人工神经网络进化简史
人工神经网络,是当下实现人工智能最主要的技术研究方向之一,我们所看到的AI落地产品,大部分都使用了人工神经网络的技术。人工智能神经网络之所以有如此广泛的应用和研究的价值,就是因为它不像以往传统的纯数学模型,不只是从数学的角度考虑人工智能的发展,而是在原来的纯数学模型的基础上加入了生物领域的知识、以及电脑硬件方面的知识体系,从更具体的落地应用方向去考虑,比如如何更快的学习,更简捷方便的部署等,而以往传统的纯数学模型更多是从学术研究的方向考虑。接下来这篇文章,我们将会详细讲述人工神经网络的来龙去脉。关注成都深度智谷科技旗下深度人工智能学院,我们长期致力于人工智能技术的教育和传播。
生命的触手——神经元
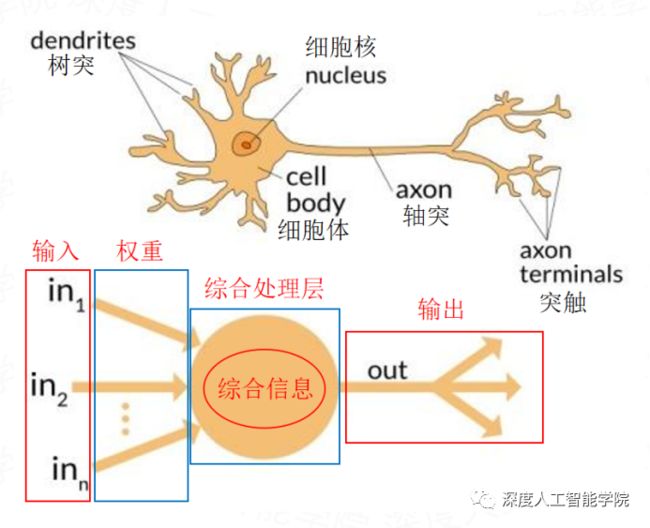
神经元又称神经细胞,是构成生物神经系统最基本的结构。生物的神经元有着可以感受外界信息的能力,这种能力能够帮助生物感知外界环境的变化,从而做出相关的反应,生物神经元主要是通过接受、整合、传导和输出信息等步骤来实现和外界的信息交换的。可以说,有了神经元,便有了生命的气息。
结构
神经元是高等动物神经系统的结构单位和功能单位。神经系统中含有大量的神经元,据估计,人类中枢神经系统中约含1000亿个神经元,仅大脑皮层中就约有140亿。
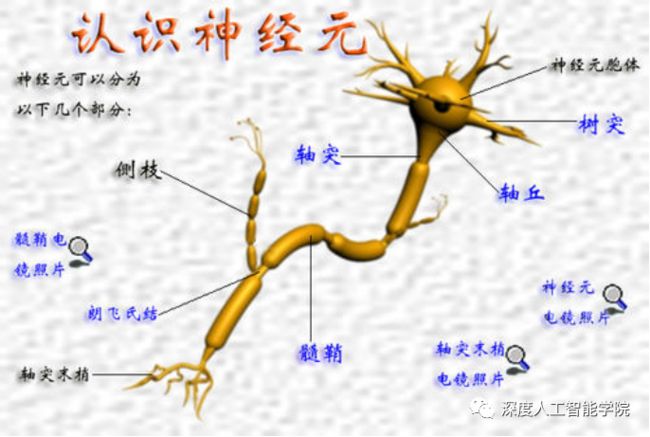
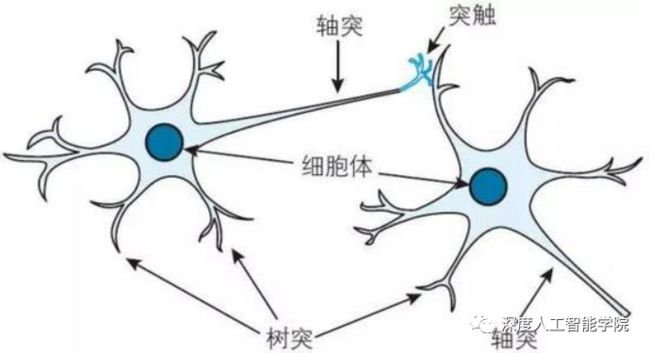
神经元的形状一般呈三角形或多角形,从结构上大致都可分成细胞体(soma)和突起(neurite)两部分。胞体包括细胞膜、细胞质和细胞核;突起由胞体发出,分为树突(dendrite)和轴突(axon)两种,所以从更加细致的分类结构上可以分为胞体和树突、轴突这三个区域。
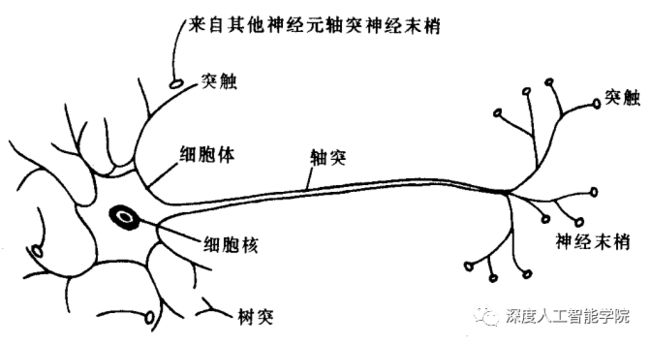
树突较多,粗而短,反复分支,逐渐变细;轴突一般只有一条,细长而均匀,中途分支较少,末端则形成许多分支,每个分支末梢部分膨大呈球状,称为突触小体。在轴突发起的部位,胞体常有一锥形隆起,称为轴丘。
轴突自轴丘发出后,开始的一段没有髓鞘包裹,称为始段(initial segment)。由于始段细胞膜的电压门控钠通道密度最大,产生动作电位的阈值最低,即兴奋性最高,故动作电位常常由此首先产生。轴突离开细胞体一段距离后才获得髓鞘,成为神经纤维。
功能
综合前面的知识,我们知道神经元的功能包括:神经元的基本功能是通过接受、整合、传导和输出信息实现信息交换。
而神经元也是脑的主要成分,神经元群通过各个神经元的信息交换,实现脑的分析功能,进而实现样本的交换产出。产出的样本通过联结路径点亮丘觉产生意识。
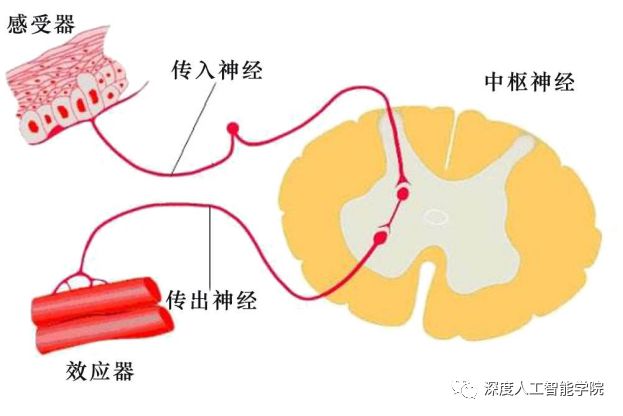
神经元的功能分区,无论是运动神经元,还是感觉神经元或中间神经元都可分为:
1)输入(感受)区 就一个运动神经元来讲,胞体或树突膜上的受体是接受传入信息的输入区,该区可以产生突触后电位(局部电位)。
2)整合(触发冲动)区 始段属于整合区或触发冲动区,众多的突触后电位在此发生总和,并且当达到阈电位时在此首先产生动作电位。
3)冲动传导区 轴突属于传导冲动区, 动作电位以不衰减的方式传向所支配的靶器官。
4)输出(分泌)区 轴突末梢的突触小体则是信息输出区,神经递质在此通过胞吐方式加以释放。
神经元分化程度高,所以一旦神经元受伤修复起来十分的慢,如果受伤严重,还有可能造成不可修复的伤害,而且修复神经元的药物的效果也不是十分理想。所以,一旦有损伤,后果很严重。
分类
神经元可以根据不同的分类机制分为不同的类型。
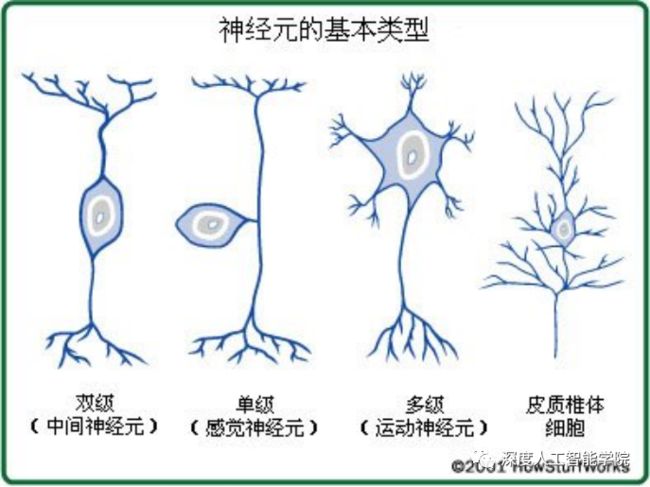
(一)根据细胞体发出突起的多少,从形态上可以把神经元分为3类:
1.假单极神经元:
胞体近似圆形,发出一个突起,在离胞体不远处分成两支,一支树突分布到皮肤、肌肉或内脏,另一支轴突进入脊髓或脑。
2.双极神经元:
胞体近似梭形,有一个树突和一个轴突,分布在视网膜和前庭神经节。
3.多极神经元:
胞体呈多边形,有一个轴突和许多树突,分布最广,脑和脊髓灰质的神经元一般是这类。
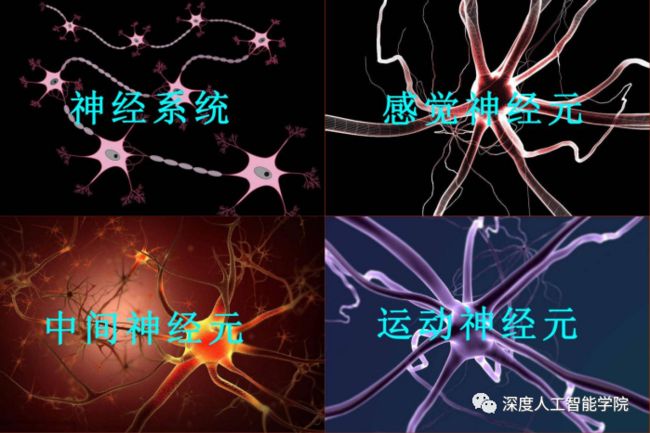
(二)根据神经元的机能分类:
1.感觉(传入)神经元:
接受来自体内外的刺激,将神经冲动传到中枢神经。神经元的末梢,有的呈游离状,有的分化出专门接受特定刺激的细胞或组织。分布于全身。在反射弧中,一般与中间神经元连接。在最简单的反射弧中,如维持骨骼肌紧张性的肌牵张反射,也可直接在中枢内与传出神经元相突触。一般来说,传入神经元的神经纤维,进入中枢神经系统后与其它神经元发生突触联系以辐散为主,即通过轴突末梢的分支与许多神经元建立突触联系,可引起许多神经元同时兴奋或抑制,以扩大影响范围。
2.运动(传出)神经元:
神经冲动由胞体经轴突传至末梢,使肌肉收缩或腺体分泌。传出神经纤维末梢分布到骨骼肌组成运动终板;分布到内脏平滑肌和腺上皮时,包绕肌纤维或穿行于腺细胞之间。在反射弧中,一般与中间神经元联系的方式为聚合式,即许多传入神经元和同一个神经元构成突触,使许多不同来源的冲动同时或先后作用于同一个神经元。即为中枢的整合作用,使反应更精确、协调。
3.联络(中间)神经元:
接受其他神经元传来的神经冲动,然后再将冲动传递到另一神经元。中间神经元分布在脑和脊髓等中枢神经内。它是三类神经元中数量最多的。其排列方式很复杂,有辐散式、聚合式、链锁状、环状等。神经元间信息传递的接触点是突触。复杂的反射活动是由传入神经元、中间神经元和传出神经元互相借突触连接而成的神经元链。在反射中涉及的中间神经元越多,引起的反射活动越复杂。人类大脑皮质的思维活动就是通过大量中间神经元的极其复杂的反射活动。中间神经元的复杂联系,是神经系统高度复杂化的结构基础。
(三)按神经元轴突的长短:
可分为高尔基(Gol-gi)Ⅰ型细胞和高尔基Ⅱ型细胞两种类型。
数量
从神经元的数量上来说,人类是目前已知生物中,神经元个数最多的生物,人类的神经元个数可以达到900到1000亿个,而狗和猫的神经元个数只有30到40亿个,这或许是为什么人类能过具有高智慧的缘由之一,我们可以简单的认为神经元的数量多少决定着生物的智慧化程度。

但是也有些研究证明,神经元的数量不是决定生物智慧程度的关键因素,真正能够决定的生物的智慧程度的除了神经元个数以外,还有神经元的连接方式和连接效率等,甚至神经元的突触结构过多反而会造成不好的现象发生。
根据近期一些国外机构的研究,发现神经元突触过多,或许是自闭症的征兆。
近期自闭症患者的神经系统具有高度异质性,这使他们表现出不同程度的神经方面症状或功能障碍。近日,意大利理工学院和比萨大学的研究人员发现了一种由特定神经元改变——大脑皮层中突触过多所导致的自闭症。
相关结果于当地时间2021年10月28日发表在《自然》杂志上,这一发现或有助于引导相关药品研制的发展。研究人员通过磁共振成像对动物模型进行了实验观察,结果显示,突触过多会导致大脑回路功能障碍,而这些回路对社交能力至关重要。进一步研究发现,这种改变可能与异常的mTOR蛋白活性有关。mTOR蛋白是调节生成突触的关键因子,也是药物治疗的潜在靶点。研究人员证实了这一观点,当mTOR过度的活动受到药物抑制时,突触的数量会回到正常生理水平,并完全恢复相关脑回路的功能和连接。

基于上述结果,研究人员随后尝试通过机器学习方法,确定这种特定的脑回路功能障碍能否在确诊的自闭症患者大脑中被扫描识别。最终,一组扫描结果显示,自闭症患者的大脑确实存在连接障碍,与小鼠模型中观察到的结果非常相似。更为重要的是,随后的基因分析同样显示,已识别的脑回路功能障碍与异常的mTOR蛋白活性有关。
本次研究的参与者、比萨大学的Massimo Pasqualetti教授总结:“这项研究表明,将大脑功能模型研究与临床实例相结合是多么重要,这既有助于理解引起病理变化的一些分子或细胞,也能在相同的模型上进行药物的实验和治疗干预,进而改善甚至治愈这些病理变化。”关注成都深度智谷科技——深度人工智能学院,获取更多人工智能知识。
生物与数学的握手——感知机
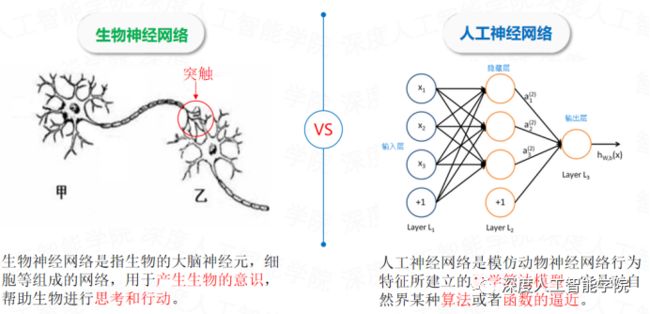
感知机又称感知器,从字面意思可以理解为感知机是用来感知外界的信息的。感知机是最早的神经网络雏形,一个单独的感知机就是模拟一个生物神经元的过程,多个感知机结合起来就是模拟生物神经网络的过程,所以多层感知机也称为人工神经网络。
生物神经网络是指生物的大脑神经元,细胞等组成的网络,用于产生生物的意识,帮助生物进行思考和行动。人工神经网络是模仿动物神经网络行为特征所建立的数学算法模型。它是对自然界某种算法或者函数的逼近。
起源
1943年,心理学家Warren McCulloch和数理逻辑学家Walter Pitts在合作的《A logical calculus of the ideas immanent in nervous activity》论文中提出并给出了人工神经网络的概念及人工神经元的数学模型,从而开创了人工神经网络研究的时代。1949年,心理学家唐纳德·赫布在《The Organization of Behavior》论文中描述了神经元学习法则。
人工神经网络更进一步被美国神经学家 Frank Rosenblatt 所发展。他提出了可以模拟人类感知能力的机器,并称之为“感知机”(MLP)。1957年,在 Cornell 航空实验室中,他成功在IBM 704机上完成了感知机的仿真。两年后,他又成功实现了能够识别一些英文字母、基于感知机的神经计算机——Mark1,并于1960年6月23日,展示与众。
特征
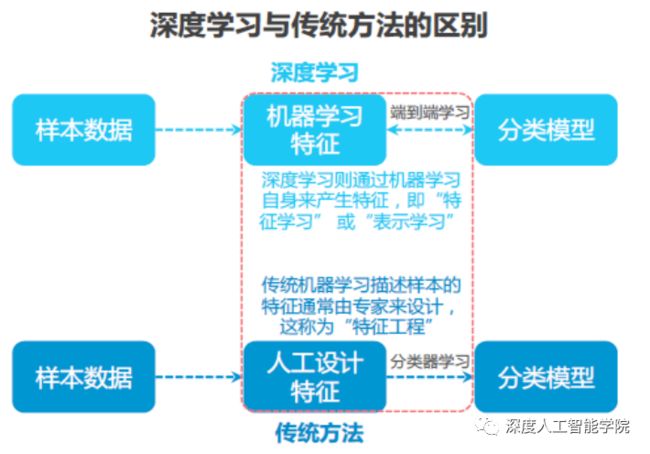
在没有出现感知机之前,早期的AI模型主要是依赖于数学模型的计算,这种传统的数学模型在实际的应用过程中有一定的局限性,并不适合大规模的实际落地应用。比如对于一个分类模型,基于统计学等数学的传统方法的模型,是在分类模型进行分类之前,往往需要提前设计好数据的特征,然后再将这些特征输入模型去分类,而这些特征又都是各领域的专家设计的,比如需要对红酒进行分类,就需要专门研究红酒类的专家来设计这些特征,因为只有他们才是最了解不同种类的红酒有哪些区别的。
而基于人工神经网络的深度学习方法则完全不需要专家设计特征的这个环节,在深度学习的模型中,所有的特征不是提前预设好的,而是通过神经网络的“反向传播算法”求导更新参数而得到的。深度学习的方法的好处是避免了人为设计特征的不便之处和局限性,放开条件后,让网络去学习数据的特征,往往效果要比人为设计特征的效果好数倍,去除了人为的先验条件做为特征的输出,从最终的输出结果上得到了质的飞跃。
但是基于人工神经网络的深度学习方法同样面临一个问题,那就是在特征的“可解释性”上并不友好,传统的基于统计学的数学模型,特征虽然是由专家设计的,在实际使用效果上也没有深度学习那么好,但是却具有现实的可解释性,比如拿红酒分类来说,可以根据颜色、含糖量、含二氧化碳、酒精含量等其他不同的特征进行分类,能够得到红葡萄酒、白葡萄酒、干葡萄酒、半干葡萄酒、汽酒、静酒等等不同种类的红酒。
如果使用深度学习来完成红酒分类的工作,那么在数据的特征提取上就不是由专家来设计了,而是由神经网络通过反向传播算法而得到的的特征,这种通过神经网络学习到的特征是由一个很大的矩阵数据构成的,不具有任何可解释性的,目前没有任何方法能够把这个矩阵数据和某些具体的可解释性的概念联系起来。关注成都深度智谷科技、深度人工智能学院,了解人工智能的发展。
结构
从感知机的内部结构上区分,可以分为输入端、处理端、输出端。输入端的作用就是接受外界信息,处理端的作用就是对数据加权求和以及非线性处理,输出端的作用就是将输出值输出到下一层。

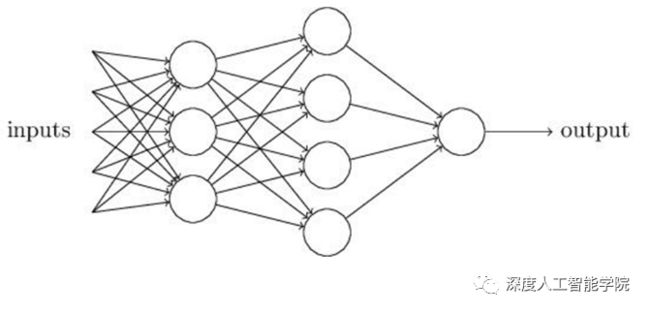
从层数结构上可以分为单层感知机和多层感知机,单层感知机就是只有一个单独的感知机,多层感知机是由多个感知机构成至少两层以上的感知机结构。
单层感知机模型:

hθ=X*W+b,其中(X=[x1,x2,x3,...],W=[w1,w2,w3,...])
多层感知机模型:
Y=((X1*W1+b1)*W2+b2)*W3+b3...,其中(X=[x1,x2,x3,...],W=[w1,w2,w3,...])
从多层感知机看出,多层感知机就是由多个单层感知机而构成的,其函数是一个核函数,也就是上一层的输出可以做为下一层的输入。超过三层的多层感知机也称为深度人工神经网络。
从运行过程来区分模型的结构,大体上可以分为前向部分和后向部分,前向部分一般也称为前馈神经网络,主要是获得输入进行计算后输出的过程,后向部分主要是指反向传播算法,通过神经网络反向求导降低误差来更新神经网络参数的过程。
神经网络前向运行过程:
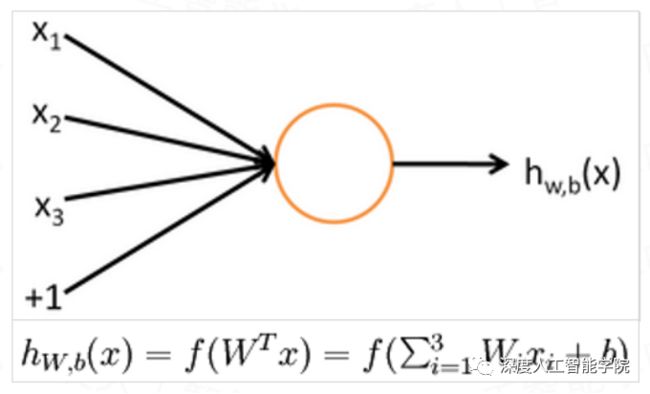
神经网络后向运行过程:
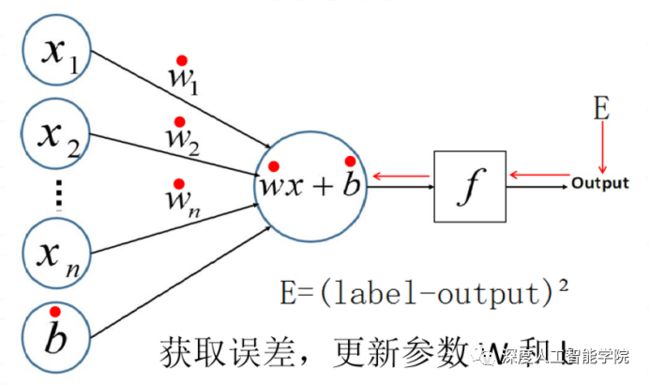
神经网络的详细运行过程可以参考下图:

功能
感知机的功能就是模拟生物神经元和神经网络,以期望达到和生物神经网络同样的功能,生物的神经网络是通过外界传入的信息来学习,感知机同样也需要外界的输入来学习,从而获取数据的特征做为学习到的结果。生物的神经元是生物获取外界感知的最基本单位,能过帮助生物在进化中获得更好的方向。感知机模型结合了数学和生物的特征,在大的结构上模拟生物神经元的结构,在具体的实现结果上满足了数学公式的逻辑,可以认为感知机是神经元的数学化表现形式,二者的功能都是一样的。
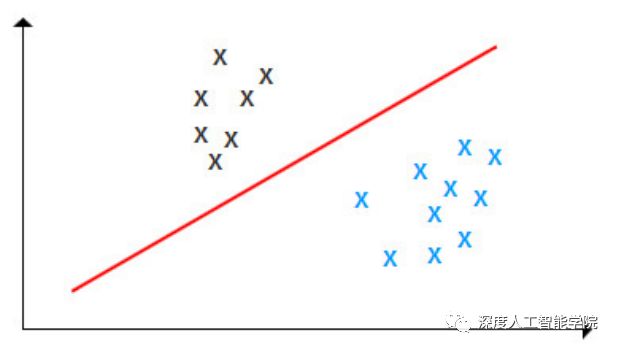
在具体的任务中,感知可以可以做为分类模型,对不同种类的物体分类:
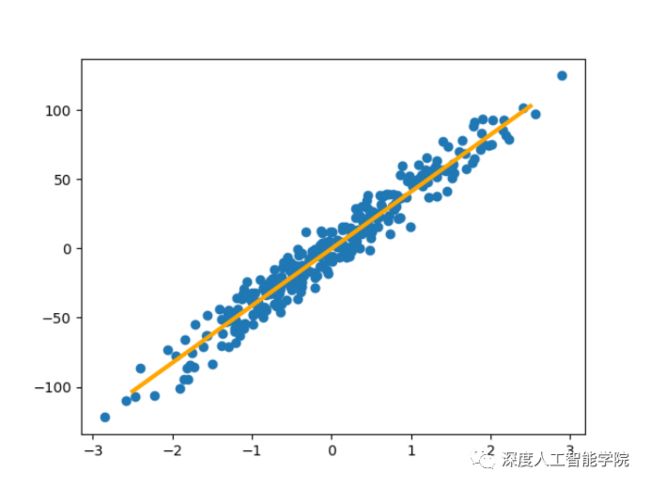
也可以对指定的数据做线性回归、拟合:
或者加入非线性函数做非线性的回归、拟合:
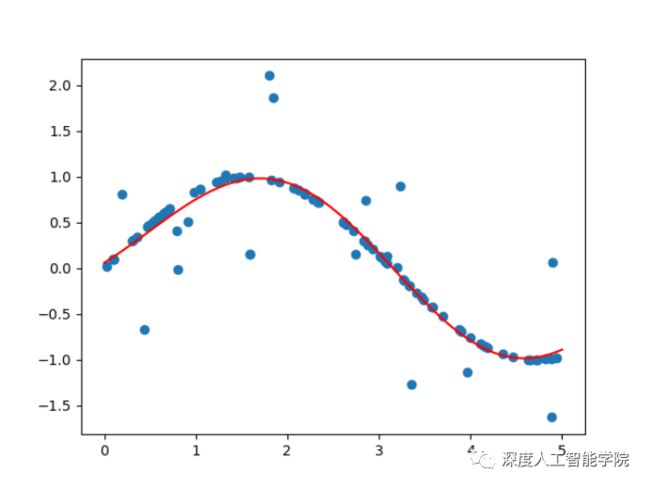
也可以对多个任务进行非线性的回归、拟合:
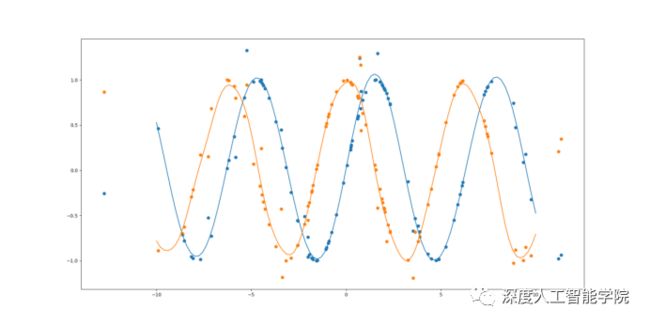
从神经元之间的连接方式来看,生物的神经元之间是受到外界的刺激后而发生的连接,比如外界的温度变化对人体带来的感觉就是由感觉神经元(传入神经元)传递的,感觉神经元的树突的末端分布于身体的外周部,接受来自体内外的刺激,将兴奋传至脊髓和脑。
外界的温度实际就是由皮肤(内含有神经末梢)传递到大脑中枢的,在人的大脑中下丘脑有体温调节中枢,所以由冷(热)感觉神经把外界温度信息传递给下丘脑,由下丘脑进行调节并产生意识。可以发现,生物的这种神经元之间的连接完全是随机的,由外界环境而影响的。
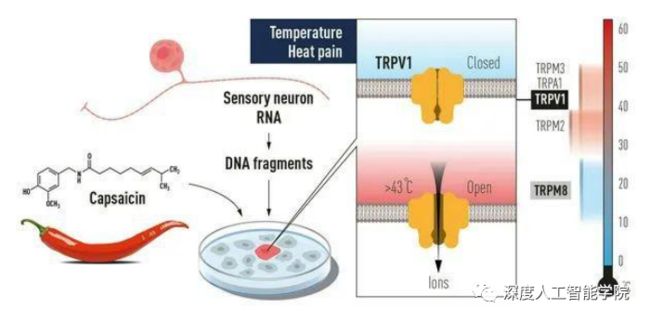
而人工神经元之间的连接则是一开始就被固定好了的,比如根据实际需求需要设计一个多大的神经网络网络模型,那么这个网络模型的参数和连接方式就基本已经被固定了。虽然可以通过神经元之间的随机失活等方法可以局部的改变神经网络内部的连接,但是这种改变仍然无法让人工神经元像生物神经元一样根据外界输入的数据信息而选择性的提取需要的特征信息。关注成都深度智谷科技—深度人工智能学院,获取更多人工智能知识。
生物的神经元之间是没有任何顺序的,可以随时根据外界传入的信息有条件的随意连接,但是人工神经网络内部的神经元之间是有顺序排列的,也就是神经网络的层数,人工神经元只能在神经网络的不同层之间发生连接,由于数学矩阵运算的规律,在同一层神经网络之间的神经元是无法连接的。
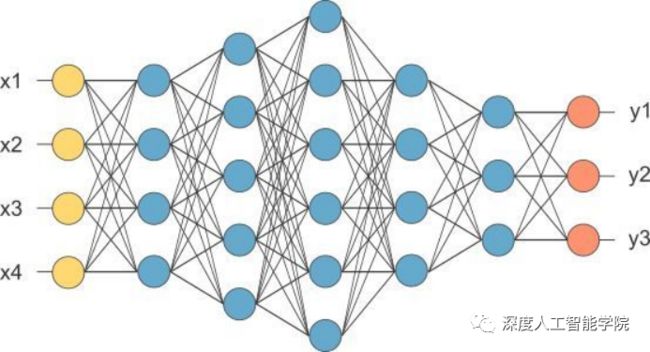
由于感知机无法完全模拟生物神经元的连接方式,这也是导致感知机模型无法像人一样达到真正的强人工智能的原因之一。
发展
按照感知机的发展过程,可以整体可以分为线性感知机和非线性感知机。线性感知机主要是处理线性分类和回归问题,非线性感知机主要是处理非线性分类和回归问题。
早期的线性感知机模型:
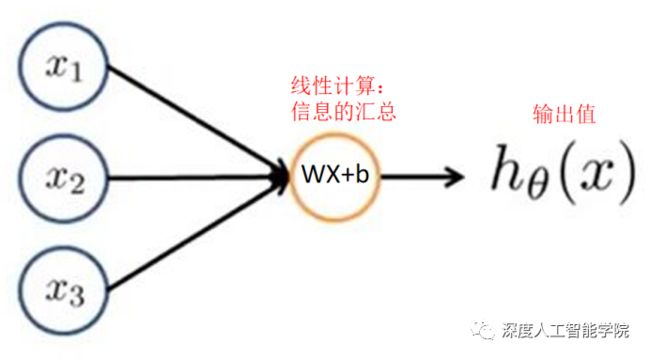
或者加入一个二分类的线性激活函数sign,做二分类任务的模型:
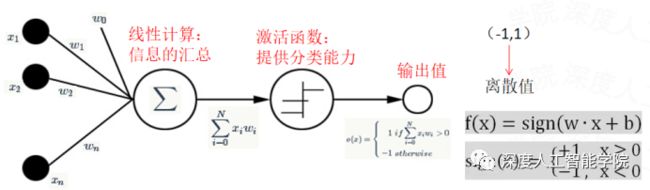
将线性激活函数sign替换成非线性激活函数sigmoid之后,原来的线性感知机也就变成了非线性感知机模型:
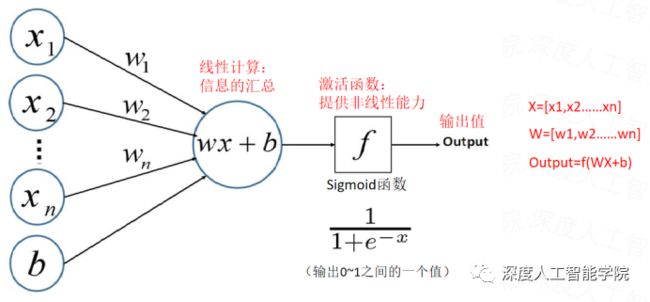
感知机从一开始简单的分类模型经过发展,逐渐向多层非线性感知机的方向进化。解决的问题也越来越复杂,也就进入了深度人工神经网络时代。
人工神经网络的发展
通过前面的对感知机的认识,基本上已经明白什么是人工神经网络了,人工神经网络实际上就是一个多层的感知机。人工神经网络的发展要追溯到20世纪80 年代,当时以来人工智能领域兴起的一些研究热点,从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络。在工程与学术界也常直接简称为神经网络或类神经网络。
神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
最近十多年来,人工神经网络的研究工作不断深入,已经取得了很大的进展,其在模式识别、智能机器人、自动控制、预测估计、生物、医学、经济等领域已成功地解决了许多现代计算机难以解决的实际问题,表现出了良好的智能特性。
人工神经网络在信息领域中的应用
在处理许多问题中,信息来源既不完整,又包含假象,决策规则有时相互矛盾,有时无章可循,这给传统的信息处理方式带来了很大的困难,而神经网络却能很好的处理这些问题,并给出合理的识别与判断。
1.信息处理
现代信息处理要解决的问题是很复杂的,人工神经网络具有模仿或代替与人的思维有关的功能, 可以实现自动诊断、问题求解,解决传统方法所不能或难以解决的问题。人工神经网络系统具有很高的容错性、鲁棒性及自组织性,即使连接线遭到很高程度的破坏, 它仍能处在优化工作状态,这点在军事系统电子设备中得到广泛的应用。现有的智能信息系统有智能仪器、自动跟踪监测仪器系统、自动控制制导系统、自动故障诊断和报警系统等。
2. 模式识别
模式识别是对表征事物或现象的各种形式的信息进行处理和分析,来对事物或现象进行描述、辨认、分类和解释的过程。该技术以贝叶斯概率论和申农的信息论为理论基础,对信息的处理过程更接近人类大脑的逻辑思维过程。现在有两种基本的模式识别方法,即统计模式识别方法和结构模式识别方法。人工神经网络是模式识别中的常用方法,近年来发展起来的人工神经网络模式的识别方法逐渐取代传统的模式识别方法。经过多年的研究和发展,模式识别已成为当前比较先进的技术,被广泛应用到文字识别、语音识别、指纹识别、遥感图像识别、人脸识别、手写体字符的识别、工业故障检测、精确制导等方面。
人工神经网络在医学中的应用
由于人体和疾病的复杂性、不可预测性,在生物信号与信息的表现形式上、变化规律(自身变化与医学干预后变化)上,对其进行检测与信号表达,获取的数据及信息的分析、决策等诸多方面都存在非常复杂的非线性联系,适合人工神经网络的应用。目前的研究几乎涉及从基础医学到临床医学的各个方面,主要应用在生物信号的检测与自动分析,医学专家系统等。
1. 生物信号的检测与分析
大部分医学检测设备都是以连续波形的方式输出数据的,这些波形是诊断的依据。人工神经网络是由大量的简单处理单元连接而成的自适应动力学系统, 具有巨量并行性,分布式存贮,自适应学习的自组织等功能,可以用它来解决生物医学信号分析处理中常规法难以解决或无法解决的问题。神经网络在生物医学信号检测与处理中的应用主要集中在对脑电信号的分析,听觉诱发电位信号的提取、肌电和胃肠电等信号的识别,心电信号的压缩,医学图像的识别和处理等。
2. 医学专家系统
传统的专家系统,是把专家的经验和知识以规则的形式存储在计算机中,建立知识库,用逻辑推理的方式进行医疗诊断。但是在实际应用中,随着数据库规模的增大,将导致知识“爆炸”,在知识获取途径中也存在“瓶颈”问题,致使工作效率很低。以非线性并行处理为基础的神经网络为专家系统的研究指明了新的发展方向, 解决了专家系统的以上问题,并提高了知识的推理、自组织、自学习能力,从而神经网络在医学专家系统中得到广泛的应用和发展。在麻醉与危重医学等相关领域的研究中,涉及到多生理变量的分析与预测,在临床数据中存在着一些尚未发现或无确切证据的关系与现象,信号的处理,干扰信号的自动区分检测,各种临床状况的预测等,都可以应用到人工神经网络技术。
人工神经网络在经济领域的应用
1. 市场价格预测
对商品价格变动的分析,可归结为对影响市场供求关系的诸多因素的综合分析。传统的统计经济学方法因其固有的局限性,难以对价格变动做出科学的预测,而人工神经网络容易处理不完整的、模糊不确定或规律性不明显的数据,所以用人工神经网络进行价格预测是有着传统方法无法相比的优势。从市场价格的确定机制出发,依据影响商品价格的家庭户数、人均可支配收入、贷款利率、城市化水平等复杂、多变的因素,建立较为准确可靠的模型。该模型可以对商品价格的变动趋势进行科学预测,并得到准确客观的评价结果。
2. 风险评估
风险是指在从事某项特定活动的过程中,因其存在的不确定性而产生的经济或财务的损失、自然破坏或损伤的可能性。防范风险的最佳办法就是事先对风险做出科学的预测和评估。应用人工神经网络的预测思想是根据具体现实的风险来源, 构造出适合实际情况的信用风险模型的结构和算法,得到风险评价系数,然后确定实际问题的解决方案。利用该模型进行实证分析能够弥补主观评估的不足,可以取得满意效果。
人工神经网络在控制领域中的应用
人工神经网络由于其独特的模型结构和固有的非线性模拟能力,以及高度的自适应和容错特性等突出特征,在控制系统中获得了广泛的应用。其在各类控制器框架结构的基础上,加入了非线性自适应学习机制,从而使控制器具有更好的性能。基本的控制结构有监督控制、直接逆模控制、模型参考控制、内模控制、预测控制、最优决策控制等。
人工神经网络在交通领域的应用
今年来人们对神经网络在交通运输系统中的应用开始了深入的研究。交通运输问题是高度非线性的,可获得的数据通常是大量的、复杂的,用神经网络处理相关问题有它巨大的优越性。应用范围涉及到汽车驾驶员行为的模拟、参数估计、路面维护、车辆检测与分类、交通模式分析、货物运营管理、交通流量预测、运输策略与经济、交通环保、空中运输、船舶的自动导航及船只的辨认、地铁运营及交通控制等领域并已经取得了很好的效果。
人工神经网络在心理学领域的应用
从神经网络模型的形成开始,它就与心理学就有着密不可分的联系。神经网络抽象于神经元的信息处理功能,神经网络的训练则反映了感觉、记忆、学习等认知过程。人们通过不断地研究, 变化着人工神经网络的结构模型和学习规则,从不同角度探讨着神经网络的认知功能,为其在心理学的研究中奠定了坚实的基础。近年来,人工神经网络模型已经成为探讨社会认知、记忆、学习等高级心理过程机制的不可或缺的工具。人工神经网络模型还可以对脑损伤病人的认知缺陷进行研究,对传统的认知定位机制提出了挑战。
虽然人工神经网络已经取得了一定的进步,但是还存在许多缺陷,例如:应用的面不够宽阔、结果不够精确;现有模型算法的训练速度不够高;算法的集成度不够高;同时我们希望在理论上寻找新的突破点, 建立新的通用模型和算法。需进一步对生物神经元系统进行研究,不断丰富人们对人脑神经的认识。
人工神经网络模型的种类
人工神经网络模型的发展从最早的多层感知机(MLP)模型开始,可以一直追溯到后期的卷积神经网络模型(CNN)、循环神经网络模型(RNN)这些基本的模型,以及它们的变种模型,也可以追溯到组合式的模型,比如由前面的基本模型组成的自编码神经网络模型(AE)、生成式对抗神经网络模型(GAN)、深度强化学习模型(DRL),以及后期出现的注意力模型(Attention Model)、transformer模型,甚至是图神经网络(GNN),以及比较前沿的量子神经网络(QNN)等等。根据不同的任务类型所设计出来的神经网络模型,在形状和结构类型上也大不一样。
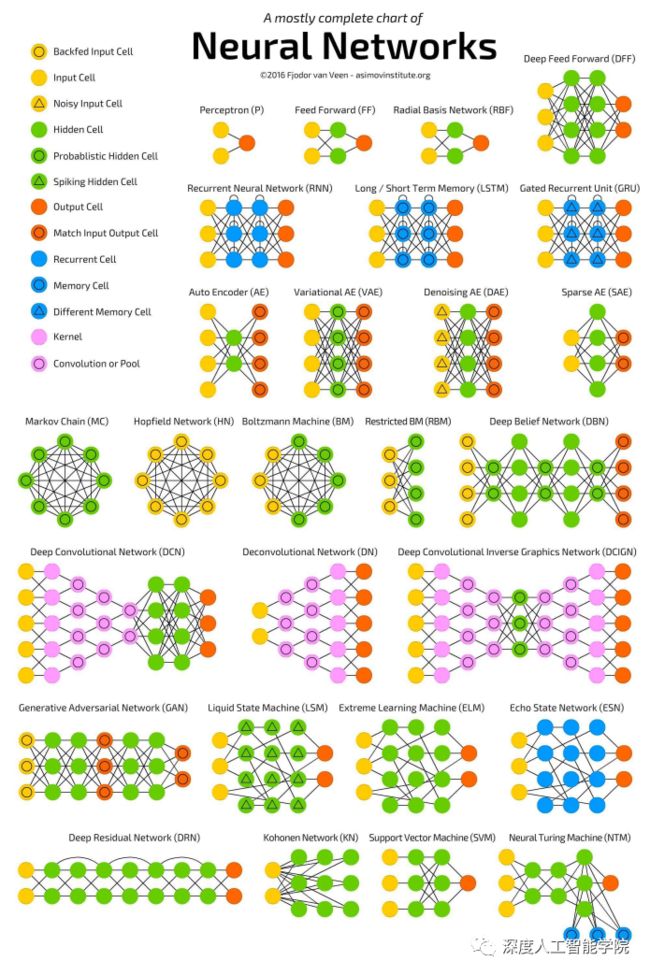
其中以卷积神经网络的模型和transformer的模型变种最多,卷积神经网络的模型发展从1994年的LNet开始,一直到现在为止,在各大顶刊论文中所出现的卷积模型不下百种,下面列出其中比较常见的一些卷积模型:
-
LNet
LeNet诞生于1994年,由深度学习三巨头之一的Yan LeCun提出,他也被称为卷积神经网络之父。LeNet主要用来进行手写字符的识别与分类,准确率达到了98%,并在美国的银行中投入了使用, LeNet奠定了现代卷积神经网络的基础。
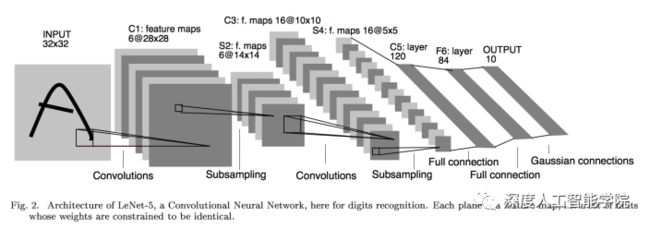
LeNet网络除去输入输出层总共有六层网络,卷积核都是5*5的,stride=1,池化都是平均池化:conv->pool->conv->pool->-conv(fc)->fc
-
AlexNet
AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。
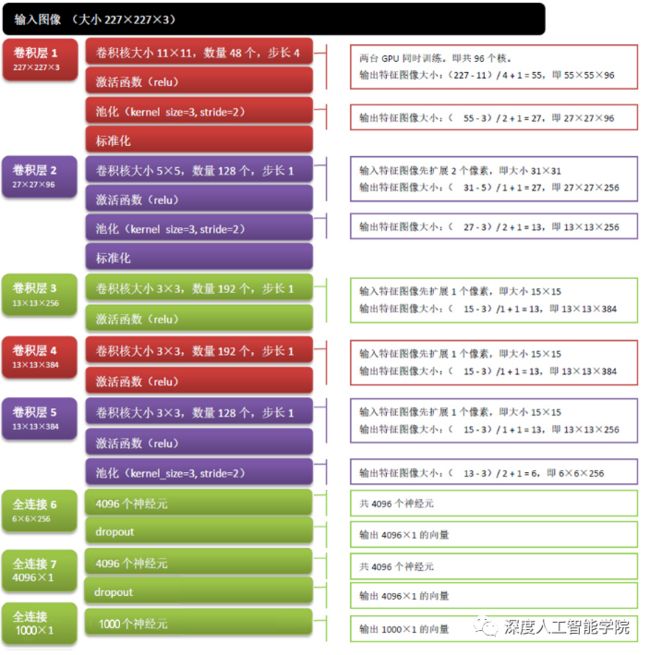
AlexNet较之前LNet的改变主要有以下几点:
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN(局部响应归一化)层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(5)使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。
(6)数据增强,随机地从256*256的原始图像中截取224*224大小的区域(以及水平翻转的镜像),相当于增加了2*(256-224)^2=2048倍的数据量。如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提升泛化能力。
-
VGGNet
VGGNet是牛津大学计算机视觉组和Google DeepMind公司一起研发的深度卷积神经网络,并取得了2014年Imagenet比赛定位项目第一名和分类项目第二名。vgg版本很多,常用的是VGG16,VGG19网络。
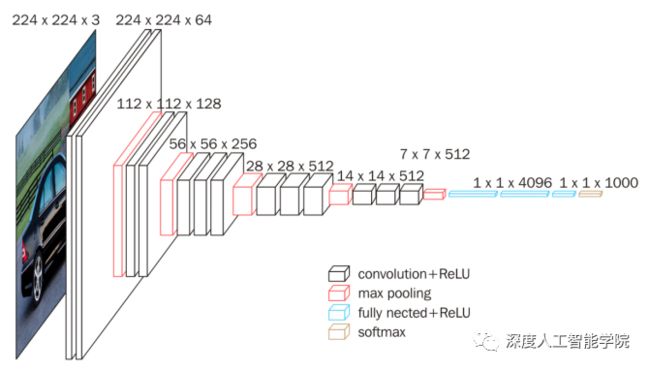
上图为VGG16的网络结构,共16层(不包括池化和softmax层),所有的卷积核都使用3*3的大小,池化都使用大小为2*2,步长为2的最大池化,卷积层深度依次为64 -> 128 -> 256 -> 512 ->512。VGG-16有16个卷积层或全连接层,包括五组卷积层和3个全连接层,即:16=2+2+3+3+3+3。
VGGNet网络结构和AlexNet相像,不同的地方在于:
1.VGGNet网络层非常深,把网络层数加到了16-19层(不包括池化和softmax层),而AlexNet是8层结构。
2.将卷积层提升到卷积块的概念。卷积块有2~3个卷积层构成,使网络有更大感受野的同时能降低网络参数,同时多次使用ReLu激活函数有更多的线性变换,学习能力更强。
3.在训练时和预测时使用Multi-Scale做数据增强。训练时将同一张图片缩放到不同的尺寸,在随机剪裁到224*224的大小,能够增加数据量。预测时将同一张图片缩放到不同尺寸做预测,最后取平均值。

作者同时对网络做了一定改进,也发现了一些问题,得出了一些结论:
1、LRN层无性能增益(A-LRN)VGG作者通过网络A-LRN发现,AlexNet曾经用到的LRN层(local response normalization,局部响应归一化)并没有带来性能的提升,因此在其它组的网络中均没再出现LRN层。2、随着深度增加,分类性能逐渐提高(A、B、C、D、E)从11层的A到19层的E,网络深度增加对top1和top5的错误率下降很明显。3、多个小卷积核比单个大卷积核性能好(B)VGG作者做了实验用B和自己一个不在实验组里的较浅网络比较,较浅网络用conv5x5来代替B的两个conv3x3,结果显示多个小卷积核比单个大卷积核效果要好。
-
GoogLeNet(Google Inception Net)
googleNet是2014年的ILSVRC的冠军模型,GoogleNet做了更大胆的网络上的尝试,而不是像vgg继承了lenet以及alexnet的一切框架。GoogleNet虽然有22层,但是参数量只有AlexNet的1/12。
GoogleNet论文指出获得高质量模型最保险的做法就是增加模型的深度,或者是它的宽度,但是一般情况下,更深和更宽的网络会出现以下问题:
1、参数太多,容易过拟合,如果训练数据有限,则这一问题更加突出;
2、网络越大计算复杂度越大,难以应用;
3、网络越深,容易出现梯度消失问题。
总之更大的网络容易产生过拟合,并且增加了计算量。GoogleNet给出的解决方案:将全连接层甚至一般的卷积都转化为稀疏连接。
GoogleNet为了保持神经网络结构的稀疏性,又能充分利用密集矩阵的高计算性能,提出了名为Inception的模块化结构来实现此目的。依据就是大量文献都表明,将稀疏矩阵聚类为比较密集的子矩阵可以提高计算性能。(这一块我没有很明白,是百度到的知识,但是关键在于GoogleNet提出了Inception这个模块化结构,在2020年的今日,这个模块依然有巨大作用)
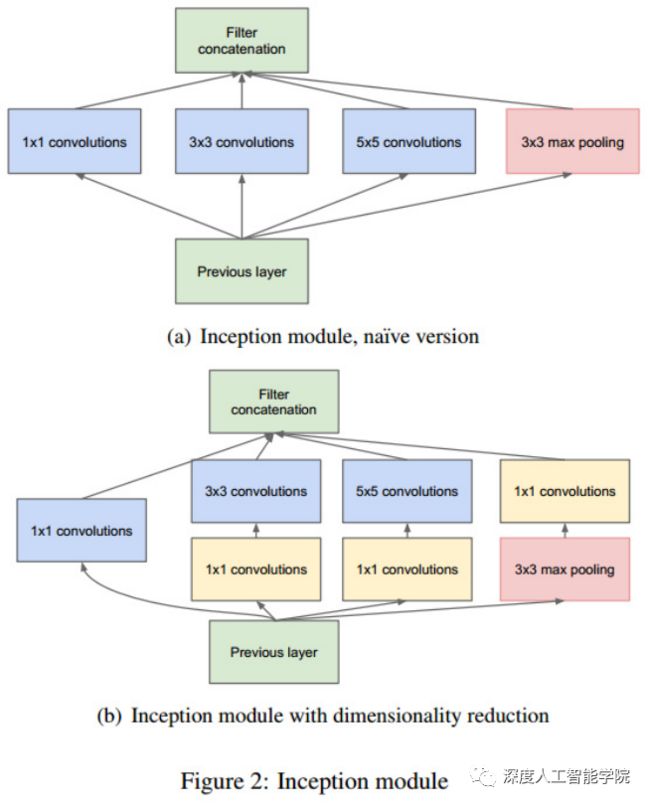
-
SqueezeNet
SqueezeNet是Han等提出的一种轻量且高效的CNN模型,它参数比AlexNet少50x,但模型性能(accuracy)与AlexNet接近。在可接受的性能下,小模型相比大模型,具有很多优势:(1)更高效的分布式训练,小模型参数小,网络通信量减少;(2)便于模型更新,模型小,客户端程序容易更新;(3)利于部署在特定硬件如FPGA,因为其内存受限。因此研究小模型是很有现实意义的。Han等将CNN模型设计的研究总结为四个方面:
(1)模型压缩:对pre-trained的模型进行压缩,使其变成小模型,如采用网络剪枝和量化等手段;
(2)CNN微观结构:对单个卷积层进行优化设计,如采用1x1的小卷积核,还有很多采用可分解卷积(factorized convolution)结构或者模块化的结构(blocks, modules);
(3)CNN宏观结构:网络架构层面上的优化设计,如网路深度(层数),还有像ResNet那样采用“短路”连接(bypass connection);
(4)设计空间:不同超参数、网络结构,优化器等的组合优化。
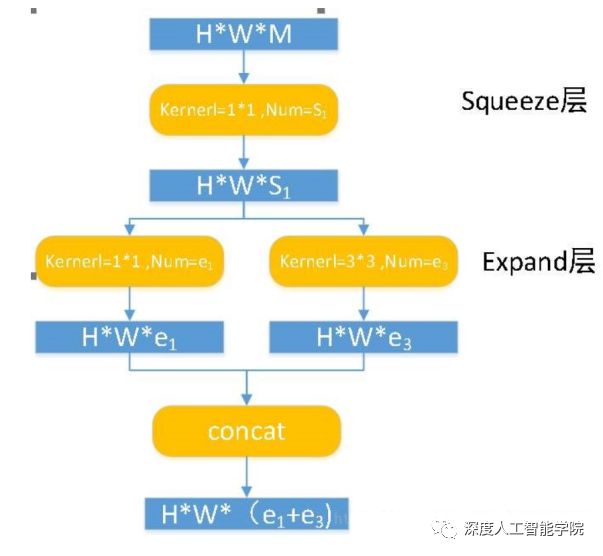
SqueezeNet也是从这四个方面来进行设计的,其设计理念可以总结为以下三点:
(1)大量使用1x1卷积核替换3x3卷积核,因为参数可以降低9倍;
(2)减少3x3卷积核的输入通道数(input channels),因为卷积核参数为:(numberof input channels) * (number of filters) * 3 * 3.
(3)延迟下采样(downsample),前面的layers可以有更大的特征图,有利于提升模型准确度。目前下采样一般采用strides>1的卷积层或者pool layer。
-
ResNet
ResNet(Residual Neural Network)由微软研究院的Kaiming He等四名华人提出,通过使用ResNet Unit成功训练出了152层的神经网络,并在ILSVRC2015比赛中取得冠军,在top5上的错误率为3.57%,同时参数量比VGGNet低,效果非常突出。ResNet的结构可以极快的加速神经网络的训练,模型的准确率也有比较大的提升。同时ResNet的推广性非常好,甚至可以直接用到InceptionNet网络中。
ResNet的主要思想是在网络中增加了直连通道,即Highway Network的思想。此前的网络结构是性能输入做一个非线性变换,而Highway Network则允许保留之前网络层的一定比例的输出。ResNet的思想和Highway Network的思想也非常类似,允许原始输入信息直接传到后面的层中,如下图所示。关注成都深度智谷科技——深度人工智能学院,了解更多的人工智能知识。

ResNet主要的作用有以下三点:
一、解决了梯度弥散问题
二、解决了网络退化问题
三、适合解决各种复杂的问题
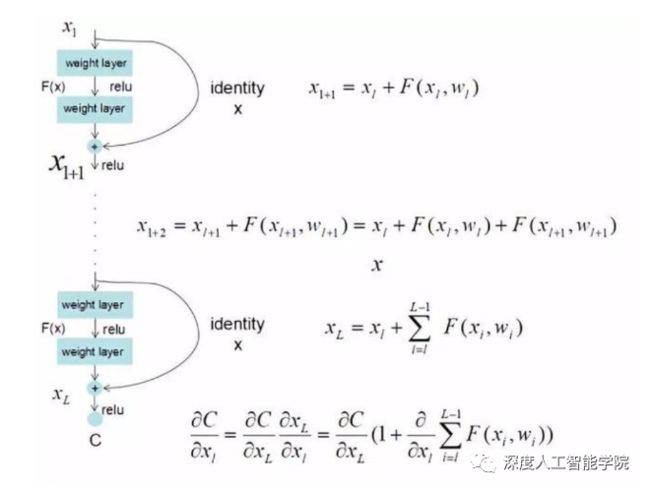
ResNet最终更新某一个节点的参数时,由于h(x)=F(x)+x,使得链式求导后的结果如图所示,不管公式右边部分的求导参数有多小,因为有x的导数1的存在,并且将原来的链式求导中的连乘变成了连加状态都能保证该节点参数更新不会发生梯度消失或梯度爆炸现象。
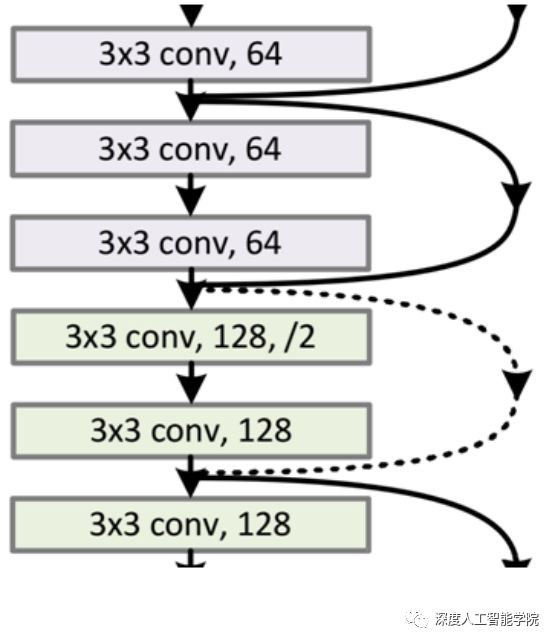
在引入ResNet之前,我们想让该层学习到的参数能够满足h(x)=x,即输入是x,经过该冗余层后,输出仍然为x。但是要想学习h(x)=x恒等映射时的这层参数时比较困难的。ResNet想到避免去学习该层恒等映射的参数,可以让h(x)=F(x)+x,这里的F(x)我们称作残差项,我们发现,要想让该冗余层能够恒等映射,我们只需要学习F(x)=0。学习F(x)=0比学习h(x)=x要简单,因为一般每层网络中的参数初始化偏向于0,这样在相比于更新该网络层的参数来学习h(x)=x,该冗余层学习F(x)=0的更新参数能够更快收敛。
-
DenseNet
DenseNet是CVPR 2017的best paper,在ResNet的基础上进行改进优化。DenseNet和ResNet的核心思想都是创建一个跨层连接来连通网络的前后层,在DenseNet中作者为了最大化层级之间的信息流,将所有层两两进行连接,这也是DenseNet(Densely Connected Convolutional Networks)名字的意义所在,密集的网络连接。
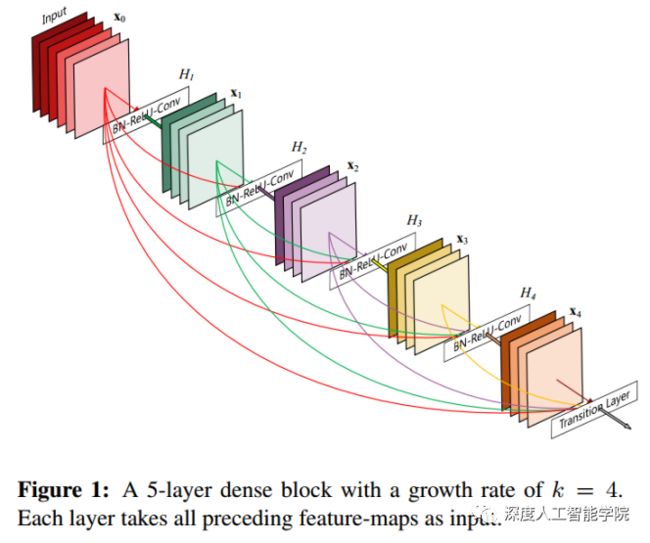
DenseNet作为另一种拥有较深层数的卷积神经网络,具有如下优点:
1、减轻了vanishing-gradient(梯度消失)2、加强了feature的传递3、更有效地利用了feature4、一定程度上较少了参数数量
-
MobileNet
MobileNets是为移动和嵌入式设备提出的高效模型。MobileNets基于流线型架构(streamlined),使用深度可分离卷积(depthwise separable convolutions,即Xception变体结构)来构建轻量级深度神经网络。
MobileNet的基本单元是深度级可分离卷积(depthwise separable convolution),其实这种结构之前已经被使用在Inception模型中。深度级可分离卷积其实是一种可分解卷积操作(factorized convolutions),其可以分解为两个更小的操作:depthwise convolution和pointwise convolution,Depthwise convolution和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上(input channels),而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise convolution是depth级别的操作。
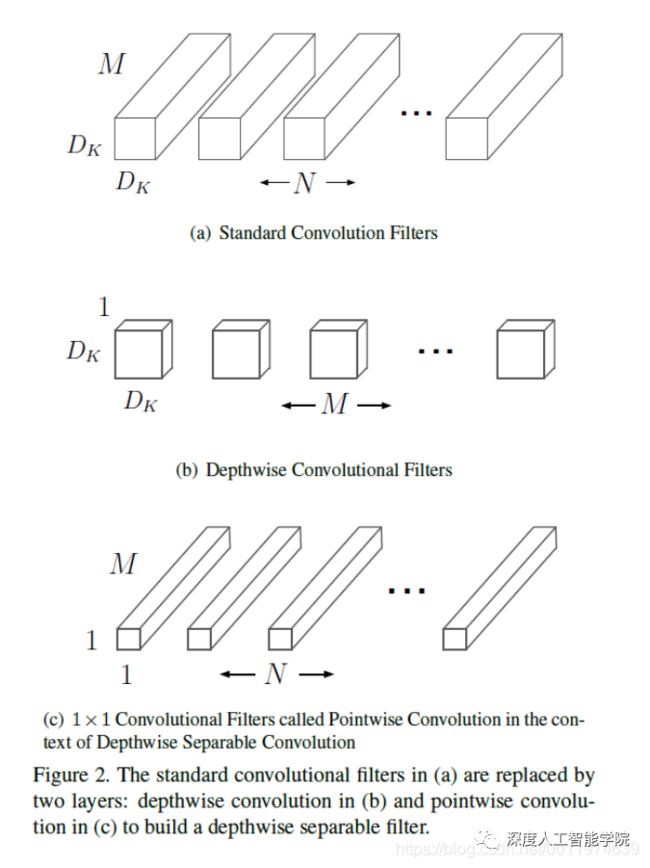
而pointwise convolution其实就是普通的卷积,只不过其采用1x1的卷积核。对于depthwise separable convolution,其首先是采用depthwise convolution对不同输入通道分别进行卷积,然后采用pointwise convolution将上面的输出再进行结合,这样其实整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。

-
ShuffleNet
ShuffleNet v1是由旷视科技在2017年底提出的轻量级可用于移动设备的卷积神经网络。该网络创新之处在于,使用pointwise group convolution还有channel shuffle,保证网络准确率的同时,大幅度降低了所需的计算资源。
在一般的神经网络网络中,pointwise convolution的出现使得所需计算量极大的增多,于是作者提出了pointwise group convolution来降低计算量,但是group与group之间的几乎没有联系,影响了网络的准确率,于是作者又提出了channel shuffle来加强group之间的联系。在一定计算复杂度下,网络允许更多的通道数来保留更多的信息,这恰恰是轻量级网络所追求的。
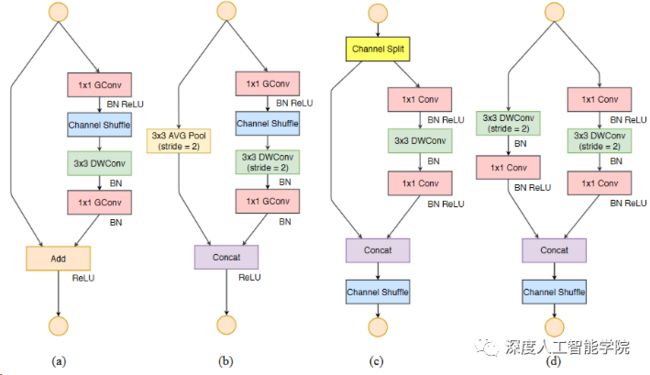
(a)和(b)是ShuffleNet v1的两种不同block结构,两者的差别在于后者对特征图尺寸做了缩小,这和ResNet中某个stage的两种block功能类似,同理(c)和(d)是ShuffleNet v2的两种不同block结构。
-
EfficientNet
卷积神经网络(ConvNets)通常是在固定的资源预算下开发的,如果有更多的资源可用,就会扩大规模以获得更好的准确性。作者系统地研究了模型缩放,发现平衡网络的深度、宽度和分辨率可以得到更好的性能。在此基础上,作者提出了一种新的尺度划分方法,即利用简单而高效的复合系数来均匀地划分深度/宽度/分辨率各维度。
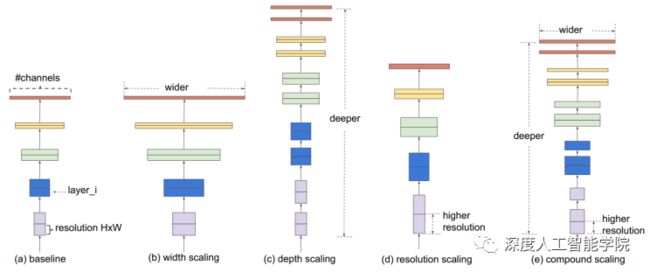
作者希望找到一个可以同时兼顾速度与精度的模型放缩方法,为此,作者重新审视了前人提出的模型放缩的几个维度:网络深度、网络宽度、图像分辨率,前人的文章多是放大其中的一个维度以达到更高的准确率,比如 ResNet-18 到 ResNet-152 是通过增加网络深度的方法来提高准确率。作者跳出了前人对放缩模型的理解,从一个高度去审视这些放缩维度。作者认为这三个维度之间是互相影响的并探索出了三者之间最好的组合,在此基础上提出了最新的网络 EfficientNet(基于神经网络搜索)。
那么第一个问题就是:单个维度做scaling存在什么问题吗?针对这个问题,作者做了这个实验,也就是针对某个分类网络的3个维度(宽度、深度和分辨率)分别做model scaling的结果对比。显然,单独优化这3个维度都能提升模型效果,但上限也比较明显,基本上在Acc达到80后提升就很小了:
1、单纯增加层数(深度d)和精度的增加变化呈log函数,也就是说深度达到一定程度后,精度的增加就很小了,但是参数量却还在不断变大。
2、同理,只对通道(宽度w)的增加也和精度的增加变化呈log函数。
3、输入图像(分辨率r)越大,精度越高,但是它们之间也呈log函数。
结论:三个维度中任一维度的放大都可以带来精度的提升,但随着倍率越来越大,提升却越来越小。

如何找到平衡参数(分辨率、深度、宽度)和精度之间的指标是首要任务。既满足参数量少,又满足精度高。如果简单的根据给定上面的3个参数参数设计模型进行训练,显然是不可行的,这样的效率太低下。
作者提出了一种混合维度放大法(compound scaling method),该方法使用一个混合系数,先设计搜索一个较小(深度d和宽度w)的网络做为基础网络,传入较小的图片(分辨率r,一般为224),先获得比较好的精度,然后增加一定的深度倍数α、宽度倍数β、、分辨率倍数γ,在参数计算量增加2倍,并且精度最高的情况下搜索到了一组最佳的参数α=1.2,β=1.1,γ=1.15 ,参数即满足公式:α*β²*γ²≈2,(α≥1,β≥1,γ≥1)。

神经网络的模型还有很多,包括后面的RepVGG、botnet、nfnet、ResNet-RS等,以及以transformer为主的TRDT、ViT、CvT、Swin Transformer、Twins 、informer等模型。有兴趣的同学可以慢慢去研究。关注成都深度智谷科技——深度人工智能学院,获取更多人工智能知识。
结语——神经网络的未来
按照神经网络的发展来看,未来发展方向主要有下面几个方向。一是在远程服务器上的模型会更大、参数更多、功能更强,主要解决大型的复杂难题;另一方向是在本地边缘设备上运行的模型发展会更小、参数更少、效率更快,主要是解决一些实时需求的任务问题;还有就是基于不同厂家的各种专用设备的专用模型。
不管模型细分领域的发展方向如何,找到适合自己项目任务的模型去训练,圆满完成上面交代的任务才是炼丹师们该去重点关注的。
关注微信公众号:深度人工智能学院,获取更多人工智能方面的知识!


官方公众号 官方微信号