Druid连接池引发的线上服务卡慢宕机问题
一、使用Druid背景
公司微服务产品改造上线后,在开发环境的时候,使用的是springboot默认的连接池HikariCP,为什么springboot2.0后选择的是HikariCP,可以参考博客,Springboot 2.0选择HikariCP作为默认数据库连接池的五大理由https://blog.csdn.net/liuhuiteng/article/details/10762753。
其实总结一句话就是HikariCP性能最高,可以pk掉其他所有的连接池;
而我们在对产品进行压测后发现,程序经常卡在获取数据库连接上,经查公司产品底座对连接池的大小的都没有进行调整,默认是最大是8个连接,没有人员负责连接池,随即接手处理,之后就对连接增大,后面再进一步优化sql;
做进一步的压测的时候,发现sql执行快慢情况,不能很好的监控出来,对性能调优有一定影响,当即决定切换阿里的Druid数据库连接池,并开启监控,发现真香啊;
在性能对比上,Druid还是可以的。
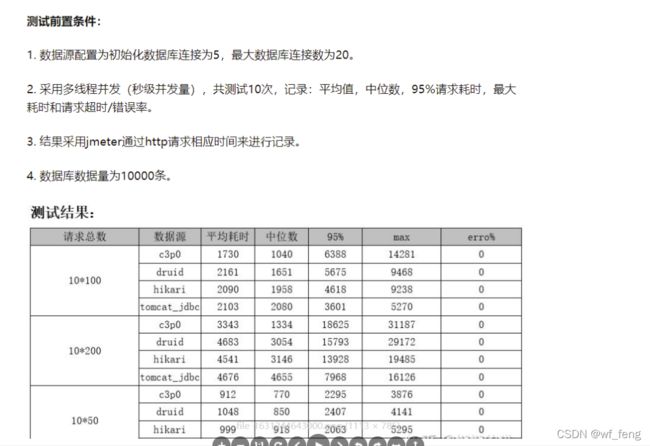
主要还是监控真的香,基于Druid强大的监控功能,有利于日常的开发工作、和线上的运维监控,同时可以基于接口自定义扩展监控;
二、问题出现及分析
1. 问题出现,快速确认问题类型
云上某服务上线没几天反馈卡慢宕机,一上午陆续几个集群节点出现问题;
随即和运维同事沟通确认应用的jvm内存正常,该服务对应的数据库实例负载正常,问题现象是某些节点正常,某些不节点不正常,当即确认为当时有问题节点应用这边阻塞导致;
问题类型,卡慢宕机无非是应用的jvm内存溢出,数据库负载高,应用线程阻塞、各种资源泄漏(如redis连接泄漏,数据库连接池泄漏)等。
2. 取日志分析问题
分析问题时间点日志,会发现很多的请求会卡在获取Druid连接池连接上,这种要反应过来,要么是池里面连接都拿去执行sql了,要么池里面的连接都泄漏了;

如何判断连接都去执行sql了?
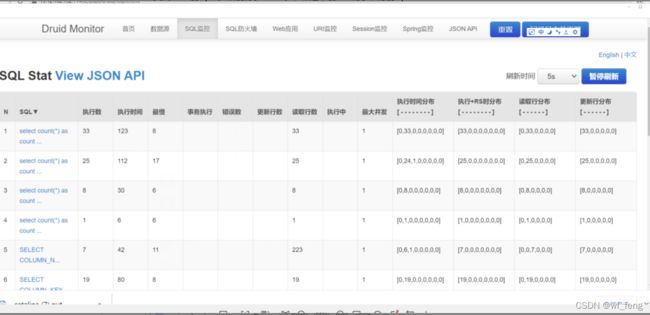
在线程快照里面找mysql相关的,从连接池里面拿完连接,当然是执行sql了。
如下图,正在执行的sql很少,那岂不是就是泄漏了?

如何判断连接泄漏了呢?
结合技术架构来看,除了Druid会去池里面的connection,业务地方取的可能性应该是极小的;
反向之,如果是连接泄漏,那按照上图为什么还有8个连接没泄漏完(有一种情况,刚刚好泄漏仅剩8个连接,而刚刚好这8个连接执行的sql较慢,或者并发请求更高,可以进一步确认);
当时直接认定没连接泄漏,然后做一步线程快照分析;
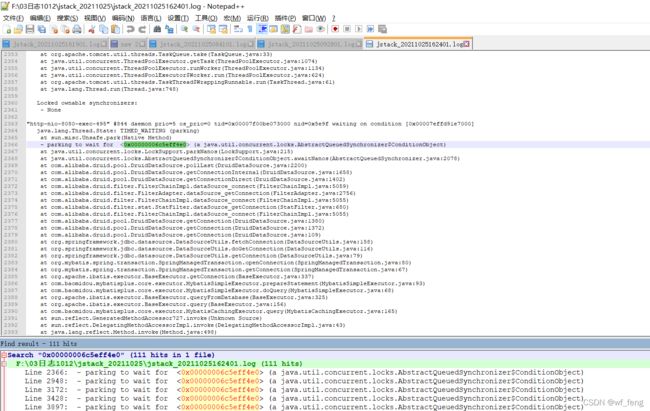
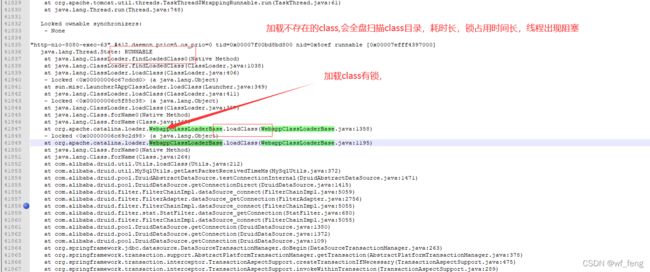
进一步分析发现,还有请求在获取Druid连接池的connection的时候,会阻塞在以下的锁上waiting to lock <0x00000006c69c35f8> (a java.lang.Object)
 进一步分析0x00000006c69c35f8锁占用问题发现,
进一步分析0x00000006c69c35f8锁占用问题发现,

这个当时我脑子是没有转过来的,什么卡在org.apache.catalina.loader.WebappClassLoaderBase.loadClass() 卡在类加载器加载class上了?为什么会卡? 没想通。。。愣是愣了几分钟;
然后又换了一个线程快照查看,如下图基本都是卡慢在同一个地方加载class

查看此处加载的class是com.mysql.jdbc.MysqlIO
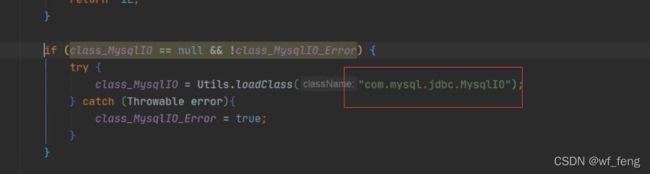
然后去确认这个卡慢宕机服务里面搜索com.mysql.jdbc.MysqlIO,确实不存在这样的class,这种查找不存在的class,肯定是慢的,即classload会遍历所有的class目录,即涉及到磁盘IO,然后对于这种druid取连接和执行sql的情况是属于并发高的场景,很容易锁阻塞;
三、验证
问题确认为druid加载不存在的class com.mysql.jdbc.MysqlIO 导致classload全盘扫描加载class目录导致的锁等待,线程阻塞问题;
如何验证loadclass慢的问题?
写一个demo,反射加载一个不存在的class,和反射加载一个存在的class即可;
可以明显对比出加载不存在的class耗时可能在几十ms(和jar包数量有关);
该服务里面为什么不存在com.mysql.jdbc.MysqlIO?
这个看包名是属于mysql驱动包的,检查项目里面使用的是8.0高驱动版本,确实是不存在的;
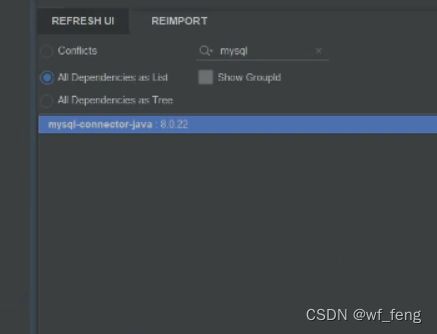
然后到maven参考拉mysql的不同版本的驱动包,确认是mysql驱动包低版本6以后就不存在了;

四、解决
拉对应版本的Druid源码,简单的看下druid源码,按照以下处理注释掉loadclass,不加载不就没问题了吗;
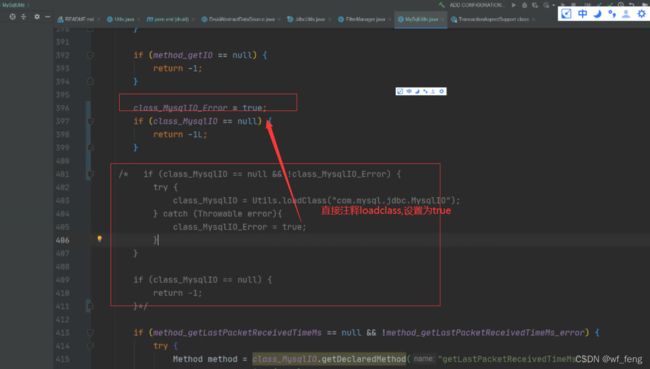
然后专门打包了一个jar包,druid-weaver.jar ,修改架构框架druid依赖为druid-weaver.jar ,上传jar到私服解决;
根本解决方案
上述直接 调整源码注释掉loadclass的逻辑,可以解决性能问题,但是某种情况下会导致获取链接不稳定。
根本解决方案是 升级版本到 druid-1.1.23
我们对比下源码:
1.1.22

1.1.23


五、后续
该服务之后就没因为druid宕机,稳定运行,由于我们线上的服务节点多达200多个,部分并发高的业务服务之后也陆续出现问题,经确认也是同问题,影响较大;
六、Druid个别参数使用建议
test-on-borrow = true, 线上建议关闭,确实是很耗性能,在我们线上生产环境,我们有监控统计获取druid获取连接检测,基本每次检查要耗时几ms,一个请求执行上百sql,就是几百ms;建议关闭为false;
然后开启test-while-idle = true,防止连接失效有问题场景;