Spark编程基础-(一)大数据技术概述
Table of Contents
1. 大数据时代
1.1 大数据时代为什么会到来?
1.1.1 大数据产生的技术支撑(3个)
1.1.2 数据产生方式的变革
2. 大数据概念
2.1 大量化
2.2 多样化
2.3 快速化
2.4 价值密度低
3. 大数据的影响
3.1 “计算”和“数据”的区别是什么?
3.2大数据时代在思维层面有什么影响呢?(3方面影响)
4. 大数据关键技术
4.1 数据采集
4.2 数据存储
4.3 数据处理
4.4 数据隐私和安全
4.5 真正的大数据技术
5.大数据计算模式
5.1 批处理计算
5.2 流计算
5.3 图计算
5.4 查询分析计算
6.代表性大数据技术
6.1 Hadoop
6.2 Spark
6.3 Flink
6.4 Beam
1. 大数据时代
大数据时代开启:2010年
大数据元年:2013年
 图1 三个信息化浪潮
图1 三个信息化浪潮
1.1 大数据时代为什么会到来?
共有两个方面:大数据产生的技术支撑和数据产生方式的变革。
1.1.1 大数据产生的技术支撑(3个)
(1) 存储设备
成本越来越低,容量越来越大。人们不会再挑选哪些要存储,哪些不需要存储。
(2) CPU计算能力
按照摩尔定律(芯片上的晶体管数量每隔24个月将增加一倍),CPU处理能力大概每隔18-24个月会翻一番。
虽然单核CPU上的晶体管数量是有限的,因此采用不用的手段来提高计算能力。例如,将单核CPU扩展成多核CPU,也可以使用多台电脑一起计算,即采用分布式集群的方式进行并行计算。
(3) 网络带宽
由于要进行分布式计算,因此对网络的带宽也提出了要求。
1.1.2 数据产生方式的变革
共有3个阶段
 图2 数据产生方式变革的三个阶段
图2 数据产生方式变革的三个阶段
2. 大数据概念
可以通过如下的4V特性说明大数据的概念。
 图3 大数据的4V特性
图3 大数据的4V特性
2.1 大量化
美国IDC的一份报告指出:
大数据的摩尔定律:人类社会数据每年50%的速度,每两年就增长一倍。
 图4 大数据摩尔定律
图4 大数据摩尔定律
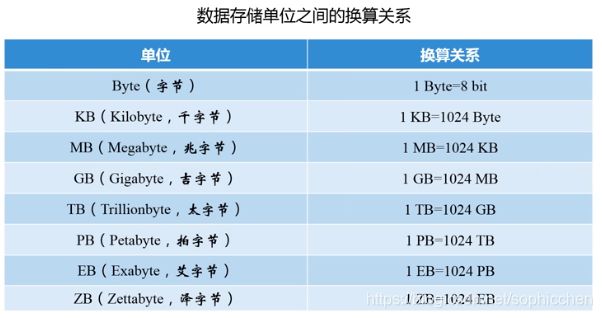 图5 换算关系
图5 换算关系
2.2 多样化
数据类型多样化。
结构化数据:具有规范的行和列结构数据。(存储于关系型数据库中)
非结构化数据:不具有规范的行和列结构数据。(存储于非关系型数据库中)
大数据中仅有10%是结构化的数据,所以需要新型大数据算法处理多种类型的数据。
2.3 快速化
一秒定律:从数据生成到决策响应仅需1秒。
如果不能在1秒内进行响应,就会失去其商业价值。(通过收集鼠标点击数据流,进行实时推荐。)
2.4 价值密度低
例如视频金控摄像头数据。
单点价值高。
3. 大数据的影响
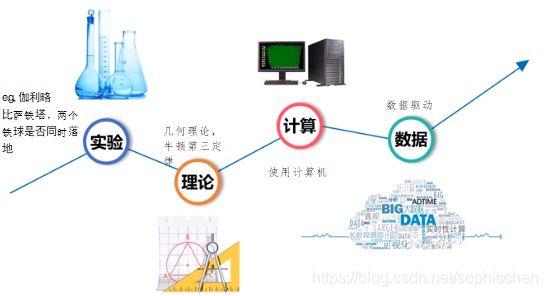 图6 科学研究的4大范式
图6 科学研究的4大范式
3.1 “计算”和“数据”的区别是什么?
“计算”是知道问题什么,通过计算来解释这一现象。例如,过去12个月中,某一款商品的销量在不断下滑。就需要通过计算机编程分析为什么在过去的12个月里,该商品销量下滑。即,问“为什么”。
“数据”是根本就不知道问题是什么,通过数据驱动的方式,从大量的数据中发现问题,并解决问题。
3.2大数据时代在思维层面有什么影响呢?(3方面影响)
(1)全样而非抽样
我们以前采用抽样的原因如下:
 图7 采样抽样的原因
图7 采样抽样的原因
现在采用全样本。
(2) 效率而非精确
现在效率比精确度更加重要。
(3)相关而非因果
只问“相关性”,不问“为什么”。
4. 大数据关键技术
如下图所示,数据处理的全流程共分为4步:
 图8 数据处理全流程
图8 数据处理全流程
4.1 数据采集
ETL:抽取转换加载工具
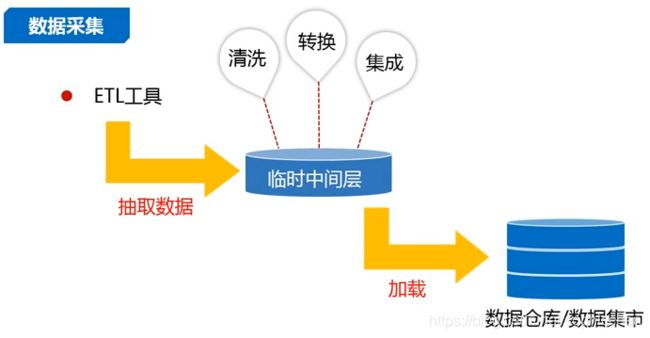 图9 数据处理过程
图9 数据处理过程
4.2 数据存储
 图10 数据存储和管理
图10 数据存储和管理
4.3 数据处理
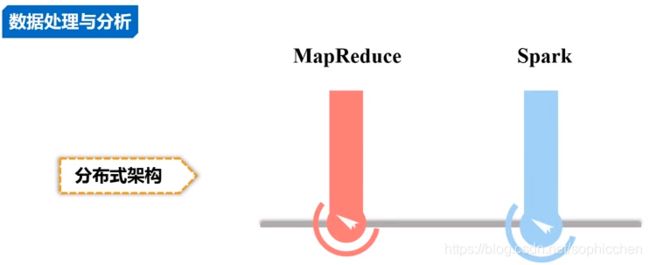 图11 数据处理框架
图11 数据处理框架
解决分布式计算。
4.4 数据隐私和安全
 图12 数据隐私和安全保护体系的存在
图12 数据隐私和安全保护体系的存在
4.5 真正的大数据技术
虽然大数据技术分为以上的4层,但是到目前为止,真正的大数据技术只发生在中间的2层,即数据存储和数据处理。
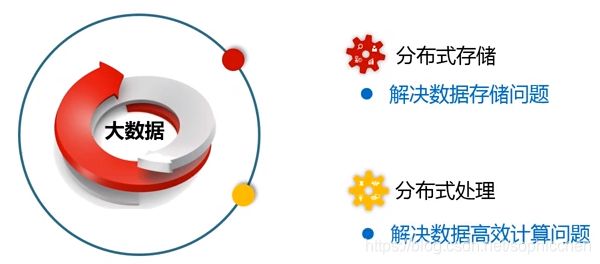 图13 目前大数据涉及到的2大核心技术
图13 目前大数据涉及到的2大核心技术
(1)分布式存储
在过去几年,出现的分布式存储技术都是有Google提出的。
 图14 分布式存储
图14 分布式存储
GFS:是google提出的分布式文件系统。
HDFS:是业界对GFS进行开源实现后的Hadoop中的分布式文件系统。
(2)分布式处理
在处理时,不会将分布式的数据传至单机上进行处理,而是对保存在机器上的数据进行本地化处理。即,数据保存在哪台机器上,就在哪台机器上处理这部分数据。
例如,我们上面提到的google公司提出的MapReduce框架。
由此,HDFS和MapReduce就构成了Hadoop生态系统中的两大核心技术。
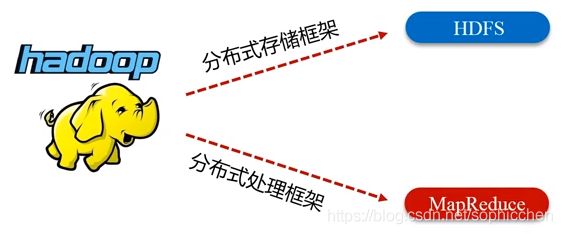 图15 Hadoop两大核心技术
图15 Hadoop两大核心技术
5.大数据计算模式
到目前为止,由于每一种技术都有其局限性,还没有一种技术能够解决所有的应用问题。我们将企业应用场景分为如下4大类:
 图16 企业应用场景的划分
图16 企业应用场景的划分
5.1 批处理计算
针对大规模数据的批量处理;不能做到实时响应。
面向批处理的计算框架:MapReduce和Spark。
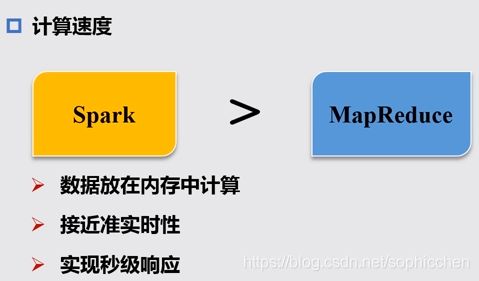 图17 批处理计算框架的计算速度对比
图17 批处理计算框架的计算速度对比
5.2 流计算
每次处理的数据量少,但是需要持续处理,并且需要实时响应(秒级)。
例如,大型应用系统的故障分析检测平台。由于各种系统不断的产生日志,大数据分析平台就需要不断地去抓取日志进行故障分析。
MapReduce不能完成流计算。
流计算框架:Twitter Storm(典型流计算框架,毫秒级响应),S4(雅虎产品),Flume,DStream。
5.3 图计算
针对图数据,例如,社交网络数据微信,微博,每个用户就是图结构数据中的一个节点;地理信息系统。
MapReduce可以完成图计算,但是效率低
图计算框架:Pregel(Google产品),Hama,Power Graph。
5.4 查询分析计算
Dremel(Google产品),Hive(Hadoop内)。
6.代表性大数据技术
这里展开介绍4个大数据技术:Hadoop,Spark,Flink,Beam。
6.1 Hadoop
在2005年到2015年间,只要谈到“大数据”,就会想到Hadoop,它是一整套的大数据技术框架。Hadoop不是一个单一的软件,它是一个完整的生态系统。
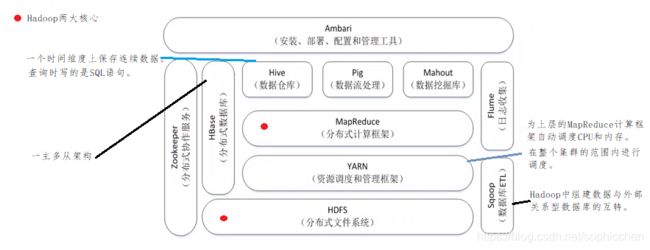 图18 Hadoop生态系统
图18 Hadoop生态系统
(1)Hive
数据库和数据仓库的区别:
- 数据库:保存某一时刻的状态数据。例如,商品的库存数量。数据库是不能记录历史状态信息。
- 数据仓库:一般以天为单位或者周为单位保存一次数据镜像,这样形成连续的时间维度上的数据状态。
由于数据仓库Hive能够反应数据的时间维度信息,因此可以通过Hive做很多的决策分析。数据仓库中常用的OLAP分析。OLAP分析就是利用数据仓库中的数据进行多维数据分析。例如,分析商品在过去12个月的销量变化趋势,再给出一些原因。
传统的数据仓库都是构建在关系型数据库上的,大数据时代的数据仓库都是构建在HDFS上的。
我们可以把Hive看成一个编程接口,他可以将SQL语句自动转换成对HDFS的查询分析。
(2)Pig
采用的是Pig Latin语言。在将数据保存到数据仓库之前,首先使用Pig对数据进行清洗和转换。
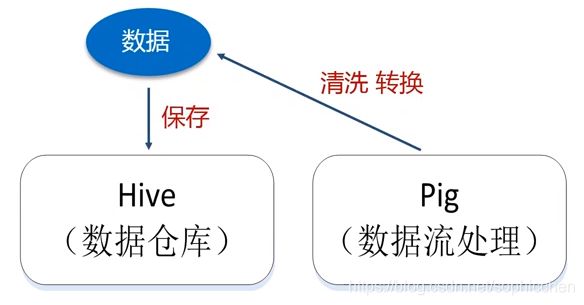 图19 Pig作用
图19 Pig作用
(3)Mahout
传统的算法都是单机的,因此需要对传统算法进行改造。
在2015年前,是专门针对MapReduce去实现的。由于2015年后,Spark逐步取代MapReduce,Mahout也不在做针对MapReduce后续的更新了。Mahout开发的算法库全面转向Spark。
(4)HBase
底层也是借助于HDFS进行数据保存的。
Hadoop安装好,HDFS配置好,能够正常的运行然后再配置HBase,让HBase指向HDFS
(5)ZooKeeper
HBase是一主多从架构,一个管家管理很多的从节点。管家提供元数据,几千个从节点提供数据存储服务。
怎么能保证这几千台服务器有唯一一个管家存在呢,就是由ZooKeeper选出。
(6)Flume
常见的Hadoop生态系统组件。
分布式的日志采集分析系统。
(7)Sqoop
在关系型数据库和HDFS(或者Hadoop组件)之间进行互转。
(8)MapReduce
将所有的计算高度抽象成两个函数:Map和Reduce。
屏蔽了底层分布式并行编程细节,就跟进行单机编程一样。
一大核心策略:“分而治之”。将海量数据进行分片,分别在不同的服务器上进行并行计算,即每一个分片交给一个Map任务去处理,实现高效的处理。
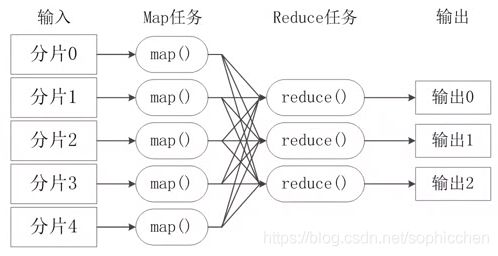 图20 MapReduce的“分而治之”
图20 MapReduce的“分而治之”
(9)YARN
是个后来者,在Hadoop 1.0时,没有YARN组件。
为什么需要YARN呢?
在大型企业中,都会有下面的企业应用场景:
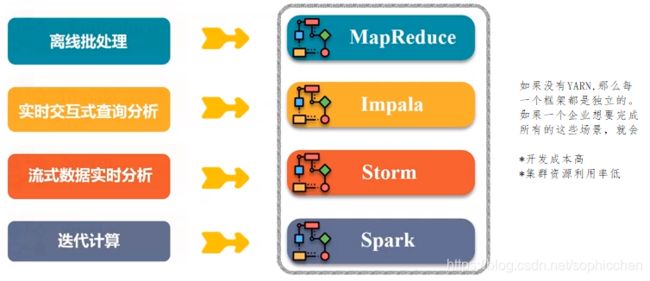 图21 企业应用场景
图21 企业应用场景
一个集群内部署多个框架,使用YARN对公用的资源进行管理和调度。
 图22 在YARN上部署各种计算框架
图22 在YARN上部署各种计算框架
6.2 Spark
可以满足企业中各种业务需求
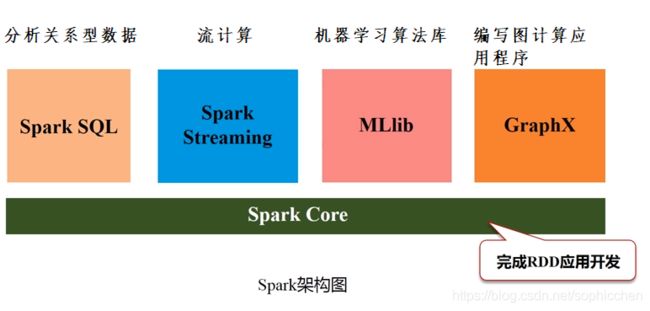 图23 Spark架构图
图23 Spark架构图
Spark是对MapReduce的改进。
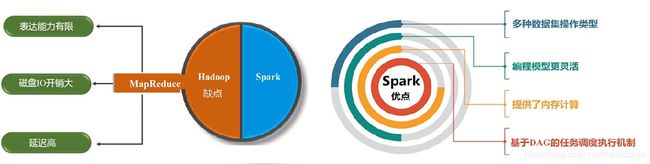 图24 MapReduce的缺点和Spark的优点
图24 MapReduce的缺点和Spark的优点
MapReduce中只有Map和Reduce两种操作,但是表达能力有限,因而Spark中增加了多种数据操作。
MapReduce是基于磁盘的IO操作,而Spark可以高效地读写内存,其很多的数据交换都是在内存中完成的。尤其是在进行迭代运算时,MapReduce是反复读写磁盘,而Spark进行内存读取。
Spark采用的是有向无环图的任务调度机制,即上一个操作的输出可以马上作为下一个操作的输入,作为一个流水线,可以完成数据的高效处理。而MapReduce在上一个操作完成后,首先要将结果写入磁盘,然后下一操作再从磁盘上读取上一次保存的结果作为本次的输入,这样造成了数据的反复落地。
Spark和Hadoop中的存储组件可以进行组合部署使用。
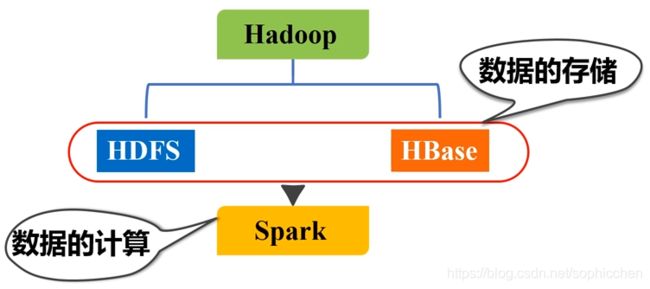 图25 Spark和Hadoop中的存储组件可以进行组合部署使用
图25 Spark和Hadoop中的存储组件可以进行组合部署使用
开发Spark使用Scala编程语言开发。Spark本身就是Scala语言开发的。
使用Java语言会比较繁琐。另外,Java是先编译再执行,而Scala是交互式编程。
Python语言最大的缺点是并发性差,因此企业级用户是不会用Python编写的。
Hadoop是Java语言开发的,因此使用Python比较麻烦。
6.3 Flink
Flink和Spark解决的问题是一样的。Flink在一个框架内集成了对流计算和批处理的两种类型数据的统一管理。
 图26 Spark和Flink的对比
图26 Spark和Flink的对比
Spark可以进行流计算,其原理是将数据切成一段一段的数据,在每一段上进行计算,来模拟流计算。但它最小的分割长度为1秒,实现不了毫秒级别的响应。
Flink(Google产品)在设计的时候就是面向流数据的,它是以一行一行为单位。
6.4 Beam
Google想要将市场上的所有产品统一管理,提供统一的编程接口。