FlyAI资讯:关于Transformer,那些的你不知道的事

摘要:基于Transformer的架构主要用于建模语言理解任务,它避免了在神经网络中使用递归,而是完全依赖于self-attention机制来绘制输入和输出之间的全局依赖关系。
人工智能学习离不开实践的验证,推荐大家可以多在FlyAI-AI竞赛服务平台多参加训练和竞赛,以此来提升自己的能力。FlyAI是为AI开发者提供数据竞赛并支持GPU离线训练的一站式服务平台。每周免费提供项目开源算法样例,支持算法能力变现以及快速的迭代算法模型。
引言
本博客主要是本人在学习 Transformer 时的「所遇、所思、所解」,通过以 「十六连弹」 的方式帮助大家更好的理解该问题。
十六连弹
为什么要有 Transformer?
Transformer 作用是什么?
Transformer 整体结构怎么样?
Transformer-encoder 结构怎么样?
Transformer-decoder 结构怎么样?
传统 attention 是什么?
self-attention 长怎么样?
self-attention 如何解决长距离依赖问题?
self-attention 如何并行化?
multi-head attention 怎么解?
为什么要 加入 position embedding ?
为什么要 加入 残差模块?
Layer normalization。Normalization 是什么?
什么是 Mask?
Transformer 存在问题?
Transformer 怎么 Coding?
问题解答
3.1 为什么要有 Transformer?
为什么要有 Transformer? 首先需要知道在 Transformer 之前都有哪些技术,这些技术所存在的问题:
RNN:能够捕获长距离依赖信息,但是无法并行;
CNN: 能够并行,无法捕获长距离依赖信息(需要通过层叠 or 扩张卷积核 来 增大感受野);
传统 Attention
方法:基于源端和目标端的隐向量计算Attention,
结果:源端每个词与目标端每个词间的依赖关系 【源端->目标端】
问题:忽略了 远端或目标端 词与词间 的依赖关系
3.2 Transformer 作用是什么?
基于Transformer的架构主要用于建模语言理解任务,它避免了在神经网络中使用递归,而是完全依赖于self-attention机制来绘制输入和输出之间的全局依赖关系。
3.3 Transformer 整体结构怎么样?
整体结构
Transformer 整体结构:
encoder-decoder 结构
具体介绍:
左边是一个 Encoder;
右边是一个 Decoder;
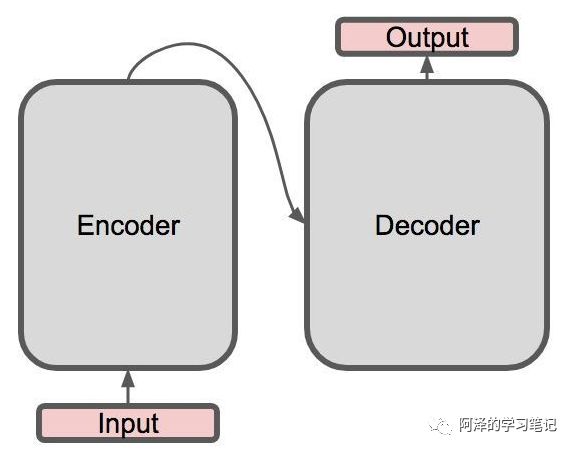
整体结构放大一点
从上一张 Transformer 结构图,可以知道 Transformer 是一个 encoder-decoder 结构,但是 encoder 和 decoder 又包含什么内容呢?
Encoder 结构:内部包含6层小encoder 每一层里面有2个子层;
Decoder 结构:内部也是包含6层小decoder ,每一层里面有3个子层
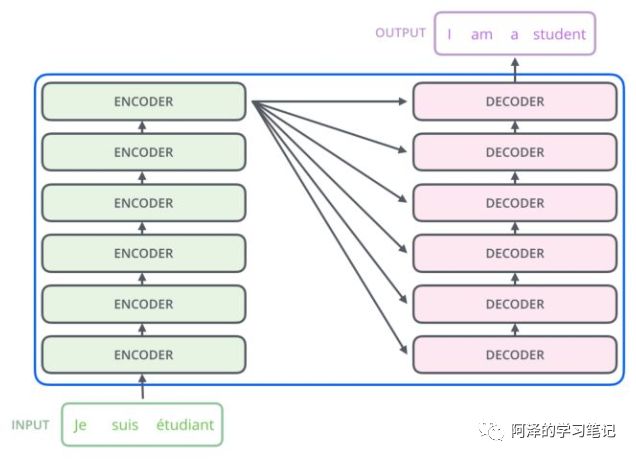
整体结构再放大一点
其中上图中每一层的内部结构如下图所求。
上图左边的每一层encoder都是下图左边的结构;
上图右边的每一层的decoder都是下图右边的结构;
具体内容,后面会逐一介绍。
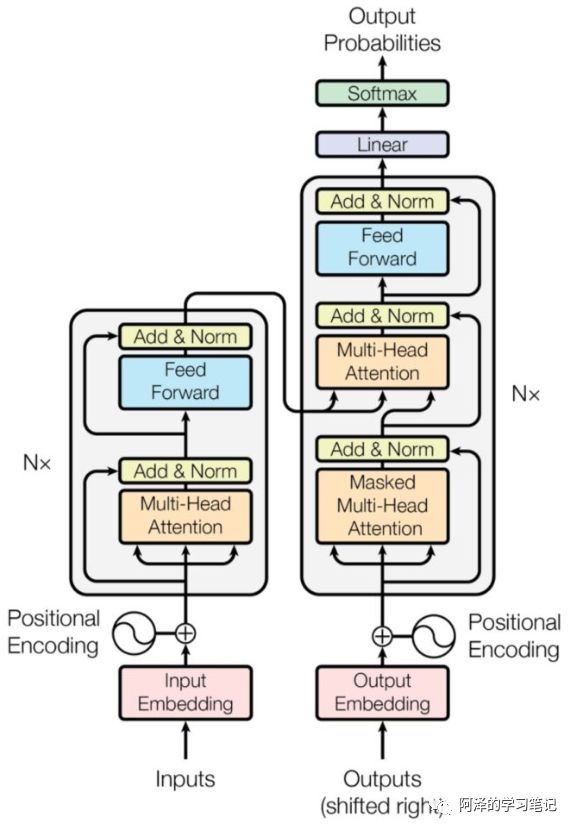
3.4 Transformer-encoder 结构怎么样?


举例说明(假设序列长度固定,如100,如输入的序列是“我爱中国”):
首先需要 「encoding」:将词映射成一个数字,encoding 后,由于序列不足固定长度,因此需要padding。然后输入 embedding 层,假设 embedding 的维度是128,则输入的序列维度就是100*128;
接着是 「Position encodding」,论文中是直接将每个位置通过cos-sin函数进行映射。这部分不需要在网络中进行训练,因为它是固定。但现在很多论文是将这块也embedding,如bert的模型,至于是encoding还是embedding可取决于语料的大小,语料足够大就用embedding。将位置信息也映射到128维与上一步的embedding相加,输出100*128
经过「self-attention层」:假设v的向量最后一维是64维(假设没有多头),该部分输出100*64;
经过残差网络:即序列的embedding向量与上一步self-attention的向量加总;
经过 「layer-norm」:原因有两点:首先由于在self-attention里面更好操作而已;其次真实序列的长度一直在变化;
经过 「前馈网络」:其目的是增加非线性的表达能力,毕竟之前的结构基本都是简单的矩阵乘法。若前馈网络的隐向量是512维,则结构最后输出100*512;
3.5 Transformer-decoder 结构怎么样?
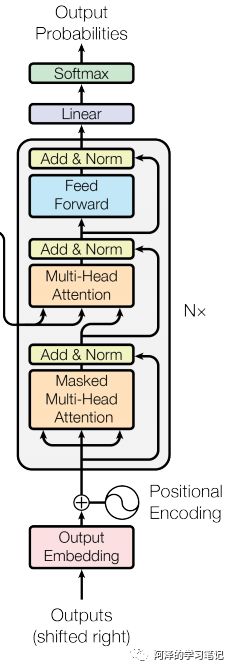
特点:与 encoder 类似
组成结构介绍
masked 层:其目的确保了位置 i 的预测仅依赖于小于 i 的位置处的已知输出;
Linear layer:其目的是将由解码器堆栈产生的向量投影到一个更大的向量中,称为对数向量。这个向量对应着模型的输出词汇表;向量中的每个值,对应着词汇表中每个单词的得分;
softmax层:这些分数转换为概率(所有正数,都加起来为1.0)。选择具有较高概率的单元,并且将与其相关联的单词作为该时间步的输出
3.6 传统 attention 是什么?
注意力机制是什么呢?
就是将精力集中于某一个点上
举个例子:你在超市买东西,突然一个美女从你身边走过,这个时候你会做什么呢?没错,就是将视线【也就是注意力】集中于这个美女身上,而周围环境怎么样,你都不关注。
思路
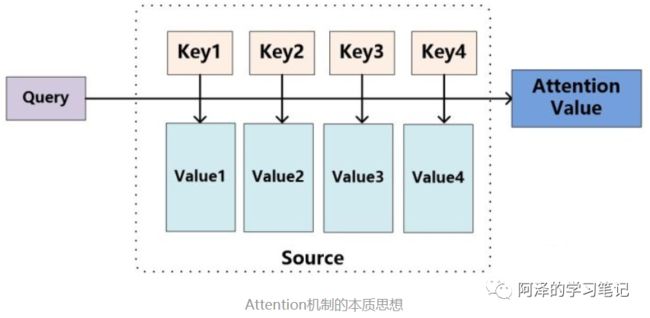
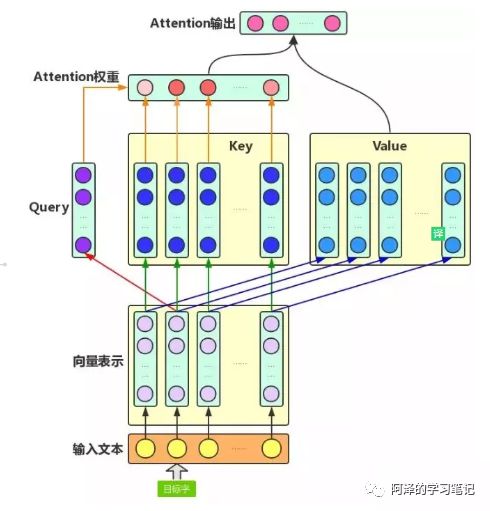
输入 给定 Target 中某个 query;
计算权值 Score:计算 query 和 各个 Key 的相似度或相关性,得到每个 Key 对应 value 的权值系数;
对权值 Score 和 value 进行加权求和
核心:
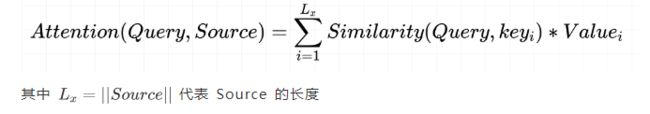
概念:
attention 的核心 就是从 大量信息中 筛选出少量的 重要信息;
具体操作:每个 value 的 权值系数,代表其重要度;



step 1:计算权值系数
step 2: softmax 归一化
step 3: 加权求和
存在问题
忽略了源端或目标端词与词间的依赖关系【以上面栗子为例,就是把注意力集中于美女身上,而没看自己周围环境,结果可能就扑街了!】
3.7 self-attention 长怎么样?
动机
CNN 所存在的长距离依赖问题;
RNN 所存在的无法并行化问题【虽然能够在一定长度上缓解 长距离依赖问题】;
传统 Attention
方法:基于源端和目标端的隐向量计算Attention,
结果:源端每个词与目标端每个词间的依赖关系 【源端->目标端】
问题:忽略了 远端或目标端 词与词间 的依赖关系
核心思想:self-attention的结构在计算每个token时,总是会考虑整个序列其他token的表达;
举例:“我爱中国”这个序列,在计算"我"这个词的时候,不但会考虑词本身的embedding,也同时会考虑其他词对这个词的影响
目的:学习句子内部的词依赖关系,捕获句子的内部结构。
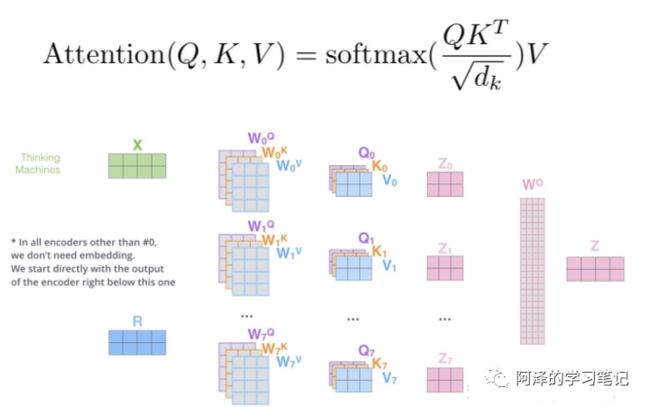

举例
答案就是文章中的Q,K,V,这三个向量都可以表示"我"这个词,但每个向量的作用并不一样,Q 代表 query,当计算"我"这个词时,它就能代表"我"去和其他词的 K 进行点乘计算其他词对这个词的重要性,所以此时其他词(包括自己)使用 K 也就是 key 代表自己,当计算完点乘后,我们只是得到了每个词对“我”这个词的权重,需要再乘以一个其他词(包括自己)的向量,也就是V(value),才完成"我"这个词的计算,同时也是完成了用其他词来表征"我"的一个过程
优点
捕获源端和目标端词与词间的依赖关系
捕获源端或目标端自身词与词间的依赖关系
3.8 self-attention 如何解决长距离依赖问题?
引言:
长距离依赖问题 是什么呢?
为什么 CNN 和 RNN 无法解决长距离依赖问题?
之前提出过哪些解决方法?
self-attention 是如何 解决 长距离依赖问题的呢?
在上一个问题中,我们提到 CNN 和 RNN 在处理长序列时,都存在 长距离依赖问题,那么你是否会有这样 几个问题:

之前提出过哪些解决方法?
增加网络的层数:通过一个深层网络来获取远距离的信息交互
使用全连接网络:通过全连接的方法对长距离建模;但这样会产生两个问题:1.无法处理变长的输入序列;2.不同的输入长度,其连接权重的大小也是不同的;
引言:那么之前主要采用什么方法解决问题呢?
解决方法:


3.9 self-attention 如何并行化?
引言:在上一个问题中,我们主要讨论了 CNN 和 RNN 在处理长序列时,都存在 长距离依赖问题,以及 Transformer 是 如何解决 长距离依赖问题,但是对于 RNN ,还存在另外一个问题:无法并行化问题
那么,Transformer 是如何进行并行化的呢?


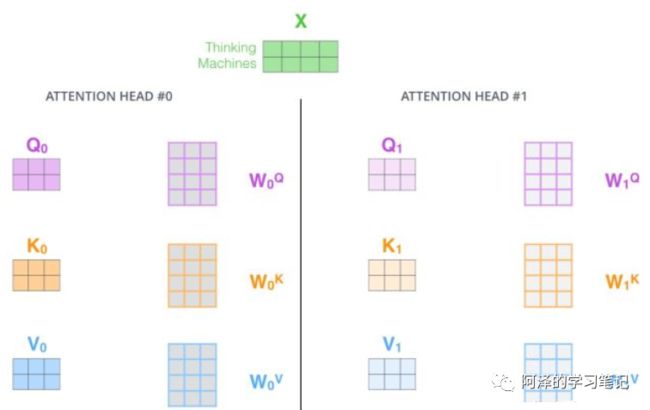
step 2 : 每组 分别 进行 self-attention;
step 3:
每次self-attention都会得到一个 Z 矩阵,把每个 Z 矩阵拼接起来,
再乘以一个Wo矩阵,
得到一个最终的矩阵,即 multi-head Attention 的结果;
问题:多个 self-attention 会得到 多个 矩阵,但是前馈神经网络没法输入8个矩阵;
目标:把8个矩阵降为1个
步骤:
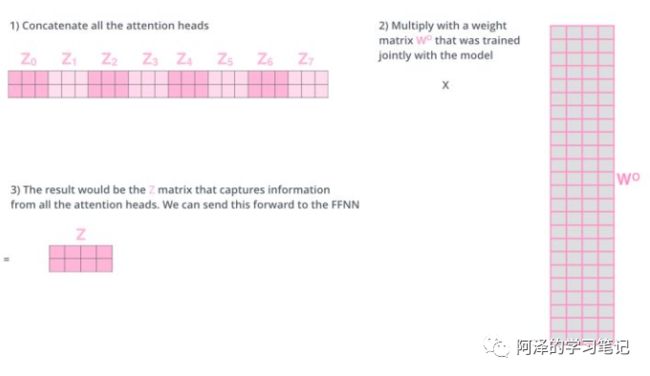
最后,让我们来看一下完整的流程:

换一种表现方式:

3.11 为什么要 加入 position embedding?
问题:
介绍:缺乏 一种 表示 输入序列中 单词顺序 的方法
说明:因为模型不包括Recurrence/Convolution,因此是无法捕捉到序列顺序信息的,例如将K、V按行进行打乱,那么Attention之后的结果是一样的。但是序列信息非常重要,代表着全局的结构,因此必须将序列的分词相对或者position信息利用起来
目的:加入词序信息,使 Attention 能够分辨出不同位置的词
思路:
在 encoder 层和 decoder 层的输入添加了一个额外的向量Positional Encoding,维度和embedding的维度一样,让模型学习到这个值
位置向量的作用:
决定当前词的位置;
计算在一个句子中不同的词之间的距离
步骤:
将每个位置编号,
然后每个编号对应一个向量,
通过将位置向量和词向量相加,就给每个词都引入了一定的位置信息。

论文的位置编码是使用三角函数去计算的。好处:
值域只有[-1,1]
容易计算相对位置。

3.12 为什么要加入残差模块?
动机:因为 transformer 堆叠了 很多层,容易 梯度消失或者梯度爆炸
3.13 Layer normalization。Normalization 是什么?
动机:因为 transformer 堆叠了 很多层,容易 梯度消失或者梯度爆炸;
原因:数据经过该网络层的作用后,不再是归一化,偏差会越来越大,所以需要将 数据 重新 做归一化处理;
目的:在数据送入激活函数之前进行normalization(归一化)之前,需要将输入的信息利用 normalization 转化成均值为0方差为1的数据,避免因输入数据落在激活函数的饱和区而出现 梯度消失或者梯度爆炸 问题
介绍:
归一化的一种方式
对每一个样本介绍均值和方差【这个与 BN 有所不同,因为他是在 批方向上 计算均值和方差】
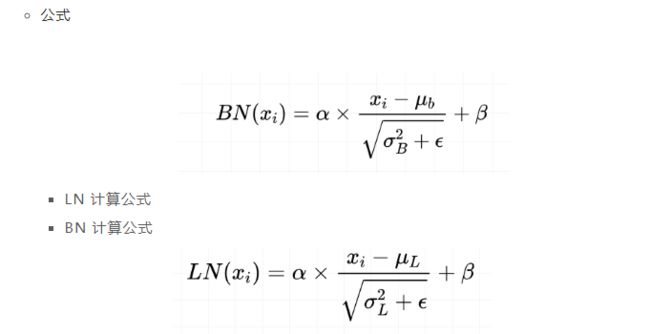
3.14 什么是 Mask?
介绍:掩盖某些值的信息,让模型信息不到该信息;
类别:padding mask and sequence mask
作用域:只作用于 decoder 的 self-attention 中
动机:不可预测性;
目标:sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
做法:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的
作用域:每一个 scaled dot-product attention 中
动机:输入句子的长度不一问题
方法:短句子:后面 采用 0 填充;长句子:只截取 左边 部分内容,其他的丢弃
原因:对于填充的位置,其所包含的信息量对于模型学习作用不大,所以 self-attention 应该 抛弃对这些位置 进行学习;
做法:在这些位置上加上 一个 非常大 的负数(负无穷),使 该位置的值经过 Softmax 后,值近似 0,利用 padding mask 标记哪些值需要做处理;
padding mask
sequence mask
注:在 decoder 的 scaled dot-product attention 中,里面的 attn_mask = padding mask + sequence mask;在 encoder 的 scaled dot-product attention 中,里面的 attn_mask = padding mask。
3.15 Transformer 存在问题?
引言
居然 Transformer 怎么厉害,那么 是否也存在不足呢?
答案: 有的
问题一:不能很好的处理超长输入问题?
处理方式一:截断句子方式(Transformer 处理方式);
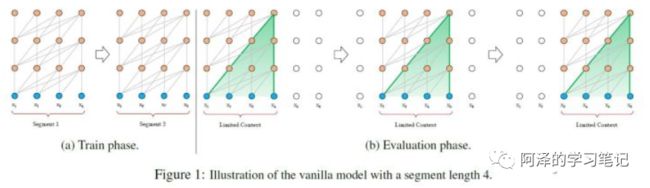
处理方式二:将句子划分为 多个 seg (Vanilla Transformer 处理方式);
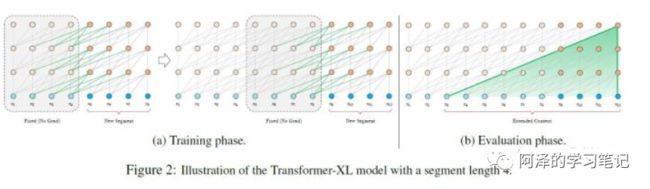
思路:将文本划分为多个segments;练的时候,对每个segment单独处理;
问题:因为 segments 之间独立训练,所以不同的token之间,最长的依赖关系,就取决于segment的长度 (如图(a));出于效率的考虑,在划分segments的时候,不考虑句子的自然边界,而是根据固定的长度来划分序列,导致分割出来的segments在语义上是不完整的 (如图(a));在预测的时候,会对固定长度的 segment 做计算,一般取最后一个位置的隐向量作为输出。为了充分利用上下文关系,在每做完一次预测之后,就对整个序列向右移动一个位置,再做一次计算,这导致计算效率非常低 (如图(b));
处理方式三:Segment-Level Recurrenc ( Transformer-XL 处理方式);
思路:在对当前segment进行处理的时候,「缓存」并利用上一个segment中所有layer的隐向量序列;上一个segment的所有隐向量序列只参与前向计算,不再进行反向传播;
介绍:Transformer 固定了句子长度;
举例:例如 在 Bert 里面,输入句子的默认长度 为 512;
对于长度长短问题,做了以下处理:短于 512:填充句子方式;长于 512:
问题二:方向信息以及相对位置 的 缺失 问题?
举例:如下图,“Inc”单词之前的词很有可能就是机构组织(ORG),“in”单词之后的词,很有可能是时间地点(TIME);并且一个实体应该是连续的单词组成,标红的“Louis Vuitton”不会和标蓝的“Inc”组成一个实体。但是原始的Transformer无法捕获这些信息。
动机:方向信息和位置信息的缺失,导致 Transformer 在 NLP 中表现性能较差,例如在 命名实体识别任务中;

解决方法:可以查看 TENER: Adapting Transformer Encoder for Name Entity Recognition 【论文后期会做总结】
问题三:缺少Recurrent Inductive Bias
动机:学习算法中Inductive Bias可以用来预测从未遇到的输入的输出(参考[10])。对于很多序列建模任务(如需要对输入的层次结构进行建模时,或者在训练和推理期间输入长度的分布不同时),Recurrent Inductive Bias至关重要【可以看论文The Importance of Being Recurrent for Modeling Hierarchical Structure】

3.16 Transformer 怎么 Coding?
最后的最后,送上 whalePaper 成员 逸神 的 【Transformer 理论源码细节详解】;
理论+实践,干活永不累!
参考资料
Transformer理论源码细节详解
论文笔记:Attention is all you need(Transformer)
深度学习-论文阅读-Transformer-20191117
Transform详解(超详细) Attention is all you need论文
目前主流的attention方法都有哪些?
transformer三部曲
Character-Level Language Modeling with Deeper Self-Attention
Transformer-XL: Unleashing the Potential of Attention Models
The Importance of Being Recurrent for Modeling Hierarchical Structure
Linformer
更多关于人工智能的文章,敬请访问:FlyAI-AI竞赛服务平台学习圈学习;同时FlyAI欢迎广大算法工程师在平台发文,获得更多原创奖励。此外,FlyAI竞赛平台提供大量数据型赛题供学习党和竞赛党参与,免费GPU试用,更多大赛经验分享;如有任何疑问可添加下方微信服务号(FlyAI小助手)进行咨询。

更多福利可添加“FlyAI小助手”获取~