2.1 Hadoop环境搭建
第一关 配置JavaJDK
- 下载JDK
下载网址:http://www.o\fracle.com/technetwork/java/javase/downloads/jdk8-download-2133151.html
educoder中已经下载好,所以这一步忽略。
- 解压
1.创建文件夹/app
mkdir /app
2.切换到/opt目录,查看压缩包
cd /opt
ll
3.解压JDK
tar -zxvf jdk-8u171-linux-x64.tar.gz
4.等待解压完成,将JDK移动到/app目录下
mv jdk1.8.0_171/ /app
可以切换到/app目录下查看解压好的文件夹
cd /app
ll
- 配置环境变量
1.输入下面的命令,编辑配置文件
vim /etc/profile
2.在文件末尾输入:
#先按i进入编辑状态,再输入下面的代码
JAVA_HOME=/app/jdk1.8.0_171
CLASSPATH=.:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATHexport JAVA_HOME CLASSPATH PATH
3.保存并退出
#先按Esc退出编辑状态,再输入下面的代码
:wq
4.输入下面的代码使刚才配置的文件生效
source /etc/profile
- 测试
测试一下环境变量是否配置成功
java -version
出现如下界面代表配置成功

第二关 Hadoop安装与伪分布式集群搭建
- 下载Hadoop
在官网下载http://hadoop.apache.org/
educoder已经下载好,切换到目录/opt目录查看:
cd /opt
ll
解压文件:
tar -zxvf hadoop-3.1.0.tar.gz -C /app
切换到/app目录:
cd /app
修改hadoop文件夹的名字
mv hadoop-3.1.0/ hadoop3.1
- 配置Hadoop环境
1.设置SSH免密登录
首先输入下面的代码:
ssh-keygen -t rsa -P ''
!!!接下来直接输入回车(生成密钥对:id_rsa和id_rsa.pub,默认存储在/home/hadoop/.ssh目录下)
把id_rsa.pub追加到授权的key里面去:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
然后修改权限:
chmod 600 ~/.ssh/authorized_keys
启用RSA认证(如果提示权限不足在下面的语句前加上sudo):
vim /etc/ssh/sshd_config
修改SSH配置:
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile %h/.ssh/authorized_keys # 公钥文件路径
!!!先按esc,再输入:
:wq
退出并保存。
重启SSH(在自己的虚拟机中可以重启,在educoder中不用重启,重启就断开连接了)
service ssh restart
2.Hadoop配置文件
首先切换到Hadoop目录下:
cd /app/hadoop3.1/etc/hadoop
hadoop-env.sh配置:
首先进入文件:
vim hadoop-env.sh
按i,光标滑到最底下,插入代码:
export JAVA_HOME=/app/jdk1.8.0_171
按esc,输入:wq
yarn-env.sh文件配置
首先进入文件:
vim yarn-env.sh
按i,光标滑到最底下,插入代码:
export JAVA_HOME=/app/jdk1.8.0_171
按esc,输入:wq
core-site.xml文件配置:
首先进入文件:
vim core-site.xml
按i,找到两个
fs.default.name
hdfs://localhost:9000
HDFS的URI,文件系统://namenode标识:端口号
hadoop.tmp.dir
/usr/hadoop/tmp
namenode上本地的hadoop临时文件夹
按esc,输入:wq
hdfs-site.xml文件配置
首先进入文件:
vim hdfs-site.xml
按i,找到两个
dfs.name.dir
/usr/hadoop/hdfs/name
namenode上存储hdfs名字空间元数据
dfs.data.dir
/usr/hadoop/hdfs/data
datanode上数据块的物理存储位置
dfs.replication
1
按esc,输入:wq
mapred-site.xml文件配置
首先进入文件:
vim mapred-site.xml
按i,找到两个
mapreduce.framework.name
yarn
按esc,输入:wq
yarn-site.xml文件配置
首先进入文件:
vim yarn-site.xml
按i,找到两个
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.webapp.address
192.168.2.10:8099
这个地址是mr管理界面的
按esc,输入:wq
3.创建文件夹
在/usr/hadoop/目录下建立tmp、hdfs/name、hdfs/data目录:
mkdir /usr/hadoop
mkdir /usr/hadoop/tmp
mkdir /usr/hadoop/hdfs
mkdir /usr/hadoop/hdfs/data
mkdir /usr/hadoop/hdfs/name
4.将Hadoop添加到环境变量中:
vim /etc/profile
在文件末尾插入下面的代码:
#set Hadoop Environment
export HADOOP_HOME=/app/hadoop3.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
最后使修改生效:
source /etc/profile
- 验证
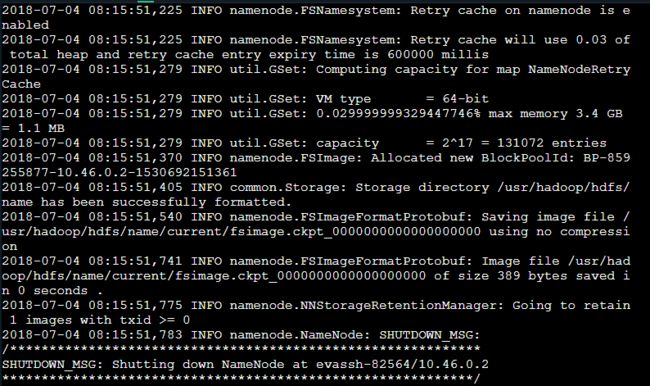
1.格式化
hadoop namenode -format
出现如下界面代表成功:
2. 启动Hadoop
用户现在还不能启动Hadoop,需要设置一些东西
切换到/hadoop3.1/sbin路径下:
cd /app/hadoop3.1/sbin
编辑start-dfs.sh文件:
vim
start-dfs.sh
按i,在文件顶部添加以下参数:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
按Esc,输入:wq,保存并退出。
编辑stop-dfs.sh文件:
vim
stop-dfs.sh
按i,在文件顶部添加以下参数:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
按Esc,输入:wq,保存并退出。
编辑start-yarn.sh文件:
vim
start-yarn.sh
按i,在文件顶部添加以下参数:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
按Esc,输入:wq,保存并退出。
编辑stop-yarn.sh文件:
vim
stop-yarn.sh
按i,在文件顶部添加以下参数:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
按Esc,输入:wq,保存并退出。
启动start-dfs.sh:
start-dfs.sh
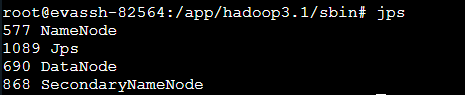
输入jps:
jps
出现以下界面表示启动成功:
第三关 HDFS系统初体验
- 编程要求
在HDFS系统的根目录下创建task文件夹,在本地创建一个名为task.txt的文件,输入:hello educoder至该文件中,最后将该文件上传至HDFS系统的/task目录。
tips:在本地操作正常输入命令即可,在HDFS系统中操作就在命令前加上hadoop fs -
- 开始编程
1.启动Hadoop:
start-dfs.sh
2.在Hadoop系统中创建/task文件夹:
hadoop fs -mkdir /task
3.查看Hadoop系统中文件:
hadoop fs -ls /
4.在本地创建task.txt文件:
touch task.txt
5.编辑task.txt文件:
vim task.txt
6.按i开始编辑,输入下面的句子:
hello educoder
按Esc,输入:wq保存并退出文件
7.将task.txt上传至HDFS的/task文件夹。
hadoop fs -put task.txt /task
8.查看HDFS /task文件夹中的task.txt文件
hadoop fs -cat /task/task.txt
显示hello educoder 表示成功。