工业界精排模型整合
参考推荐系统精排模型综述2021
整合如下,论文链接可直接点击model name跳转。
代码链接GitHub - shenweichen/DeepCTR-Torch: 【PyTorch】Easy-to-use,Modular and Extendible package of deep-learning based CTR models.
| model name | 网络构成 | 优点 |
| wide&deep | linear + DNN | 两种网络结合不但记忆性好且泛化性。 |
| deepFM | DNN + FM | 增加了低阶和高阶特征的交互。 |
| AFM | FM based attention | 为特征之间的交互的重要程度赋予权重,减弱不必要交互,使得特征交互更具灵活性。 |
| DCN | Cross + DNN | 显式高阶特征交互且交互过程中输入输出维度不变。 |
| xdeepFM | linear + CIN + DNN | 上升到vector级去除了field内bit级无关的交互。 |
| AutoInt | multi-head attention + DNN | 显式学习高阶特征交叉 |
| DIN | local activation unit + DNN | 使得用户兴趣多样化更好表达,减弱了无关用户兴趣对用户行为的影响。 |
| DIEN | GRU + (AI/A/AU)GRU + DNN | 挖掘用户潜在兴趣,增强了用户兴趣在演化过程中的相互作用。 |
ps:以上网络构成自己总结,并不是特别准确,比如local activation unit本质其实是一个dnn,只是有新的名字,仅供参考,有错请指正。优点也是自己总结的,有错指正或缺漏可以补充。
Wide & Deep Learning for Recommender Systems(2016.06)
Google
Overview
由wide部分和deep部分组成
Part 1
Wide Layer
线性模型
记忆性好
Part 2
Deep Layer
先embedding然后扔进dnn
泛化性好
最后把part1 跟 part2 的结果concat起来
Experiment
在一个实时的推荐系统Google play
评估的性能:app acquisitions / serving performance
app acquisitions
宽深模型对app store主页应用程序获取率增加了 3.9%

serving performance
采用了多线程小批量处理 服务延迟减少到了14ms
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction(2017.05)
哈尔滨工业大学 / 华为
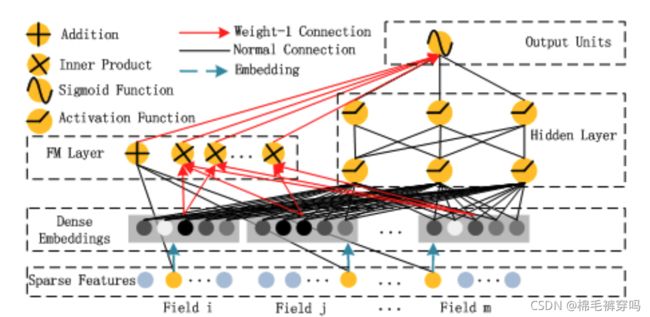
Overview
特征交互在推荐机制中非常重要
举个栗子 比如 人们常常在吃饭的时候下载food delivery app 表现了时间戳跟app目录的特征交互
再举个栗子 比如 年轻男性更喜欢 射击 和 RPG 游戏 表明了在CTR上 app目录 跟 性别 年龄的交互
而之前的Deep & Wide 网络 线性模型 缺少 特征交互。
DeepFM是 没有预训练 没有特征工程 且有高阶低阶特征交互
Part 1
FM Layer
模型把两两特征交互作为特征之间潜在向量的内积
线性模型 + 内积
![]()
Part 2
Deep Layer
同 Deep & Wide 模型 DNN侧
最后把part1 跟 part2 的结果concat起来
Experiment
Datasets
Criteo Dataset
Company Dataset
Results
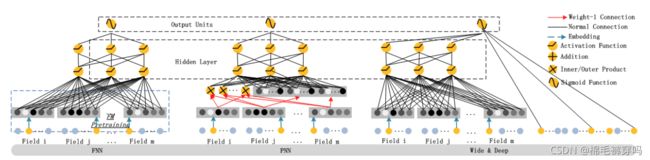
(ps:在deep&wide实验中,离线AUC ⬆️ 0.275% 就可以 线上CTR ⬆️ 3.9%

上述模型中LR为logistics regression / LR & DNN 和 FM & DNN 都是deep&wide模型中直接把wide换成LR 和 FM
其他模型如下图
Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks(2017.08)
浙江大学 / 新加坡国立大学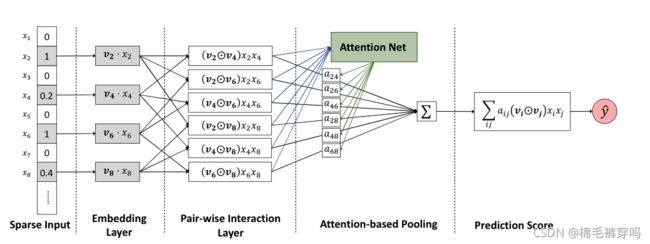
Overview
FM是在线性模型的基础上增加了二阶特征的交互,但并不是所有特征的交互都有效,无用的交互可能引入噪声,FM缺乏区分特征交互重要性的功能,于是引入了注意力机制。
Embedding Layer
普通embedding
Pair-wise Interaction Layer
二阶特征交叉层 (同FM层
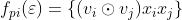
 代表两个向量元素乘积。
代表两个向量元素乘积。
Attention-based attention Layer
![]()
 为
为![]() 的attention score。为了预测通过最小化预测损失,是最直观的方法。但是很多特征交互在训练数据中没有,为了解决泛化问题,于是用了Attention layer(MLP)。
的attention score。为了预测通过最小化预测损失,是最直观的方法。但是很多特征交互在训练数据中没有,为了解决泛化问题,于是用了Attention layer(MLP)。
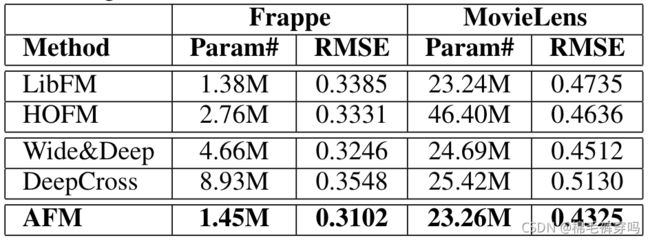
Experiment
dataset
Frappe
MovieLens :context-aware recommendation 上下文感知推荐
Results
Deep & Cross Network for Ad Click Predictions(2017.08)
斯坦福 / 谷歌
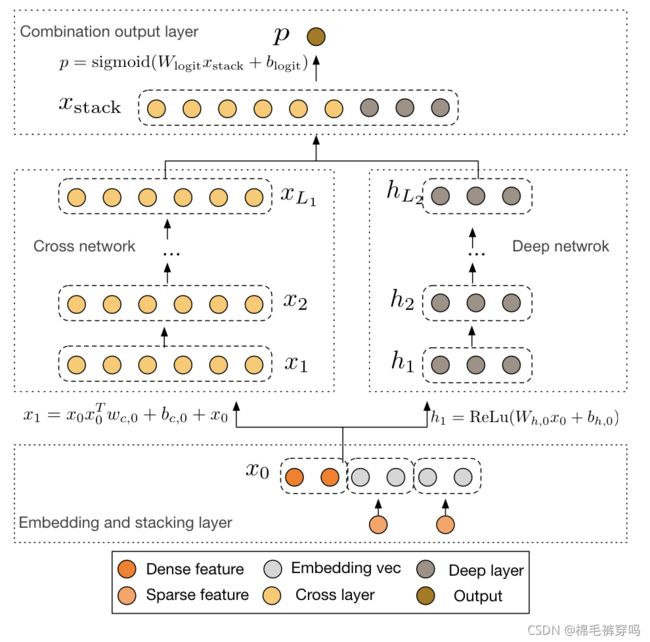 Overview
Overview
该网络结构可以显式提取高阶特征,并学习对应权重,告别了繁琐的人工叉乘。
原始特征处理
对sparse特征进行embedding,然后和dense特征concat。
Part 1
Cross network
交叉网络
![]()
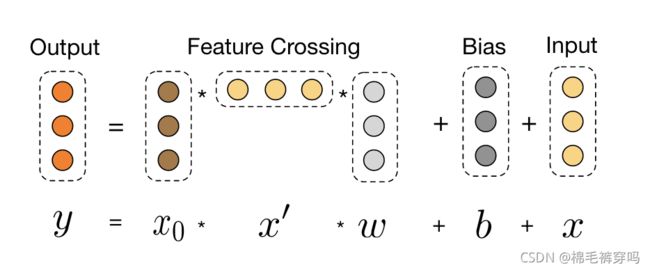
优点
1.每层神经元数相同,都等于输入的 维度d,即每层的输出输入的维度都相同。
维度d,即每层的输出输入的维度都相同。
2.受残差网络启发,在处理梯度消失的问题上,可以让网络更深。
Part 2
Deep Network
同之前的DNN
最后把part1 跟 part2 的结果concat起来
Experiment
Database
Criteo Dataset
Results
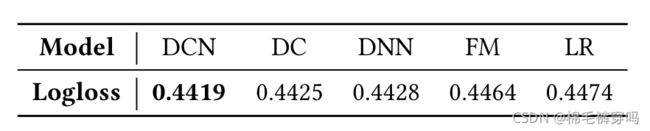 参数量上跟DNN比较
参数量上跟DNN比较

xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems(2018.05)
中国科学技术大学 / 北京邮电大学 / 微软
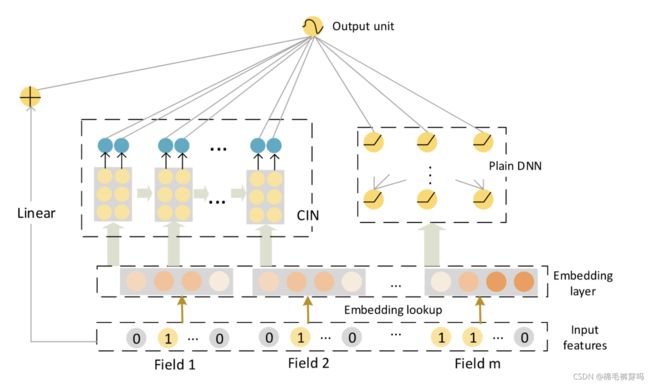
Overview
Compressed Interaction network(CIN) 和 DNN 和 线性 结合
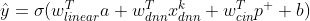
1)DCN是bit-wise级的,同一个field内进行特征交叉不含有效信息,CIN是vector-wise级别的,解决了这个问题。
2)网络的复杂性不会随着相互作用的程度指数增长
Part 1
CIN
![]()
 表示第
表示第 层embedding feature vetcor的个数。
层embedding feature vetcor的个数。
具体计算方法如下图,个人觉得有些许复杂。十分复杂。一百分吧。

在上述公式获取每层的输出,然后每层在维度上进行sum-pooling操作后获得维度的一维向量,然后将所有层获得的向量进行拼接,代表为CIN的输出。
Part 2
DNN
普通dnn
最后把linear,CIN,DNN的结果加起来。
Experiment
Dataset
Criteo Dataset(CTR)
Dianping Dataset
dianping.com 中国最大消费者评论网站。
在该网站上收集用户信息,预测用户访问餐厅的可能性。
Bing News Dataset
Bing News 微软Bing搜索引擎的一部分(为了验证模型在真实商业数据中的作用
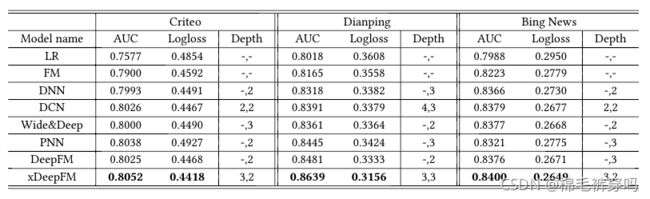
Results
AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks(2019.08)
清华大学 / 加州大学
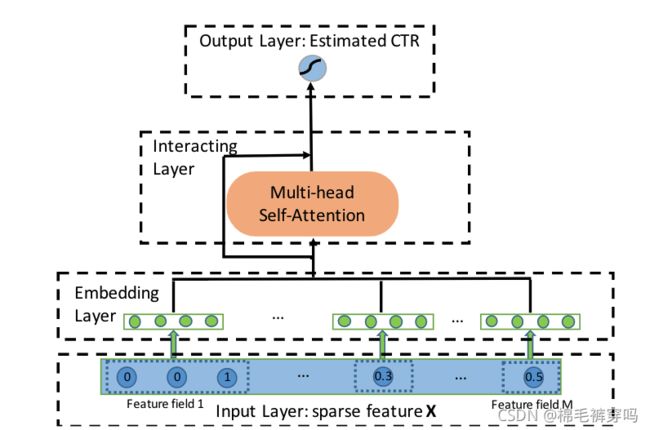
(ps:图上只是多头注意网络的部分)
Overview
显式学习高阶特征
原始特征处理
输入 ![]()

其中 是one-hot vector 如果是类别的话。
是one-hot vector 如果是类别的话。
如果是一个标量,如果是数字的话。
因为很多类别可能是multi-hot vector,于是embedding计算公式如下
![]() (q为第i个字段中的值的个数)
(q为第i个字段中的值的个数)
对于标量输入的计算
![]()
Part 1
AutoInt Layer
attention head  得到系数
得到系数![]()
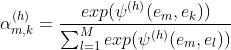
其中![]()
ps: ![]() 是head 下的特征
是head 下的特征  和它相关特征的组合
和它相关特征的组合
![]()
其中  是 concatentation operator
是 concatentation operator
![]()
Output Layer
![]()
Part 2
Dnn Layer
同上
Experiment
Dataset
Criteo Dataset(CTR)
Avazu
KDD12
MovieLens-1M
Results

Deep Interest Network for Click-Through Rate Prediction(2018.09)
阿里
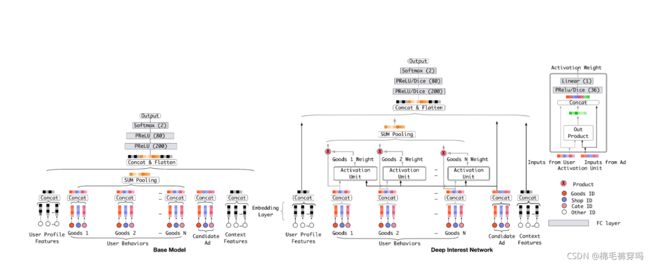
Overview
提出的网络针对的问题:
1.用户多样的兴趣被压缩成一个固定长度的向量会限制embedding&MLP的表达,即用户兴趣是多样的,但向量长度是固定的,就会影响用户兴趣多样化的发挥。
2.不是所有的用户兴趣会影响用户的行为
(比如一个女游泳运动员会点击泳镜大概率是因为买过的泳衣,而不是上星期买的鞋子)
part 1
Attention
local activation unit
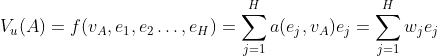
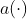 is outer product
is outer product
本质是一个DNN
输入1.user behavior embedding2. candidate item embedding 3.前俩的差4. 前俩的积
得到经过单位激活单元得到每个序列点上的权重以后,对对应的序列点embedding做乘积。
part 2
DNN
第2)步得到的embedding 和 其他的离散特征embedding 做一个concat,一起送到DNN里。
Experiment
Dataset
Amazon Dataset
MovieLens Dataset
Alibaba Dataset
Results
Deep Interest Evolution Network for Click-Through Rate Prediction(2018.09)
阿里
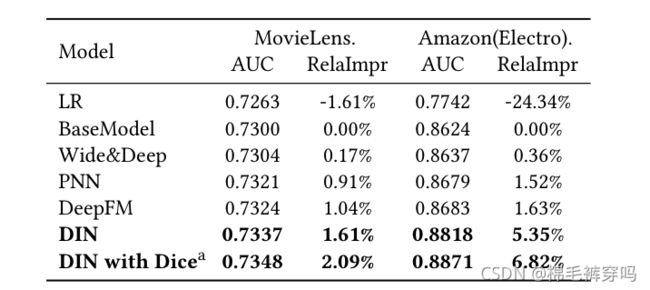
Overview
挖掘用户潜在兴趣,使用了AUGRU(增加了兴趣演化过程中兴趣的相关性,减弱了来自兴趣漂移的无关兴趣)
part 1
Interest Extractor Layer
把用户按照时间行为序列送入GRU, 让GRU学习序列之间的依赖关系。
然后计算 auxiliary loss
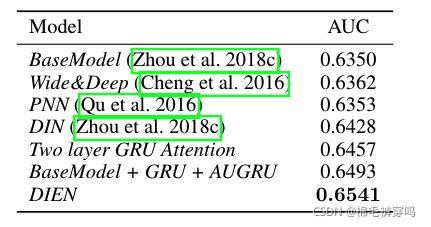
![L_{aux} = -\frac{1}{N}(\sum^N_{i=1}\sum_tlog\sigma(h_t,e_b^i[b+1])+log(1-\sigma(h_t, \hat e_b^i[t+1]))](http://img.e-com-net.com/image/info8/fa53959218d144488c280015bd9f6217.gif)
![]()
part 2
Interest Evolving Layer
因为兴趣的多样性,用户的兴趣可能会发生漂移。比如一段时间需要书,另外一个时间就需要衣服。
每个兴趣都有自己的发展过程。比如书和衣服。目的主要关注和目标项目有关的演变过程
在上一层兴趣提取层的基础上直接获得其输出然后用以下n种GRU
以下公式中的attention function如下
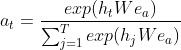
i.GRU with attentional input (AIGRU)
直接将attention的权重和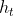 相乘作为GRU的输出。
相乘作为GRU的输出。
(attention score 可以减少无关兴趣的分数
![]()
ii.Attention based GRU(AGRU)
将从询问种提取关键信息⇒在兴趣演化过程中提取相关兴趣
减弱在兴趣演化过程中的无关兴趣
![]()
iii.GRU with attentional update gate (AUGRU)
AGRU使用attention系数来直接控制隐状态的更新,这种做法忽略了不同维度重要的区别。于是提出了改进版本AUGRU,它使用了update gate来替换了 .
.
![]()
![]()
避免了兴趣漂移带来的干扰,推动了相对兴趣的平滑性。
part 3
DNN
第2)步得到的embedding 和 其他的离散特征embedding 做一个concat,一起送到DNN里。
Experiment
Dataset
Amazon Dataset
Industrial Dataset
工业数据集是通过一个在线显示广告系统的显示和点击日志来构建的。
Results
on public dataset
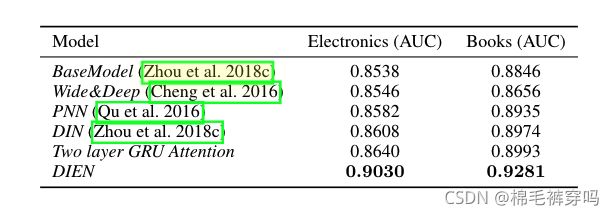
on Industrial Dataset
图均来自论文截图。