python数据可视化的简单应用
本篇文章主要讲的是python数据可视化的简单实例,主要使用的是matplotlib,但在代码中还会用到pandas和numpy库用来对数据进行处理。
本次项目我使用的数据是2013-2019年全国31个省、自治区、直辖市的人均年支出情况。excel表的部分数据如图:
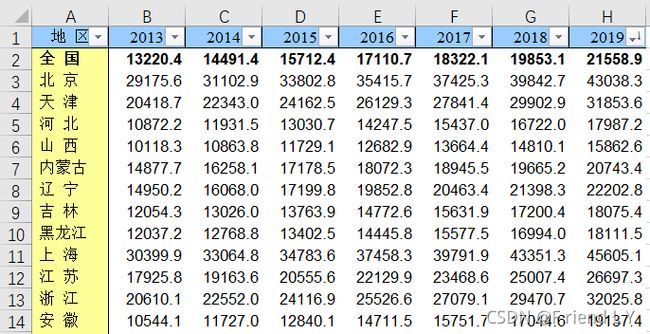
要求:
能够直观地看出各省2013--2019年的增长趋势以及同全国平均情况的对比。
问题分析:
通过项目要求,我们可以先构思一个基本的思路:既然要直观地看出各省每年的增长情况,那么可以考虑使用折线图来反映;还要看出各省同全国平均情况的对比,那么可以将全国的情况和各省的情况放在一张图中,如果把31个省、自治区、直辖市和全国的人均支出情况都放在一张图上的话,必然会显得过于杂乱,所以我们可以画31张图,每张图上的内容就是该省和全国的人均支出情况的对比,虽然画的图比较多,但是更加简洁、直观。
具体实现:
读取excel里面的数据并将其赋值给自定义变量data。
data = pd.read_excel('E:\\人均年支出.xlsx')自定义三个列表,listx用来存储2013-2019作为图上的x周,listyy是用来存储各年的数据,listcity是用来存储城市的名称的。之后用for循环遍历excel表格,将每行的城市名称添加进列表listcity里面。然后再用for循环将每个城市2013-2019年的数据作为列表添加进列表listyy中,并使用numpy里面的round()函数将列表中的数据保留一位小数(方便画图)。
data.iloc[i]是取出excel第i+1行的数据(excel最开始地区那一行不算数据),所以说i=1时就是取第二行,也就是北京那一行的数据。
如果只写 data.iloc[i],此时的数据类型是'pandas.core.series.Series',是没办法对数据进行操作的,需要加上.values,将其变成'numpy.ndarray'数据类型(类似于数组)才可进行操作。这里我用list()函数将它强转为了列表,然后通过索引得到其中的第一个元素(也就是城市名)。
listx = ['2013', '2014', '2015', '2016', '2017', '2018', '2019']
listyy = []
listcity = []
for i in range(1, 32):
num = list(data.iloc[i].values)[0]
listcity.append(num) # 将每行的城市名添加进列表
for i in range(0, 32):
listyy.append(list(data.iloc[i].values)[1:]) # 将每个城市2013-2019年的数据作为列表添加进自定义列表listyy中
listy=np.round(listyy, 1) 自定义一个画图函数rin(b,c),为了下面画31张图的重复调用。该函数第一个参数传的是2013-2019年的数据,数据类型是列表,第二个参数传的是城市名称,数据类型是字符串。
这两句代码是为了解决画的图上中文出错的问题,不加的话图上的中文会显示为一个个方框。
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False这两个for循环的作用是在图上将两条折线上的每个点的数据显示出来。
zip()函数的作用是以可迭代对象为参数,将对象中对应的元素打包成一个个元组,然后返回这些元组组成的列表。
text()函数的作用相当于添加注释,拿我代码中的这个函数来说,前两个参数分别表示注释文本所在的x和y坐标,第三个参数是注释文本的内容,第四个和第五个参数就是用来调整注释的相对位置,比如我这个就是显示在点的中上方。
for ax, bx in zip(listx, listy[0]):
plt.text(ax, bx, bx, ha='center', va='bottom', fontsize=15)
for a1, b1 in zip(listx, b):
plt.text(a1, b1, b1, ha='center', va='bottom', fontsize=15)rin()函数完整代码:
def rin(b, c):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure()
plt.title(c, fontsize=20)
plt.plot(listx, listy[0], label=' 全 国') # 画出‘全国’所对应的折线图
plt.plot(listx, b, label=c, linestyle='--', marker='o') # 画出具体省份所对应的折线图
plt.xlabel('年份')
plt.ylabel('人均支出')
for ax, bx in zip(listx, listy[0]):
plt.text(ax, bx, bx, ha='center', va='bottom', fontsize=15)
for a1, b1 in zip(listx, b):
plt.text(a1, b1, b1, ha='center', va='bottom', fontsize=15)
plt.legend() # 显示图例
plt.savefig('E:\\Rin\\'+c)最后的话呢,就是用for循环画出所有的图了。要注意的一点是要保证从listcity中取出的城市名和从listy中取出的每条数据相匹配。
for i in range(1, 32):
rin(listy[i], listcity[i-1])以北京为例,画出的图是这样的:

总结:
本次的这个小项目并不算太复杂,重点是matplotlib里面的各种函数的使用,学会各种函数的组合使用才是项目成功的关键。最后,如果代码中有不正确的地方,希望能够给本人指出来,我会不断改正。
完整代码:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
data = pd.read_excel('E:\\人均年支出.xlsx')
listx = ['2013', '2014', '2015', '2016', '2017', '2018', '2019']
listyy = []
listcity = []
for i in range(1, 32):
num = list(data.iloc[i].values)[0]
listcity.append(num)
print(listcity)
for i in range(0, 32):
listyy.append(list(data.iloc[i].values)[1:])
listy=np.round(listyy, 1)
def rin(b, c):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure()
plt.title(c, fontsize=20)
plt.plot(listx, listy[0], label=' 全 国')
plt.plot(listx, b, label=c, linestyle='--', marker='o')
plt.xlabel('年份')
plt.ylabel('人均支出')
for ax, bx in zip(listx, listy[0]):
plt.text(ax, bx, bx, ha='center', va='bottom', fontsize=15)
for a1, b1 in zip(listx, b):
plt.text(a1, b1, b1, ha='center', va='bottom', fontsize=15)
plt.legend()
plt.savefig('E:\\Rin\\'+c)
for i in range(1, 32):
rin(listy[i], listcity[i-1])