[C++] 一篇带你搞懂引用(&)-- C++入门(3)
问题引入
在我们日常的生活中每个人都或多或少存在一个"外号",例如《西游记》中孙悟空就有诸多外号:美猴王,孙行者,齐天大圣等等。那么在C++中,也可以给一个已经存在的变量取别名,这就是引用。
那么接下来深入来探讨一下引用
目录
1.引用的概念
1.1引用的表示方法
1.2引用特性
1.3常引用 引用权限
1.4引用的使用场景
1.4.1做参数
1.4.2做返回值
传值的底层过程:
引用导致野指针:
1.5值和引用作为返回值类型的性能比较
1.6引用和指针的区别
1.引用的概念
1.1引用的表示方法
类型 & 引用变量名 ( 对象名 ) = 引用实体;
如果熟悉C语言的同学可能会发现引用符号(&)看上去就像取地址运算符(&)或者按位AND运算符(&),其实这是一个运算符重载的例子。通过重载,同一个运算符将会有不同的含义。编译器会通过上下文来确定运算符的含义。除了这里所提到的,其实在C++中还有一些运算符重载的情况。例如:* 即表示乘法,又表示对指针的解引用操作;<<即表示插入运算符,又表示按位左移运算符等。
代码实例:
int main()
{
//引用:取别名
int a = 10;
int& b = a;//定义引用类型
int& c = b;
return 0;
}本段代码我们可以得知,a变量取了b,c两个别名。
我们也可以通过调试观察他们的内存:
![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第1张图片](http://img.e-com-net.com/image/info8/71e63ef5532f4a7ca3f4b358973585fc.jpg)
通过调取内存我们可以发现,a,b,c所指向的是同一块内存空间。
1.2引用特性
引用有三个特性,分别是:
1. 引用在 定义时必须初始化2. 一个变量可以有多个引用3. 引用一旦引用一个实体,再不能引用其他实体
1.引用在定义的时候必须初始化
由于引用是对已经存在的变量进行取别名,因此使用引用时必须指定变量(初始化)。
int& d;//错误,未初始化2.一个变量可以有多个引用
在C++语法中,一个变量有多个引用,就类似于一个人可以有多个外号。在1.1的代码实例中变量a就有2个引用,分别是b和c。
3.引用一旦引用一个实体,再不能引用其他实体
这个也比较好理解,因为引用一旦引用了一个已经存在的实体,就是这个实体的别名,当然不能再成为其他实体的别名。
1.3常引用 引用权限
我们来观察下面这段代码,他能编译成功吗?
int main()
{
//1.
const int x = 20;
int& y = x;
return 0;
}当我们编译这段代码发现编译器报出错误警告: 无法从“const int”转换为“int &”
![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第2张图片](http://img.e-com-net.com/image/info8/82c7c9c6e3c5492c9be4cd7993641956.png)
这是因为我们在引用的时候要遵守引用的原则:
引用原则:对原变量的引用,权限不能放大。
1.3这段代码中x变量是const修饰是一个常变量,只有可读权限。而我们引用的类型是int,不仅有可读权限,还有可修改权限。这就造成了对原变量的权限放大。根据我们引用原则知道,对原变量的引用,权限是不能放大的,这就是为什么这段代码会报错的原因。
那我们再来看这一段代码,它能编译成功吗?
int main()
{
//2.
const int x = 20;
const int& y = x;//不变
//3.
int c = 30;
const int& d = c;//缩小
return 0;
}![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第3张图片](http://img.e-com-net.com/image/info8/5d933f194c4548498238f4eb8fd08d74.png)
这段代码我们发现编译成功了,我们也可以轻松地分析出这里的引用是遵守引用规则的,我们发现,权限不变或者权限缩小都是符合规则的,唯一需要注意的是:权限不能放大。
1.4引用的使用场景
1.4.1做参数
void Swap(int& x, int& y)
{
int tmp = x;
x = y;
y = tmp;
}
int main()
{
int a = 0, b = 1;
Swap(a, b);
return 0;
}引用可以作函数的形参,x是a的别名,y是b的别名。这里使用引用更加方便,也更好理解。
那既然以值作为函数参数和以引用作为函数参数都能解决这个问题,那为什么还要使用引用来做参数呢?这是因为引用的效率更高,我们可以通过下面这段测试代码更加直观看出效率的差别:
#include
struct A { int a[10000]; };
void TestFunc1(A a) {}
void TestFunc2(A& a) {}
void TestRefAndValue()
{
A a;
// 以值作为函数参数
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 以引用作为函数参数
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 分别计算两个函数运行结束后的时间
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
int main()
{
TestRefAndValue();
return 0;
} ![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第4张图片](http://img.e-com-net.com/image/info8/b515a49cb83c4c1b982bca8600181ea9.png)
我们发现使用引用作为函数参数效率大大提高。以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
引用做参数的意义:
1.输出型参数。
2.减少拷贝,提高效率。
1.4.2做返回值
首先我们来观察这段代码的返回值是什么?
int Count()
{
static int n = 0;
n++;
return n;
}
int main()
{
cout << Count() << endl;
cout << Count() << endl;
cout << Count() << endl;
return 0;
}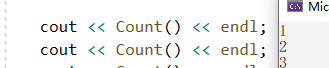
这里的结果是:1 2 3
因为n是局部静态的成员变量,只会初始化一次,虽然作用域在Count函数内部,但是生命周期是全局,我们可以通过调试观看他是否再执行函数的第一句?
![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第5张图片](http://img.e-com-net.com/image/info8/0dbe1e976adc45238e45946508902fa1.jpg)
传值的底层过程:
![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第6张图片](http://img.e-com-net.com/image/info8/a3e6be75f72e4718a67cb9113abbd9ba.png)
传值返回这个过程当中会产生一个临时变量,跟传参一样,如果小会用寄存器替代。传值返回的类型其实是临时变量的类型,将n拷贝给临时变量,再将临时变量拷贝给ret。那么为什么要设计临时变量呢?直接把n给ret不好吗?
这是因为在当临时变量出了函数作用域之后会销毁,函数栈桢也会销毁,那么此时n是不能作为返回值再赋值给ret的。那么编译器就在此生成了一个临时变量,把n拷给临时变量,再把临时变量给ret。此时,函数栈桢销毁是不会影响临时变量的。
![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第7张图片](http://img.e-com-net.com/image/info8/df28ffc1746747199816291808a5e2be.png)
![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第8张图片](http://img.e-com-net.com/image/info8/9fc18b0787c445eeb4773af98ef1433b.jpg)
那我们怎么可以证明这个过程产生了临时变量,我们可以给ret前加个引用。
![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第9张图片](http://img.e-com-net.com/image/info8/edbc973e31784590a756f50bc541d3dc.jpg)
此时我们发现,编译器是过不了的,这是因为此时ret是引用的临时变量,而临时变量具有常性,这里属于权限的放大,因此我们只需要加上const即可。我们也通过这个例子证明了临时变量的存在。
![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第10张图片](http://img.e-com-net.com/image/info8/6a5932663e014db594705c7b870d6852.png)
那现在我们给Count函数加个引用是什么意思?我们来看这段代码。
int& Count()
{
int n = 0;
n++;
return n;
}
//中间产生了一个临时变量
int main()
{
int ret = Count();
return 0;
}这里可以这么认为,中间也会产生一个临时变量,这个临时变量的类型为int&,此时这个临时变量是n的别名,再把临时变量赋给ret。返回的是一个n的别名,就相当于是吧n返回给了ret。
![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第11张图片](http://img.e-com-net.com/image/info8/e4f149ee73d74dcaa8182021b8af1ad1.jpg)
此时我们再观察这段代码我们发现编译器可以通过了,这里ret相当于是n的别名。
我们可以打印n和ret的地址看看:
![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第12张图片](http://img.e-com-net.com/image/info8/4f1a0748571b480780072d135058a191.jpg)
这里ret和n的地址相同,也能证明ret是n的别名。因此,引用作为返回值其实返回的就是n的别名。
引用导致野指针:
![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第13张图片](http://img.e-com-net.com/image/info8/27807fb5ea7546ddb853239d161cc35b.jpg)
这段代码合法吗?
其实这段代码是不合法的,因为出了函数的作用域,Count函数已经销毁了,我们再对此空间进行访问,就会造成非法访问,这里就是引用搞出来的野指针。
我们来验证一下:
//传引用返回的是n的别名
int& Count()
{
int n = 0;
n++;
//cout << "n:"<< & n << endl;
return n;
}
//中间产生了一个临时变量
int main()
{
int& ret = Count(); //ret是别名的别名 也就是n的别名
cout << ret << endl;
cout << "ret"<< & ret << endl;
cout << ret << endl;
return 0;
}通过打印我们能够发现:第二个ret打印的是随机值。
![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第14张图片](http://img.e-com-net.com/image/info8/10ee773ce8384be1a1ac708394237833.jpg)
因此此处需要注意 :如果函数返回时,出了函数作用域,如果返回对象还未还给系统,则可以使用引用返回,如果已 经还给系统了,则必须使用传值返回。
我们来做一个实例巩固一下:
下面这段代码的结果是什么?为什么?
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
Add(3, 4);
cout << "Add(1, 2) is :" << ret << endl;
return 0;
}![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第15张图片](http://img.e-com-net.com/image/info8/a5ee10b74550416789d15bd10c29202f.jpg)
结果:7,这里是因为在第一次调用Add时,ret为3,Add函数的栈桢销毁,在第二次调用时,Add函数的栈桢是相同的,c的位置为覆盖为7,再次访问ret此时就为7,因此这里使用是不安全的。以下打印就可以更加清晰了解这个过程。
![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第16张图片](http://img.e-com-net.com/image/info8/148226cc9088423f83bf0abbe7db6df9.jpg)
1.5值和引用作为返回值类型的性能比较
#include
struct A { int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a; }
// 引用返回
A& TestFunc2() { return a; }
void TestReturnByRefOrValue()
{
// 以值作为函数的返回值类型
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1();
size_t end1 = clock();
// 以引用作为函数的返回值类型
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2();
size_t end2 = clock();
// 计算两个函数运算完成之后的时间
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{
TestReturnByRefOrValue();
return 0;
} ![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第17张图片](http://img.e-com-net.com/image/info8/e97656802c734400b121431a9d3acc6b.png)
通过打印我们发现引用作为返回值类型大大提高了效率。
原因:以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
1.6引用和指针的区别
引用在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。 在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。
int main()
{
int a = 10;
int& ra = a;
ra = 20;
int* pa = &a;
*pa = 20;
return 0;
}我们来看引用和指针的汇编代码对比:
![[C++] 一篇带你搞懂引用(&)-- C++入门(3)_第18张图片](http://img.e-com-net.com/image/info8/7882fe4b84404ad1a5f9c703c0895b4b.png)
因此引用的底层实现上是按照指针的方式来实现的。
引用和指针的不同点:1. 引用在定义时必须初始化,指针没有要求2. 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体3. 没有NULL引用,但有NULL指针4. 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)5. 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小6. 有多级指针,但是没有多级引用7. 访问实体方式不同,指针需要显式解引用,引用编译器自己处理8. 引用比指针使用起来相对更安全
(本篇完)