动求导图。并在该图的叶节点上调用 backward() 通过跨越图中的函数和张量网络执行反向模式微分,最终产生梯度。以下是一个示例:
#include ATen 中的类 at::Tensor 默认是不可微的。要添加 Autograd API 提供的张量的可微性,要使用torch:: 命名空间而不是 at:: 命名空间的张量工厂函数。也就是说,使用 at::ones 创建的张量是不可微的,但使用torch::ones 创建的张量是可微的。
C++ Frontend
PyTorch C++ 前端为神经网络和通用 ML(机器学习)研究和生产用例提供了一个高级的纯 C++ 建模接口,在设计和提供的功能上很大程度上与 Python API 保持一致。C++ 前端包括以下内容:
- 通过多层模块系统(如
torch.nn.Module)定义机器学习模型的接口; - 一些已有模块的的常见的建模方法(例如卷积、RNN、BN等)的“标准库”;
- 优化器 API,包括流行优化器的实现,如 SGD、Adam、RMSprop 等;
- 一系列表示数据集和数据处理管道的方法,包括在多个 CPU 内核上并行加载数据的功能;
- 用于保存和加载训练会话 checkpoint 的序列化格式(如
torch.utils.data.DataLoader); - 将模型自动并行化到多个 GPU(如
torch.nn.parallel.DataParallel); - 支持使用pybind11轻松将C++模型绑定到Python的代码;
- TorchScript JIT 编译器的入口点;
- 有助于与 ATen 和 Autograd API 接口的有用实用程序。
有关C++ 前端的更详细说明,可参阅此文档。 与 C++ 前端相关的torch::命名空间的相关部分包括torch::nn、 torch::optim、 torch::data、 torch::serialize、 torch::jit 和torch::python。C++ 前端的示例可以在此存储库中找到,该存储库正在持续且积极地扩展。
TorchScript
TorchScript 是一种 PyTorch 模型的表示,可以被 TorchScript 编译器理解、编译和序列化。从根本上说,TorchScript 本身就是一种编程语言。它是使用 PyTorch API 的 Python 子集。TorchScript 的 C++ 接口包含三个主要功能:
- 一种在 Python 中定义的用于加载和执行序列化 TorchScript 模型的机制;
- 用于定义扩展 TorchScript 标准操作库的自定义操作符的 API;
- 从 C++ 实时编译 TorchScript 程序。
如果您想尽可能在 Python 中定义模型,但随后将它们导出到 C++ 以用于生产环境和非 Python 推理,则第一种机制可能对您很感兴趣。您可以通过此链接了解更多信息。第二个 API 涉及您希望使用自定义算子扩展 TorchScript 的场景,这些算子同样可以在推理期间从 C++ 序列化和调用。最后,torch::jit::compile 函数可用于直接从 C++ 访问 TorchScript 编译器。
C++ Extension
C++ Extension 提供了一种访问上述所有接口的简单而强大的方法,目的是扩展 PyTorch 的常规 Python 用例。C++ 扩展最常用于在 C++ 或 CUDA 中实现自定义算子。C++ 扩展 API 没有向 PyTorch C++ API 添加任何新功能。而是提供了与 Python setuptools 的集成以及允许从 Python 访问 ATen、Autograd 和其他 C++ API 的 JIT 编译机制来进行自定义扩展。要了解有关 C++ 扩展 API 的更多信息,请阅读 本教程。
torch命名空间
| Component | Description |
|---|---|
| torch::Tensor | Automatically differentiable, efficient CPU and GPU enabled tensors |
| torch::nn | A collection of composable modules for neural network modeling |
| torch::optim | Optimization algorithms like SGD, Adam or RMSprop to train your models |
| torch::data | Datasets, data pipelines and multi-threaded, asynchronous data loader |
| torch::serialize | A serialization API for storing and loading model checkpoints |
| torch::python | Glue to bind your C++ models into Python |
| torch::jit | Pure C++ access to the TorchScript JIT compiler |
CUDA Stream任务级并行
官方教程
Onnx部署推理
优化模型以在各种平台和编程语言上运行是很困难的。要在各种框架和硬件组合中最大化性能非常耗时。Open Neural Network Exchange(ONNX) 运行时为您提供了一个解决方案,让您只需进行一次训练,即可在任何需要的硬件、云端或边缘设备上加速推断。
ONNX Runtime是一个跨平台的机器学习模型加速器,具有灵活的接口来集成特定于硬件的库。ONNX Runtime能够使用不同的执行提供者执行神经网络模型,如CPU、CUDA和TensorRT等。它也可以用于各种框架的模型,如PyTorch、Tensorflow/Keras、TFLite、scikit-learn等。

上图展示了使用ONNX运行时将预训练的PyTorch模型部署到c++应用程序中的管道。给定在PyTorch中预训练的模型文件(. pth文件或.pt文件),我们首先将该文件转换为ONNX格式的文件(.onnx文件)。这种转换也发生在PyTorch中。生成的onnx文件被输入到c++应用程序,该应用程序调用onnx Runtime c++ API来执行推理。
Conversion from the PyTorch model to ONNX
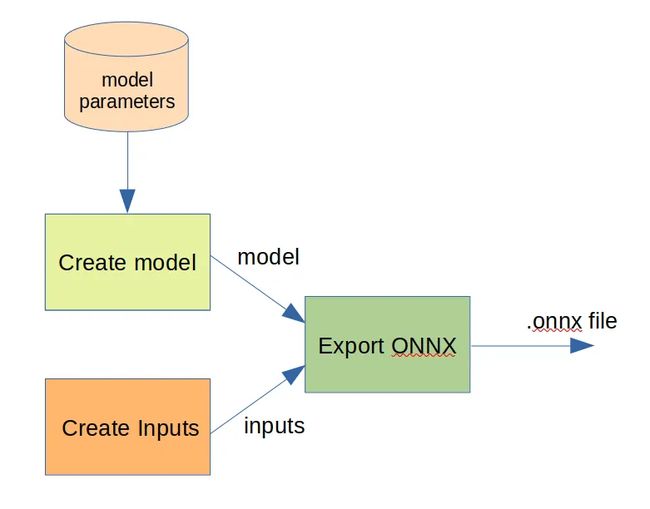
从.pth/.pt文件到.onnx文件的转换可以在PyTorch中通过四个步骤简单地完成。首先需要创建网络,如果在GPU上进行推理,则需要将模型放到CUDA中。
net = Model()
net.cuda()
其次,将存储在.pth/.pt文件中的模型参数加载到模型中
PATH = 'model.pth'
net.load_state_dict(torch.load(PATH))
net.eval()
在创建模型之后,我们指定输入。输入可以简单地设置为模型所需的具有正确形状的随机张量。形状格式为NCHW(批大小*通道数量*高度*宽度)。例如,输入可以设置如下
x = torch.randn((1, 3, 32, 32)).cuda()
最后,给定模型和输入,可以导出.onnx文件
torch.onnx.export(net, # model being run
x, # model input
"model.onnx", # where to save the model
export_params=True, # store the trained weights
opset_version=11, # the ONNX version
do_constant_folding=True,
input_names= ['input'], # set model input names
output_names=['output'], # set model output names
)
Inference using ONNX Runtime

使用ONNX Runtime c++ API执行推理包括两个步骤:初始化和推理。在初始化步骤中,创建ONNX运行时环境,并设置ONNX运行时会话的选项。给定运行时环境、会话选项和预训练的ONNX模型,就会创建ONNX运行时会话。ONNX运行时会话用于
- 与创建的分配器结合时,提取模型输入和输出的信息,如模型输入/输出的数量、名称、类型和形状,
- 在推理阶段运行推理
推理阶段从初始化步骤接收模型输入和输出的数字、名称、类型和形状,然后执行推理任务。它首先创建输入和输出张量,并为这些张量分配内存。然后,运行ONNX运行时会话来执行推理。最后对推理结果进行后处理,得到最终的预测结果
我实现了一个图像分类器类,它有ONNX运行时环境,会话,模型输入和输出的名称和形状的字段变量。这些变量将被ONNX运行时推断使用。
class ImageClassifier {
private:
// ORT Environment
std::shared_ptr<Ort::Env> mEnv;
// Session
std::shared_ptr<Ort::Session> mSession;
// Inputs
char* mInputName;
std::vector<int64_t> mInputDims; // shape
// Outputs
char* mOutputName;
std::vector<int64_t> mOutputDims; // shape
然后在类构造函数中执行如图3所示的初始化步骤,以创建运行时环境、会话和分配器
/******* Create ORT environment *******/
std::string instanceName{"Image classifier inference"};
mEnv = std::make_shared<Ort::Env>(OrtLoggingLevel::ORT_LOGGING_LEVEL_WARNING,instanceName.c_str());
/******* Create ORT session *******/
// Set up options for session
Ort::SessionOptions sessionOptions;
// Enable CUDA
sessionOptions.AppendExecutionProvider_CUDA(OrtCUDAProviderOptions{});
// Sets graph optimization level (Here, enable all possible optimizations)
sessionOptions.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
// Create session by loading the onnx model
mSession = std::make_shared<Ort::Session>(*mEnv, modelFilepath.c_str(), sessionOptions);
/******* Create allocator *******/
// Allocator is used to get model information
Ort::AllocatorWithDefaultOptions allocator;
模型输入和输出的信息,比如输入/输出的数量、名称和形状,也可以在类构造函数中使用创建的会话和分配器获得
/******* Inputs *******/
// Number of input nodes
size_t numInputNodes = mSession->GetInputCount();
// Name of input
// 0 means the first input
mInputName = mSession->GetInputName(0, allocator);
// Input type
Ort::TypeInfo inputTypeInfo = mSession->GetInputTypeInfo(0);
auto inputTensorInfo = inputTypeInfo.GetTensorTypeAndShapeInfo();
ONNXTensorElementDataType inputType = inputTensorInfo.GetElementType();
// Input shape
mInputDims = inputTensorInfo.GetShape();
/******* Outputs *******/
// Number of output nodes
size_t numOutputNodes = mSession->GetOutputCount();
// Name of output
// 0 mans the first output
mOutputName = mSession->GetOutputName(0, allocator);
// Output type
Ort::TypeInfo outputTypeInfo = mSession->GetOutputTypeInfo(0);
auto outputTensorInfo = outputTypeInfo.GetTensorTypeAndShapeInfo();
ONNXTensorElementDataType outputType = outputTensorInfo.GetElementType();
// Output shape
mOutputDims = outputTensorInfo.GetShape();
初始化步骤完成后,使用ONNX Runtime c++ API对每个图像进行推理,如图3所示。首先,对图像进行加载和预处理,以便与预训练的模型输入兼容。然后,我以ONNX运行时所需的格式创建输入张量
// Load an input image
cv::Mat img = cv::imread(imageFilepath, cv::IMREAD_COLOR);
cv::Mat scaledImage, preprocessedImage;
// Scale image pixels from [0 255] to [-1, 1]
img.convertTo(scaledImage, CV_32F, 2.0f / 255.0f, -1.0f);
// Convert HWC to CHW
cv::dnn::blobFromImage(scaledImage, preprocessedImage);
// Create input tensor buffer and assign preprocessed image to the buffer
size_t inputTensorSize = vectorProduct(mInputDims);
std::vector<float> inputTensorValues(inputTensorSize);
inputTensorValues.assign(preprocessedImage.begin<float>(),
preprocessedImage.end<float>());
// Create input tensors of ORT::Value, which is a tensor format used by ONNX Runtime
std::vector<Ort::Value> inputTensors;
Ort::MemoryInfo memoryInfo = Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
inputTensors.push_back(Ort::Value::CreateTensor<float>(memoryInfo, inputTensorValues.data(),inputTensorSize,mInputDims.data(),mInputDims.size()));
类似地,我创建输出张量,如下所示
// Create output tensor buffer
size_t outputTensorSize = vectorProduct(mOutputDims);
std::vector<float> outputTensorValues(outputTensorSize);
// Create output tensors of ORT::Value
std::vector<Ort::Value> outputTensors;
outputTensors.push_back(Ort::Value::CreateTensor<float>(memoryInfo, outputTensorValues.data(), outputTensorSize,mOutputDims.data(), mOutputDims.size()));
在创建完输入和输出张量之后,我们调用Session run方法来执行推理
std::vector<const char*> inputNames{mInputName};
std::vector<const char*> outputNames{mOutputName};
// 1 means number of inputs and outputs
mSession->Run(Ort::RunOptions{nullptr}, inputNames.data(),inputTensors.data(), 1, outputNames.data(),outputTensors.data(), 1);
最后,对推理结果进行后处理,得到输入图像的预测类
// Get the inference result
float* floatarr =
outputTensors.front().GetTensorMutableData<float>();
// Compute the index of the predicted class
// 10 means number of classes in total
int cls_idx = std::max_element(floatarr, floatarr + 10) - floatarr;
Exporting the model to ONNX
PyTorch 具有原生的 ONNX 导出支持。但是,由于 PyTorch 执行图的动态性质,因此导出过程必须遍历执行图以生成持久化的 ONNX 模型。因此,在导出例程中应传入适当大小的测试变量(在我们的情况下,我们将创建一个正确大小的虚拟零张量)。您可以从训练数据集的 shape 函数中获取尺寸大小,例如 tensor.shape:
input_image = torch.zeros((1,28,28))
onnx_model = 'data/model.onnx'
onnx.export(model, input_image, onnx_model)
加载ONNX模型并推断
我们需要使用onnxruntime.InferenceSession创建推断会话。为了对ONNX模型进行推断,使用run函数并传入您想要返回的输出列表(如果您想返回所有输出,请留空),以及一个输入值的映射。结果是一个输出列表。
onnxruntime.InferenceSession是使用 ONNX 运行时库创建的推断会话对象,用于加载和执行 ONNX 模型进行推断。通过使用 onnxruntime.InferenceSession,您可以轻松地将训练好的模型导出为 ONNX 格式,然后在其他设备、平台或编程语言上进行推断,而不需要重新训练模型。在推断过程中,您只需将输入数据传递给会话对象,然后会话对象将返回相应的输出。ONNX 运行时库提供了高效、跨平台、跨硬件的推断支持,可以在多种硬件和操作系统上加速推断。
InferenceSession构造
onnxruntime.InferenceSession构造函数接受以下参数:
model_path:必需。指定要加载的 ONNX 模型文件的路径。这是唯一必需的参数。sess_options:可选。用于配置会话的选项。这是一个onnxruntime.SessionOptions对象。您可以使用这个对象来设置会话的一些属性,如线程数、计算设备、图形优化等等。providers:可选。用于指定要使用的计算提供程序的名称。这是一个字符串列表。计算提供程序是用于在不同硬件和操作系统上执行模型的代码库。默认情况下,ONNX 运行时库会尝试自动检测并选择最佳的计算提供程序。您可以使用这个参数来覆盖默认值,或者指定要使用的特定计算提供程序。provider_options:可选。用于配置计算提供程序的选项。这是一个字典,其中键是计算提供程序的名称,值是一个onnxruntime.ProviderOptions对象。这个参数允许您为每个计算提供程序配置不同的选项。例如,您可以使用这个参数为不同的硬件设备配置不同的选项。custom_ops_library:可选。指定要加载的自定义操作库的路径。这个参数可以用于加载包含自定义操作的 ONNX 模型。如果您的模型使用了自定义操作,您需要将自定义操作库的路径传递给这个参数。custom_op_paths:可选。指定要加载的自定义操作库路径列表。这个参数可以用于加载包含自定义操作的 ONNX 模型。如果您的模型使用了自定义操作,您需要将自定义操作库的路径传递给这个参数。
总之,您可以使用这些参数来自定义您的 ONNX 推断会话的行为和性能,并根据您的需求进行优化。
InferenceSession推断函数
onnxruntime.InferenceSession.run()函数是在使用ONNX模型进行推理时的核心函数之一。它的作用是运行模型推理并返回输出结果。
下面是该函数的详细解释:
onnxruntime.InferenceSession.run(output_names=None, input_feed=None, run_options=None)
参数说明:
output_names:一个包含要获取输出的Tensor名称的列表。默认值为None,表示返回所有输出Tensor。input_feed:一个字典,用于指定输入Tensor的名称和值。键是输入Tensor的名称,值是NumPy数组或稀疏Tensor。默认值为None,表示没有输入Tensor。run_options:一个可选的RunOptions对象,用于配置运行选项。默认值为None。
返回值说明:
该函数返回一个包含输出Tensor值的列表。
该函数的使用示例如下:
import onnxruntime as ort
import numpy as np
# 加载ONNX模型
sess = ort.InferenceSession("model.onnx")
# 准备输入数据
input_data = np.array([[1, 2, 3], [4, 5, 6]], dtype=np.float32)
# 执行推理
output = sess.run(["output"], {"input": input_data})
# 输出结果
print(output)
在这个例子中,我们首先使用ort.InferenceSession()函数加载ONNX模型,然后准备输入数据并通过sess.run()函数执行推理,最后打印输出结果。