LightGBM算法详解
ref. AI蜗牛车
文章目录
- 前言
- 一、LightGBM介绍
- 二、LightGBM的直方图算法(Histogram)
- 三、 LightGBM调参
- 四、 总结
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、LightGBM介绍
谈起Lightgbm, 我们已经知道了是xgboost的强化版本, 关于xgboost,从其工作原理到数学推导再到优化策略最后到实战应用,都已经描述过了,这里只进行简单的回忆和梳理,在这次回忆中我们看看xgboost在某些策略上是不是依然存在一些问题? 然后这些问题是不是可以有改进的方式?
xgboost是属于boosting家族,是GBDT算法的一个工程实现, 在模型的训练过程中是聚焦残差,在目标函数中使用了二阶泰勒展开并加入了正则,在决策树的生成过程中采用了精确贪心的思路,寻找最佳分裂点的时候,使用了预排序算法, 对所有特征都按照特征的数值进行预排序, 然后遍历所有特征上的所有分裂点位,计算按照这些候选分裂点位分裂后的全部样本的目标函数增益,找到最大的那个增益对应的特征和候选分裂点位,从而进行分裂。这样一层一层的完成建树过程, xgboost训练的时候,是通过加法的方式进行训练,也就是每一次通过聚焦残差训练一棵树出来, 最后的预测结果是所有树的加和表示。
上面简单的把xgboost的一些知识给梳理了一下,我们主要是看看xgboost在树生成的过程中,是否存在某些策略上的问题啊! 机智的你可能会说:xgboost在进行最优分裂点的选择上是先进行预排序,然后对所有特征的所有分裂点计算按照这些分裂点位分裂后的全部样本的目标函数增益,这样会不会太费时间和空间了啊! 哈哈, 果真是一语中的, 还真会带来这样的问题, 首先就是空间消耗很大,因为预排序的话既需要保存数据的特征值, 还得保存特征排序后的索引,毕竟这样后续计算分割点的时候快一些,但是这样就需要消耗训练数据两倍的内存。其次, 时间上也有很大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
这时候你又可能说了xgboost不是有个近似分割的算法吗? 这个不就对分裂点进行了分桶了,不就可以少遍历一些分裂点了? 嗯嗯, 这个其实就是下面要讲的lightgbm里面的直方图的思路, 所以直方图这个思路在xgboost里面也体现过,不算是lightgbm的亮点了, 这个是会有一些效果,可以减少点计算,但是比较微妙,lightgbm直方图算法进行了更好的优化(具体的下面说), 比xgboost的这个还要快很多,并且XGB虽然每次只需要遍历几个可能的分裂节点,然后比较每个分裂节点的信息增益,选择最大的那个进行分割,但比较时需要考虑所有样本带来的信息增益,这样还是比较费劲。 所以基于xgboost寻找最优分裂点的复杂度,我总结了下面三点:
![]()
所以如果想在xgboost上面做出一些优化的话,我们是不是就可以从上面的三个角度下手,比如想个办法减少点特征数量啊, 分裂点的数量啊, 样本的数量啊等等。
Lightgbm里面的直方图算法就是为了减少分裂点的数量, Lightgbm里面的单边梯度抽样算法就是为了减少样本的数量, 而Lightgbm里面的互斥特征捆绑算法就是为了减少特征的数量。 并且后面两个是Lightgbm的亮点所在。
二、LightGBM的直方图算法(Histogram)
LightGBM的直方图算法是代替Xgboost的预排序算法的, 之前我们提到过,Lightgbm是在xgboost的基础上进行的优化,为什么要基于xgboost进行优化呢? 这是因为在GBDT的众多演化算法里面,Xgboost性能应该算是最好的一个,而Lightgbm也算是演变家族中的一员,所以为了凸显其优越性,都是一般和xgboost进行对比。 虽然直方图的算法思路不算是Lightgbm的亮点,毕竟xgboost里面的近似算法也是用的这种思想,但是这种思路对于xgboost的预排序本身也是一种优化,所以Lightgbm本着快的原则,也采用了这种直方图的思想。那么直方图究竟在做什么事情呢?
直方图算法说白了就是把连续的浮点特征离散化为k个整数(也就是分桶bins的思想), 比如[0, 0.1) ->0, [0.1, 0.3)->1。 并根据特征所在的bin对其进行梯度累加和个数统计,在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。 这么说起来,可能还是一脸懵逼, 那么就再来形象的画个图吧(有图就有真相了,哈哈,我们就拿出某一个连续特征来看看如何分桶的):
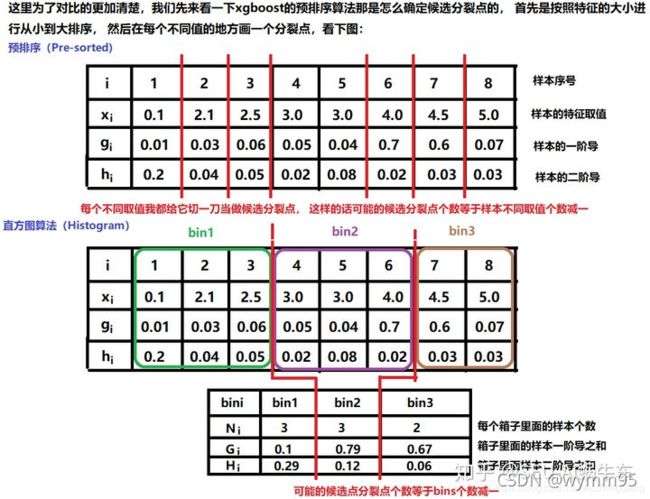
这样在遍历到该特征的时候,只需要根据直方图的离散值,遍历寻找最优的分割点即可,由于bins的数量是远小于样本不同取值的数量的,所以分桶之后要遍历的分裂点的个数会少了很多,这样就可以减少计算量。基于上面的这个方式,如果是把所有特征放到一块的话,应该是下面的这种感觉:
这里注意一下,XGBoost 在进行预排序时只考虑非零值进行加速,而 LightGBM 也采用类似策略:只用非零特征构建直方图。这种离散化分桶思路其实有很多优点的, 首先最明显就是内存消耗的降低,xgboost需要用32位的浮点数去存储特征值, 并用32位的整型去存储索引,而Lightgbm的直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。
然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而Lightgbm直方图算法只需要计算k次(k可以认为是常数),时间复杂度从[公式]优化到[公式]。而我们知道[公式]
但是你知道吗?Histogram算法还可以进一步加速。一个叶子节点的Histogram可以直接由父节点的Histogram和兄弟节点的Histogram做差得到。一般情况下,构造Histogram需要遍历该叶子上的所有数据,通过该方法,只需要遍历Histogram的k个捅。速度提升了一倍。再说一下这个细节, 到底这是啥意思呢?
三、 LightGBM调参
Lightgbm的参数非常多,有核心参数,学习控制参数,IO参数,目标函数参数,度量参数等很多,但是我们调参的时候不需要关注这么多,只需要记住常用的关键的一些参数即可,下面从四个问题的维度整理一些调参的指导:
- 针对leaf-wise树的参数优化
- num_leaves:控制了叶节点的数目。它是控制树模型复杂度的主要参数。 如果是level-wise,则该参数为[公式],其中depth为树的深度。但是当叶子数量相同时,leaf-wise的树要远远深过level-wise树,非常容易导致过拟合。因此应该让num_leaves小于[公式]。在leaf-wise树中,并不存在depth的概念。因为不存在一个从leaves到depth的合理映射。
- min_data_in_leaf: 每个叶节点的最少样本数量。它是处理leaf-wise树的过拟合的重要参数。将它设为较大的值,可以避免生成一个过深的树。但是也可能导致欠拟合。
- max_depth: 控制了树的最大深度。该参数可以显式的限制树的深度。
- 针对更快的训练速度
- 通过设置 bagging_fraction 和 bagging_freq 参数来使用 bagging 方法
- 通过设置 feature_fraction 参数来使用特征的子抽样
- 使用较小的 max_bin
- 使用 save_binary 在未来的学习过程对数据加载进行加速
- 获得更好的准确率
- 使用较大的 max_bin (学习速度可能变慢)
- 使用较小的 learning_rate 和较大的 num_iterations
- 使用较大的 num_leaves (可能导致过拟合)
- 使用更大的训练数据
- 尝试DART
- 缓解过拟合
- 使用较小的 max_bin, 分桶粗一些
- 使用较小的 num_leaves 不要在单棵树分的太细
- 使用 lambda_l1, lambda_l2 和 min_gain_to_split 来使用正则
- 尝试 max_depth 来避免生成过深的树
- 使用 min_data_in_leaf 和 min_sum_hessian_in_leaf, 确保叶子节点有足够多的数据
下面就以一个乳腺癌数据的例子,看看我们应该怎么具体去调参:
LightGBM的调参过程和RF、GBDT等类似,其基本流程如下:
- 首先选择较高的学习率,大概0.1附近,这样是为了加快收敛的速度。这对于调参是很有必要的。
- 对决策树基本参数调参
- 正则化参数调参
- 最后降低学习率,这里是为了最后提高准确率
四、 总结
到这里终于把Lightgbm说的差不多了,不知不觉依然是整理了这么多,篇幅和xgboost差不多,因为这个算法也是超级的重要,面试的时候也会扣得很细,所以能多整理点还是尽量多整理一些。 这次我重点放到了算法的原理上面,尽量用白话的语言去描述,关于论文里面的算法流程图我可没敢放上来,但具体的细节还是建议去看原文,这次内容挺多,依然是快速回顾一遍。
讲Lightgbm,基本上就是围绕着快进行的,为了实现这个目的,lightgbm基于xgboost做了很多的优化,首先,从寻找最优分裂点上,我们说了直方图算法算法原理,这个可以降低分裂点的数量,然后我们又说了lightgbm的两大亮点技术GOSS和EFB的算法原理, 前者是为了降低样本的数量,后者是为了减少特征的数量,这样从这三个角度lightgbm降低了xgboost在寻找最优分裂点上的复杂度,从而实现了快。然后Lightgbm又从树的生长策略上对xgboost进行了优化,使用了Leaf-wise实现了高精度。 最后工程上Lightgbm首次支持类别特征,并且在并行方式上也做了很多的优化,然后就是提高了cache的命中率,这些方式都提高了lightgbm的训练速度,所以相比于xgboost,快,更快,越来越快 后面作为收尾,依然是给出了一个实战示例,并整理了一些调参技术。
下面就与xgboost对比一下,总结一下lightgbm的优点作为收尾, 从内存和速度两方面总结:
- 内存更小
- XGBoost 使用预排序后需要记录特征值及其对应样本的统计值的索引,而 LightGBM 使用了直方图算法将特征值转变为 bin 值,且不需要记录特征到样本的索引,将空间复杂度从 O(2*#data) 降低为 O(#bin) ,极大的减少了内存消耗;
- LightGBM 采用了直方图算法将存储特征值转变为存储 bin 值,降低了内存消耗;
- LightGBM 在训练过程中采用互斥特征捆绑算法减少了特征数量,降低了内存消耗。
- 速度更快
- LightGBM 采用了直方图算法将遍历样本转变为遍历直方图,极大的降低了时间复杂度;
- LightGBM 在训练过程中采用单边梯度算法过滤掉梯度小的样本,减少了大量的计算;
- LightGBM 采用了基于 Leaf-wise 算法的增长策略构建树,减少了很多不必要的计算量;
- LightGBM 采用优化后的特征并行、数据并行方法加速计算,当数据量非常大的时候还可以采用投票并行的策略;
- LightGBM 对缓存也进行了优化,增加了 Cache hit 的命中率。