zookeeper下载安装详细图文教程
1.下载jar包并解压zookeeper
链接:https://pan.baidu.com/s/1tI2DzIaSVmn0sHWu18P9Cw
提取码:1234
2.修改环境变量(环境变量的路径就是zookeeper文件的位置)如果没有vim文件编辑就用vi编辑,一样的,或者直接下载一下 yum -y install vim 。
[root@hadoop101 ~]#mv apache-zookeeper-3.5.7-bin.tar.gz zookeeper #修改文件名字
[root@hadoop101 ~]#sudo vim /etc/profile.d/my_env.sh #配置环境变量#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/opt/module/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin如下图所示:

3.配置/opt/module/zookeeper/conf/下的zoo.cfg文件
[qurui@hadoop102 ~]$ cd /opt/module/zookeeper/conf/ #进入目录
[qurui@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg #修改名字
[qurui@hadoop102 conf]$ vim zoo.cfg #打开修改文件修改以下两个地方:
dataDir=/opt/module/zookeeper-3.5.7/zkData
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888如下图:

4.创建zkData目录和myid文件,在myid文件写入2,这个取决于上面的server.2,小数点后写几,这个就写几。
[qurui@hadoop102 conf]$ cd .. #退回zookeeper的目录下
[qurui@hadoop102 zookeeper]$ mkdir -p zkData #建立zkDate文件夹
[qurui@hadoop102 zookeeper]$ cd zkDate #进入zkDate文件夹
[qurui@hadoop102 zkData]$ touch myid #建立myid文件
[qurui@hadoop102 zkData]$ vim myid #打开myid文件
2 #写入一个2就行,这个取决于上面的server.2,小数点后写几,这个就写几。5. 其他机器重复以上步骤,注意,myid的值需要变,与上文的server对应,如果根据本文走,应该是3,4。如果可以分发文件那直接分发就行,博主会出一期分发文件的博客,直接再其他机器上也装一遍也行。
6. 检查zookeeper状态

mode显示leader,即成功。
7.为了达到博客的字数要求,添加了一些zookeeper的基础知识,和安装没什么关系:
1. 概述
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
2.特点
1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。2)集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。 3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。4)更新请求顺序进行,来自同一个Client的更新请求按其发送顺序依次执行。 5)数据更新原子性,一次数据更新要么成功,要么失败。6)实时性,在一定时间范围内,Client能读到最新数据。
3.命令行操作
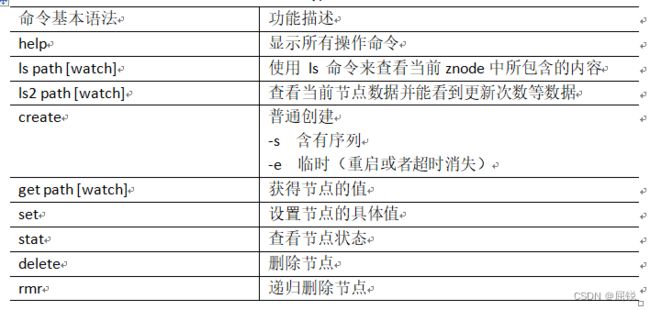
4.paxos算法
Paxos算法流程中的每条消息描述如下:
- Prepare: Proposer生成全局唯一且递增的Proposal ID (可使用时间戳加Server ID),向所有Acceptors发送Prepare请求,这里无需携带提案内容,只携带Proposal ID即可。
- Promise: Acceptors收到Prepare请求后,做出“两个承诺,一个应答”。
两个承诺:
- 不再接受Proposal ID小于等于(注意:这里是<= )当前请求的Prepare请求。
- 不再接受Proposal ID小于(注意:这里是< )当前请求的Propose请求。
一个应答:
- 不违背以前做出的承诺下,回复已经Accept过的提案中Proposal ID最大的那个提案的Value和Proposal ID,没有则返回空值。
- Propose: Proposer 收到多数Acceptors的Promise应答后,从应答中选择Proposal ID最大的提案的Value,作为本次要发起的提案。如果所有应答的提案Value均为空值,则可以自己随意决定提案Value。然后携带当前Proposal ID,向所有Acceptors发送Propose请求。
- Accept: Acceptor收到Propose请求后,在不违背自己之前做出的承诺下,接受并持久化当前Proposal ID和提案Value。
- Learn: Proposer收到多数Acceptors的Accept后,决议形成,将形成的决议发送给所有Learners。
5.选举机制
1)半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器。
2)Zookeeper虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内部的选举机制临时产生的。
3)以一个简单的例子来说明整个选举的过程。假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的ID比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。