elastic 概述
引言
1.1 海量数据
在海量数据中执行搜索功能时,如果使用MySQL,效率太低。
1.2 全文检索
在海量数据中执行搜索功能时,如果使用MySQL,效率太低。
1.3 高亮显示
将搜索关键字,以红色的字体展示。
ES概述 ES 也是一个nosql
ES的介绍
ES是一个使用Java语言并且基于Lucene编写的搜索引擎框架,他提供了分布式的全文搜索功能,提供了一个统一的基于RESTful风格的WEB接口,官方客户端也对多种语言都提供了相应的API。
Lucene:Lucene本身就是一个搜索引擎的底层。
分布式:ES主要是为了突出他的横向扩展能力。
全文检索:将一段词语进行分词,并且将分出的单个词语统一的放到一个分词库中,在搜索时,根据关键字去分词库中检索,找到匹配的内容。(倒排索引)
RESTful风格的WEB接口:操作ES很简单,只需要发送一个HTTP请求,并且根据请求方式的不同,携带参数的同,执行相应的功能。
应用广泛:Github.com,WIKI,Gold Man用ES每天维护将近10TB的数据。
ES和Solr
Solr在查询死数据时,速度相对ES更快一些。但是数据如果是实时改变的,Solr的查询速度会降低很多,ES的查询的效率基本没有变化。
Solr搭建基于需要依赖Zookeeper来帮助管理。ES本身就支持集群的搭建,不需要第三方的介入。
最开始Solr的社区可以说是非常火爆,针对国内的文档并不是很多。在ES出现之后,ES的社区火爆程度直线上升,ES的文档非常健全。
ES对现在云计算和大数据支持的特别好。
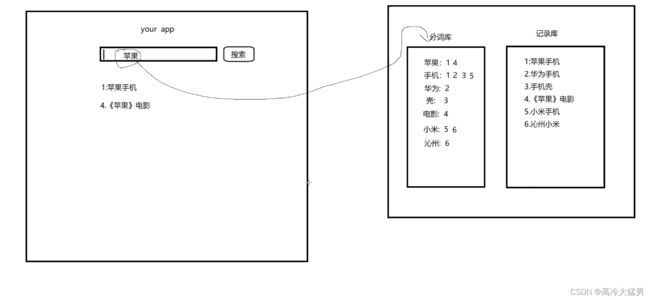
倒排索引
将存放的数据,以一定的方式进行分词,并且将分词的内容存放到一个单独的分词库中。
当用户去查询数据时,会将用户的查询关键字进行分词。
然后去分词库中匹配内容,最终得到数据的id标识。
根据id标识去存放数据的位置拉取到指定的数据。
ElasticSearch安装
usr/local/docker/es 目录下 vim docker-compose.yml文件 kibana es的图形化管理工具 ip改为自己的ip
version: "3.1"
services:
elasticsearch:
image: daocloud.io/library/elasticsearch:6.5.4
restart: always
container_name: elasticsearch
ports:
- 9200:9200
kibana:
image: daocloud.io/library/kibana:6.5.4
restart: always
container_name: kibana
ports:
- 5601:5601
environment:
- elasticsearch_url=http://192.168.199.109:9200
depends_on:
- elasticsearch安装IK分词器
下载IK分词器的地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.5.4/elasticsearch-analysis-ik-6.5.4.zip
由于网络问题,采用国内的路径去下载:http://tomcat01.qfjava.cn:81/elasticsearch-analysis-ik-6.5.4.zip
进去到ES容器内部,跳转到bin目录下,执行bin目录下的脚本文件:
./elasticsearch-plugin install http://tomcat01.qfjava.cn:81/elasticsearch-analysis-ik-6.5.4.zip
重启ES的容器,让IK分词器生效。
如果以上方法执行不了,可以采用本地离线方法
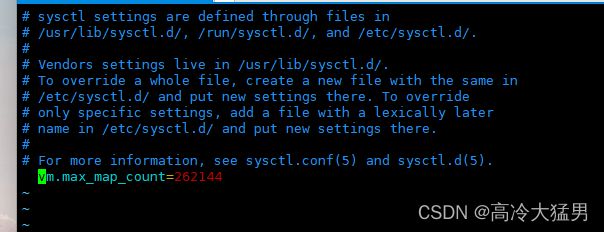
注意:如果进入el容器闪退,要增加虚拟内存
去这编辑这个文件 vim /etc/sysctl.conf
设置 vm的虚拟内存大小 vm.max_map_count=262144
查看设置完成的内存状态 sysctl -p
![]()
分词器离线安装
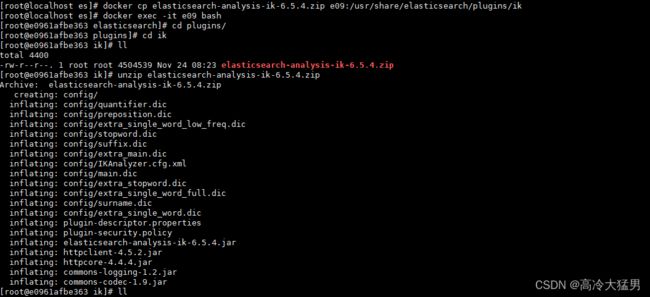
进入es容器内部,找到plugins目录,创建一个ik目录,进入ik,pwd找见当前地址
退出容器,docker cp ik 分词器 容器id:刚pwd地址
进去容器目录 unzip ik分词器解压
退出容器重启es就好了

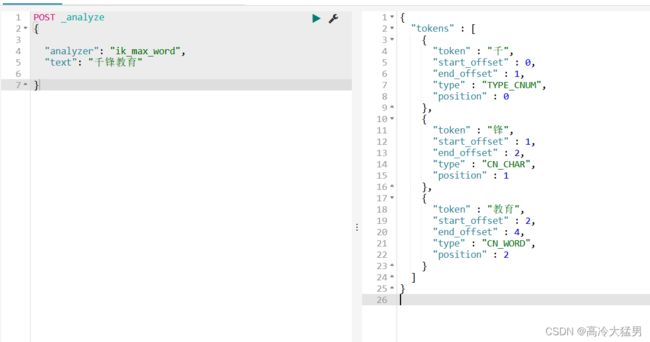
安装好之后 访问9200 有了页面就好了 安装ik分词器为了支持中文分词
以下是案例 analyze 分析
ElasticSearch基本操作
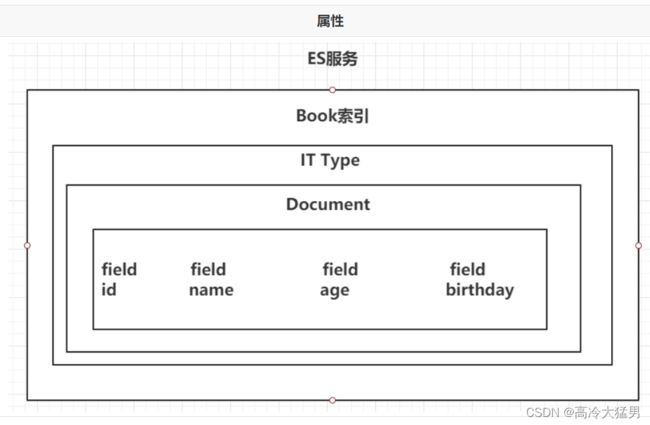
ES的结构
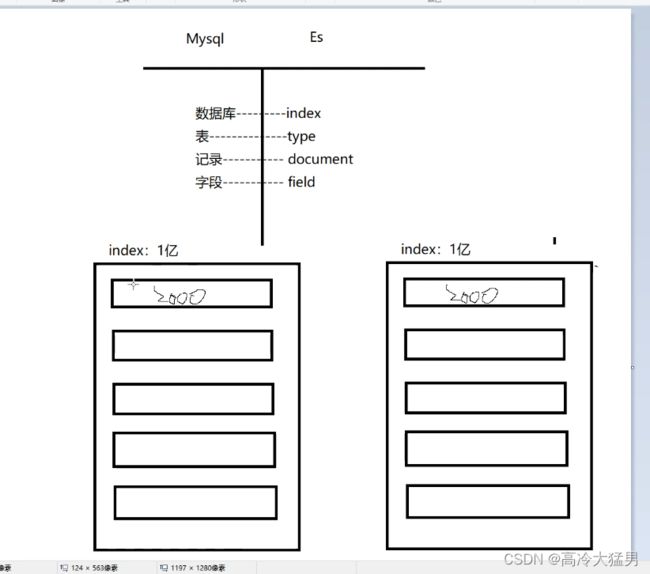
1.索引Index,分片和备份 相当于mysql的数据库
ES的服务中,可以创建多个索引。
解释:索引 index 索引相当于数据库,可以创建多个数据库
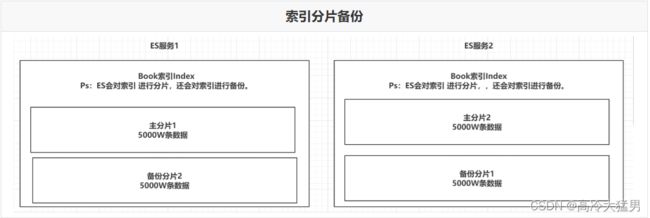
每一个索引默认被分成5片存储。
解释:每个数据库分成五片存储
每一个分片都会存在至少一个备份分片。
解释:每一分片至少一个备份分片
备份分片默认不会帮助检索数据,当ES检索压力特别大的时候,备份分片才会帮助检索数据。
备份的分片必须放在不同的服务器中。
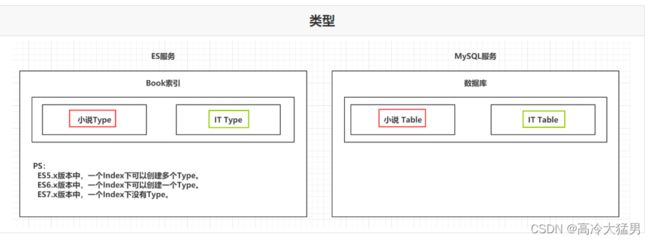
2.类型 Type 相当于数据库的表
一个索引下,可以创建多个类型。 Ps:根据版本不同,类型的创建也不同。
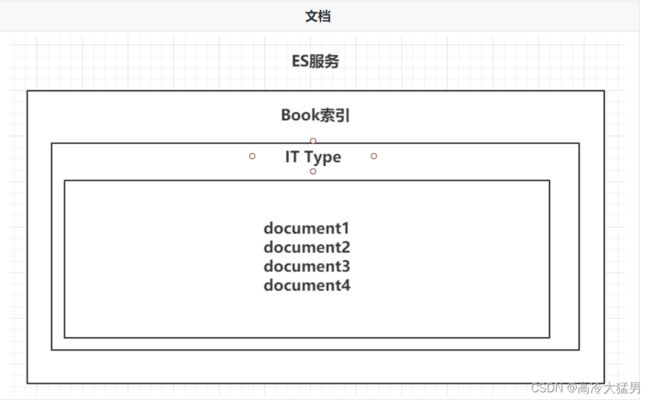
3.文档 Doc 相当于数据库的一行
一个类型下,可以有多个文档。这个文档就类似于MySQL表中的一行数据。 多个文档多行数据
4. 属性 Field 相当于mysql的列
一个文档中,可以包含多个属性。类似于MySQL表中的一行数据存在多个列。
操作ES的RESTful语法
GET请求:
http://ip:port/index:查询索引信息
http://ip:port/index/type/doc_id:查询指定的文档信息
POST请求:
http://ip:port/index/type/_search:查询文档,可以在请求体中添加json字符串来代表查询条件
http://ip:port/index/type/doc_id/_update:修改文档,在请求体中指定json字符串代表修改的具体信息
PUT请求:
http://ip:port/index:创建一个索引,需要在请求体中指定索引的信息,类型,结构
http://ip:port/index/type/_mappings:代表创建索引时,指定索引文档存储的属性的信息
DELETE请求:
http://ip:port/index:删除索引
http://ip:port/index/type/doc_id:删除指定的文档
索引的操作
创建一个索引
PUT /person
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}查看索引信息
GET /person删除索引
DELETE /person
ES中Field可以指定的类型
字符串类型:
text:一把被用于全文检索。 将当前Field进行分词。
keyword:当前Field不会被分词。
数值类型:
long:取值范围为-9223372036854774808~922337203685477480(-2的63次方到2的63次方-1),占用8个字节
integer:取值范围为-2147483648~2147483647(-2的31次方到2的31次方-1),占用4个字节
short:取值范围为-32768~32767(-2的15次方到2的15次方-1),占用2个字节
byte:取值范围为-128~127(-2的7次方到2的7次方-1),占用1个字节
double:1.797693e+308~ 4.9000000e-324 (e+308表示是乘以10的308次方,e-324表示乘以10的负324次方)占用8个字节
float:3.402823e+38 ~ 1.401298e-45(e+38表示是乘以10的38次方,e-45表示乘以10的负45次方),占用4个字节
half_float:精度比float小一半。
scaled_float:根据一个long和scaled来表达一个浮点型,long-345,scaled-100 -> 3.45
时间类型:
date类型,针对时间类型指定具体的格式
布尔类型:
boolean类型,表达true和false
二进制类型:
binary类型暂时支持Base64 encode string
范围类型:
long_range:赋值时,无需指定具体的内容,只需要存储一个范围即可,指定gt,lt,gte,lte
integer_range:同上
double_range:同上
float_range:同上
date_range:同上
ip_range:同上
经纬度类型:
geo_point:用来存储经纬度的
ip类型:
ip:可以存储IPV4或者IPV6
其他的数据类型参考官网:Field datatypes | Elasticsearch Guide [6.5] | Elastic
创建索引并指定数据结构
# 创建索引,指定数据结构
PUT /book
{
"settings": {
# 分片数
"number_of_shards": 5,
# 备份数
"number_of_replicas": 1
},
# 指定数据结构
"mappings": {
# 类型 Type
"novel": {
# 文档存储的Field
"properties": {
# Field属性名
"name": {
# 类型
"type": "text",
# 指定分词器
"analyzer": "ik_max_word",
# 指定当前Field可以被作为查询的条件
"index": true ,
# 是否需要额外存储
"store": false
},
"author": {
"type": "keyword"
},
"count": {
"type": "long"
},
"on-sale": {
"type": "date",
# 时间类型的格式化方式
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"descr": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
文档的操作
文档在ES服务中的唯一标识,
_index,_type,_id三个内容为组合,锁定一个文档,操作是添加还是修改。
新建文档
自动生成_id
# 添加文档,自动生成id
POST /book/novel
{
"name": "盘龙",
"author": "我吃西红柿",
"count": 100000,
"on-sale": "2000-01-01",
"descr": "山重水复疑无路,柳暗花明又一村"
}手动指定_id
# 添加文档,手动指定id
PUT /book/novel/1
{
"name": "红楼梦",
"author": "曹雪芹",
"count": 10000000,
"on-sale": "1985-01-01",
"descr": "一个是阆苑仙葩,一个是美玉无瑕"
}修改文档
覆盖式修改
# 添加文档,手动指定id
PUT /book/novel/1
{
"name": "红楼梦",
"author": "曹雪芹",
"count": 4353453,
"on-sale": "1985-01-01",
"descr": "一个是阆苑仙葩,一个是美玉无瑕"
}doc修改方式
# 修改文档,基于doc方式
POST /book/novel/1/_update
{
"doc": {
# 指定上需要修改的field和对应的值
"count": "1234565"
}
}删除文档
根据id删除
# 根据id删除文档
DELETE /book/novel/_id