【数据库原理 | MySQL】一文打通 DDL语句

♂️ 个人主页: @计算机魔术师
作者简介:CSDN内容合伙人,全栈领域优质创作者。
书接上文介绍了数据库的前世今生,本文讲解SQL语句中的DDL语句
文章目录
- 二、SQL
-
- 2.1 SQL通用语法
- 2.2 SQL的分类
- 三、 SQL之DDL
-
- 3.1 数据库操作
-
- 1)查询所有数据库
- 2) 查询当前数据库(select等用法)
- 3)查询创建数据库的建库语句
- 4)创建数据库
- 5)删除数据库
- 6)切换数据库
- 3.2 表操作
-
- 3.2.1 查询创建
-
- 1)查询数据库所有表
- 2)查看表结构
- 3) 查询指定表的建表语句
- 4)创建表结构
- 3.2.2 表字段的数据类型
-
- 1) 数值类型
- 2)字符类型
- 3) 时间类型
- 3.2.3 表操作-修改
- 3.2.3 表操作-删除
- 个人总结(选读*)
二、SQL
SQL编程语言是对关系型数据库操作的一套统一标准的语言,全程:Structed Query Language,结构化查询语言
2.1 SQL通用语法
- SQL语句可以单行书写,也可以多行书写,以分号结尾
- SQL语句可以用空格/缩进来增强语句可读性
- MySQL数据库的语句不分大小写,使用关键字建议使用大写
- 注释:
单行注释 :--#
多行注释/* */
2.2 SQL的分类
我们对SQL功能进行分类,主要分为四类
- DDL(Defined) DML(Manipulation) DQL(Query) DCL(Contrl)
| 分类 | 全称 | 作用 |
|---|---|---|
| DDL | Data Defined Language | 数据库定义语言,用于定义数据库对象(数据库,表,数据字段) |
| DML | Data Manipulation Language | 数据库操作语言,对数据库表中数据进行增删改查 |
| DQL | Data Query Language | 数据库查询语言,用于查询数据库表的记录 |
| DCL | Data Contrl Language | 数据库控制语言,用来创建数据库用户,控制数据库的访问权限。 |
三、 SQL之DDL
Data Definition Language,数据定义语言,用来定义数据库对象(数据库,表,字段) 。
3.1 数据库操作
1)查询所有数据库
show databases;

2) 查询当前数据库(select等用法)
select在其他编程语言类似于write可以用于打印字符串、数字、数学表达式结果等
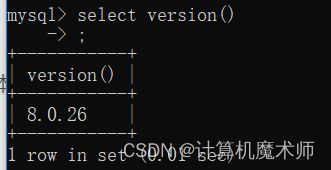
- 查看MySQL版本
select version(); # version() 函数 返回版本号,select输出该字符串
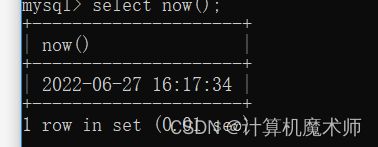
- 输出当前时间
select now(); # now()
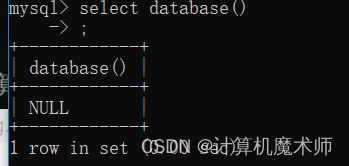
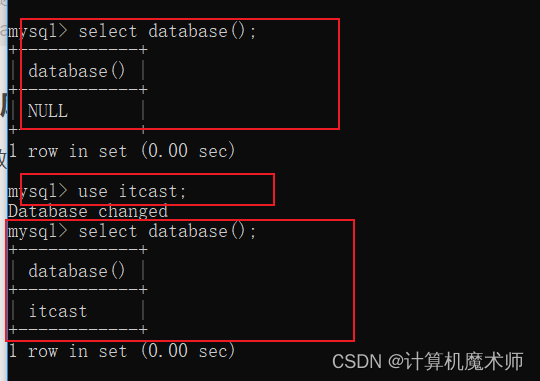
- 查看当前数据库
select database(); # database() 不接受任何参数,返回默认或当前数据库的名称,没有则返回 NULL
关于select更多操作(点击链接跳转)
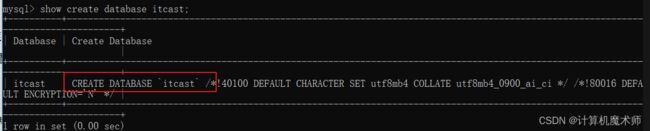
3)查询创建数据库的建库语句
该语句一般很少用到
show create table 表名;
4)创建数据库
create database [if not exists] 数据库名 [default charset utf8] [collate 排序规则];
- 案例: 创建一个数据库 命名为:
myDatabase, 使用字符集 utf8mb4(这里的utf8mb4是四个字节的因为utf8中文是三个字节,且不能敲utf-8mb4,会报错)
由于创建同名数据库会报错,我们往往添加
if not exists语句判断是否以及存在同名
- 实现代码
create database if not exists myDatabase charset utf8mb4

5)删除数据库
drop database [if exists] 数据库名;
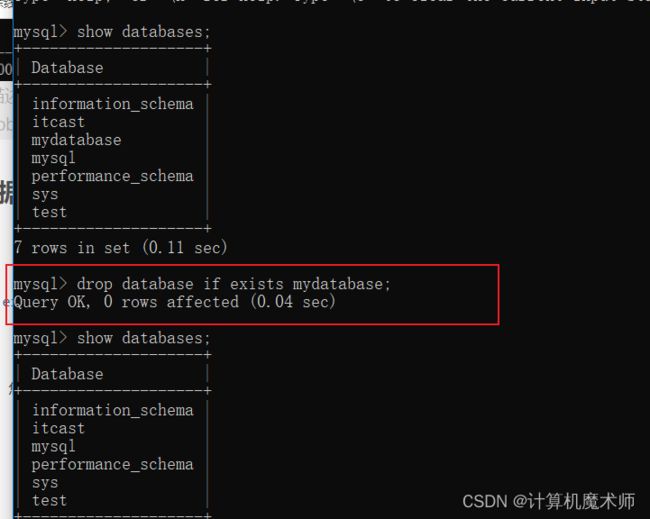
6)切换数据库
如果想要操作一个数据库中的表,则需要切换到该数据库,不然是无法操作的
use 数据库名;
可以看到当前数据库成功切换
3.2 表操作
3.2.1 查询创建
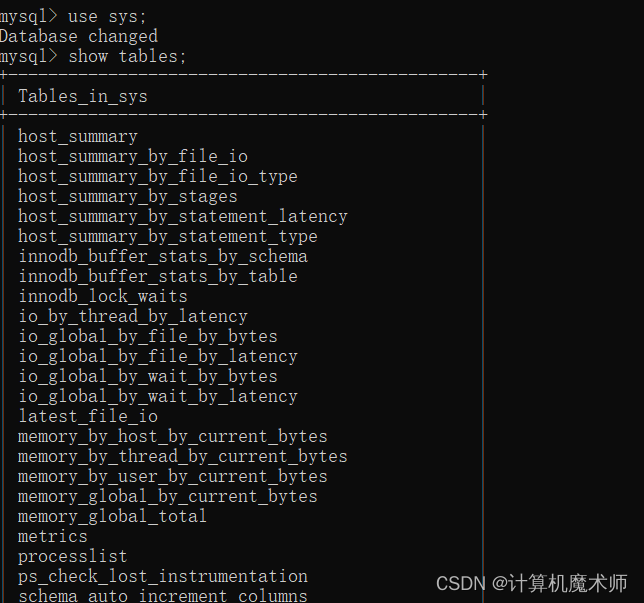
1)查询数据库所有表
show tables;
我们切换到系统数据库sys查看表
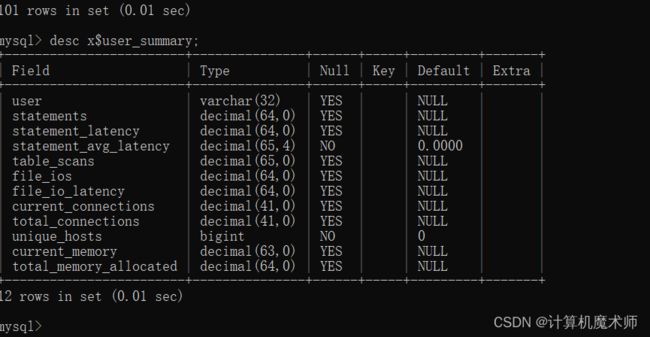
2)查看表结构
descent(n. 下降)
desc table 表名;
作用:
| 查看表的字段 | 字段类型 | 是否可为NULL | 是否默认存在默认值 | … |
|---|
3) 查询指定表的建表语句
show create table 表名;
作用(主要是查看建表语句):
有部分参数建表时并未指定也能查询到,如存贮引擎,数据集等(因为这些都是数据库的默认值)

4)创建表结构
一个二维表基本结构就是
| 字段(相当于表格中的列头) | 字段类型 |
|---|
注意!!: 最后一个字段没有逗号
create table 表名(
字段1 字段1类型 [comment 字段注释],
字段2 字段2类型 [comment 字段注释],
字段3 字段3类型 [comment 字段注释],
字段4 字段4类型 [comment 字段注释],
...
字段n 字段n类型 [comment 字段注释]
)[comment 表的注释]
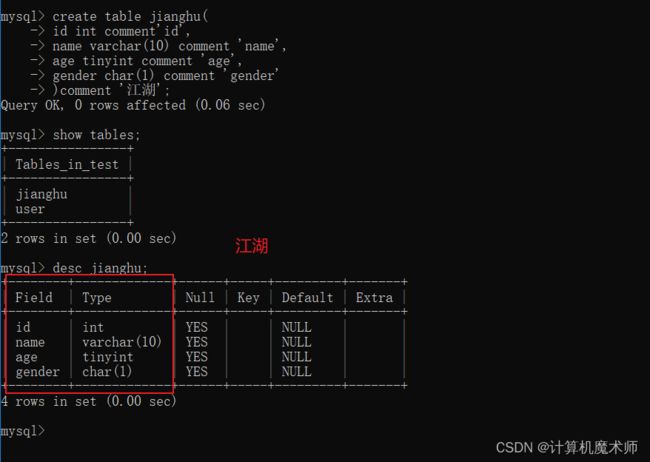
例如:建立如下表

- 代码
create table rivers_and_lakes(
id int comment "id",
name varchar(10) comment "name",
age tinyint comment "age",
gender char(1) comment "gender"
)comment "江湖";
实际中在表中,很少用男,女来存贮性别,一般都是用0,1,节省内存。
3.2.2 表字段的数据类型
在上述创建表语句,我们用到了varchar,tinyint等,那么表究竟有哪些数据类型呢?
1) 数值类型
| 类型 | 字节大小 | 有符号(signed)范围 | 无符号(unsigned)范围 | 描述 |
|---|---|---|---|---|
| tinyInt | 1bytes | -128~127 | 0~255 | 小整数值 |
| smallInt | 2bytes | -32768~32767 | 0~65535 | 大整数值 |
| mediumInt | 3bytes | -8388608,8388607 | 0,16777215 | 大整数值 |
| int/integer | 4bytes | -2147483648, 2147483647 | 0,4294967295 | 大整数值 |
| bigInt | 8bytes | − 2 63 , 2 63 − 1 -2^{63} ,2^{63}-1 −263,263−1 | 0 , 2 64 − 1 0,2^{64}-1 0,264−1 | 大整数值 |
| float | 4bytes | -3.402823466 E+38, 3.402823466351 E+38 | 0 和 (1.175494351 E- 38,3.402823466 E+38) | 单精度浮点数值 |
| double | 8bytes | -1.7976931348623157 E+308, 1.7976931348623157 E+308 | 0 和 (2.2250738585072014 E-308, 1.7976931348623157 E+308) | 双精度浮点数值 |
| decimal(十进制,小数) | 依赖于M(精度)和D(标度)的 值 | 小数值(精 确定点数) |
精度是指数字长度标度是小数位如:123.45精度为5 标度为2|依赖于M(精度)和D(标度) 的值
其实可以看到无符号正数范围是有符号正数范围的两倍,是由于在二进制中无符号将第一个二进制数作为大小,幂加一。
- 可以看到int分为了五份,从
1bytes到8bytes, 分得这么细的原因显然是为了节省空间,数据库在面对大型数据才不会太浪费空间
2)字符类型
| 类型 | 字节大小 | 描述 |
|---|---|---|
| char(重要) | 0-255 bytes | 定长字符串(需要指定长度) |
| varchar(重要) | 0-65535 bytes | 变长字符串(需要指定长度) |
| tinyBlob | 0-255 bytes | 不超过255个字符的二进制数据 |
| tinyText | 0-255 bytes | 短文本字符串 |
| blob | 0-65 535 bytes | 二进制形式的长文本数据 |
| text | 0-65 535 bytes | 长文本数据 |
| mediumBlob | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| mediumText | 0-16 777 215 bytes | 中等长度文本数据 |
| longBlob | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| longText | 0-4 294 967 295 bytes | 极大文本数据 |
3) 时间类型
| 类型 | 字节大小 | 范围 | 格式 | 描述 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | -838:59:59 至 838:59:59 | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901 至 2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00 至9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:01 至2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值,时间戳 |
3.2.3 表操作-修改
1). 添加字段
ALTER TABLE 表名 ADD 字段名 类型 (长度) [ COMMENT 注释 ] [ 约束 ];
2). 修改数据类型
ALTER TABLE 表名 MODIFY 字段名 新数据类型 (长度);
3). 修改字段名和字段类型
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型 (长度) [ COMMENT 注释 ] [ 约束 ];
4). 删除字段
ALTER TABLE 表名 DROP 字段名;
5). 修改表名
ALTER TABLE 表名 RENAME TO 新表名;
3.2.3 表操作-删除
1). 删除表
DROP TABLE [ IF EXISTS ] 表名;
2). 删除指定表, 并重新创建表(相当于清空数据)
TRUNCATE TABLE 表名;
个人总结(选读*)
在以上的对数据库或者表操作中,方法其实都是有规律的,总结规律如下
动作 + 类 + 对象 [附加条件]
如:
- 查询所有数据库 & 查询所有表
数据库: show databases;
表: show tables;
- 创建数据库
create database 数据库名称;
create table 表名称
等等诸如此类,都是比较语义化的代码