1、简介
相当于Linux文件系统,只不过比文件系统强大
2、功能了解
数据读写
数据安全
提高性能
热备份
自动故障恢复
高可用方面支持
3、存储引擎种类(笔试)
3.1 介绍
InnoDB
MyISAM
MEMORY
ARCHIVE
FEDERATED
EXAMPLE
BLACKHOLE
MERGE
NDBCLUSTER
CSV
MySQL支持的存储引擎种类查看:
show engines;
存储引擎是作用在表上的,也就意味着,不同的表可以有不同的存储引擎类型。
PerconaDB:XtraDB
MariaDB:
TokuDB ------> zabbix
扩展:
TokuDB:insert数据比Innodb快的多,数据压缩比要Innodb高
Myrocks
3.2 简历案例(存储引擎替换)
环境: zabbix 3.2 mariaDB 5.5 centos 7.3
现象 : zabbix卡的要死 , 每隔3-4个月,都要重新搭建一遍zabbix
问题 :
1. zabbix 版本
2. 数据库版本
3. zabbix数据库500G,存在一个文件里
优化建议:
1.版本升级到5.7版本
2.存储引擎改为tokudb
3.监控数据按月份进行切割
4.关闭binlog
5.参数调整....
优化结果:
监控状态良好
为什么?
1. 原生态支持tokudb,另外经过测试环境,5.7要比5.5 版本性能 高 2-3倍
2. TokuDB:insert数据比Innodb快的多,数据压缩比要Innodb高
3.监控数据按月份进行切割,为了能够truncate每个分区表,立即释放空间
4.关闭binlog ----->减少无关日志的记录
5.参数调整...----->安全性参数关闭,提高性能
---------------------------
4、InnoDB存储引擎介绍
在MySQL5.5版本之后,默认的存储引擎,提供高可靠性和高性能。
4.1 优点
事务安全(遵从 ACID)
MVCC(Multi-Versioning Concurrency Control,多版本并发控制)
InnoDB 行级别锁定
Oracle 样式一致非锁定读取
表数据进行整理来优化基于主键的查询
支持外键引用完整性约束
大型数据卷上的最大性能
将对表的查询与不同存储引擎混合
出现故障后快速自动恢复
用于在内存中缓存数据和索引的缓冲区池
---------
4.2 笔试题
请你列举MySQL InnoDB存储优点?
请你列举 InooDB和MyIsam的区别?
InnoDB:
1、事务(Transaction)
2、MVCC(Multi-Version Concurrency Control多版本并发控制)
3、行级锁(Row-level Lock)
4、ACSR(Auto Crash Safe Recovery)自动的故障安全恢复
5、支持热备份(Hot backup)
6、Replication: Group Commit , GTID (Global Transaction ID) ,多线程(SQL Multi-Threads)
5、存储引擎查看
5.1 使用 SELECT 确认会话存储引擎
SELECT @@default_storage_engine;
5.2 存储引擎(不代表生产操作)
会话级别:
set default_storage_engine=myisam;
全局级别(仅影响新会话):
set global default_storage_engine=myisam;
重启之后,所有参数均失效.
如果要永久生效:
写入配置文件
vim /etc/my.cnf
[mysqld]
default_storage_engine=myisam
存储引擎是表级别的,每个表创建时可以指定不同的存储引擎,但是我们建议统一为innodb.
5.3 SHOW 确认每个表的存储引擎:
SHOW CREATE TABLE City\G;
SHOW TABLE STATUS LIKE 'CountryLanguage'\G
5.4 INFORMATION_SCHEMA 确认每个表的存储引擎
Master [world]>select table_schema,table_name ,engine from information_schema.tables where engine='innodb';
Master [world]>show table status;
Master [world]>show create table city;
5.5 修改一个表的存储引擎
db01 [oldboy]>alter table t1 engine innodb;
注意:此命令我们经常使用他,进行innodb表的碎片整理
5.6 扩展:如何批量修改
需求:将zabbix库中的所有表,innodb替换为tokudb
select concat("alter table zabbix.",table_name," engine tokudb;") from
information_schema.tables where table_schema='zabbix' into outfile '/tmp/tokudb.sql';
注:
此命令既可以修改存储引擎类型,也可以自动分析整理innodb表的随便,避开业务繁忙期.
alter table t1 engine innodb;
怎么判断有大量的碎片?
提示:表真实的空间占用和磁盘的ibd文件比较
(1) 真正占用空间大小
SELECT table_schema,SUM(AVG_ROW_LENGTH * TABLE_ROWS+ INDEX_LENGTH)/1024 AS Total_KB
FROM information_schema.tables
GROUP BY table_schema;
(2) 磁盘方面查看IBD文件占用的磁盘空间
du -sh
ll -h
5.7 InnoDB与MyISAM存储引擎区别(面试题)
InnoDB支持事务,支持行级别锁,支持热备,支持自动故障恢复,MVCC
MyISAM 不支持事务,支持表级锁,支持温备份,不支持自动故障恢复和MVCC
6、InnoDB存储引擎物理存储结构
6.0 最直观的存储方式(/data/mysql/data)
ibdata1:系统元数据表,undo表空间等数据 **********
ib_logfile0 ~ ib_logfile1: REDO日志文件,事务日志文件。
ibtmp1: 临时表空间磁盘位置,存储临时表
frm:存储表的列信息 *********
ibd:表的数据行和索引 *********
6.1 表空间(Tablespace)
6.1.1、共享表空间
需要将所有数据存储到同一个表空间中 ,管理比较混乱
5.5版本出现的管理模式,也是默认的管理模式。
5.6版本以后,共享表空间保留,只用来存储,系统表相关数据,undo,临时表。
6.1.2 共享表空间设置
共享表空间设置(在搭建MySQL时,初始化数据之前设置到参数文件中)
select @@innodb_file_per_table; 查看表空间,0为共享表空间,1为独立表空间
5.6以后贡献表空间只存系统元数据以及undo表空间等数据
8.0版本以后 只存系统元数据,undo也被独立出来了
innodb_data_file_path=ibdata1:512M:ibdata2:512M:autoextend
6.1.3 独立表空间
从5.6,默认表空间不再使用共享表空间,替换为独立表空间。
主要存储的是用户数据
存储特点为:一个表一个ibd文件,存储数据行以及索引信息
基本表结构元数据存储:
xxx.frm
最终结论:
元数据 数据行+索引
mysql表数据 =(ibdataX+frm)+ibd(段、区、页)
DDL DML+DQL
MySQL的存储引擎日志:
Redo Log: ib_logfile0 ib_logfile1,重做日志
Undo Log: ibdata1 ibdata2(存储在共享表空间中),回滚日志
临时表:ibtmp1,在做join union操作产生临时数据,用完就自动
6.1.4 独立表空间设置问题
db01 [(none)]>select @@innodb_file_per_table;
+-------------------------+
| @@innodb_file_per_table |
+-------------------------+
| 1 |
+-------------------------+
alter table city dicard tablespace; 查出city表中的idb文件。(表的数据行和索引)
alter table city import tablespace; 导入
------
6.1.5 真实的学生案例
开发用户
jira(bug追踪) 、 confluence(内部知识库) ------>LNMT
联想服务器(IBM)
磁盘500G 没有raid
centos 6.8
mysql 5.6.33 innodb引擎 独立表空间
备份没有,日志也没开
------------------
编译→制作rpm
/usr/bin/mysql
/var/lib/mysql
confulence jira
所有软件和数据都在"/"
------------
断电了,启动完成后“/” 只读
fsck 重启
启动mysql启动不了。
结果:confulence库在 , jira库不见了
------------
求助:
这种情况怎么恢复?
我问:
有备份没
求助:
连二进制日志都没有,没有备份,没有主从
我说:
没招了,jira需要硬盘恢复了。
求助:
1、jira问题拉倒中关村了
2、能不能暂时把confulence库先打开用着
将生产库confulence,拷贝到1:1虚拟机上/var/lib/mysql,直接访问时访问不了的
问:有没有工具能直接读取ibd
我说:我查查,最后发现没有
CREATE TABLE `t1` (
`stuid` int(11) NOT NULL,
`stuname` varchar(20) NOT NULL,
`stusex` char(1) NOT NULL,
`cardid` varchar(20) NOT NULL,
`birthday` datetime DEFAULT NULL,
`entertime` datetime DEFAULT NULL,
`address` varchar(100) DEFAULT NULL,
PRIMARY KEY (`stuid`),
KEY `idx_name` (`stuname`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
我想出一个办法来:
create table xxx
alter table confulence.t1 discard tablespace;
alter table confulence.t1 import tablespace;
虚拟机测试可行。
CREATE TABLE `city_new` (
`ID` int(11) NOT NULL AUTO_INCREMENT,
`Name` char(35) NOT NULL DEFAULT '',
`CountryCode` char(3) NOT NULL DEFAULT '',
`District` char(20) NOT NULL DEFAULT '',
`Population` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`ID`),
KEY `CountryCode` (`CountryCode`),
KEY `idx_popu` (`Population`)
) ENGINE=InnoDB AUTO_INCREMENT=4080 DEFAULT CHARSET=latin1;
面临的问题,confulence库中一共有107张表。
1、创建107和和原来一模一样的表。
他有2016年的历史库,我让他去他同时电脑上 mysqldump备份confulence库
mysqldump -uroot -ppassw0rd -B confulence --no-data >test.sql
拿到你的测试库,进行恢复
到这步为止,表结构有了。
2、表空间删除。
select concat('alter table ',table_schema,'.'table_name,' discard tablespace;') from information_schema.tables where table_schema='confluence' into outfile '/tmp/discad.sql';
source /tmp/discard.sql
执行过程中发现,有20-30个表无法成功。主外键关系
很绝望,一个表一个表分析表结构,很痛苦。
set foreign_key_checks=0 跳过外键检查。
把有问题的表表空间也删掉了。
3、拷贝生产中confulence库下的所有表的ibd文件拷贝到准备好的环境中
select concat('alter table ',table_schema,'.'table_name,' import tablespace;') from information_schema.tables where table_schema='confluence' into outfile '/tmp/discad.sql';
4、验证数据
表都可以访问了,数据挽回到了出现问题时刻的状态(2-8)
----------
故障案例模拟
(1)获得原数据库表的结构(创建语句)
<1>通过历史备份
<2>和开发一起来完成
模拟——我们直接 show create table t1;
CREATE TABLE `t1` (
`stuid` int(11) NOT NULL,
`stuname` varchar(20) NOT NULL,
`stusex` char(1) NOT NULL,
`cardid` varchar(20) NOT NULL,
`birthday` datetime DEFAULT NULL,
`entertime` datetime DEFAULT NULL,
`address` varchar(100) DEFAULT NULL,
PRIMARY KEY (`stuid`),
KEY `idx_stuname` (`stuname`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
(2)搭建一个1:1的测试数据库
mysql -S /data/3307/mysql.sock
(3)在测试库中,恢复表结构
mysql -S /data/3307/mysql.sock
create database oldboy;
CREATE TABLE `t1` (
`stuid` int(11) NOT NULL,
`stuname` varchar(20) NOT NULL,
`stusex` char(1) NOT NULL,
`cardid` varchar(20) NOT NULL,
`birthday` datetime DEFAULT NULL,
`entertime` datetime DEFAULT NULL,
`address` varchar(100) DEFAULT NULL,
PRIMARY KEY (`stuid`),
KEY `idx_stuname` (`stuname`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
(4)删除空的ibd文件
alter table t1 discard tablespace;
(5)使用源库的ibd导入
cp /usr/local/mysql/mydata/oldboy/t1.ibd /data/3307/data/oldboy/
chown -R mysql.mysql /data/*
alter table t1 import tablespace;
文件句柄
rm -rf
inode 位图索引 标记改为可覆盖状态
7、事务简介 (OLTP,在线事务处理系统)*****
事务:主要是针对DML(insert、update、delete)来进行控制的。
DML1
DML2
DML3
以上三条语句,必须同时成功,或同时失败
8、事务的ACID特性
Atomic(原子性)
所有语句作为一个单元全部成功执行或全部取消。不能出现中间状态。
Consistent(一致性)
如果数据库在事务开始时处于一致状态,则在执行该事务期间将保留一致状态。
Isolated(隔离性)
事务之间不相互影响。
Durable(持久性)
事务成功完成后,所做的所有更改都会准确地记录在数据库中。所做的更改不会丢失。
9、事务的生命周期(事务控制语句)
9.1 事务的开始
begin
说明:在5.5 以上的版本,不需要手工begin,只要你执行的是一个DML,会自动在前面加一个begin命令。
9.2 事务的结束
commit:提交事务
完成一个事务,一旦事务提交成功 ,就说明具备ACID特性了。
rollback :回滚事务
将内存中,已执行过的操作,回滚回去
9.3 自动提交策略(autocommit)
db01 [(none)]>select @@autocommit;
db01 [(none)]>set autocommit=0;
db01 [(none)]>set global autocommit=0;
注:
自动提交是否打开,一般在有事务需求的MySQL中,将其关闭
不管有没有事务需求,我们一般也都建议设置为0,可以很大程度上提高数据库性能
(1)
set autocommit=0;
set global autocommit=0;
(2)
vim /etc/my.cnf
autocommit=0
9.4 隐式提交语句
用于隐式提交的 SQL 语句:
begin
a
b
begin
SET AUTOCOMMIT = 1
导致提交的非事务语句:
DDL语句: (ALTER、CREATE 和 DROP)
DCL语句: (GRANT、REVOKE 和 SET PASSWORD)
锁定语句:(LOCK TABLES 和 UNLOCK TABLES)
导致隐式提交的语句示例:
TRUNCATE TABLE
LOAD DATA INFILE
SELECT FOR UPDATE
========================
开始事务流程:
1、检查autocommit是否为关闭状态
select @@autocommit;
或者:
show variables like 'autocommit';
2、开启事务,并结束事务
begin
delete from student where name='alexsb';
update student set name='alexsb' where name='alex';
rollback;
--------
begin
delete from student where name='alexsb';
update student set name='alexsb' where name='alex';
commit;
10. InnoDB 事务的ACID如何保证?
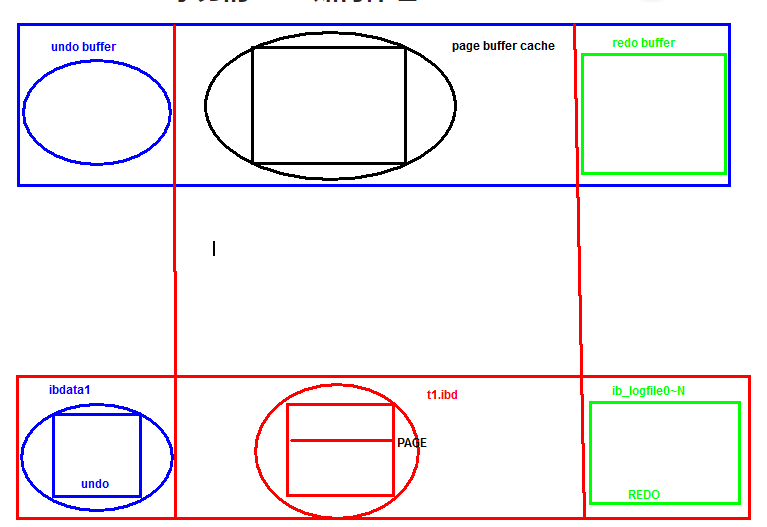
10.1 redo log
10.1.1 Redo是什么?
redo,顾名思义“重做日志”,是事务日志的一种。
10.1.2 作用是什么?
在事务ACID过程中,实现的是“D”持久化的作用。对于AC也有相应的作用
10.1.3 redo日志位置
redo的日志文件:iblogfile0 iblogfile1
10.1.4 redo buffer
redo的buffer:数据页的变化信息+数据页当时的LSN号
LSN:日志序列号 磁盘数据页、内存数据页、redo buffer、redolog
10.1.5 redo的刷新策略
commit;
刷新当前事务的redo buffer到磁盘
还会顺便将一部分redo buffer中没有提交的事务日志也刷新到磁盘
10.1.6 MySQL CSR——前滚
MySQL : 在启动时,必须保证redo日志文件和数据文件LSN必须一致,
如果不一致就会触发CSR,最终保证一致
redo 日志文件是轮询使用
11.2 undo 回滚日志
11.2.1 undo是什么?
undo,顾名思义“回滚日志”
11.2.2 作用是什么?
在事务ACID过程中,实现的是“A” 原子性的作用
另外CI也依赖于Undo
11.3 概念性的东西:
redo怎么应用的
undo怎么应用的
CSR(自动故障恢复)过程
LSN :日志序列号
TXID:事务ID
CKPT(Checkpoint)
11.4 锁
“锁”顾名思义就是锁定的意思。
“锁”的作用是什么?
在事务ACID过程中,“锁”和“隔离级别”一起来实现“I”隔离性和"C" 一致性 (redo也有参与).
悲观锁:行级锁定(行锁)
谁先操作某个数据行,就会持有<这行>的(X)锁.
乐观锁: 没有锁
11.5 隔离级别
影响到数据的读取,默认的级别是 RR模式.
RU(read uncommited) : 读未提交(脏读)
transaction_isolation=read-uncommit
事务没提交,其他事务也可以看到修改后的数据(脏页读)
此种隔离级别,会造成脏读和幻读。
RC : 读已提交
事务已提交,其他事务才可以可以看到修改后的数据(会出现幻读)
防止了脏读,会有幻读,非金融性的业务此种级别足够
RR : 可重复读
不管是事务执行前,事务执行中,事务结束后,同一个会话一定读到的是同一个数据,MySQL默认的隔离级别.必须支持事务(undo快照),必须有索引,可以防止幻读,读一致性的目的.
防止脏读和幻读,通过一致性快照实现(undo)。
S : 可串行化
12 InnoDB存储引擎核心特性-参数补充
12.1 存储引擎相关
12.1.1 查看
show engines;
show variables like 'default_storage_engine';
select @@default_storage_engine;
12.1.2 如何指定和修改存储引擎
(1) 通过参数设置默认引擎
(2) 建表的时候进行设置
(3) alter table t1 engine=innodb;
12.2. 表空间
12.2.1 共享表空间
innodb_data_file_path
一般是在初始化数据之前就设置好
例子:
innodb_data_file_path=ibdata1:512M:ibdata2:512M:autoextend
12.2.2 独立表空间
show variables like 'innodb_file_per_table';
12.3. 缓冲区池
12.3.1 查询
select @@innodb_buffer_pool_size;
show engine innodb status\G
innodb_buffer_pool_size
一般建议最多是物理内存的 75-80%
12.4. innodb_flush_log_at_trx_commit (双一标准之一)
12.4.1 作用
主要控制了innodb将log buffer中的数据写入日志文件并flush磁盘的时间点,取值分别为0、1、2三个。
12.4.2 查询
select @@innodb_flush_log_at_trx_commit;
12.4.3 参数说明:
1,每次事物的提交都会引起日志文件写入、flush磁盘的操作,确保了事务的ACID;
flush 到操作系统的文件系统缓存 fsync到物理磁盘
0,表示当事务提交时,不做日志写入操作,而是每秒钟将log buffer中的数据写入日志文件并flush磁盘一次;
2,每次事务提交引起写入日志文件的动作,但每秒钟完成一次flush磁盘操作。
12.5. Innodb_flush_method=(O_DIRECT, fdatasync)

12.5.1 作用
控制的是,log buffer 和data buffer,刷写磁盘的时候是否经过文件系统缓存
12.5.2 查看
show variables like '%innodb_flush%';
12.5.3 参数值说明
O_DIRECT :数据缓冲区写磁盘,不走OS buffer
fdatasync :日志和数据缓冲区写磁盘,都走OS buffer
O_DSYNC :日志缓冲区写磁盘,不走 OS buffer
12.5.4 使用建议
最高安全模式
innodb_flush_log_at_trx_commit=1
Innodb_flush_method=O_DIRECT
最高性能:
innodb_flush_log_at_trx_commit=0
Innodb_flush_method=fdatasync
12.6. redo日志有关的参数
innodb_log_buffer_size=16777216
innodb_log_file_size=50331648
innodb_log_files_in_group = 3
13.扩展(自己扩展,建议是官方文档。)
GAP
next-lock
RR模式(对索引进行删除时):
GAP: 间隙锁
next-lock: 下一件锁定
id(有索引)
1 2 3 4 5 6
GAP:
在对3这个值做变更时,会产生两种锁,一种是本行的行级锁,另一种会在2和4索引键上进行枷锁
next-lock:
对第六行变更时,一种是本行的行级锁,在索引末尾键进行加锁,6以后的值在这时是不能被插入的。
总之:
GAP、next lock都是为了保证RR模式下,不会出现幻读,降低隔离级别或取消索引,这两种锁都不会产生。
IX IS X S