HADOOP HA之NameNode HA集群配置与应用
目录
前言
一、HADOOP HA之NameNode HA集群配置
1、修改hadoop-env.sh
2、修改core-site.xml
3、修改hdfs-site.xml
4、修改workers
5、同步配置文件
6、启动zookeeper集群
7、启动journalnode
8、格式化namenode
9、同步元数据
10、格式化ZKFC
11、启动HDFS
二、HADOOP HA之NameNode HA集群应用
1、查看两个NameNode的运行状态
(1)命令行 (nn2是 NameNode的名字,可以换成nn1)
(2)Hadoop的Web UI界面
2、关闭集群中的原Active NameNode,查看原Standby NameNode的运行状态
3、重新启动原Active NameNode,依次查看原Active NameNode和原Standby NameNode的运行状态
问题
1、Active NameNode关闭后Standby NameNode没有自动切换成Active NameNode
2、两个NameNode的运行状态都是Standby
3、Standby NameNode启动不了
参考
前言
本文只讲解HADOOP HA的NameNode HA集群配置与应用,Yarn HA不作讲解。
集群基础环境准备:
1、已经搭建好Hadoop和zookeeper集群
2、在本地主机的 /etc/hosts文件修改集群各个主机名和IP的映射关系(访问Hadoop的Web UI界面时需要)
3、配置好ssh免登陆
一、HADOOP HA之NameNode HA集群配置
找到你配置hadoop的目录,想不起来可以用which hadoop命令行查看,在bin的同级目录etc下找到hadoop配置文件所在目录,进行修改配置文件。
1、修改hadoop-env.sh
vi hadoop-env.shexport JAVA_HOME=/opt/module/jdk-8u162-linux-x64/jdk1.8.0_162
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/module
export PATH=$HADOOP_HOME/bin:$PATH
export PATH=$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root把jdk和hadoop的配置路径换成你自己的,可以用which java和which hadoop命令行查看。
2、修改core-site.xml
vi core-site.xml
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
file:/home/hadoop/tmp
io.file.buffer.size
131702
ha.zookeeper.quorum
hadoop1:2181,hadoop2:2181,hadoop3:2181
我Hadoop集群的主机名是hadoop1、hadoop2、hadoop3(记得完成主机名和ip地址映射,不然会出问题),换成你自己集群的主机名。
3、修改hdfs-site.xml
vi hdfs-site.xml
dfs.namenode.name.dir
file:/home/hadoop/hdfs_name
dfs.datanode.data.dir
file:/home/hadoop/hdfs_data
dfs.replication
2
dfs.webhdfs.enabled
true
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
hadoop1:8020
dfs.namenode.http-address.mycluster.nn1
hadoop1:9870
dfs.namenode.rpc-address.mycluster.nn2
hadoop2:8020
dfs.namenode.http-address.mycluster.nn2
hadoop2:9870
dfs.namenode.shared.edits.dir
qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/mycluster
dfs.journalnode.edits.dir
/home/hadoop/data/journaldata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
集群的主机名和存放数据的目录换成你自己的。
4、修改workers
vi workershadoop1
hadoop2
hadoop3换成你自己集群的主机名。
5、同步配置文件
返回上一层目录,把hadoop目录下的配置文件同步给集群中的其他主机,-r后加目录路径,@后加主机名,如果新建了存放数据的目录也要同步给集群中的其他主机。
cd ..
scp -r hadoop root@hadoop2:$PWD6、启动zookeeper集群
在集群中的每台主机上启动zookeeper,在zookeeper安装目录下输入:
bin/zkServer.sh start查看状态:一般是一个leader,两个follower
bin/zkServer.sh status7、启动journalnode
在集群中的每台主机上启动journalnode,用jps命令行查看进程,可以看到JournalNode进程
hdfs --daemon start journalnode
jps8、格式化namenode
格式化和启动namenode,在hadoop1上执行命令:
hdfs namenode -format
hdfs --daemon start namenode9、同步元数据
在hadoop2上执行命令:
hdfs namenode -bootstrapStandby10、格式化ZKFC
在哪台主机上执行,哪台主机就将成为第一次的Active Namenode
hdfs zkfc -formatZK11、启动HDFS
在hadoop1上执行命令:
start-dfs.sh二、HADOOP HA之NameNode HA集群应用
1、查看两个NameNode的运行状态
有两种方式可以查看:
(1)命令行 (nn2是 NameNode的名字,可以换成nn1)
hdfs haadmin -getServiceState nn2(2)Hadoop的Web UI界面
在浏览器网址栏输入:http://hadoop1:9870/ 和 http://hadoop2:9870/
我是用docker在虚拟机里搭建hadoop集群的,所以用虚拟机主机里的浏览器查看,如果是开了三台虚拟机搭建hadoop集群的话,在电脑本地的浏览器查看即可。如果用主机名+端口访问不了,应该是主机号和ip地址映射没做好,可以直接用ip地址+端口号访问;如果还是访问不了那就是配置文件没改好,或者是防火墙没关闭等等。
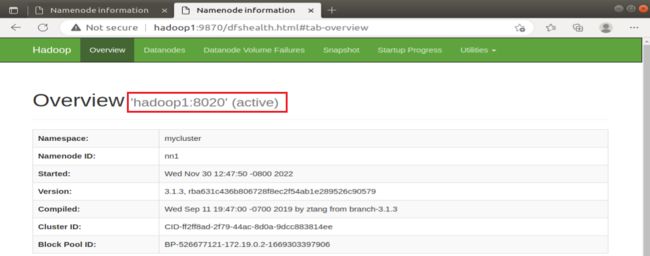

2、关闭集群中的原Active NameNode,查看原Standby NameNode的运行状态
hadoop1的NameNode原来是Active NameNode,hadoop2的NameNode原来是Standby NameNode,所以在hadoop1中关闭NameNode,输入:
hdfs --daemon stop namenode也可以用jps查看进程号,kill -9 进程号,结束NameNode进程。刷新网页后,发现hadoop1的NameNode访问不了,hadoop2的NameNode变成了Active NameNode。
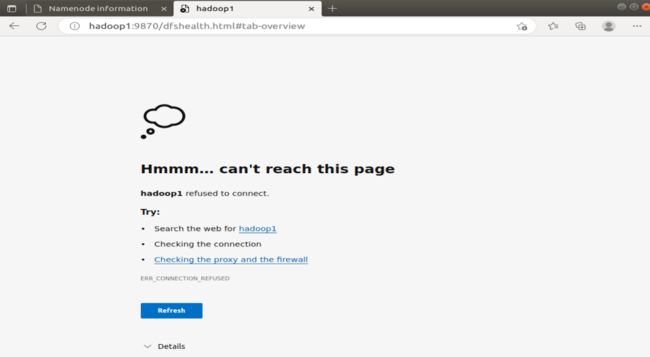
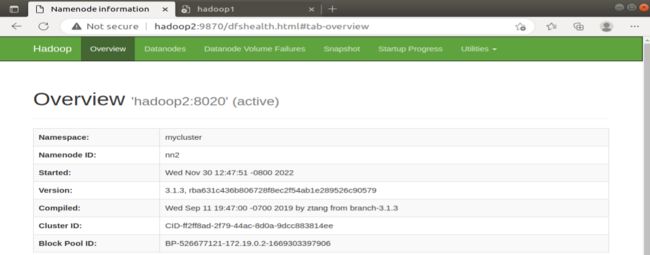
3、重新启动原Active NameNode,依次查看原Active NameNode和原Standby NameNode的运行状态
在hadoop1中输入:
hdfs --daemon start namenode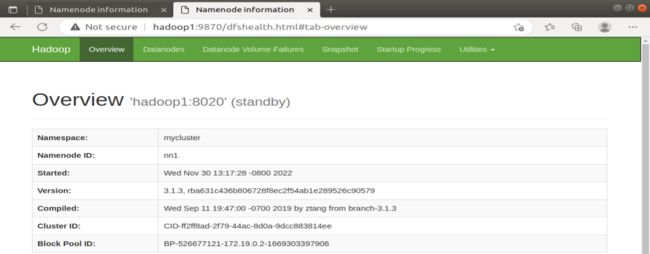
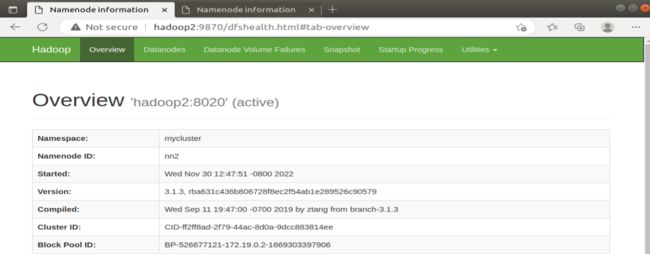
刷新网页后,hadoop1的NameNode可以访问且变成了Standby NameNode,hadoop2的NameNode是Active NameNode。
问题
1、Active NameNode关闭后Standby NameNode没有自动切换成Active NameNode
解决方法:CentOS可能没有自带fuster 程序,但是在hdfs-site.xml中用到了fuster 程序,所以得自己安装(每台主机上都要安装),安装完如果还是不行,可以重启所有虚拟机再试试。
yum -y install psmisc2、两个NameNode的运行状态都是Standby
解决方法:强制选定一个NameNode为Active NameNode,nn1是名称节点的名字,换成你选定的
NameNode的名字
hdfs haadmin -transitionToActive --forcemanual nn13、Standby NameNode启动不了
解决方法:从Active NameNode拉取FSimage和元数据,再启动Standby NameNode
hdfs namenode -bootstrapStandby参考
黑马程序员:HADOOP HA集群搭建