淘宝搜索的向量召回算法MGDSPR
1. 概述
前面已经介绍了多个搜索召回中的向量召回算法,如Facebook的EBR,Que2Search,京东的DPSR。对于搜索系统来说,召回通常是由倒排召回构成,倒排召回的简单原理如下图所示:

对于Document,首先对其关键词的提取,并将其索引化,在索引中,其key是核心词,value对应了item的列表,这便是倒排索引的来源,这部分是可以离线完成的。对于在线的检索部分,首先会通过分词将用户的Query进行分词,得到Query的核心词后在倒排索引中查找到相关的item。倒排召回的原理相对比较简单,同时因为是基于词的匹配,相对而言相关性上能够得到保证。但是基于倒排索引的召回形式也存在着一些问题:
- 语义鸿沟(Semantic Gap)的问题。如item的核心词是“长裙”,那么对于“长裙”的Query,通过核心词便不能对其找回,当然这部分问题可以通过query改写或者query扩展的方式进行解决;
- 个性化的召回。基于词匹配的方式无法加入个性化的特征,因此在召回匹配的过程中无法进行个性化的操作。
- 多模态特征的融合。这一点与个性化类似。
前面介绍到的基于向量召回的召回算法能够很好的解决上述提到的问题。淘宝在2021年也提出了对应的向量召回算法MGDSPR(Multi-Grained Deep Semantic Product Retrieval)[1]。在MGDSPR中着重要解决的问题是如何优化相关性的问题,这一点在其他的文章中很少提及,但是搜索中的相关性问题对于向量召回来说是避不开的一个问题,而且是一个较难解决的一个问题。
2. MGDSPR的算法原理
2.1. MGDSPR的模型结构
MGDSPR的模型结构如下图所示:

相比较于EBR,Que2Search以及DPSR,MGDSPR的结构是相当复杂。分开来讲,模型的特征主要是三个方面,Query侧(1-gram,2-gram,q_seg和q_his),用户行为序列(实时行为序列,短期行为序列,长期行为序列),item侧(item ID和title)。
2.2. 特征的处理
2.2.1. Query侧
Query侧的模型结构详细如下图所示:
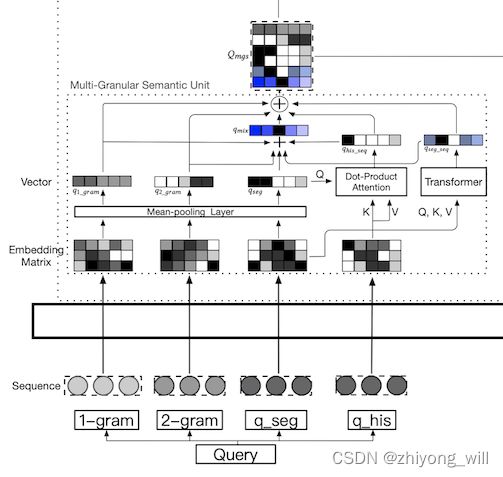
特征方面主要是四个,分别为1-gram,2-gram,q_seg和q_his。这样设计的目的是希望对于Query能够尽可能的挖掘多粒度的特征,这也就对应了MGDSPR中的Multi-Grained。那么这几个部分都是如何实现的呢?当一个用户发起一次query请求时,如“红色连衣裙”,其对应的分词结果为 q u = { w 1 u , ⋯ , w n u } q_u=\left\{w_1^u,\cdots ,w_n^u \right\} qu={w1u,⋯,wnu},如上述的query分词结果为“{红色,连衣裙}”。而每一个词又是由单个字组成 w u = { c 1 u , ⋯ , c m u } w_u=\left\{c_1^u,\cdots ,c_m^u \right\} wu={c1u,⋯,cmu},如词“红色”是由“{红,色}”组成。历史query是由多个query组成 q h i s = { q 1 u , ⋯ , q k u } ∈ R k × d q_{his}=\left\{q_1^u,\cdots ,q_k^u \right\}\in \mathbb{R}^{k\times d} qhis={q1u,⋯,qku}∈Rk×d。通过组合可以得到6个维度的query侧的特征 Q m g s Q_{mgs} Qmgs。
第一个是 q 1 _ g r a m q_{1\_gram} q1_gram,也就是单字维度的特征,其取的是所有字的embedding的均值 q 1 _ g r a m = m e a n _ p o o l i n g ( c 1 , ⋯ , c m ) q_{1\_gram}=mean\_pooling\left ( c_1,\cdots ,c_m \right ) q1_gram=mean_pooling(c1,⋯,cm),其中 c m ∈ R 1 × d c_m\in \mathbb{R}^{1\times d} cm∈R1×d,则 q 1 _ g r a m ∈ R 1 × d q_{1\_gram}\in \mathbb{R}^{1\times d} q1_gram∈R1×d。
第二个是 q 2 _ g r a m q_{2\_gram} q2_gram,也就是2个字维度的特征,与单字维度的特征类似,其值为 q 2 _ g r a m = m e a n _ p o o l i n g ( c 1 c 2 , ⋯ , c m − 1 c m ) q_{2\_gram}=mean\_pooling\left ( c_1c_2,\cdots ,c_{m-1}c_m \right ) q2_gram=mean_pooling(c1c2,⋯,cm−1cm),且 q 2 _ g r a m ∈ R 1 × d q_{2\_gram}\in \mathbb{R}^{1\times d} q2_gram∈R1×d。
第三个是 q s e g q_{seg} qseg,也就是词维度的特征,与单字维度的特征类似,其值为 q s e g = m e a n _ p o o l i n g ( w 1 , ⋯ , w n ) q_{seg}=mean\_pooling\left ( w_1,\cdots ,w_n \right ) qseg=mean_pooling(w1,⋯,wn),其中 w n ∈ R 1 × d w_n\in \mathbb{R}^{1\times d} wn∈R1×d,则 q s e g ∈ R 1 × d q_{seg}\in \mathbb{R}^{1\times d} qseg∈R1×d。
第四个是 q s e g _ s e q q_{seg\_seq} qseg_seq,也就是将词粒度的又当成序列作为特征。这里使用了基于Transformer的方法来处理序列数据,最终取均值 q s e g _ s e q = m e a n _ p o o l i n g ( T r i m ( w 1 , ⋯ , w n ) ) q_{seg\_seq}=mean\_pooling\left (Trim\left ( w_1,\cdots ,w_n \right ) \right ) qseg_seq=mean_pooling(Trim(w1,⋯,wn)),且 q s e g _ s e q ∈ R 1 × d q_{seg\_seq}\in \mathbb{R}^{1\times d} qseg_seq∈R1×d。
第五个是 q h i s _ s e q q_{his\_seq} qhis_seq,也就是历史query的序列,这里直接与 q s e g q_{seg} qseg做attention操作 q h i s _ s e q = s o f t m a x ( q s e g ⋅ ( q h i s ) T ) q h i s q_{his\_seq}=softmax\left ( q_{seg}\cdot \left ( q_{his} \right )^T \right )q_{his} qhis_seq=softmax(qseg⋅(qhis)T)qhis,且 q h i s _ s e q ∈ R 1 × d q_{his\_seq}\in \mathbb{R}^{1\times d} qhis_seq∈R1×d。
第六个是 q m i x q_{mix} qmix,也就是混合上述的五个特征,在MGDSPR直接将其相加 q m i x = q 1 _ g r a m + q 2 _ g r a m + q s e g + q s e g _ s e q + q h i s _ s e q q_{mix}=q_{1\_gram}+q_{2\_gram}+q_{seg}+q_{seg\_seq}+q_{his\_seq} qmix=q1_gram+q2_gram+qseg+qseg_seq+qhis_seq,且 q m i x ∈ R 1 × d q_{mix}\in \mathbb{R}^{1\times d} qmix∈R1×d。
最后将上述六个粒度的特征垂直concat在一起,便得到了 Q m g s Q_{mgs} Qmgs:
Q m g s = c o n c a t ( q 1 _ g r a m , q 2 _ g r a m , q s e g , q s e g _ s e q , q h i s _ s e q , q m i x ) Q_{mgs}=concat\left ( q_{1\_gram},q_{2\_gram},q_{seg},q_{seg\_seq},q_{his\_seq},q_{mix} \right ) Qmgs=concat(q1_gram,q2_gram,qseg,qseg_seq,qhis_seq,qmix)
且 q m g s ∈ R 6 × d q_{mgs}\in \mathbb{R}^{6\times d} qmgs∈R6×d。
2.2.2. 用户行为序列
对用户行为序列的挖掘就成为个性化的核心,通过用户历史行为,挖掘出用户的兴趣。行为序列部分的模型结构详细如下:

对于用户行为序列的挖掘,包括三个部分,分别为实时用户行为序列,短期用户行为序列,长期用户行为序列。
对于实时用户行为序列 R u = { i 1 u , ⋯ , i t u , ⋯ , i T u } R^u=\left\{i_1^u,\cdots,i_t^u,\cdots,i_T^u \right\} Ru={i1u,⋯,itu,⋯,iTu},使用LSTM对其进行处理,得到隐含层的结果 R l s t m u = { h 1 u , ⋯ , h t u , ⋯ , h T u } R^u_{lstm}=\left\{h_1^u,\cdots,h_t^u,\cdots,h_T^u \right\} Rlstmu={h1u,⋯,htu,⋯,hTu},再经过Multi-head Self Attention得到 R s e l f _ a t t u = { h 1 u , ⋯ , h t u , ⋯ , h T u } R^u_{self\_att}=\left\{h_1^u,\cdots,h_t^u,\cdots,h_T^u \right\} Rself_attu={h1u,⋯,htu,⋯,hTu},在 R s e l f _ a t t u R^u_{self\_att} Rself_attu的第一个位置上加入全0的向量,得到 R z e r o _ a t t u = { 0 , h 1 u , ⋯ , h t u , ⋯ , h T u } ∈ R ( T + 1 ) × d R^u_{zero\_att}=\left\{0,h_1^u,\cdots,h_t^u,\cdots,h_T^u \right\}\in \mathbb{R}^{\left ( T+1 \right )\times d} Rzero_attu={0,h1u,⋯,htu,⋯,hTu}∈R(T+1)×d,最后与 q m g s q_{mgs} qmgs进行Dot-Product Attention的计算,且 q m g s q_{mgs} qmgs作为Q, R z e r o _ a t t u R^u_{zero\_att} Rzero_attu作为K和V,得到实时个性化表示 H r e a l ∈ R 6 × d H_{real}\in \mathbb{R}^{6\times d} Hreal∈R6×d,其数学表达式为:
H r e a l = s o f t m a x ( Q m s g ⋅ R z e r o _ a t t T ) ⋅ R z e r o _ a t t T H_{real}=softmax\left ( Q_{msg}\cdot R_{zero\_att}^T \right )\cdot R_{zero\_att}^T Hreal=softmax(Qmsg⋅Rzero_attT)⋅Rzero_attT
对于短期用户行为序列 S u = { i 1 u , ⋯ , i t u , ⋯ , i T u } S^u=\left\{i_1^u,\cdots,i_t^u,\cdots,i_T^u \right\} Su={i1u,⋯,itu,⋯,iTu},通过Multi-head Self Attention得到 S s e l f _ a t t u = { h 1 u , ⋯ , h t u , ⋯ , h T u } S^u_{self\_att}=\left\{h_1^u,\cdots,h_t^u,\cdots,h_T^u \right\} Sself_attu={h1u,⋯,htu,⋯,hTu},在 S s e l f _ a t t u S^u_{self\_att} Sself_attu的第一个位置上加入全0的向量,得到 S z e r o _ a t t u = { 0 , h 1 u , ⋯ , h t u , ⋯ , h T u } ∈ R ( T + 1 ) × d S^u_{zero\_att}=\left\{0,h_1^u,\cdots,h_t^u,\cdots,h_T^u \right\}\in \mathbb{R}^{\left ( T+1 \right )\times d} Szero_attu={0,h1u,⋯,htu,⋯,hTu}∈R(T+1)×d,最后与 q m g s q_{mgs} qmgs进行Dot-Product Attention的计算,且 q m g s q_{mgs} qmgs作为Q, S z e r o _ a t t u S^u_{zero\_att} Szero_attu作为K和V,得到短期个性化表示 H s h o r t ∈ R 6 × d H_{short}\in \mathbb{R}^{6\times d} Hshort∈R6×d,其数学表达式为:
H s h o r t = s o f t m a x ( Q m s g ⋅ S z e r o _ a t t T ) ⋅ S z e r o _ a t t T H_{short}=softmax\left ( Q_{msg}\cdot S_{zero\_att}^T \right )\cdot S_{zero\_att}^T Hshort=softmax(Qmsg⋅Szero_attT)⋅Szero_attT
对于长期用户行为序列的挖掘与上述的不一样,在长期用户行为序列的描述中包含四个方面的属性,分别为item维度 L i t e m u L_{item}^u Litemu,shop维度 L s h o p u L_{shop}^u Lshopu,叶子类目维度 L l e a f u L_{leaf}^u Lleafu和品牌维度 L b r a n d u L_{brand}^u Lbrandu。而对于每一个维度,又分为三个方面的行为序列,以item维度为例,又分为点击 L c l i c k _ i t e m L_{click\_item} Lclick_item,购买 L b u y _ i t e m L_{buy\_item} Lbuy_item和收藏 L c o l l e c t _ i t e m L_{collect\_item} Lcollect_item。这里直接对向量进行mean-pooling对其压缩合并成一个向量(文章中给出的原因是考虑到速度),最终得到item维度的结果 L i t e m u = { 0 , h c l i c k , h b u y , h c o l l e c t } L^u_{item}=\left\{0,h_{click},h_{buy},h_{collect} \right\} Litemu={0,hclick,hbuy,hcollect},最后与 q m g s q_{mgs} qmgs进行Dot-Product Attention的计算,且 q m g s q_{mgs} qmgs作为Q, L i t e m u L^u_{item} Litemu作为K和V,得到实时个性化表示 H a _ i t e m ∈ R 6 × d H_{a\_item}\in \mathbb{R}^{6\times d} Ha_item∈R6×d,其数学表达式为:
H a _ i t e m = s o f t m a x ( Q m s g ⋅ L i t e m T ) ⋅ L i t e m T H_{a\_item}=softmax\left ( Q_{msg}\cdot L_{item}^T \right )\cdot L_{item}^T Ha_item=softmax(Qmsg⋅LitemT)⋅LitemT
其他两个维度类似,得到 H a _ s h o p ∈ R 6 × d H_{a\_shop}\in \mathbb{R}^{6\times d} Ha_shop∈R6×d, H a _ l e a f ∈ R 6 × d H_{a\_leaf}\in \mathbb{R}^{6\times d} Ha_leaf∈R6×d和 H a _ b r a n d ∈ R 6 × d H_{a\_brand}\in \mathbb{R}^{6\times d} Ha_brand∈R6×d,最终得到长期用户行为的挖掘结果,其数学表达式为:
H l o n g = H a _ i t e m + H a _ s h o p + H a _ l e a f + H a _ b r a n d H_{long}=H_{a\_item}+H_{a\_shop}+H_{a\_leaf}+H_{a\_brand} Hlong=Ha_item+Ha_shop+Ha_leaf+Ha_brand
在上述的 R z e r o _ a t t u R^u_{zero\_att} Rzero_attu, S z e r o _ a t t u S^u_{zero\_att} Szero_attu和 L i t e m u L^u_{item} Litemu中都添加了0,简单来说就是为了在计算attention的时候用于处理与 Q m s g Q_{msg} Qmsg不相关的情况,相关性为0。
2.2.3. Query和User塔的输出
通过上面的计算,得到了query的各粒度表示 q m g s ∈ R 6 × d q_{mgs}\in \mathbb{R}^{6\times d} qmgs∈R6×d,实时个性化表示 H r e a l ∈ R 6 × d H_{real}\in \mathbb{R}^{6\times d} Hreal∈R6×d,短期个性化表示 H s h o r t ∈ R 6 × d H_{short}\in \mathbb{R}^{6\times d} Hshort∈R6×d以及长期个性化表示 H l o n g ∈ R 6 × d H_{long}\in \mathbb{R}^{6\times d} Hlong∈R6×d,其中, q m g s q_{mgs} qmgs为多粒度的语义表示, { H r e a l , H s h o r t , H l o n g } \left\{H_{real},H_{short},H_{long} \right\} {Hreal,Hshort,Hlong}为用户个性化表示,将[CLS]和 q m g s q_{mgs} qmgs,H_{real},H_{short}和H_{long}合并作为Multi-head Self Attention的输入(类似于Bert中的输入),最终取[CLS]作为Query和User塔的输出 H q u ∈ R 1 × d H_{qu}\in \mathbb{R}^{1\times d} Hqu∈R1×d,其数学表达式为:
H q u = S e l f _ A t t f i r s t ( [ [ C L S ] , Q m s g , H r e a l , H s h o r t , H l o n g ] ) H_{qu}=Self\_Att^{first}\left ( \left [ \left [ CLS \right ],Q_{msg},H_{real},H_{short},H_{long} \right ] \right ) Hqu=Self_Attfirst([[CLS],Qmsg,Hreal,Hshort,Hlong])
2.4. Item塔
相对而言,Item塔就简单了很多,特征主要包含两个方面,分别为ID类和title,ID类直接通过Embedding转换成向量 e i ∈ R 1 × d e_i\in \mathbb{R}^{1\times d} ei∈R1×d,标题的分词结果 T i = { w 1 i , ⋯ , w N i } T_i=\left\{w_1^i,\cdots,w_N^i \right\} Ti={w1i,⋯,wNi},最终通过下面的数学表达式得到item的向量表示:
H i t e m = e + t a n h ( W t ⋅ ∑ i = 1 N w i N ) H_{item}=e+tanh\left ( W_t\cdot \frac{\sum_{i=1}^{N}w_i}{N} \right ) Hitem=e+tanh(Wt⋅N∑i=1Nwi)
其中, W t W_t Wt为转换矩阵。
这里直接对分词后的词向量取均值,而没有使用序列的方式学习,文中给出的解释是关键词缺乏语法结构,但是在 q s e g _ s e q q_{seg\_seq} qseg_seq中却对分词结果使用了Transformer,这一点是存在矛盾的。
2.3. 损失函数
在MGDSPR中的损失函数使用的是交叉熵损失,没有选择Hinge Loss。文中指出Hinge Loss会导致训练和推断不一致,Hinge Loss只具备局部的比较能力。其中Hinge Loss的数学表达式为:
L = ∑ i = 1 N m a x ( 0 , D ( q ( i ) , d + ( i ) ) − D ( q ( i ) , d − ( i ) ) + m ) L=\sum_{i=1}^{N}max\left ( 0,D\left ( q^{\left ( i \right )},d_+^{\left ( i \right )} \right )-D\left ( q^{\left ( i \right )},d_-^{\left ( i \right )} \right )+m \right ) L=i=1∑Nmax(0,D(q(i),d+(i))−D(q(i),d−(i))+m)
对于局部比较能力,我的理解是在损失函数中,比较的是 D ( q ( i ) , d + ( i ) ) D\left ( q^{\left ( i \right )},d_+^{\left ( i \right )} \right ) D(q(i),d+(i))和 D ( q ( i ) , d − ( i ) ) D\left ( q^{\left ( i \right )},d_-^{\left ( i \right )} \right ) D(q(i),d−(i)),因此是一个局部的比较。同时Hinge Loss受到超参数 m m m的影响较大。
而Cross-entropy Loss的数学表达式为:
L = − ∑ i ∈ I y i l o g ( e x p ( F ( q u , i + ) ) ∑ i ′ ∈ I e x p ( F ( q u , i ′ ) ) ) L=-\sum _{i\in I}y_ilog\left ( \frac{exp\left ( F\left ( q_u,i^+ \right ) \right )}{\sum _{{i}'\in I}exp\left ( F\left ( q_u,{i}' \right )\right )} \right ) L=−i∈I∑yilog(∑i′∈Iexp(F(qu,i′))exp(F(qu,i+)))
其中, F F F表示的是内积, I I I表示的是全量商品, i + i^+ i+表示的是item塔的输出 H i t e m H_{item} Hitem, q u q_u qu表示的是Query和User塔的输出 H q u H_{qu} Hqu。为了能便于计算,在softmax计算中,使用sampled softmax,同时对于每个batch都是用同样的负样本。
2.4. 样本选择
2.4.1. 平滑噪音数据
我们在选择正样本的过程中通常会选择点击样本作为正样本,但是这个是存在噪音的,因为用户的点击与很多因素有关,不仅仅是query和item之间的相关性,还可能与价格等其他因素有关。为了缓解这部分噪音导致的模型问题,在softmax中加入温度单数 τ \tau τ,那么对应的softmax的计算如下:
y ^ ( i + ∣ q u ) = e x p ( F ( q u , i + ) / τ ) ∑ i ′ ∈ I e x p ( F ( q u , i ′ ) / τ ) \hat{y}_{\left ( i^+\mid q_u \right )}=\frac{exp\left ( F\left ( q_u,i^+ \right )/\tau \right )}{\sum _{{i}'\in I}exp\left ( F\left ( q_u,{i}' \right )/\tau \right )} y^(i+∣qu)=∑i′∈Iexp(F(qu,i′)/τ)exp(F(qu,i+)/τ)
这一点在前面的文章中也已经分析过, τ \tau τ的作用就是能够平滑softmax的结果。
2.4.2. 负样本
对于双塔的向量召回,负样本的选择一般包含随机负样本和困难负样本,在随机负样本部分,MGDSPR是通过从商品库 I I I中随机选择,而对于困难样本的挖掘,就相对而言要复杂一点,假设 q u q_u qu, i + i^+ i+和 i − i^- i−分别表示的是query,正样本,负样本的表示。我们按照内积的大小对负样本排序,选择top-N个负样本作为困难负样本 I h a r d ∈ R N × d I_{hard}\in \mathbb{R}^{N\times d} Ihard∈RN×d,然后混合 i + ∈ 1 1 × d i^+\in \mathbb{1}^{1\times d} i+∈11×d和 I h a r d I_{hard} Ihard,通过采样得到 I m i x ∈ R N × d I_{mix}\in \mathbb{R}^{N\times d} Imix∈RN×d, I m i x I_{mix} Imix的数学表达式为:
I m i x = α i + + ( 1 − α ) I h a r d I_{mix}=\alpha i^++\left ( 1-\alpha \right )I_{hard} Imix=αi++(1−α)Ihard
其中, α ∈ R N × 1 \alpha \in \mathbb{R}^{N\times 1} α∈RN×1,且是通过从均匀分布中采样得到,最终softmax表达式为:
y ^ ( i + ∣ q u ) = e x p ( F ( q u , i + ) / τ ) ∑ i ′ ∈ I ∪ I m i x e x p ( F ( q u , i ′ ) / τ ) \hat{y}_{\left ( i^+\mid q_u \right )}=\frac{exp\left ( F\left ( q_u,i^+ \right )/\tau \right )}{\sum _{{i}'\in I\cup I_{mix}}exp\left ( F\left ( q_u,{i}' \right )/\tau \right )} y^(i+∣qu)=∑i′∈I∪Imixexp(F(qu,i′)/τ)exp(F(qu,i+)/τ)
将正样本也有一定的概率被选择为负样本,不是很清楚为什么对于结果是正向的作用。
3. 相关性控制模块
在搜索系统的向量召回中,存在很大的相关性的问题,尽管在模型上已经对query进行多粒度的建模,但是对于电商系统来说,还存在着品牌,型号,类目,颜色等更细粒度的相关性,为了能对系统具有更好的相关性控制能力,在向量召回的后面加入了相关性控制模块,具体如下图所示:

简单来说,相关性控制模块就是一个布尔匹配(boolean matching),结合ANN,最终的表达式为:(ANN results) and (Brand: Adidas) and (Category: shoes)。单独的相关性控制模块具有很好的相关性控制能力,方便对系统的维护。
4. 总结
阿里的模型相对而言是相当复杂的,里面涉及到了大量的attention的计算,这会给在线任务带来巨大的压力。从原理上来说,低一点是对Query进行多粒度的分析,试图能够挖掘多粒度的语义信息。第二点是用户行为的挖掘,相当的复杂了。第三点是对相关性的控制,设立了独立的模块用于控制相关性。其他的如样本的选择,softmax中的温度参数等都差不太多。除了上述的重点分析意外,还有几点更多的思考:
- query侧进行了多粒度的语义分析,但item侧相对就简单了很多,这个对相关性的建模是不太友好的;
- 在MGDSPR中,个性化占据了很大的计算量,但是个性化是建立在召回充足的情况下的,这部分在我们的实际使用中是可以选择性使用的。
参考文献
[1] Li S, Lv F, Jin T, et al. Embedding-based product retrieval in taobao search[C]//Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021: 3181-3189.