02-Redis持久化、主从与哨兵架构详解
一、Redis持久化
1.1 RDB快照(snapshot)
在默认情况下, Redis 将内存数据库快照保存在名字为 dump.rdb 的二进制文件中。 你可以对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时, 自动保存一次数据集。
/opt/redis-5.0.3/redis.conf
# Save the DB on disk:
# //多少 秒内有多少个键被改动”这一条件时, 自动保存一次
# save
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
save 900 1
save 300 10
save 60 10000
文件名称和文件的位置
# The filename where to dump the DB
dbfilename dump.rdb
# The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
dir /opt/redis-5.0.3/data
查看
[root@k8s-master01 data]# pwd
/opt/redis-5.0.3/data
[root@k8s-master01 data]# ll
total 8
-rw-r--r-- 1 root root 81 Nov 21 11:31 appendonly.aof
-rw-r--r-- 1 root root 111 Nov 21 11:31 dump.rdb
[root@k8s-master01 data]# cat dump.rdb
REDIS0009 redis-ver5.0.3
redis-bitse£½used-memh
preamble~ᩱv1k2v2ÿU®[root@k8s-master01 data]# XshellXshell
还可以手动执行命令生成RDB快照,进入redis客户端执行命令save或bgsave可以生成dump.rdb文件, 每次命令执行都会将所有redis内存快照到一个新的rdb文件里,并覆盖原有rdb快照文件。
bgsave的写时复制(COW)机制
Redis 借助操作系统提供的写时复制技术(Copy-On-Write, COW),在生成快照的同时,依然可以正常 处理写命令。简单来说,bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。 bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。此时,如果主线程对这些 数据也都是读操作,那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据,那 么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文 件,而在这个过程中,主线程仍然可以直接修改原来的数据。
save与bgsave对比:
| 命令 | save | bgsave |
|---|---|---|
| IO类型 | 同步 | 异步 |
| 是否阻塞redis其它命令 | 是 | 否 |
| 复杂度 | O(n) | O(n) |
| 优点 | 不会消耗额外内存 | 不阻塞客户端命令 |
| 缺点 | 阻塞客户端命令 | 需要fork子进程,消耗内存 |
配置自动生成rdb文件后台使用的是bgsave方式。
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> save
OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> bgsave
Background saving started
127.0.0.1:6379>
1.2 AOF(append-only file)
快照功能并不是非常耐久(durable): 如果 Redis 因为某些原因而造成故障停机, 那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。从 1.1 版本开始, Redis 增加了一种完全耐久的持久化方 式: AOF 持久化,将修改的每一条指令记录进文件appendonly.aof中(先写入os cache,每隔一段时间 fsync到磁盘)
redis.conf
开启aof持久化:appendonly 设置为yes
从现在开始, 每当 Redis 执行一个改变数据集的命令时(比如 SET), 这个命令就会被追加到 AOF 文 件的末尾。 这样的话, 当 Redis 重新启动时, 程序就可以通过重新执行 AOF 文件中的命令来达到重建数据集的目 的。
############################## APPEND ONLY MODE ###############################
# By default Redis asynchronously dumps the dataset on disk. This mode is
# good enough in many applications, but an issue with the Redis process or
# a power outage may result into a few minutes of writes lost (depending on
# the configured save points).
#
# The Append Only File is an alternative persistence mode that provides
# much better durability. For instance using the default data fsync policy
# (see later in the config file) Redis can lose just one second of writes in a
# dramatic event like a server power outage, or a single write if something
# wrong with the Redis process itself happens, but the operating system is
# still running correctly.
#
# AOF and RDB persistence can be enabled at the same time without problems.
# If the AOF is enabled on startup Redis will load the AOF, that is the file
# with the better durability guarantees.
#
# Please check http://redis.io/topics/persistence for more information.
appendonly yes
# The name of the append only file (default: "appendonly.aof")
appendfilename "appendonly.aof"
文件的存储位置和rdb在同一个目录中
[root@k8s-master01 data]# pwd
/opt/redis-5.0.3/data
[root@k8s-master01 data]# ll
total 8
-rw-r--r-- 1 root root 81 Nov 21 11:31 appendonly.aof
-rw-r--r-- 1 root root 111 Nov 21 11:31 dump.rdb
[root@k8s-master01 data]# cat appendonly.aof
*2
$6
SELECT
$1
0
*3
$3
set
$2
k1
$2
v1
*3
$3
set
$2
k2
$2
v2
[root@k8s-master01 data]#
这是一种resp协议格式数据,星号后面的数字代表命令有多少个参数,$号后面的数字代表这个参数有几个字符
注意,如果执行带过期时间的set命令,aof文件里记录的是并不是执行的原始命令,而是记录key过期的时间戳
127.0.0.1:6379> set k3 v3 ex 100
OK
appendonly.aof文件内容
[root@k8s-master01 data]# cat appendonly.aof
*2
$6
SELECT
$1
0
*3
$3
set
$2
k1
$2
v1
*3
$3
set
$2
k2
$2
v2
*3
$3
set
$2
k3
$2
v3
*3
$9
PEXPIREAT
$2
k3
$13
1637465914723
你可以配置 Redis 多久才将数据 fsync 到磁盘一次。
appendfsync always:每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。
appendfsync everysec:每秒 fsync 一次,足够快,并且在故障时只会丢失 1 秒钟的数据。
appendfsync no:从不fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性。会丢失1s中的数据
AOF重写
AOF文件里可能有太多没用指令,所以AOF会定期根据内存的最新数据生成aof文件
如下两个配置可以控制AOF自动重写频率
#aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就 很快,重写的意义不大
# auto‐aof‐rewrite‐min‐size 64mb
#aof文件自上一次重写后文件大小增长了100%则再次触发重写,比如上次重写之后40mb,下次80mb重写
# auto‐aof‐rewrite‐percentage 100
当然AOF还可以手动重写,进入redis客户端执行命令bgrewriteaof重写AOF
注意,AOF重写redis会fork出一个子进程去做(与bgsave命令类似),不会对redis正常命令处理有太多影响
执行多个命令后进行重写:
127.0.0.1:6379> incr visitcount
(integer) 1
127.0.0.1:6379> incr visitcount
(integer) 2
127.0.0.1:6379> incr visitcount
(integer) 3
127.0.0.1:6379> incr visitcount
(integer) 4
127.0.0.1:6379> incr visitcount
(integer) 5
127.0.0.1:6379> incr visitcount
(integer) 6
127.0.0.1:6379> incr visitcount
(integer) 7
查看文件内容:
[root@k8s-master01 data]# ll
total 8
-rw-r--r-- 1 root root 240 Nov 21 12:24 appendonly.aof
-rw-r--r-- 1 root root 111 Nov 21 12:23 dump.rdb
[root@k8s-master01 data]# cat appendonly.aof
*2
$6
SELECT
$1
0
*2
$4
incr
$10
visitcount
*2
$4
incr
$10
visitcount
*2
$4
incr
$10
visitcount
*2
$4
incr
$10
visitcount
*2
$4
incr
$10
visitcount
*2
$4
incr
$10
visitcount
*2
$4
incr
$10
visitcount
进行手动重写:拿最新的数据直接存储即可,之前对key的操作可以直接清理
设置不开启混合持久化:
127.0.0.1:6379> config get aof-use-rdb-preamble
1) "aof-use-rdb-preamble"
2) "yes"
127.0.0.1:6379> config set aof-use-rdb-preamble no
OK
127.0.0.1:6379> config get aof-use-rdb-preamble
1) "aof-use-rdb-preamble"
2) "no"
127.0.0.1:6379> bgrewriteaof
Background append only file rewriting started
重写之后再次查看文件内容
[root@k8s-master01 data]# ll
total 8
-rw-r--r-- 1 root root 60 Nov 21 12:27 appendonly.aof
-rw-r--r-- 1 root root 111 Nov 21 12:23 dump.rdb
[root@k8s-master01 data]# cat appendonly.aof
*2
$6
SELECT
$1
0
*3
$3
SET
$10
visitcount
$1
7
RDB 和 AOF ,我应该用哪一个?
| 命令 | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 容易丢数据 | 根据策略决定 |
生产环境可以都启用,redis启动时如果既有rdb文件又有aof文件则优先选择aof文件恢复数据,因为aof 一般来说数据更全一点
1.3 Redis 4.0 混合持久化
重启 Redis 时,我们很少使用 RDB来恢复内存状态,因为会丢失大量数据。我们通常使用 AOF 日志重 放,但是重放 AOF 日志性能相对 RDB来说要慢很多,这样在 Redis 实例很大的情况下,启动需要花费很 长的时间。 Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化。
通过如下配置可以开启混合持久化(必须先开启aof):
aof‐use‐rdb‐preamble yes
如果开启了混合持久化,AOF在重写时,不再是单纯将内存数据转换为RESP命令写入AOF文件,而是将重写这一刻之前的内存做RDB快照处理,并且将RDB快照内容和增量的AOF修改内存数据的命令存在一 起,都写入新的AOF文件,新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改 名,覆盖原有的AOF文件,完成新旧两个AOF文件的替换。 于是在 Redis 重启的时候,可以先加载 RDB 的内容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,因此重启效率大幅得到提升。
混合持久化AOF文件结构如下:
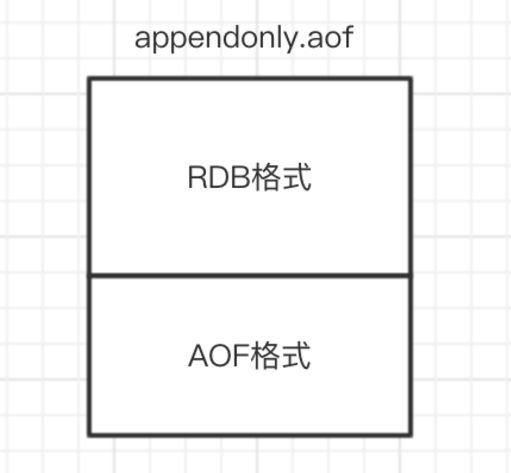
开启混合持久化之后的文件内容格式:
[root@k8s-master01 data]# cat appendonly.aof
REDIS0009 redis-ver5.0.3
redis-bitseb˙used-memÀ
preambleþ
visitcount^18+k¢½*2
$6
SELECT
$1
0
*3
$3
set
$2
k1
$2
v2
*3
$3
set
$2
k2
$2
v2
开启混合持久化之后,可以把rdb关闭,直接注释掉rdb的保存规则即可
# save 900 1
# save 300 10
# save 60 10000
数据恢复
当我们开启了混合持久化时,启动redis依然优先加载aof文件,aof文件加载可能有两种情况如下:
- aof文件开头是rdb的格式, 先加载 rdb内容再加载剩余的 aof。
- aof文件开头不是rdb的格式,直接以aof格式加载整个文件。
Redis数据备份策略
- 写crontab定时调度脚本,每小时都copy一份rdb或aof的备份到一个目录中去,仅仅保留最近48 小时的备份
2. 每天都保留一份当日的数据备份到一个目录中去,可以保留最近1个月的备份
3. 每次copy备份的时候,都把太旧的备份给删了
4. 每天晚上将当前机器上的备份复制一份到其他机器上,以防机器损坏
二、Redis主从架构
2.1 redis主从架构搭建
1、复制一份redis.conf文件
[root@k8s-master01 conf]# pwd
/opt/redis-5.0.3/conf
[root@k8s-master01 conf]# ll
total 128
-rw-r--r-- 1 root root 62181 Nov 21 15:18 redis-6379.conf
-rw-r--r-- 1 root root 62239 Nov 21 15:22 redis-6380.conf
2、将相关配置修改为如下值:
port 6380
pidfile /var/run/redis_6380.pid # 把pid进程号写入pidfile配置的文件
logfile "6380.log"
dir /opt/redis‐5.0.3/data/6380 # 指定数据存放目录
# 需要注释掉bind
# bind 127.0.0.1(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,
#代表允许客户端通 过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可)
[root@k8s-master01 data]# pwd
/opt/redis-5.0.3/data
[root@k8s-master01 data]# ll
total 8
drwxr-xr-x 2 root root 4096 Nov 21 15:22 6379
drwxr-xr-x 2 root root 4096 Nov 21 15:22 6380
3、配置主从复制
replicaof 47.96.114.225 6379 # 从本机6379的redis实例复制数据,Redis 5.0之前使用slaveof
replica-read-only yes
4、启动从节点
src/redis-server conf/redis-6380.conf
5、连接从节点
src/redis-cli -p 6380
#查看节点状态
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:47.96.114.225
master_port:6379
master_link_status:up
master_last_io_seconds_ago:5
master_sync_in_progress:0
slave_repl_offset:154
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:337b036a157fbff1b99a492b3fcae9f6215faf09
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:154
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:154
6、测试在6379实例上写数据,6380实例是否能及时同步新修改数据
## 6379
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> keys *
1) "k1"
2) "k2"
127.0.0.1:6379>
## 6380
127.0.0.1:6380> keys *
(empty list or set)
127.0.0.1:6380> keys *
1) "k2"
2) "k1"
127.0.0.1:6380>
7、再配置一个6381的从节点
8、在master上查看节点信息
127.0.0.1:6379> info Replication
# Replication
role:master
connected_slaves:2
slave0:ip=47.96.114.225,port=6380,state=online,offset=12495,lag=0
slave1:ip=47.96.114.225,port=6381,state=online,offset=12495,lag=0
master_replid:337b036a157fbff1b99a492b3fcae9f6215faf09
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:12495
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:12495
2.2 Redis主从工作原理
如果你为master配置了一个slave,不管这个slave是否是第一次连接上Master,它都会发送一个PSYNC 命令给master请求复制数据。 master收到PSYNC命令后,会在后台进行数据持久化通过bgsave生成最新的rdb快照文件,持久化期 间,master会继续接收客户端的请求,它会把这些可能修改数据集的请求缓存在内存中。当持久化进行完 毕以后,master会把这份rdb文件数据集发送给slave,slave会把接收到的数据进行持久化生成rdb,然后 再加载到内存中。然后,master再将之前缓存在内存中的命令发送给slave。 当master与slave之间的连接由于某些原因而断开时,slave能够自动重连Master,如果master收到了多 个slave并发连接请求,它只会进行一次持久化,而不是一个连接一次,然后再把这一份持久化的数据发送 给多个并发连接的slave。
主从复制(全量复制)流程图: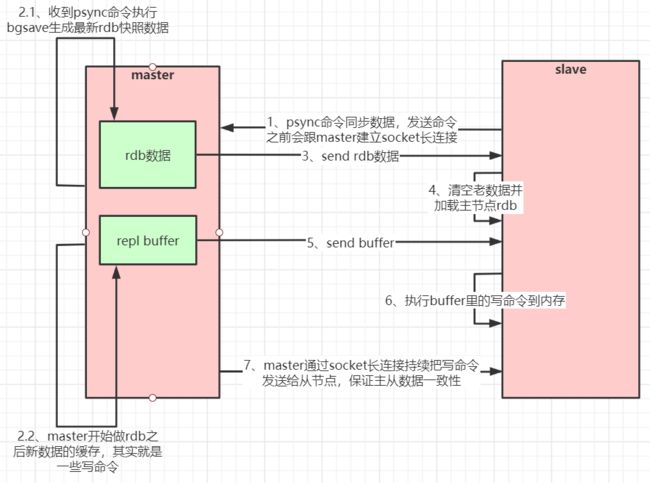
三、java客户端连接
3.1 代码示例
引入依赖
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>3.2.0version>
dependency>
代码示例:
package com.zengqingfa.test;
import org.junit.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import redis.clients.jedis.Pipeline;
import java.util.Arrays;
import java.util.List;
public class JedisTest {
@Test
public void test() {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(10);
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMinIdle(5);
// timeout,这里既是连接超时又是读写超时,从Jedis 2.8开始有区分connectionTimeout和soTimeout的构造函数
JedisPool jedisPool = new JedisPool(jedisPoolConfig, "47.96.114.225", 6379, 3000, null);
Jedis jedis = null;
try {
//从redis连接池里拿出一个连接执行命令
jedis = jedisPool.getResource();
System.out.println(jedis.set("single", "shenlongfeixian"));
System.out.println(jedis.get("single"));
//管道示例
//管道的命令执行方式:cat redis.txt | redis‐cli ‐h 127.0.0.1 ‐a password ‐ p 6379 ‐‐pipe
Pipeline pipelined = jedis.pipelined();
for (int i = 0; i < 5; i++) {
pipelined.incr("pipelineKey");
pipelined.set("shenlongfeixian" + i, "shenlongfeixian");
}
List<Object> objects = pipelined.syncAndReturnAll();
System.out.println(objects);
//lua脚本模拟一个商品减库存的原子操作
//lua脚本命令执行方式:redis‐cli ‐‐eval /tmp/test.lua , 10
jedis.set("product_count_10086", "15"); //初始化商品10016的库存
String script= " local count = redis.call('get',KEYS[1]) " +
"local a =tonumber(count) " +
"local b =tonumber(ARGV[1]) " +
" if a >= b then " +
"redis.call('set',KEYS[1],a-b) " +
" return 1 " +
" end " +
" return 0 ";
Object obj = jedis.eval(script, Arrays.asList("product_count_10086"), Arrays.asList("10"));
System.out.println(obj);
} catch (Exception e) {
e.printStackTrace();
} finally {
//注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。
if (jedis != null) {
jedis.close();
}
}
}
}
3.2 管道(Pipeline)
客户端可以一次性发送多个请求而不用等待服务器的响应,待所有命令都发送完后再一次性读取服务的响 应,这样可以极大的降低多条命令执行的网络传输开销,管道执行多条命令的网络开销实际上只相当于一 次命令执行的网络开销。需要注意到是用pipeline方式打包命令发送,redis必须在处理完所有命令前先缓 存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。所以并不是打包的命令越多越好。 pipeline中发送的每个command都会被server立即执行,如果执行失败,将会在此后的响应中得到信 息;也就是pipeline并不是表达“所有command都一起成功”的语义,管道中前面命令失败,后面命令 不会有影响,继续执行。
Pipeline pipelined = jedis.pipelined();
for (int i = 0; i < 5; i++) {
pipelined.incr("pipelineKey");
pipelined.set("shenlongfeixian" + i, "shenlongfeixian");
//模拟管道报错
pipelined.setbit("shenlongfeixian", -1L, true);
}
List<Object> objects = pipelined.syncAndReturnAll();
System.out.println(objects);
执行结果:
OK
shenlongfeixian
[1, OK, redis.clients.jedis.exceptions.JedisDataException: ERR bit offset is not an integer or out of range,
2, OK, redis.clients.jedis.exceptions.JedisDataException: ERR bit offset is not an integer or out of range,
3, OK, redis.clients.jedis.exceptions.JedisDataException: ERR bit offset is not an integer or out of range,
4, OK, redis.clients.jedis.exceptions.JedisDataException: ERR bit offset is not an integer or out of range,
5, OK, redis.clients.jedis.exceptions.JedisDataException: ERR bit offset is not an integer or out of range]
3.3 Redis Lua脚本
A Redis script is transactional by definition, so everything you can do with a Redis
t ransaction, you can also do with a script, and usually the script will be both
simpler and faster.
Redis在2.6推出了脚本功能,允许开发者使用Lua语言编写脚本传到Redis中执行。使用脚本的好处如下:
1、减少网络开销:本来5次网络请求的操作,可以用一个请求完成,原先5次请求的逻辑放在redis服务器 上完成。使用脚本,减少了网络往返时延。这点跟管道类似。
2、原子操作:Redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。管道不是原子的,不过 redis的批量操作命令(类似mset)是原子的。
3、替代redis的事务功能:redis自带的事务功能很鸡肋,而redis的lua脚本几乎实现了常规的事务功能, 官方推荐如果要使用redis的事务功能可以用redis lua替代。
从Redis2.6.0版本开始,通过内置的Lua解释器,可以使用EVAL命令对Lua脚本进行求值。EVAL命令的格 式如下:
EVAL script numkeys key [key ...] arg [arg ...]
script参数是一段Lua脚本程序,它会被运行在Redis服务器上下文中,这段脚本不必(也不应该)定义为一 个Lua函数。numkeys参数用于指定键名参数的个数。键名参数 key [key …] 从EVAL的第三个参数开始算 起,表示在脚本中所用到的那些Redis键(key),这些键名参数可以在 Lua中通过全局变量KEYS数组,用1 为基址的形式访问( KEYS[1] , KEYS[2] ,以此类推)。
在命令的最后,那些不是键名参数的附加参数 arg [arg …] ,可以在Lua中通过全局变量ARGV数组访问, 访问的形式和KEYS变量类似( ARGV[1] 、 ARGV[2] ,诸如此类)。例如
127.0.0.1:6379> eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
1) "key1"
2) "key2"
3) "first"
4) "second"
其中 “return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}” 是被求值的Lua脚本,数字2指定了键名参数的数 量, key1和key2是键名参数,分别使用 KEYS[1] 和 KEYS[2] 访问,而最后的 first 和 second 则是附加 参数,可以通过 ARGV[1] 和 ARGV[2] 访问它们。 在 Lua 脚本中,可以使用redis.call()函数来执行Redis命令
//lua脚本模拟一个商品减库存的原子操作
//lua脚本命令执行方式:redis‐cli ‐‐eval /tmp/test.lua , 10
jedis.set("product_count_10086", "15"); //初始化商品10016的库存
String script = " local count = redis.call('get',KEYS[1]) " +
"local a =tonumber(count) " +
"local b =tonumber(ARGV[1]) " +
" if a >= b then " +
"redis.call('set',KEYS[1],a-b) " +
//模拟语法报错回滚操作
" bb == 0 " +
" return 1 " +
" end " +
" return 0 ";
Object obj = jedis.eval(script, Arrays.asList("product_count_10086"), Arrays.asList("10"));
System.out.println(obj);
正常情况下查看
127.0.0.1:6379> get product_count_10086
"5"
模拟报错情况下,数值不变。
redis.clients.jedis.exceptions.JedisDataException: ERR Error compiling script (new function): user_script:1: '=' expected near '=='
at redis.clients.jedis.Protocol.processError(Protocol.java:132)
at redis.clients.jedis.Protocol.process(Protocol.java:166)
注意,不要在Lua脚本中出现死循环和耗时的运算,否则redis会阻塞,将不接受其他的命令, 所以使用 时要注意不能出现死循环、耗时的运算。redis是单进程、单线程执行脚本。管道不会阻塞redis。
四、Redis哨兵高可用架构
单纯的主从架构,如果主节点宕机,需要手动调整从节点为主节点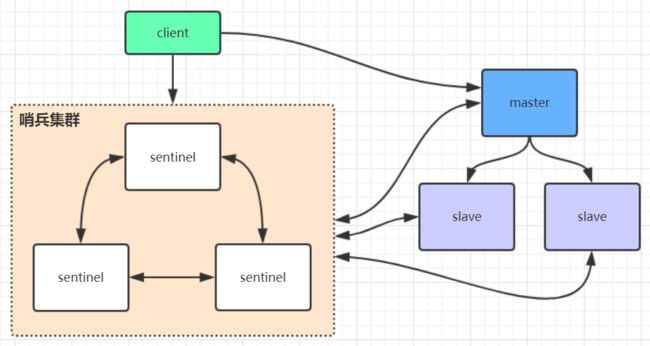
4.1 redis哨兵架构搭建
1、复制一份sentinel.conf文件
cp sentinel.conf conf/sentinel‐26379.conf
2、将相关配置修改为如下值:
port 26379
daemonize yes
pidfile /var/run/redis-sentinel-26379.pid
logfile "26379.log"
dir /opt/redis-5.0.3/data
# sentinel monitor
# quorum是一个数字,指明当有多少个sentinel认为一个master失效时(值一般为:sentinel总数/2 + 1),
# master才算真正失效
# mymaster这个名字随便取,客户端访问时会用到
sentinel monitor mymaster 47.96.114.225 6379 2
3、启动sentinel哨兵实例
src/redis-sentinel conf/sentinel-26379.conf
4、查看sentinel的info信息
src/redis-cli -p 26379
127.0.0.1:26379> info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=47.96.114.225:6379,slaves=2,sentinels=3
5、可以自己再配置两个sentinel,端口26380和26381,注意上述配置文件里的对应数字都要修改
sentinel集群都启动完毕后,会将哨兵集群的元数据信息写入所有sentinel的配置文件里去(追加在文件的 最下面),我们查看下如下配置文件sentinel-26379.conf,如下所示:
# SENTINEL rename-command mymaster CONFIG CONFIG
# Generated by CONFIG REWRITE
protected-mode no
sentinel known-replica mymaster 47.96.114.225 6381 #代表redis主节点的从节点信息
sentinel known-replica mymaster 47.96.114.225 6380 #代表redis主节点的从节点信息
sentinel known-sentinel mymaster 172.17.12.88 26380 b648825a047389eb58b57f66bf1532295c43efc6 #代表感知到的其它哨兵节点
sentinel known-sentinel mymaster 172.17.12.88 26381 368b4dc575062d556122c4bc86ef70bdcd02d7fe #代表感知到的其它哨兵节点
sentinel current-epoch 0
当redis主节点如果挂了,哨兵集群会重新选举出新的redis主节点,同时会修改所有sentinel节点配置文件 的集群元数据信息,比如6379的redis如果挂了,假设选举出的新主节点是6380,则sentinel-26379.conf文件里的集 群元数据信息会变成如下所示:
# SENTINEL rename-command mymaster CONFIG CONFIG
# Generated by CONFIG REWRITE
protected-mode no
sentinel known-replica mymaster 47.96.114.225 6381 #代表redis主节点的从节点信息
sentinel known-replica mymaster 47.96.114.225 6379 #代表redis主节点的从节点信息
sentinel known-sentinel mymaster 172.17.12.88 26380 b648825a047389eb58b57f66bf1532295c43efc6 #代表感知到的其它哨兵节点
sentinel known-sentinel mymaster 172.17.12.88 26381 368b4dc575062d556122c4bc86ef70bdcd02d7fe #代表感知到的其它哨兵节点
sentinel current-epoch 1
同时还会修改sentinel文件里之前配置的mymaster对应的6379端口,改为6380
sentinel monitor mymaster 47.96.114.225 6380 2
当6379的redis实例再次启动时,哨兵集群根据集群元数据信息就可以将6379端口的redis节点作为从节点 加入集群
4.2 哨兵的Jedis连接
引入jedis依赖
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>3.2.0version>
dependency>
package com.zengqingfa.test;
import org.junit.Test;
import redis.clients.jedis.*;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Set;
public class JedisSentinelTest {
@Test
public void test() {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(10);
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMinIdle(5);
String masterName = "mymaster";
Set<String> sentinels = new HashSet<String>();
sentinels.add(new HostAndPort("47.96.114.225", 26379).toString());
sentinels.add(new HostAndPort("47.96.114.225", 26380).toString());
sentinels.add(new HostAndPort("47.96.114.225", 26381).toString());
//JedisSentinelPool其实本质跟JedisPool类似,都是与redis主节点建立的连接池
//JedisSentinelPool并不是说与sentinel建立的连接池,而是通过sentinel发现redis主节点并与其 建立连接
JedisSentinelPool jedisSentinelPool = new JedisSentinelPool(masterName, sentinels, jedisPoolConfig, 3000, null);
Jedis jedis = null;
try {
jedis = jedisSentinelPool.getResource();
System.out.println(jedis.set("sentinel", "shenlongfeixian"));
System.out.println(jedis.get("sentinel"));
} catch (Exception e) {
e.printStackTrace();
} finally {
//注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。
if (jedis != null)
jedis.close();
}
}
}
执行结果:
17:31:18.714 [main] INFO redis.clients.jedis.JedisSentinelPool - Trying to find master from available Sentinels...
17:31:18.721 [main] DEBUG redis.clients.jedis.JedisSentinelPool - Connecting to Sentinel 47.96.114.225:26381
17:31:18.854 [main] DEBUG redis.clients.jedis.JedisSentinelPool - Found Redis master at 47.96.114.225:6380
17:31:18.855 [main] INFO redis.clients.jedis.JedisSentinelPool - Redis master running at 47.96.114.225:6380, starting Sentinel listeners...
17:31:18.926 [main] INFO redis.clients.jedis.JedisSentinelPool - Created JedisPool to master at 47.96.114.225:6380
OK
shenlongfeixian
4.3 哨兵的Spring Boot整合Redis连接
引入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
<version>2.8.1version>
dependency>
配置文件:applciation.yaml
spring:
application:
name: springboot-redis-demo
redis:
database: 0
timeout: 3000
sentinel: #哨兵模式
master: mymaster #主服务器所在集群名称
nodes: 47.96.114.225:26379,47.96.114.225:26380,47.96.114.225:26381
lettuce:
pool:
max-active: 100
max-idle: 50
max-wait: 1000
min-idle: 10
server:
port: 8087
代码:
package com.zengqingfa.springboot.redis.rest;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/redis")
@Slf4j
public class RedisController {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private RedisTemplate redisTemplate;
/**
* 测试节点挂了哨兵重新选举新的master节点,客户端是否能动态感知到
* 新的master选举出来后,哨兵会把消息发布出去,客户端实际上是实现了一个消息监听机制,
* 当哨兵把新master的消息发布出去,客户端会立马感知到新master的信息,从而动态切换访问的masterip
*/
@RequestMapping("/sentinel")
public void sentinel() {
int i = 1;
while (true) {
try {
stringRedisTemplate.opsForValue().set("shenlongfeixian" + i, i + "");
redisTemplate.opsForValue().set("slfx" + i, i + "");
System.out.println("设置key:" + "shenlongfeixian" + i);
i++;
Thread.sleep(1000);
} catch (Exception e) {
log.error("错误:", e);
}
}
}
}
断开主节点,sentinel会重新选举主节点
StringRedisTemplate与RedisTemplate详解
spring 封装了 RedisTemplate 对象来进行对redis的各种操作,它支持所有的 redis 原生的 api。在 RedisTemplate中提供了几个常用的接口方法的使用,分别是:
private ValueOperations<K, V> valueOps;
private HashOperations<K, V> hashOps;
private ListOperations<K, V> listOps;
private SetOperations<K, V> setOps;
private ZSetOperations<K, V> zSetOps;
RedisTemplate中定义了对5种数据结构操作:
redisTemplate.opsForValue();//操作字符串
redisTemplate.opsForHash();//操作hash
redisTemplate.opsForList();//操作list
redisTemplate.opsForSet();//操作set
redisTemplate.opsForZSet();//操作有序set
StringRedisTemplate继承自RedisTemplate,也一样拥有上面这些操作。
StringRedisTemplate默认采用的是String的序列化策略,保存的key和value都是采用此策略序列化保存 的。
RedisTemplate默认采用的是JDK的序列化策略,保存的key和value都是采用此策略序列化保存的。
127.0.0.1:6379> get slfx1
"\"1\""
127.0.0.1:6379> get shenlongfeixian1
"1"
gRedisTemplate与RedisTemplate详解
spring 封装了 RedisTemplate 对象来进行对redis的各种操作,它支持所有的 redis 原生的 api。在 RedisTemplate中提供了几个常用的接口方法的使用,分别是:
private ValueOperations<K, V> valueOps;
private HashOperations<K, V> hashOps;
private ListOperations<K, V> listOps;
private SetOperations<K, V> setOps;
private ZSetOperations<K, V> zSetOps;
RedisTemplate中定义了对5种数据结构操作:
redisTemplate.opsForValue();//操作字符串
redisTemplate.opsForHash();//操作hash
redisTemplate.opsForList();//操作list
redisTemplate.opsForSet();//操作set
redisTemplate.opsForZSet();//操作有序set
StringRedisTemplate继承自RedisTemplate,也一样拥有上面这些操作。
StringRedisTemplate默认采用的是String的序列化策略,保存的key和value都是采用此策略序列化保存 的。
RedisTemplate默认采用的是JDK的序列化策略,保存的key和value都是采用此策略序列化保存的。
127.0.0.1:6379> get slfx1
"\"1\""
127.0.0.1:6379> get shenlongfeixian1
"1"