Hudi系列7:使用SparkSQL操作Hudi
文章目录
- 一. SparkSQL连接Hudi
-
- 1.1 Hive配置
- 1.2 SparkSQL连接Hudi
- 二. 创建表
-
- 2.1 常规的建表
- 2.2 CTAS
- 三. 插入数据
- 四. 查询数据
- 五. 更新数据
-
- 5.1 普通
- 5.2 MergeInto
- 六. 删除数据
- 七. Insert Overwrite
- 参考:
一. SparkSQL连接Hudi
1.1 Hive配置
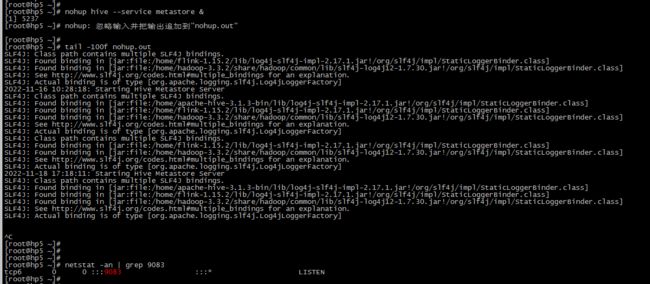
我们需要将Hive 的 metastore服务独立出来
-- 目前只指定一个节点,也可以只用zookeeper做个高可用
cd $HIVE_HOME/conf
vi hive-site.xml
hive.metastore.uris
thrift://hp5:9083
然后启动hive metastore 服务
nohup hive --service metastore &
netstat -an | grep 9083
1.2 SparkSQL连接Hudi
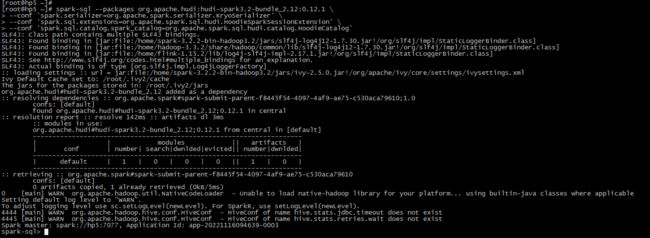
# Spark 3.3
spark-sql --packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
二. 创建表
创建表的时候有如下3个需要注意:
-
表类型
Hudi的两种表类型,即写时复制(COW)和读时合并(MOR),都可以使用Spark SQL创建。在创建表时,可以使用type选项指定表的类型:type = 'cow’或type = ‘mor’。 -
分区表和非分区表
用户可以在Spark SQL中创建分区表或非分区表。要创建分区表,需要使用partitioned by语句指定分区列以创建分区表。当没有使用create table命令进行分区的语句时,该表被认为是一个非分区表。 -
Managed表和External表
通常,Spark SQL支持两种表,即Managed表和External表。如果使用location语句或使用create external table显式地创建表来指定一个位置,则它是一个外部表,否则它被认为是一个托管表。你可以在这里阅读更多关于外部vs托管表的信息。
2.1 常规的建表
语法:
创建表的时候需要指定路径,不指定路径创建到本地了,Spark启用的是集群,其它节点访问不到,会产生报错。
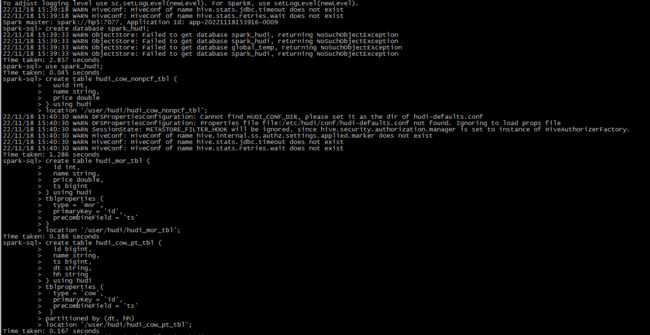
-- 创建数据库
create database spark_hudi;
use spark_hudi;
-- 创建一个表,不指定参数
create table hudi_cow_nonpcf_tbl (
uuid int,
name string,
price double
) using hudi
location '/user/hudi/hudi_cow_nonpcf_tbl';
-- 创建一个MOR的非分区表
-- preCombineField 预聚合列 当id相同的时候,保留ts更大的那一条
create table hudi_mor_tbl (
id int,
name string,
price double,
ts bigint
) using hudi
tblproperties (
type = 'mor',
primaryKey = 'id',
preCombineField = 'ts'
)
location '/user/hudi/hudi_mor_tbl';
-- 创建一个预聚合分区的COW表
create table hudi_cow_pt_tbl (
id bigint,
name string,
ts bigint,
dt string,
hh string
) using hudi
tblproperties (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (dt, hh)
location '/user/hudi/hudi_cow_pt_tbl';
测试记录:
2.2 CTAS
代码:
-- CTAS: create a non-partitioned cow table without preCombineField
create table hudi_ctas_cow_nonpcf_tbl
using hudi
tblproperties (primaryKey = 'id')
location '/user/hudi/hudi_ctas_cow_nonpcf_tbl'
as
select 1 as id, 'a1' as name, 10 as price;
create table hudi_ctas_cow_pt_tbl
using hudi
tblproperties (type = 'cow', primaryKey = 'id', preCombineField = 'ts')
partitioned by (dt)
location '/user/hudi/hudi_ctas_cow_pt_tbl'
as
select 1 as id, 'a1' as name, 10 as price, 1000 as ts, '2021-12-01' as dt;
测试记录:
虽然建表过程看到有报错,但是依旧是成功的
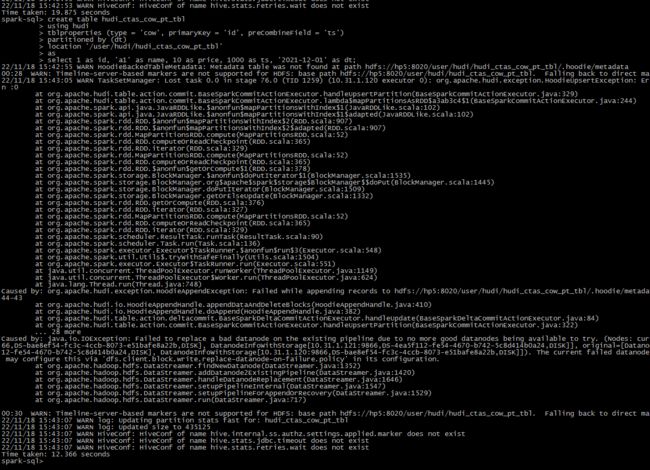
![]()
三. 插入数据
-- insert into non-partitioned table
insert into hudi_cow_nonpcf_tbl select 1, 'a1', 20;
insert into hudi_mor_tbl select 1, 'a1', 20, 1000;
-- insert dynamic partition
insert into hudi_cow_pt_tbl partition (dt, hh)
select 1 as id, 'a1' as name, 1000 as ts, '2021-12-09' as dt, '10' as hh;
-- insert static partition
insert into hudi_cow_pt_tbl partition(dt = '2021-12-09', hh='11') select 2, 'a2', 1000;
-- upsert mode for preCombineField-provided table
insert into hudi_mor_tbl select 1, 'a1_1', 20, 1001;
select id, name, price, ts from hudi_mor_tbl;
1 a1_1 20.0 1001
-- bulk_insert mode for preCombineField-provided table
set hoodie.sql.bulk.insert.enable=true;
set hoodie.sql.insert.mode=non-strict;
insert into hudi_mor_tbl select 1, 'a1_2', 20, 1002;
select id, name, price, ts from hudi_mor_tbl;
1 a1_1 20.0 1001
1 a1_2 20.0 1002
测试记录:
虽然比insert hive_table快一些,但是感觉速度依旧不行
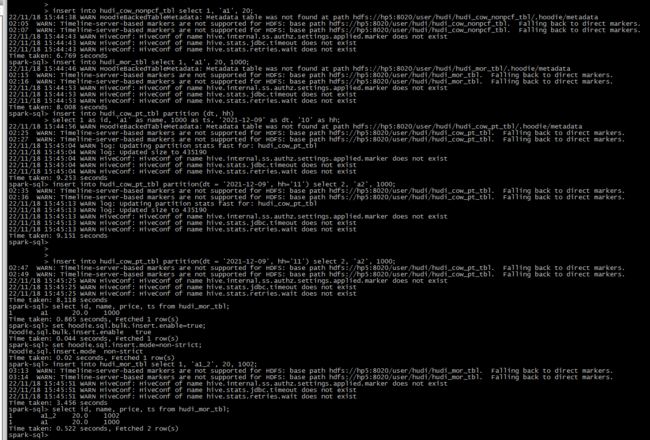
四. 查询数据
代码:
# 普通查询
select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0;
# 基于时间线查询
create table hudi_cow_pt_tbl (
id bigint,
name string,
ts bigint,
dt string,
hh string
) using hudi
tblproperties (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (dt, hh)
location '/user/hudi/hudi_cow_pt_tbl';
insert into hudi_cow_pt_tbl select 1, 'a0', 1000, '2021-12-09', '10';
select * from hudi_cow_pt_tbl;
-- record id=1 changes `name`
insert into hudi_cow_pt_tbl select 1, 'a1', 1001, '2021-12-09', '10';
select * from hudi_cow_pt_tbl;
-- time travel based on first commit time, assume `20221118154519532`
select * from hudi_cow_pt_tbl timestamp as of '20221118154519532' where id = 1;
-- time travel based on different timestamp formats
select * from hudi_cow_pt_tbl timestamp as of '2022-11-18 15:45:19.532' where id = 1;
select * from hudi_cow_pt_tbl timestamp as of '2022-03-08' where id = 1;

五. 更新数据
5.1 普通
语法:
UPDATE tableIdentifier SET column = EXPRESSION(,column = EXPRESSION) [ WHERE boolExpression]
代码:
update hudi_mor_tbl set price = price * 2, ts = 1111 where id = 1;
update hudi_cow_pt_tbl set name = 'a1_1', ts = 1001 where id = 1;
-- update using non-PK field
update hudi_cow_pt_tbl set ts = 1001 where name = 'a1';
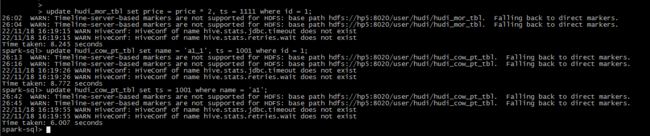
5.2 MergeInto
语法:
MERGE INTO tableIdentifier AS target_alias
USING (sub_query | tableIdentifier) AS source_alias
ON
[ WHEN MATCHED [ AND ] THEN ]
[ WHEN MATCHED [ AND ] THEN ]
[ WHEN NOT MATCHED [ AND ] THEN ]
=A equal bool condition
=
DELETE |
UPDATE SET * |
UPDATE SET column1 = expression1 [, column2 = expression2 ...]
=
INSERT * |
INSERT (column1 [, column2 ...]) VALUES (value1 [, value2 ...])
代码:
-- source table using hudi for testing merging into non-partitioned table
create table hudi_merge_source (id int, name string, price double, ts bigint) using hudi
tblproperties (primaryKey = 'id', preCombineField = 'ts')
location '/user/hudi/hudi_merge_source';
insert into hudi_merge_source values (1, "old_a1", 22.22, 900), (2, "old_a2", 33.33, 2000), (3, "old_a3", 44.44, 2000);
create table hudi_merge_source2 (id int, name string, price double, ts bigint) using hudi
tblproperties (primaryKey = 'id', preCombineField = 'ts')
location '/user/hudi/hudi_merge_source2';
insert into hudi_merge_source2 values (2, "new_a2", 22.22, 900), (3, "new_a3", 33.33, 2000), (4, "new_a4", 44.44, 2000);
merge into hudi_merge_source as target
using (
select * from hudi_merge_source2
) source
on target.id = source.id
when matched then
update set name = source.name, price = source.price, ts = source.ts
when not matched then
insert (id, name, price, ts) values(source.id, source.name, source.price, source.ts);
测试记录:
spark-sql>
> create table hudi_merge_source (id int, name string, price double, ts bigint) using hudi
> tblproperties (primaryKey = 'id', preCombineField = 'ts')
> location '/user/hudi/hudi_merge_source';
22/11/25 11:33:55 WARN DFSPropertiesConfiguration: Cannot find HUDI_CONF_DIR, please set it as the dir of hudi-defaults.conf
22/11/25 11:33:55 WARN DFSPropertiesConfiguration: Properties file file:/etc/hudi/conf/hudi-defaults.conf not found. Ignoring to load props file
22/11/25 11:33:58 WARN SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory.
Time taken: 3.65 seconds
spark-sql> insert into hudi_merge_source values (1, "old_a1", 22.22, 900), (2, "old_a2", 33.33, 2000), (3, "old_a3", 44.44, 2000);
00:27 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://hp5:8020/user/hudi/hudi_merge_source. Falling back to direct markers.
00:32 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://hp5:8020/user/hudi/hudi_merge_source. Falling back to direct markers.
Time taken: 25.452 seconds
spark-sql> create table hudi_merge_source2 (id int, name string, price double, ts bigint) using hudi
> tblproperties (primaryKey = 'id', preCombineField = 'ts')
> location '/user/hudi/hudi_merge_source2';
Time taken: 0.541 seconds
spark-sql> insert into hudi_merge_source2 values (2, "new_a2", 22.22, 900), (3, "new_a3", 33.33, 2000), (4, "new_a4", 44.44, 2000);
00:58 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://hp5:8020/user/hudi/hudi_merge_source2. Falling back to direct markers.
01:02 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://hp5:8020/user/hudi/hudi_merge_source2. Falling back to direct markers.
Time taken: 11.574 seconds
spark-sql> merge into hudi_merge_source as target
> using (
> select * from hudi_merge_source2
> ) source
> on target.id = source.id
> when matched then
> update set name = source.name, price = source.price, ts = source.ts
> when not matched then
> insert (id, name, price, ts) values(source.id, source.name, source.price, source.ts);
01:18 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://hp5:8020/user/hudi/hudi_merge_source. Falling back to direct markers.
01:21 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://hp5:8020/user/hudi/hudi_merge_source. Falling back to direct markers.
Time taken: 14.218 seconds
spark-sql>
spark-sql>
> select * from hudi_merge_source2 ;
20221125113448990 20221125113448990_0_0 id:3 e3dec8f3-1c73-42dd-b1fa-b8d0c01748f5-0_0-64-2460_20221125113448990.parquet 3new_a3 33.33 2000
20221125113448990 20221125113448990_0_1 id:2 e3dec8f3-1c73-42dd-b1fa-b8d0c01748f5-0_0-64-2460_20221125113448990.parquet 2new_a2 22.22 900
20221125113448990 20221125113448990_0_2 id:4 e3dec8f3-1c73-42dd-b1fa-b8d0c01748f5-0_0-64-2460_20221125113448990.parquet 4new_a4 44.44 2000
Time taken: 0.781 seconds, Fetched 3 row(s)
spark-sql> select * from hudi_merge_source;
20221125113508944 20221125113508944_0_0 id:3 8ac8139e-0e9c-41f3-8046-24bf1b99aa9d-0_0-111-3707_20221125113508944.parquet 3new_a3 33.33 2000
20221125113412110 20221125113412110_0_1 id:1 8ac8139e-0e9c-41f3-8046-24bf1b99aa9d-0_0-111-3707_20221125113508944.parquet 1old_a1 22.22 900
20221125113412110 20221125113412110_0_2 id:2 8ac8139e-0e9c-41f3-8046-24bf1b99aa9d-0_0-111-3707_20221125113508944.parquet 2old_a2 33.33 2000
20221125113508944 20221125113508944_0_3 id:4 8ac8139e-0e9c-41f3-8046-24bf1b99aa9d-0_0-111-3707_20221125113508944.parquet 4new_a4 44.44 2000
Time taken: 1.231 seconds, Fetched 4 row(s)
spark-sql>
六. 删除数据
Apache Hudi支持两种类型的删除:
(1)软删除:保留记录键,只清除所有其他字段的值(软删除中为空的记录始终保存在存储中,而不会删除);
(2)硬删除:从表中物理删除记录的任何痕迹。详细信息请参见写入数据页面的删除部分。
Spark SQL目前只支持硬删除
语法:
DELETE FROM tableIdentifier [ WHERE BOOL_EXPRESSION]
代码:
delete from hudi_merge_source where id = 1;
七. Insert Overwrite
代码:
-- insert overwrite non-partitioned table
insert overwrite hudi_mor_tbl select 99, 'a99', 20.0, 900;
insert overwrite hudi_cow_nonpcf_tbl select 99, 'a99', 20.0;
-- insert overwrite partitioned table with dynamic partition
insert overwrite table hudi_cow_pt_tbl select 10, 'a10', 1100, '2021-12-09', '10';
-- insert overwrite partitioned table with static partition
insert overwrite hudi_cow_pt_tbl partition(dt = '2021-12-09', hh='12') select 13, 'a13', 1100;
参考:
- https://hudi.apache.org/docs/quick-start-guide/