Prometheus原理以及架构详细介绍
Prometheus介绍
Prometheus 是一套开源的系统监控报警框架。它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年正式发布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
什么是TSDB
TSDB(Time Series Database)时序列数据库,我们可以简单的理解为一个优化后用来处理时间序列数据的软件,并且数据中的数组是由时间进行索引的。
Prometheus作为TSDB具有以下特点:
·具有由指标名称和键/值对标识的时间序列数据的多维度数据模型。·PromQL灵活的查询语言。·不依赖分布式存储,单个服务器节点是自主的。·通过基于HTTP的pull方式采集时序数据。·可以通过中间网关(Pushgateway)进行时序列数据推送。·通过服务发现或者静态配置来发现目标服务对象。·支持多种多样的图表和界面展示,比如Grafana等。
Prometheus组成和架构
Prometheus 生态圈中包含了多个组件,其中许多组件是可选的:
·Prometheus Server:它是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储及查询。Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Sever需要对采集到的数据进行存储,Prometheus Server本身就是一个实时数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。Prometheus Server对外提供了自定义的PromQL,实现对数据的查询以及分析。另外Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据。·Exporters:Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,将其转化为Prometheus支持的格式,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可以获取到需要采集的监控数据。可以将Exporter分为2类:
直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
间接采集:原有监控目标并不直接支持Prometheus,因此需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。如:Mysql Exporter,JMX Exporter,Consul Exporter等。
·AlertManager:在Prometheus Server中支持基于Prom QL创建告警规则,如果满足Prom QL定义的规则,则会产生一条告警。当AlertManager从 Prometheus server 端接收到 alerts后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,webhook 等。·PushGateway: 主要用于短期的jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus中间网关推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。(PushGatway类似zabbix proxy)
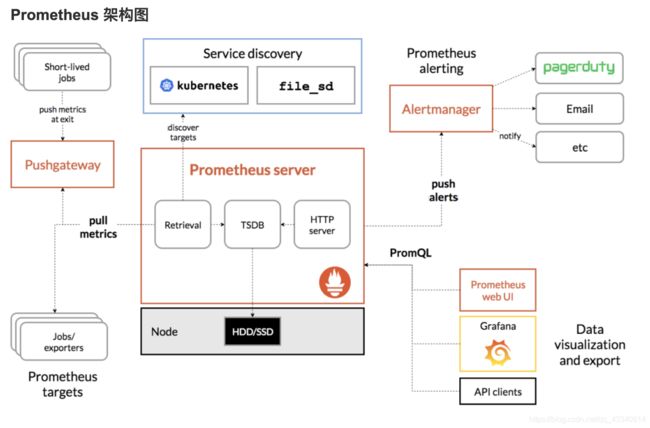
Prometheus 架构图
null
从上图可以看出,Prometheus 的主要模块包括:Prometheus server, exporters, Pushgateway, PromQL, Alertmanager 以及图形界面。Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
Prometheus工作流程
1.Prometheus server 定期从配置好的 jobs 或者 exporters 中拉取 metrics,或者从Pushgateway 拉取metrics,或者从其他的 Prometheus server 中拉 metrics。2.Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中。记录新的时间序列或者向 Alertmanager 推送警报。3.Prometheus通过PromQL和其他API可视化地展示收集的数据。Prometheus支持很多方式的图表可视化,例如Grafana、自带的Promdash以及自身提供的模版引擎等等。Prometheus还提供HTTP API的查询方式,自定义所需要的输出。
Prometheus相关概念
数据模型
Prometheus 中存储的数据为时间序列,是由 metric 的名字和一系列的标签(键值对)唯一标识的,不同的标签则代表不同的时间序列。给定度量标准名称和一组标签,通常使用此表示法标识时间序列:
{=, …}
例如:度量名称的时间序列api_http_requests_total和标签method=”POST”,并handler=”/messages”可以这样写:
api_http_requests_total{method=‘POST’, handler=’/messages’}
四种Metric类型
·Counter
一种累加的 metric,计数器可以用于记录只会增加不会减少的指标类型,比如记录:应用请求的总数,cpu使用时间,结束的任务数, 出现的错误数等。对于Counter类型的指标,只包含一个inc()方法,用于计数器+1。
·Gauge
一种常规的 metric,可以任意加减。常用于反应应用的当前状态。典型的应用如:温度,运行的 goroutines 的个数。对于Gauge指标的对象则包含两个主要的方法inc()以及dec(),用户添加或者减少计数。
·Histogram
自带buckets区间用于统计分布直方图,主要用于在指定分布范围内(Buckets)记录大小或者事件发生的次数。典型的应用如:请求持续时间,响应大小。
*Summary
Summary和Histogram非常类型相似,都可以统计事件发生的次数或者大小,以及其分布情况。Summary和Histogram都提供了对于事件的计数_count以及值的汇总_sum。因此使用_count,和_sum时间序列可以计算出相同的内容,例如http每秒的平均响应时间:rate(basename_sum[5m]) / rate(basename_count[5m])。同时Summary和Histogram都可以计算和统计样本的分布情况,比如中位数,9分位数等等。其中 0.0<= 分位数Quantiles <= 1.0。不同在于Histogram可以通过histogram_quantile函数在服务器端计算分位数。而Sumamry的分位数则是直接在客户端进行定义。因此对于分位数的计算。Summary在通过PromQL进行查询时有更好的性能表现,而Histogram则会消耗更多的资源。
Jobs 和 Instances
在Prometheus术语中,您可以scrape的目标称为instance,通常对应于单个进程。具有相同目的的instance集合,例如,为可伸缩性或可靠性而复制的流程称为Job。例如:
job: api-server instance 1: 1.2.3.4:5670 instance 2: 1.2.3.4:5671 instance 3: 5.6.7.8:5670 instance 4: 5.6.7.8:5671
当Prometheus进行scrape目标时,它会自动将job标签和instance标签附加到scrape到的时间序列中,用于识别被抓取的目标,如果这些标签中的任何一个已存在于已删除数据中,则行为取决于honor_labels配置选项。
表达式语言类型
Prometheus表达式或子表达式可以评估为一下四种类型之一:
·即时向量(Instant vector) - 包含每个时间序列单个样品的一组时间序列,共享相同的时间戳·范围向量(Range vector) - 包含一个范围内数据点的一组时间序列·标量(Scalar) - 一个简单的数字浮点值·字符串(String) - 一个简单的字符串值;当前未使用
时间序列选择器
即时向量选择
即时向量选择器允许选择一组时间序列,或者某个给定的时间戳的样本数据。下面这个例子选择了具有http_requests_total的时间序列:
http_requests_total
你可以通过附加一组标签,并用{}括起来,来进一步筛选这些时间序列。下面这个例子只选择有http_requests_total名称的、有prometheus工作标签的、有canary组标签的时间序列:
http_requests_total{job=‘prometheus’,group=‘canary’}
另外,也可以也可以将标签值反向匹配,或者对正则表达式匹配标签值。下面列举匹配操作符:
·=:选择正好相等的字符串标签·!=:选择不相等的字符串标签·=:选择匹配正则表达式的标签(或子标签)·!:选择不匹配正则表达式的标签(或子标签)
例如,选择staging、testing、development环境下的,GET之外的HTTP方法的http_requests_total的时间序列:
http_requests_total{environment=~‘staging|testing|development’,method!=‘GET’}
范围向量选择
范围向量表达式正如即时向量表达式一样运行,但是前者返回从当前时刻开始的一定时间范围的时间序列集合回来。语法是,在一个向量表达式之后添加[]来表示时间范围,持续时间用数字表示,后接下面单元之一:
·s:seconds·m:minutes·h:hours·d:days·w:weeks·y:years
在下面这个例子中,我们选择最后5分钟的记录,metric名称为http_requests_total、作业标签为prometheus的时间序列的所有值:
http_requests_total{job=‘prometheus’}[5m]
偏移量Offset
所述offset可以改变时间为查询中的个别时刻和范围矢量偏移。例如,以下表达式返回http_requests_total相对于当前查询评估时间的过去5分钟值 :
http_requests_total offset 5m
同样适用于范围向量。这将返回http_requests_total一周前的5分钟费率 :
rate(http_requests_total[5m] offset 1w)
操作符
关于操作符的说明,请参考官网操作符说明https://prometheus.io/docs/prometheus/latest/querying/operators/
函数
关于函数的说明,请参考官网函数解释https://prometheus.io/docs/prometheus/latest/querying/functions/
Prometheus的安装
下载prometheus二进制包
$ wget https://github.com/prometheus/prometheus/releases/download/v2.9.1/prometheus-2.9.1.linux-amd64.tar.gz
解压prometheus压缩包
$ tar zxvf prometheus-2.9.1.linux-amd64.tar.gz
将prometheus放到/usr/local目录下
$ mv prometheus-2.9.1.linux-amd64 /usr/local/prometheus
验证版本
$ /usr/local/prometheus/prometheus --version prometheus, version 2.9.1 (branch: HEAD, revision: ad71f2785fc321092948e33706b04f3150eee44f) build user: root@09f919068df4 build date: 20190416-17:50:04 go version: go1.12.4
配置prometheus用户
$ groupadd prometheus$ useradd -g prometheus -s /sbin/nologin prometheus
创建prometheus数据目录
$ mkdir -p /var/lib/prometheus
创建prometheus的systemctl文件
$ cat > /usr/lib/systemd/system/prometheus.service << EOF[Unit]Description=PrometheusDocumentation=https://prometheus.io/After=network.target
[Service]Type=simpleUser=prometheusExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --storage.tsdb.path=/var/lib/prometheusRestart=on-failure
[Install]WantedBy=multi-user.targetEOF
prometheus权限配置
- prometheus主程序$ chown -R prometheus:prometheus /usr/local/prometheus/
- prometheus数据目录$ chown -R prometheus:prometheus /var/lib/prometheus/
- prometheus启动文件$ chown prometheus:prometheus /usr/lib/systemd/system/prometheus.service
启动服务并设为开机启动
$ systemctl start prometheus$ systemctl enable prometheus
Prometheus.yml配置说明
Prometheus通过命令行参数和配置文件进行配置。虽然命令行参数配置了不可变的系统参数(例如存储位置,保留在磁盘和内存中的数据量等),但配置文件定义了与抓取job及其instance相关的所有内容,以及哪些规则文件的加载。
Prometheus可以在运行时重新加载其配置。如果新配置格式不正确,则不会应用更改。它有两种方式:
·通过向prometheus进程发送SIGHUP信号·向Prometheus进程发送/-/reload的POST请求,curl -X POST http://localdns:9090/-/reload
配置文件
要指定要加载的配置文件,请使用该–config.file标志。该文件以YAML格式编写,由下面描述的方案定义。括号表示参数是可选的。对于非列表参数,该值设置为指定的默认值。
以下为一个简单的prometheus.yml示例:
-
Prometheus全局配置项global: scrape_interval: 15s # 设定抓取数据的周期,默认为1min evaluation_interval: 15s # 设定更新rules文件的周期,默认为1min scrape_timeout: 15s # 设定抓取数据的超时时间,默认为10s external_labels: # 额外的属性,会添加到拉取得数据并存到数据库中 monitor: ‘codelab_monitor’
-
Alertmanager配置alerting: alertmanagers: - static_configs: - targets: [‘localhost:9093’] # 设定alertmanager和prometheus交互的接口,即alertmanager监听的ip地址和端口
-
rule配置,首次读取默认加载,之后根据evaluation_interval设定的周期加载rule_files: - ‘alertmanager_rules.yml’ - ‘prometheus_rules.yml’
-
scrape配置scrape_configs:- job_name: ‘prometheus’ # job_name默认写入timeseries的labels中,可以用于查询使用 scrape_interval: 15s # 抓取周期,默认采用global配置 static_configs: # 静态配置 - targets: [‘localdns:9090’] # prometheus所要抓取数据的地址,即instance实例项
- job_name: ‘example-random’ static_configs: - targets: [‘localhost:8080’]
更多关于prometheus配置文件参数以及自动发现规则,请参考官方prometheus配置
https://prometheus.io/docs/prometheus/latest/configuration/configuration/
原文:
https://www.ipyker.com/2019/01/12/prometheus.html