Big Data Management笔记04:SparkSQL和PySpark MLlib
Big Data Management笔记04:SparkSQL和PySpark MLlib
- Spark SQL
-
- Dataframe
-
- Create Dataframe
- Dataframe Operations
- More on Dataframes
-
- Columnar Storage(柱状存储)
- Dataframe and RDD
- Schemas in DataFrame
- Plan Optimization & Execution
-
- Logical Plan
- Physical Plan
- PySpark MLlib
-
- Pipeline
- Stacking(模型堆叠)
Spark SQL
之所以去使用Spark SQL,是为了处理表格(Table)这种普遍存在的结构化数据。对于表格这种结构化数据,想必大家都已经在数据库系统中进行了学习,因此对其不再做过多的介绍,我们只需知道,Spark SQL是为此特定结构创建定制的一种工具/平台。
Spark SQL从Spark 1.0起就是其一个核心部分,它的基本思想就是用SQL或者类似SQL的方法来对RDD进行变换(Transform)操作。Spark SQL可以整合来自不同来源的数据,比如JSON, CSV, Hive, Parquet等。
这里我们需要注意的一个概念是“Spark SQL与SQL无关”,我们使用Spark SQL的目的是在已知RDD是结构化数据(Table)的前提下,使得Spark程序的创建和运行更快,它与DBMS中的SQL是不同的。
这里我们先给出一个例子,这里用RDD和Spark SQL两种方法来进行操作,可以进行一个直观的对比:

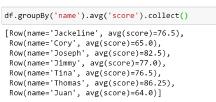
*这里的的df是一个DataFrame
Dataframe
Dataframe是一种以列(Column)进行组织的分布式数据集合我们在使用Python的时候,常用Pandas对其进行处理。在大数据中,尽管Datafreame和RDD存在一些差别,但我们通常认为Dataframe就是RDD,因此RDD API可用于Dataframe(但反之不行)。
Dataframe主要有以下特征:
- 能够将单个笔记本电脑上的KB级数据扩展到大型群集上的PB级别数据,这意味着它能够处理不同量级的数据
- 支持多种数据格式和存储系统
- 通过Spark SQL Catalyst优化器进行最先进的优化和代码生成
- 通过Spark与所有大数据工具和基础架构无缝集成
- 适用于Python,Java,Scala和R的API
总的来说,对于已经在其他语言中对dataframe很熟悉的用户来说,该API能让他们更自如。对于Spark用户来说,该API能让Spark更易于编程。同时DataFrames将通过智能优化和代码生成来提高性能。
Spark SQL的Data Source API可以用不同的格式读写dataframe:

Create Dataframe
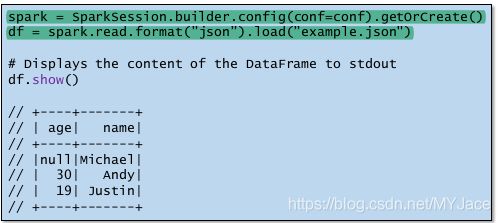
要创建Dataframe,首先要初始化一个SparkSession。SparkSession是使用Dataset和DataFrame API编程Spark的入口点。
这里给出一个从JSON文件创建Dataframe的例子:
Dataframe Operations
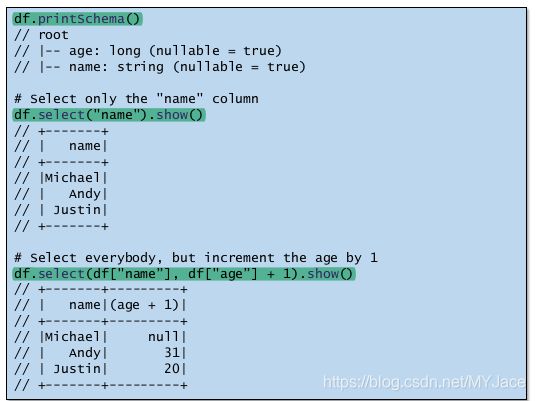
基于上面创建的Dataframe,这里给出一些基本的操作例子

这里整理一下Dataframe和Spark SQL的关系:
- DataFrames和SparkSQL从根本上相关
- DataFrames API提供了一个编程接口,实际上是一种域特定语言(DSL),用于和你的数据进行交互
- Spark SQL提供了类似SQL的界面。因此,您可以在Spark SQL中做什么,就可以在DataFrames中做什么,反之亦然
- Spark SQL允许用户使用(与DBMS中的一样的)SQL查询操作分布式数据
- 用户可以使用sql()方法通过SparkSession发出SQL查询
- sql()使应用程序能够以编程方式运行SQL查询,并将结果作为DataFrame返回
- 用户可以在同一代码中混合使用DataFrame方法和SQL查询。
这里给出一个例子:

注意:要使用SQL,需要使用registerTempTable()为DataFrame创建表别名
More on Dataframes
我们之前已经说过,Dataframes就是RDD,因此,它和RDD具备相同的Lazy Evaluation特性。即,Transformations有助于查询计划,但它们不执行任何操作,Actions才会让查询执行。这里给出一些Dataframes API中常用的Transformations和Actions:

Lazy Evaluation是一个很关键的特性,正是因为它的存在,所以有助于在查询(Query)执行之前进行规划,我们可以想象以下,如果没有Lazy Evaluation,那么每个Transformation都会立刻被执行,这样就没有留下提升查询效率的空间。
Columnar Storage(柱状存储)
在一般的表格(Table)中,基本都采用Row Format进行存储,即表格的每一行是一个tuple/record/object。而Dataframe主要使用Columnar Storage,这其实就是Row Format的转置,即将每-列(具有相同attribute)的数据打包在一起。

这样的存储形式有以下优点:
- 便于计算每一行中的offset。如果仍以Row Format进行存储,每一行中的数据有多个类型,不便于计算offset,而Column Format中,每一行的数据类型相同,计算offset更方便
- 密集存储。便于基于数据类型进行压缩
- 兼容性和零序列化(Compatibility and zero serialization
) - 对GPU / TPU有更多扩展
- 高效的查询处理。在进行join操作时,对比明显,若是row format,在进行join时,要遍历所有的数据但若是column format,不需要访问无关的列。而且,我们用column format进行存储时,会减少需要的存储节点,降低IO操作
但是同样也存在一个问题,那就是不利于Transactions。比如在进行写操作时,每当我们要添加一个新的record,我们需要对每一列都进行操作。
Dataframe and RDD
DataFrames建立在Spark RDD API之上,因此用户可以对DataFrame使用常规的RDD操作。但是,如果可能,我们尽量使用DataFrame API,因为使用RDD操作,返回的仍是RDD,而不是DataFrame,而且DataFrame API可能会更高效,因为它可以使用Catalyst优化基础操作。
DataFrame更像传统的二维数据库形式,除了数据外,还掌握数据的结构信息,即模式(Schema)
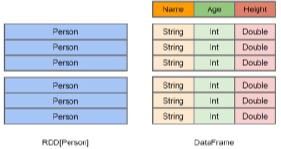
Schemas in DataFrame
Dataframe的schema和DBMS中Table的Schema是一样的,描述了数据的结构(声明了列名以及数据类型)。Spark可以从JSON文件中推断出一个schema。
如果数据文件没有schema(比如txt文件),SparkSQL会创建特定类型的RDD并让Spark从该类型推断Schema或者使用API以编程方式指定Schema。

Plan Optimization & Execution
Spark SQL拥有逻辑规划(Logical plan)和物理规划(Physical plans),由于Lazy Evaluation特性,因此可以进行优化。
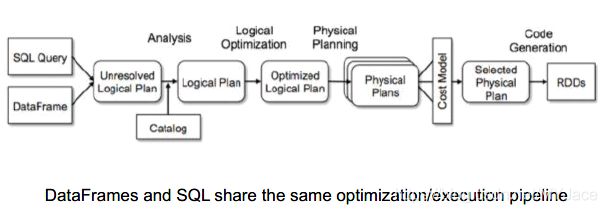
Logical Plan
Logical Plan是需要被执行的所有transformation步骤的摘要。它不会涉及有关驱动程序(Master Node)或执行程序(Worker Node)的任何内容,这些内容是由SparkContext负责的。同时,整个Logical Plan也是由SparkContext生成和存储。
Logical Plan被分为3个部分:
- Unresolved Logical Plan
- (Resolved/Analyzed) Logical Plan:
- Optimized Logical Plan
Unresolved Logical Plan:代码和语法都合法,SparkContext认为代码没有问题。但是table/column name不存在,所以需要unresolved logical plan应对这种情况。尽管我们给了一个不存在的column name,unresolved logical plan仍被创建(没有任何对column/table name的检查)
Resolved Logical Plan:Spark会使用Catalog去检查Unresolved Logical Plan,Catalog存储了所有关于spark table/dataframe的信息,Analiser 执行,它通过交叉对比catalog来决定是否拒绝。如果Analiser仍无法处理,就会拒绝该Unresolved Logical Plan。否则,Resolved Logical Plan被创建。
Optimized Logical Plan:主要进行逻辑优化,检查哪些任务可以在同一个阶段一起执行,multi-join query它可决定执行的顺序以优化效率
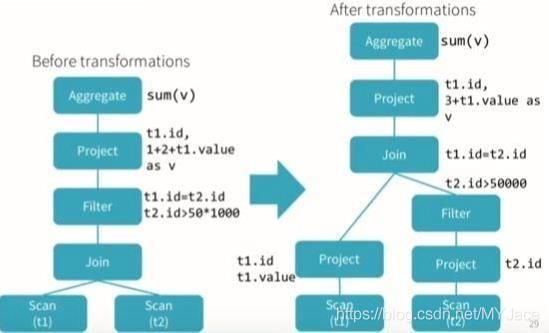
Physical Plan
Spark的内部优化,一旦Optimized Logical Plan创建,Physical Plan就会被生成。指明了Logical Plan如何在集群上执行,它会生成多个不同的执行策略(Strategy)并在cost model中进行对比。最终被选择的那个Physical Plan会生成对应的代码并被执行。
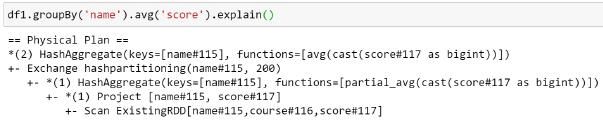
可以使用.explain()去显示最终被选择的那个Physical Plan
PySpark MLlib
Pipeline
在机器学习中,我们经常需要运行一系列的算法对数据进行处理和学习。Pipeline就是一个制定了几个操作阶段的序列,每一个阶段是一个Transformer或者Estimator,同时Pipeline中的操作按顺序进行,我们需要注意的是Pipeline的输入是Dataframe。
- Transformer:输入和输出都是dataframe,负责处理数据。(对Dataframes调用.transform())
- Estimator:调用.fit()方法以生成一个Transformer(它成为PipelineModel或拟合的Pipeline的一部分)
下面给出一个例子:
首先读取数据集

之后建立Pipeline进行预处理

之后对模型进行训练和评估

Stacking(模型堆叠)
集成学习(Ensemble Learning)主要分为三类:bagging,boosting和stacking。前两者在机器学习中已经了解过了,这里只介绍最后一种。
其实它的概念很简单,我们主要先定义一些基分类器(Base Classifier)和一个元分类器(Meta Classifier),然后用这些基分类器的输出作为特征值,输入给元分类器进行训练。
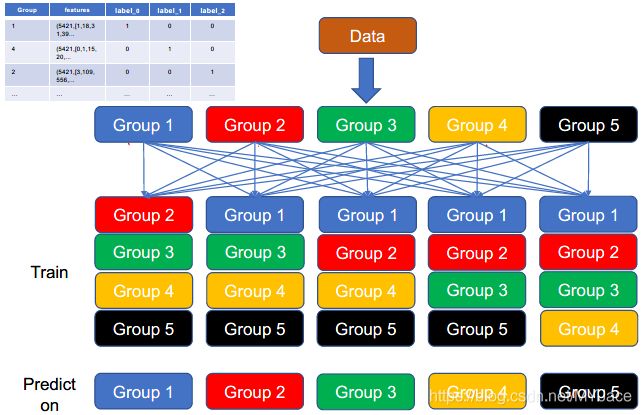
因此,模型堆叠的具体流程为:

这里我们需要注意的一点是,在对基分类器进行训练时,我们一般不会用整个训练集用来训练,这样容易造成过拟合。因此,我们一般借鉴Cross-validation的思想。
比如,我们设定了两个基分类器(一个NB分类器和一个SVM),一个元分类器(一个逻辑回归分类器)。在训练过程中,我们采用5-fold训练法,即将训练集分为5份,因此,一共要进行5次迭代。每次迭代中,我们用4份数据来训练两个基分类器,然后用剩下的1份数据来进行预测,预测的结果经过处理后作为元特征数据(Meta Features)输入给元分类器进行训练。
在进行检测的时候,我们只需要将测试集数据输入给训练好的两个基分类器进行预测,将结果输入给元分类器进行预测,得到最后预测结果。
训练大致如下图所示: