8.Hadoop的HA(高可用)模式集群搭建
本案例软件包:链接:https://pan.baidu.com/s/1ighxbTNAWqobGpsX0qkD8w
提取码:lkjh(若链接失效在下面评论,我会及时更新)
搭建环境:hadoop-3.1.3,jdk1.8.0_162
一、HA模式简介
Hadoop的HA模式是在Hadoop全分布式基础上,利用ZooKeeper等协调工具配置的高可用Hadoop集群。
如果还没有配置全分布式的Hadoop和ZooKeeper可以去这三篇博客查看如何配置
Linux虚拟机的JDK和Hadoop安装
Hadoop的完全分布式搭建
ZooKeeper的完全分布式

二、HDFS的HA模式
由于HDFS的HA模式搭建步骤较多,建议在搭建之前先对虚拟机master,slave01,slvae02拍摄快照,这样如果出现错误可以快速恢复。
1、修改master的/usr/local/hadoop/etc/hadoop/core-site.xml文件
cd /usr/local/hadoop/etc/hadoop/
sudo vim core-site.xml
将其中中的内容替换为如下内容
fs.defaultFS
hdfs://ggb
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
io.file.buffer.size
4096
ha.zookeeper.quorum
master:2181,slave01:2181,slave02:2181
2、修改master的hdfs-site.xml文件
sudo vim hdfs-site.xml
将其中中的内容替换为如下内容
dfs.replication
3
dfs.blocksize
134217728
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
dfs.webhdfs.enabled
true
dfs.permissions.enabled
false
dfs.nameservices
ggb
dfs.ha.namenodes.ggb
nn1,nn2
dfs.namenode.rpc-address.ggb.nn1
master:8020
dfs.namenode.rpc-address.ggb.nn2
slave01:8020
dfs.namenode.http-address.ggb.nn1
master:50070
dfs.namenode.http-address.ggb.nn2
slave01:50070
dfs.namenode.shared.edits.dir
qjournal://master:8485;slave01:8485;slave02:8485/ggb
dfs.client.failover.proxy.provider.ggb
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.automatic-failover.enabled
true
dfs.ha.fencing.methods
shell(/bin/true)
3、将master的Hadoop目录分发到虚拟机slave01,slave02
sudo scp -r /usr/local/hadoop slave01:/usr/local
sudo scp -r /usr/local/hadoop slave02:/usr/local
在三台虚拟机分别给予权限
cd /usr/local
sudo chown -R hadoop:hadoop ./hadoop
4、在虚拟机slave01上新建ssh公私密钥对
不了解可以先查看一下这篇博客里面详细写了ssh的免密登录Linux虚拟机下的Hadoop集群搭建之Xshell及Xftp的使用和SSH服务配置
ssh-keygen -t rsa
ssh-copy-id hadoop@master
ssh-copy-id hadoop@slave01
ssh-copy-id hadoop@slave02
5、将master的HDFS元数据的存储目录分发到slave01
由于在配置文件中我将HDFS的元数据存储目录放置在了Hadoop的安装路径下,所以这步省略,大家根据自身情况上传。
6、启动HDFS的HA模式
(1)首先启动ZooKeeper集群
xzk-start.sh
这是我自己写的脚本命令具体可以看ZooKeeper的全分布式安装和常见问题这篇文章的最后部分,正常的启动命令为分别在三台虚拟机执行
zkServer.sh start
(2)分别在三台虚拟机上启动JournalNode进程
hadoop-daemon.sh start journalnode
(3)对NameNode进行格式化
一定要先启动JournaNode进程,否则会出错。
首先删除Hadoop下的临时文件,防止NameNode后续启动不起来
cd /usr/local
sudo rm -rf ./hadoop/tmp
sudo rm -rf ./hadoop/logs/*
在这里要注意,先格式化一个namenode,再用另一台namenode同步先前那台namenode。
在master虚拟机执行如下命令
hdfs namenode -format
格式化之后启动namenode
hadoop-daemon.sh start namenode
在第二个namenode节点虚拟机即slave01执行如下命令
同步第一台namenode
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
这时登录HDFS的web界面可以查看到都处于standby,手动切换nn1为强制激活。
hdfs haadmin -transitionToActive nn1
hdfs haadmin -transitionToActive --forcemanual nn1 //这里需要选择y
查看nn1,nn2状态
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
(4)在master上格式化ZooKeeper
hdfs zkfc -formatZK
(5)在master上初始化共享编辑日志
hdfs namenode -initializeShareEdits
(6)在master启动HDFS进程
hadoop.sh start
这里由于我的虚拟机之前进程无法使用命令同时全部启动,需要单个进程命令启动,所以编写一个一键启动脚本,具体看Hadoop一键启动脚本编写
正常启动命令
start-dfs.sh
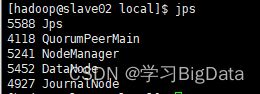
如果出现以下进程,即为配置成功(由于我这里将yarn也启动了,对照的时候可以也将yarn启动,或者忽略yarn进程)


(7)测试
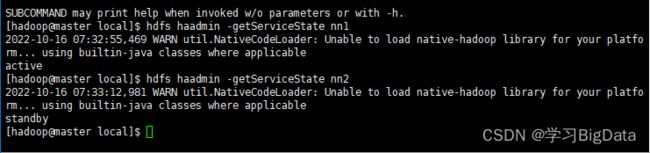
使用命令查看nn1,nn2状态
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
当前nn1处于活跃状态,nn2处于备用状态
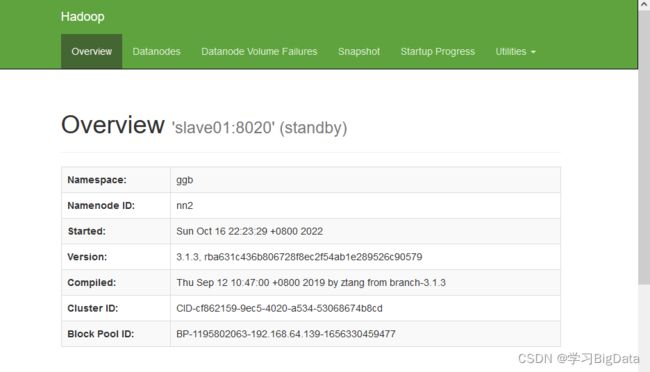
也可以通过NameNode Web界面查看nn1,nn2状态。
通过输入http://192.168.64.133:50070
http://192.168.64.133:50070可查看nn2处于备用,nn1处于活跃。
如果在虚拟机外无法访问该网站,在虚拟机内置浏览器可以的话,可能没有关闭防火墙和修改hosts文件,关闭防火墙命令如下
sudo service iptables stop
sudo chkconfig iptables off
hosts文件在windows10的路径:C:\Windows\System32\drivers\etc
在最下面添加映射例如

添加之后保存退出即可

(8)验证
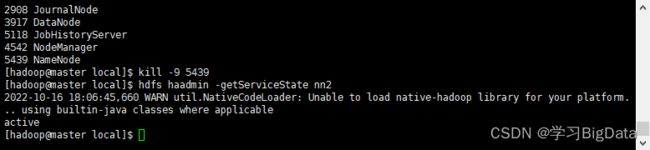
使用jps命令在master查看NameNode的进程ID


使用kill命令强制关闭NameNode进程,使nn1出现故障
kill -9 5439
在master上查看nn2的状态,nn2已切换为活跃状态
再次启动nn1,查看状态

使用kill命令强制关闭NameNode进程,使nn2出现故障
查看nn1状态,nn1已切换到活跃状态(可能会等待几秒钟)
 再次启动nn2,查看状态
再次启动nn2,查看状态
 NameNode的HA模式配置成功!!!!
NameNode的HA模式配置成功!!!!
三、yarn的HA模式
首先确保Hadoop集群和ZooKeeper集群处于关闭状态
1、修改虚拟机master的yarn-site.xml文件
cd /usr/local/hadoop/etc/hadoop/
sudo vim yarn-site.xml
将内容修改为
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
ggb
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
master
yarn.resourcemanager.hostname.rm2
slave01
yarn.resourcemanager.webapp.address.rm1
master:8088
yarn.resourcemanager.webapp.address.rm2
slave01:8088
yarn.resourcemanager.zk-address
master:2181,slave01:2181,slave02:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.log-aggregation-enable
true
yarn.log.server.url
http://master:19888/jobhistory/logs/
yarn.log-aggregation.retain-seconds
86400
2、将master的yarn文件分发到虚拟机slave01,slave02
sudo scp -r yarn-site.xml slave01:/usr/local/hadoop/etc/hadoop
sudo scp -r yarn-site.xml slave02:/usr/local/hadoop/etc/hadoop
3、查看进程
先启动ZooKeeper,再启动YARN进程
xzk-start.sh //我自己写的脚本命令
start-yarn.sh

出现如下进程,即master,slave01均有resourcemanager进程
查看rm1,rm2状态
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2

当前rm1为活跃,rm2为备用
访问web页面

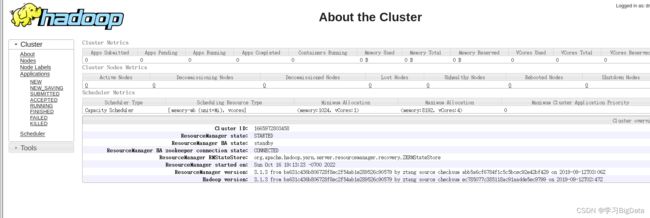
4、验证自动故障转移
首先使用jps查看master虚拟机中resourcemanager的进程ID
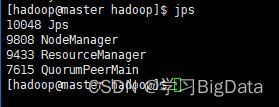
使用kill命令强制关闭进程
kill -9 9433
查看rm2的状态

在几秒钟后rm2由备用转为活跃状态
重新启动rm1,kill掉rm2尝试
在slave01节点执行jps查询进程ID,使用kill命令强制关闭进程,与上面步骤一样,等待几秒查看rm1,rm2状态

自此!!!YARN的HA模式配置成功!!!
四、启动和关闭Hadoop的HA模式的注意事项
1、启动
启动Hadoop集群的HA模式,需要在master虚拟机上,先启动ZooKeeper集群,后启动Hadoop集群
如下
xzk-start.sh
hadoop.sh start
以上为我自己写的脚本,正常启动为
分别在三台机器执行
zkServer.sh start
然后在主节点master执行
start-dfs.sh
start-yarn.sh
执行结果如下

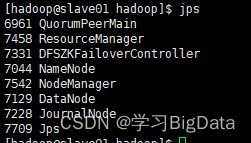

各进程与最开始我们对集群的规划相匹配

2、关闭
为确保稳定,在关闭时我们要倒着关闭集群,也就是说先关闭Hadoop的HA模式,再关闭ZooKeeper集群
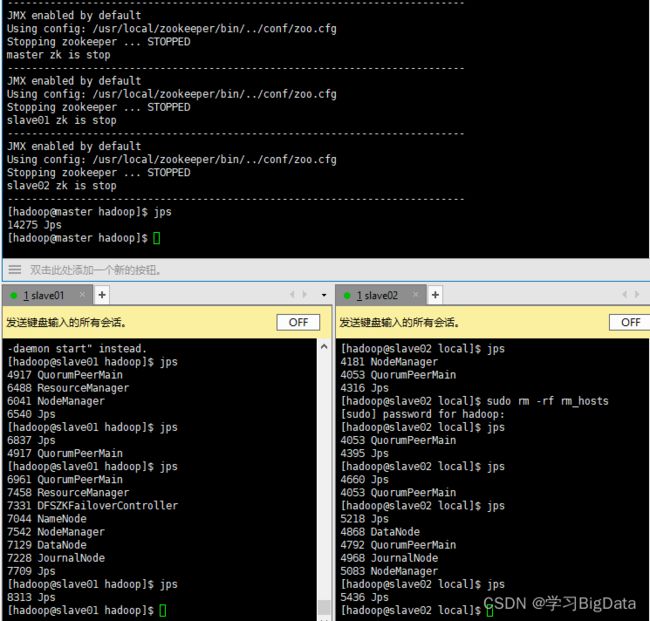 自此,Hadoop的HA模式全部配置成功!!!
自此,Hadoop的HA模式全部配置成功!!!