机器学习很有趣!第四章:深度学习进行人脸识别
作者:Adam Geitgey
原文:https://medium.com/@ageitgey/machine-learning-is-fun-part-4-modern-face-recognition-with-deep-learning-c3cffc121d78
翻译:拼命先生
转载请联系译者!
您是否注意到Facebook已经开发出一种不可思议的能力来识别您照片中的朋友?在过去,Facebook曾经让你通过点击他们并输入他们的名字来标记照片中的朋友。现在,只要你上传一张照片,Facebook 就可以像魔术一样标记每个人:
Facebook会自动为您之前标记过的照片中的人物标记,我不确定这是否有用或令人毛骨悚然!
这项技术称为人脸识别。你的朋友只需被标记过几次,Facebook的算法就能够识别他们的脸。这是一项非常了不起的技术 - Facebook的人脸识别准确率达到了98%,这几乎与人类做的一样好!
让我们来了解现代人脸识别的工作原理!但是,识别你的朋友太容易了。我们可以挑战一下这项技术的极限,解决一个更具挑战性的问题 - 区分Will Ferrell(着名演员)和Chad Smith(着名摇滚音乐家)!

其中一个人是威尔·法瑞尔,另一个是查德·史密斯。我发誓他们不是同一个人!
如何在一个非常复杂的问题上使用机器学习
到目前为止,在前三章中,我们使用机器学习解决了一些一步就可以解决的孤立的问题 - 估计房子的价格,生成基于现有数据的新数据,并判断图像中是否包含某个物品。所有这些问题都可以通过选择一种机器学习算法,输入数据并获得结果来解决。
但面部识别实际上是一系列相关问题:
- 首先,查看图片并找到其中的所有面孔
- 其次,对于每一张脸,即使脸部不同的方向或光线不好,仍然能够辨别这是同一个人。
- 第三,能够挑选出可以用来区别于其他人的脸部特征 - 例如眼睛有多大,脸部有多长等等。
- 最后,将这张脸的独特特征与您已知的所有人进行比较,以确定该人的姓名。
作为人类,你的大脑可以一瞬间做出这些判断。事实上,人类太善于进行人脸识别了,以至于会在日常用品中也去照脸:

计算机还不具备这种高级概括的能力(至少还没有......),所以我们必须教他们如何分别完成这个过程中的每一步。
我们需要建立一个流水线,分别完成人脸识别的每个步骤,并将当前步骤的结果传递给下一步。换句话说,我们会将几个机器学习算法连接在一起:
一个基础的人脸识别的流水线是怎样工作的
人脸识别 - 步步分解
让我们一步一步解决这个问题。对于每个步骤,我们将学习不同的机器学习算法。我不打算详细解释每一个算法,以避免这篇文章变成一本教科书,但你将学习每个算法背后的精髓,以及如何在 Python 中使用 OpenFace 和 dlib 来构建一个你自己的面部识别系统
第1步:找到所有面孔
流水线的第一步是人脸检测。显然,在我们试图区分它们之前,我们需要在照片中找到面孔!
如果您在过去10年中使用过任何相机,您可能已经见到过人脸检测功能了:

人脸检测是相机的一大特色。当相机可以自动选中面部时,可以确保所有面部在拍摄前都处于对焦状态。但是我们将它用于不同的目的 - 找到我们想要传递到我们流水线中下一步的图像区域。
面部检测在2000年初成为主流,当时保罗·维奥拉和迈克尔·琼斯发明了一种可以快速在廉价相机上运行的人脸检测方法。然而现在,我们有更可靠的解决方案。我们将使用2005年发明的一种称为方向梯度直方图(Histogram of Oriented Gradients)的方法 - 或简称为HOG。
要在图像中查找人脸,我们首先将图像设为黑白,因为我们不需要颜色数据来查找面部:

然后,我们将查看图片中的每一个像素。 对于每一个像素,我们也要查看围绕在它周围的其他像素:
我们的目标是要弄清楚当前像素与直接围绕它的像素的暗度。然后我们要画一个箭头,显示图像变暗的方向:
只看这个像素和它周围的像素,图像向右上方变暗
如果对图像中的每个像素重复该过程,最终会将每个像素替换为箭头。这些箭头称为梯度(gradients),它们显示整个图像从明亮到暗的流动过程:
这似乎是一个随机的事情,但用梯度替换像素有一个非常好的理由。如果我们直接分析像素,同一个人的明暗不同的两张图像将具有完全不同的像素值。但是,只考虑亮度变化的方向(direction),明暗的图像将会有同样的结果。这使问题更容易解决!
但是为每个像素保存梯度太过细节,我们最终可能错过森林。如果我们能够在更高的层次上看到亮度/暗度的基本流动会更好,这样我们就可以看到图像的基本图案。
为此,我们将图像分解为每个16x16像素的小方块。在每个方格中,我们将计算每个主要方向上有多少个梯度(有多少指向上,指向右上,指向右侧等等)。然后我们将用最强的箭头方向替换图像中的那个小方块。
最终结果是我们将原始图像转换为一个非常简单的表示,以一种简单的方式捕获面部的基本结构:
原始图像变为HOG表示,无论图像亮度如何,都能捕获图像的主要特征。
要在此HOG图像中查找人脸,我们所要做的就是,从我们的图像中,找到看起来与从一堆其他面部训练所提取的已知HOG模式最相似的部分:

使用这种技术,我们现在可以轻松地在任何图像中找到面孔:

如果你想使用Python和dlib自己尝试这一步,这些代码展示了如何生成和查看HOG图像。
第2步:面部不同方向的投射
哇,我们在图像中把面部分离出来了。但是现在我们必须处理一个问题,面向不同方向的面部对于计算机来说是完全不同:

人类可以很容易地认识到这两幅图像都是Will Ferrell,但计算机会将这些图片视为两个完全不同的人
为了解释这一点,我们将尝试扭曲每张照片,使眼睛和嘴唇始终位于图像的样本位置(sample place)。这将使我们在接下来的步骤中,更容易比较面部之间的不同。
为此,我们将使用一种称为面部地标估计(face landmark estimation)的算法。有很多方法可以做到这一点,但我们将使用Vahid Kazemi 和Josephine Sullivan在2014年发明的方法。
基本的想法是我们将在每个面上提出68个地标(landmarks) - 下巴的顶部,每只眼睛的外边缘,每个眉毛的内边缘等等。然后我们将训练一台机器学习算法能够在任何面部找到这68个地标:

我们将在每张脸上找到68个特征点-地标。此图片由CMU 的Brandon Amos创建,他在OpenFace工作
这是在测试图片上找到 68 个地标的结果:

友情提示:你也可以使用这一技术来实现自己的 Snapchat 实时 3D 脸部过滤器!
现在我们知道了眼睛和嘴巴的位置,我们只需把图像旋转,缩放和错切,使眼睛和嘴巴尽可能地居中。我们不做任何花哨的3D扭曲,因为这会使图像失真。我们只会使用基本的图像变换,如旋转和缩放,以保留平行线(称为仿射变换):

现在,无论面部如何转动,我们都可以将眼睛和嘴巴对准图像中大致相同的位置。这将使我们的下一步更准确。
如果你想使用Python和dlib自己尝试这一步,这里是查找面部地标的代码,这里是使用这些地标完成图像变形的代码。
第3步:给面部编码
现在我们要解决最核心的问题了 - 如何分辨不同人的面孔。现在事情变得非常有趣!
最简单的人脸识别方法是直接将我们在步骤2中找到的未知面部与我们已经标记过的人的所有图片进行比较。当我们发现之前标记过的脸看起来与我们未知的脸非常相似时,它肯定是同一个人。看起来好像是个好主意,对吗?
这种方法实际上存在很大问题。拥有数十亿用户和万亿张照片的Facebook这样的网站不可能遍历每个先前标记的脸部,以将其与每个新上传的图片进行比较。这将花费太长时间。他们需要能够在几毫秒而不是几小时内识别面部。
我们需要的是从每个面部提取一些基本测量值的方法。然后我们可以用同样的方法测量我们未知的面部并找到具有最接近测量值的已知面部。例如,我们可以测量每只耳朵的大小,眼睛之间的间距,鼻子的长度等。如果你曾经看过像CSI《犯罪现场调查》这样的节目,你就知道我在说什么了:
就像电视一样,太真实了!
测量面部最可靠的方法
那么,我们应该从每个面部收集哪些测量值来构建我们已知的面部数据库呢?耳朵大小?鼻子长度?眼睛的颜色?别的什么?
事实证明,对我们人类来说显而易见的测量值(如眼睛颜色)对于查看图像中单个像素的计算机来说并没有多大意义。研究人员发现,最准确的方法是让计算机自己找出它要收集的测量值。在确定面部的哪些部分的测量值更为重要时,深度学习比人类做的更好。
所以,解决方案是训练深度卷积神经网络(就像我们在第三章做的那样)。但是,我们不是像上次那样训练网络识别图片中的物体,而是训练它为每张脸生成128个测量值。
训练过程通过一次查看3张脸部图像来工作:
- 加载一张已知人员的面部训练图像
- 加载同一个人的另一张照片
- 加载一张另外一个人的照片
然后算法查看它为这三个图像中的每一个生成的测量值。再然后,稍微调整神经网络,以确保它为#1和#2生成的测量值比较接近,同时确保#2和#3的测量结果比较不同:
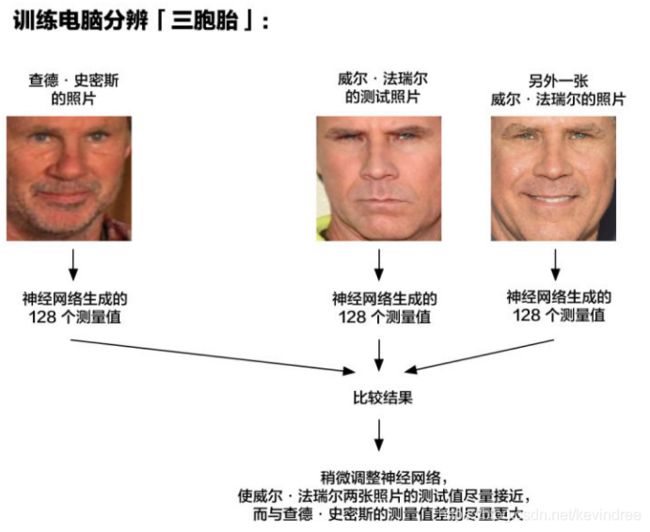
在对数千个不同的人的数百万张图像重复这一步数百万次之后,神经网络学会可靠地为每个人生成128个测量值。同一个人的任何十张不同的照片应该给出大致相同的测量值。
机器学习人员将每个面部的128个测量称为嵌入(embedding)。将复杂的原始数据(如图片)缩减为计算机生成数字列表的想法在机器学习中尤为常见(特别是在语言翻译中)。我们所使用的这种面孔提取的方法是由Google的研究人员于2015年发明的,但也存在许多类似的方法。
给我们的脸部图像编码
这种通过训练卷积神经网络以输出面部嵌入的过程,需要大量的数据和强大的计算机能力。即使使用昂贵的NVidia Telsa视频卡,也需要大约24小时的连续训练,才能获得良好的准确性。
但是,一旦网络经过训练,它就可以为任何面部生成测量结果,甚至是以前从未见过的面部!所以这一步只需要做一次。幸运的是,OpenFace的大神们已经做到了这一点,他们发布了几个我们可以直接使用的训练有素的网络。谢谢Brandon Amos和团队!
因此,我们自己需要做的就是通过预先训练好的网络运行我们的脸部图像,以获得每个脸部的128个测量值。这是测试图像的测量值:

那么这些128个数字到底准确测量了脸部的哪些数据?事实证明我们不知道。这对我们来说并不重要。我们所关心的只是网络在查看同一个人的两张不同图片时会产生几乎相同的数字。
如果你想自己尝试这个步骤,OpenFace 提供了一个lua脚本,它将生成文件夹中的所有图像的嵌入,并将它们写入csv文件。这里可以查看如何运行它。
第4步:从编码中查找此人的姓名
最后一步实际上是整个过程中最简单的步骤。我们所要做的就是在我们的数据库中,找到与我们的测试图像测量值最接近的那个人。
您可以使用任何基本的机器学习分类算法来实现。不需要花哨的深度学习技巧。我们将使用简单的线性SVM分类器,但许多分类算法都可以工作。
我们需要做的就是训练一个分类器,它可以从新的测试图像中获取测量值,并告诉哪个已知的人是最接近的匹配者。运行此分类器需要几毫秒。分类器的结果是人的名字!
那么让我们试试我们的系统。首先,我训练了一个分类器,其中包括Will Ferrell,Chad Smith和Jimmy Falon的约20张图片的嵌入:

yammi , 好吃的训练数据!
接下来,我在这个分类器上运行了威尔·法瑞尔和查德·史密斯在吉米·法伦的节目上互相模仿的那个视频的每一帧:
结果成功了!不同角度的脸部,甚至是侧脸,它都能捕捉到!
自己动手
让我们回顾一下我们遵循的步骤:
- 使用HOG算法对图片进行编码以创建图像的简化版本。使用此简化图像,找到通用HOG编码的图像中看起来最像面部的部分。
- 通过找到脸部的主要地标来弄清楚脸部的姿势。一旦我们找到这些地标,就用它们来扭曲图像,使眼睛和嘴巴居中。
- 通过神经网络传递居中的脸部图像,神经网络知道如何测量脸部的特征,保存这128个测量值。
- 观察我们过去测量的所有面孔,看看哪个人的面部测量结果和我们要测试的人最接近,那就是我们要找的那个人!
现在您已经了解了这一切是如何工作的,这里是从头到尾的说明如何在您自己的计算机上运行整个面部识别的说明:
更新4/9/2017: 您仍然可以按照以下步骤使用OpenFace。但是,我发布了一个新的名为 face_recognition的基于Python的人脸识别库,它更易于安装和使用。所以我建议先尝试使用 face_recognition而不是继续下面!
我甚至将预配置的虚拟机与face_recognition,OpenCV,TensorFlow和许多其他深度学习工具预先安装在一起。您可以非常轻松地在计算机上下载并运行它。如果您不想自己安装所有这些库,请为虚拟机几次搞定所有这些安装!
原始的OpenFace说明:
开始之前
确保你已经安装了 python、OpenFace 和 dlib。你也可以在这里手动安装,或者使用一个已经设定好的 docker image:
docker pull
bamos/openface
docker run -p 9000:9000
-p 8000:8000 -t -i bamos/openface /bin/bash
cd /root/openface
友情提示:如果你正在 OSX 上使用 Docker,你可以这样使你的 OSX /Users/
文件夹在 docker image 中可见:
docker run -v /Users:/host/Users -p 9000:9000 -p
8000:8000 -t -i bamos/openface /bin/bash
cd /root/openface
然后你就能访问你在 docker image 中 /host/Users/...的 OSX 文件
ls /host/Users/
第一步
在 openface 文件中建立一个名为 ./training-images/ 的文件夹。
mkdir training-images
第二步
为你想识别的每个人建立一个子文件夹。例如:
mkdir ./training-images/will-ferrell/
mkdir ./training-images/chad-smith/
mkdir ./training-images/jimmy-fallon/
第三步
将每个人的所有图像复制进对应的子文件夹。确保每张图像上只出现一张脸。不需要裁剪脸部周围的区域。OpenFace 会自己裁剪。
第四步
从 openface 的根目录中运行这个
openface 脚本。
首先,进行姿势检测和校准:
./util/align-dlib.py
./training-images/ align outerEyesAndNose ./aligned-images/ --size 96
这将创建一个名为./aligned-images/的子文件夹,里面是每一个测试图像裁剪过、并且对齐的版本。
其次,从对齐的图像中生成特征文件:
./batch-represent/main.lua
-outDir ./generated-embeddings/ -data ./aligned-images/
运行完后,这个./generated-embeddings/子文件夹会包含一个带有每张图像嵌入的 csv 文件。
第三,训练你的面部检测模型:
./demos/classifier.py
train ./generated-embeddings/
这将生成一个名为 ./generated-embeddings/classifier.pkl的新文件,其中包含了你用来识别新面孔的 SVM 模型。
到这一步为止,你应该有了一个可用的人脸识别器!
第五步:识别面孔!
获取一个未知脸孔的新照片,然后像这样把它传递入分类器脚本中:
./demos/classifier.py
infer ./generated-embeddings/classifier.pkl your_test_image.jpg
你应该会得到像这样的一个预测:
===/test-images/will-ferrel-1.jpg ===
Predict will-ferrell with 0.73 confidence.
至此,你已经完成了一个预测了。你也可以修改./demos/classifier.py 这个 python 脚本,来让它匹配其他人的脸。
重要提示:
- 如果你得到的结果不够理想,试着在第三步为每个人添加更多照片(特别是不同姿势的照片)。
- 即使完全不知道这个面孔是谁,现在这个脚本仍然会给出预测。在真实应用中,低可信度(low confidence)的预测可能会被直接舍弃,因为很有可能它们就是错的。