AIGC图像生成的原理综述与落地畅想

AIGC,这个当前的现象级词语。本文尝试从文生图的发展、对其当前主流的 Stable Diffusion 做一个综述。以下为实验按要求生成的不同场景、风格控制下的生成作品。


概述
▐ 技术演进一:昙花初现 GAN 家族
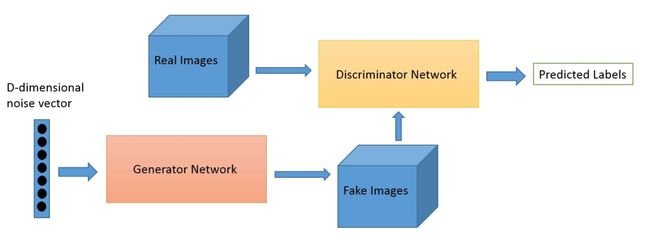
GAN 系列算法开启了图片生成的新起点。GAN的主要灵感来源于博弈论中零和博弈的思想,通过生成网络G(Generator)和判别网络D(Discriminator)不断博弈,进而使G学习到数据的分布。
G是一个生成式的网络,它接收一个随机的噪声z(随机数),通过这个噪声生成图像。
D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片。
训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量辨别出G生成的假图像和真实的图像。这样,G和D构成了一个动态的“博弈过程”,最终的平衡点即纳什均衡点。
▐ 技术演进二:小试牛刀 Auto-Regressive
自回归模型模型利用其强大的注意力机制已成为序列相关建模的范例,受GPT模型在自然语言建模中的成功启发,图像GPT(iGPT)通过将展平图像序列视为离散标记,采用Transformer进行自回归图像生成。生成图像的合理性表明,Transformer模型能够模拟像素和高级属性(纹理、语义和比例)之间的空间关系。Transformer整体主要分为Encoder和Decoder两大部分,利用多头自注意力机制进行编码和解码。在图像生成上主要有2种策略:
VQ-VAE 进行结合,首先将文本部分转换成token,利用的是已经比较成熟的SentencePiece模型;然后将图像部分通过一个离散化的AE(Auto-Encoder)转换为token,将文本token和图像token拼接到一起,之后输入到GPT模型中学习生成图像。
CLIP 结合。首先对于一幅没有文本标签的图像,使用 CLIP 的图像编码器,在语言-视觉联合嵌入空间中提取图像的 embedding。接着,将图像转换为 VQGAN 码本空间(codebook space)中的一系列离散标记。最后,再训练一个自回归 Transformer,用它来将图像标记从 Transformer 的语言-视觉统一表示中映射出对应图像。经过这样的训练后,面对一串文本描述,Transformer 就可以根据从 CLIP 的文本编码器中提取的文本嵌入生成对应的图像标记了。
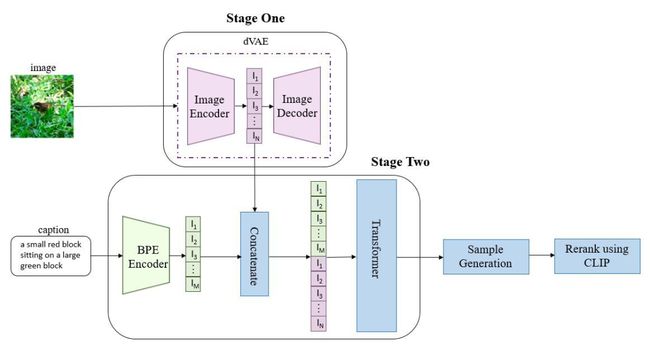
图像和文本通过各自编码器转化成序列,拼接到一起送入到 Transformer(这里用的是 GPT3)进行自回归序列生成。在推理阶段,使用预训练好的 CLIP 计算文本与生成图像的相似度,进行排序后得到最终生成图像的输出。
▐ 技术演进三:大放异彩 CLIP + Diffusion Model
沟通桥梁:CLIP 模型
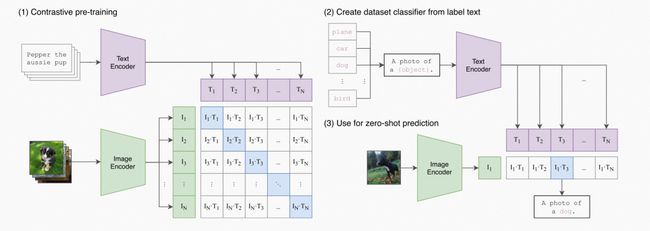
利用text信息监督视觉任务自训练,本质就是将分类任务化成了图文匹配任务,效果可与全监督方法相当 ;
CLIP 模型作为“图片-文本”预训练的底座模型,起到连接图像-文字的作用。作为后续文生图重要部分之一而持续发挥作用。
Diffusion Model
扩散模型(Diffusion Model)是一种图像生成技术,扩散模型分为两阶段:
加噪:沿着扩散的马尔可夫链过程,逐渐向图像中添加随机噪声;
去噪:学习逆扩散过程恢复图像。常见变体有去噪扩散概率模型(DDPM)等。

通过带条件引导的扩散模型学习文本特征到图像特征的映射,并对图像特征进行解码得到最终图像。DALLE-2 使用 CLIP 对文本进行编码,并使用扩散模型学习一个先验(prior)过程,得到文本特征到图像特征的一个映射;最后学习一个反转 CLIP 的过程,将图像特征解码成最终的图像。
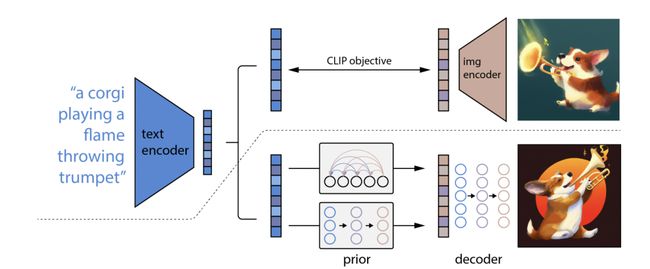
▐ 文生图主角:Stable Diffusion
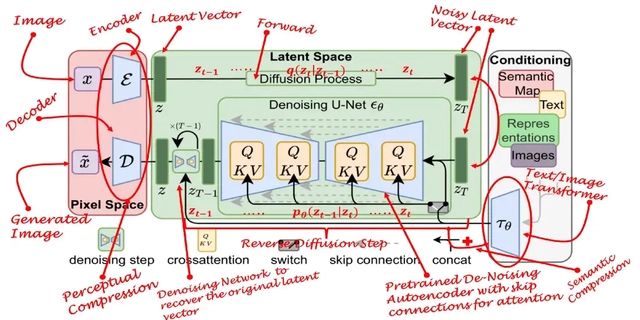
网络结构
Stable Diffusion 是一个复杂的系统而非单一模型,总体上看可以分为以下三个部分:
ClipText:用于文本编码 promot。
输入:文本 promot
输出: 77 个 token embeddings 向量,每个向量 768 维
UNet + scheduler:在潜空间中逐步处理信息。
输入:文本 embeddings 和一个初始化的多维数组组成的噪声
输出:经过处理的信息数组
自动编码解码器(Autoencoder Decoder):使用经过处理的信息数组绘制最终图像。
输入:经过处理的信息数组 (4, 64, 64)
输出:生成的图像(3, 512, 512)
核心:潜空间的引入,替换了原先直接在像素空间的去噪过程。
开源模型
开源的 SD 模型是一个通用的基础模型,在此基础上,微调训练了各种各样的垂类模型:
偏动漫二次元类型:novelai、naifu ai
国风类型:https://civitai.com/models/10415/guofeng3
Hugging Face 上开源的200+模型:https://huggingface.co/sd-dreambooth-library
C 站模型大全:https://civitai.com/
等等
不同的预训练模型可以与下游任务更为的契合。下面也会讲述如何用自己的数据去微调得到自己心仪的模型。
Prompt "公式"与设计
Prompt格式优化:简易换行三段式表达:
第一段:画质tag,画风tag
第二段:画面主体,主体强调,主体细节概括。(主体可以是人、事、物、景)画面核心内容。第二段一般提供人数,人物主要特征,主要动作(一般置于人物之前),物体主要特征,主景或景色框架等
第三段:画面场景细节,或人物细节,embedding tag。画面细节内容
元素同典调整版语法:质量词→前置画风→前置镜头效果→前置光照效果→(带描述的人或物AND人或物的次要描述AND镜头效果和光照)*系数→全局光照效果→全局镜头效果→画风滤镜(embedding)
Example:
A beautiful painting (画作种类) of a singular lighthouse, shining its light across a tumultuous sea of blood (画面描述) by greg rutkowski and thomas kinkade (画家/画风), Trending on artstation (参考平台), yellow color scheme (配色)
其中关键字说明:
画作种类:ink painting(水墨画),oil painting(油画),comic(漫画),illustration(插画),realistic painting(写实风)等等。
参考平台:Trending on artstation,也可以替换为「Facebook」「Pixiv」「Pixabay」等等。
画家/画风:成图更接近哪位画家的风格,此处可以输入不止一位画家。比如「Van Gogh:3」and「Monet:2」,即作品三分像梵高,两分像莫奈。
配色:yellow color scheme 指整个画面的主色调为黄色。
可用工具
https://promptomania.com/
一款编写智能AI绘画关键词(Prompts )的在线生成工具,提供多种智能AI绘画工具(Midjourney、Stable Diffusion、DreamStudio等)的关键词(Prompts )文本描述模板。
https://promptomania.com/prompt-builder/
一款 prompt 生成器
搜索引擎
https://openart.ai/?continueFlag=df21d925f55fe34ea8eda12c78f1877d
https://www.krea.ai/
https://lexica.art/

应用
▐ 阶段一:盲盒时代
在当前阶段,借助于 CLIP + Diffusion 的底座大规模预训练的成果,在风格、主题、艺术家、光线、物体等 400 维度的学习之后,根据提示信息已经可以绘画出相当具有意境的画作。根据提示词、随机种子、采样器的不同,往往会随机出现多幅作品:此时良品率大概在 15% 左右,是不是有种开盲盒的感觉呢?
txt2img
以未加训练的 SD-2-1-base 为基础模型,随机输入文字制作几张图片, 仅作示例。
advanced anime character art render,
beautiful anime girl wearing a whale skin hoodie outfit,
blue watery eyes, close up , Rossdraws, WLOP , Sakimimichan
群山环绕的城堡,赛伯朋克风格
难点
对于用户的文本输入,优质的出图效果需要一定的专家经验
对于 C 端用户,如何将这种专家经验去门槛化
prompt 特征工程的建立
计算效率和资源占用
768 * 768,1024 * 1024 的出图计算资源需求依旧庞大
img2img
以未加训练的 SD-2-1-base 为基础模型,随机几张图片加指定风格,做风格迁移,创作补充等等
可能应用
风格迁移
草图作画
▐ 阶段二:造卡时代
相比于开盲盒时代,我们有了新的追求
我想要自由控制整体的绘画风格
我想要生成一些在训练数据中未曾出现的概念
于是,产生了一批微调大模型的方案,这里选取当前比较流行的 Textual Inversion 和 DreamBooth 做个介绍。
Textual Inversion
文生图模型为通过自然语言指导创作提供了前所未有的自由。然而,目前尚不清楚如何运用这种自由来生成特定独特概念的图像,修改其外观,或将其合成新角色和新场景。换言之,要把现实中的一些新概念(new concept)引入到生成中,单从文本出发还是不够的。
Textual Inversion 提出了 personalized text-to-image generation,即个性化的文转图生成。可以基于文本+用户给的3-5张图(“new concepts”)来生成新的图像,把图片概念转换成pseudo-words(伪单词),然后一起合并到prompt中,从而生成一些具备这样概念的图片。
基本原理
在大多数文生图模型的文本编码阶段,第一步是将prompt 转换为数字表示,而这通常是通过将words转换为tokens来完成的,每个token相当于模型字典中的一个条目(entry)。然后将这些entries转换为embeddings进行训练。
添加用户提供的special token (S*,表示新概念)来作为新的embedding。然后,将这个embedding 链接到新的伪单词,伪单词可以同其它词一样被合并到新的句子中。在某种意义上,我们正在对冻结模型的文本嵌入空间进行反转,所以我们称这个过程为Textual Inversion。
模型结构如下图所示: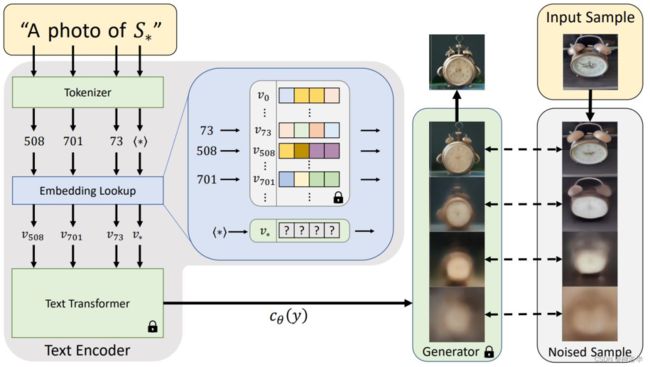
图片来源原论文
是基于latent diffusion做的,只改进了其中text encoder部分的词表部分,添加S*来表达新概念,其它token的embedding不变,从而实现与新概念的组合。
为了训练S*对应的文本编码v*,使用prompt “A photo of S*”生成新的图片,我们希望这个概念生成图片和用户给的图片相符合,从而学习到v*这个新概念。学到之后就可以利用S*来做新的生成了。
损失函数:让通过这个句子prompt产生的图片和用户给的small sample(3~5张图)越近越好
DreamBooth
基本原理
使用包含特殊字符和 class 的 prompt(例子:"a [identifier] [class noun]"。其中 identifier 表示稀有字符,模型没有该字符的先验知识,否则该字符容易在模型先验和新注入概念产生混淆;class noun是对 subject 粗力度类的描述,通过将稀有字符和class绑定,模型可以将class的先验和identifier绑定。对低分辨率的text-to-image模型微调,其中在少数数据上对模型微调容易产生“overfitting and language drift”问题,为此提出了class-specific prior preservation loss。使用prompt(A [class noun])在模型fine-tune之前产生的输出结果与当前模型在prompt(a [identifier] [class noun])输出的结果做正则,从而保证 class 类的先验。
其次对super-resolution模型微调,主要为了产生高保真度的图片
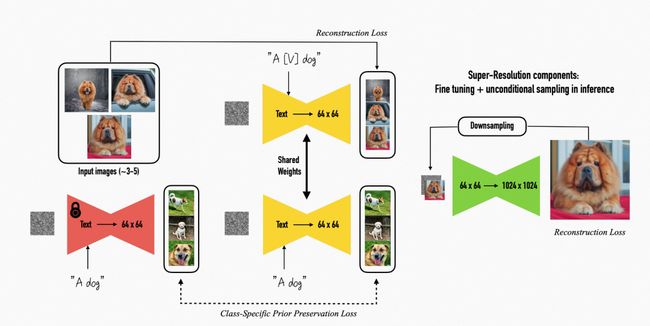
图片来源原论文
简单实践
人物学习
选取几张家里的小狗作为训练目标,测试 dreambooth 对未曾见过的新真实人物的刻画。
训练样本
我们来看看生成的效果,训练的关键词我们使用的是 tmicDUODUO dog

左:a photo of tmicDUODUO dog
右:a photo of tmicDUODUO dog, riding a bicycle
画风学习
当然,更多的画风学习,多目标的 LoRA 融合,都可以自行尝试,炼丹都这么有艺术量了么?!
▐ 阶段三:你的时代
ControlNet
随着欲望的膨胀,对于画不出合格的手、可以控制对象而不能控制其姿态,我们来到了第三个阶段,期望去训练一个更加听话的生成器。于是,ControlNet 走入了人们的视线。
基本原理
ControlNet的原理,本质上是给预训练扩散模型增加一个额外的输入,控制它生成的细节。
这里可以是各种类型的输入,作者给出来的有8种,包括:
草图
边缘图像
语义分割图像
人体关键点特征
霍夫变换检测直线
深度图
人体骨骼等。
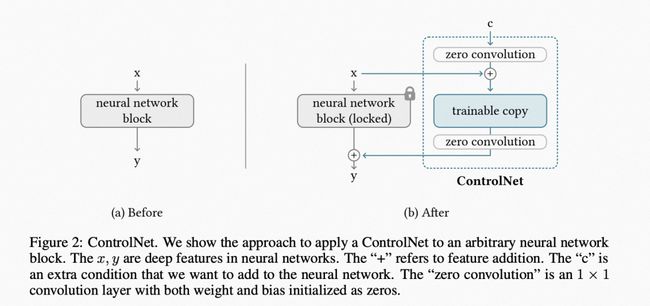
具体来说,ControlNet先复制一遍扩散模型的权重,得到一个“可训练副本”。相比之下,原扩散模型经过几十亿张图片文本对的预训练,因此参数是被“锁定”的。而这个“可训练副本”只需要在特定任务的小数据集上训练,就能学会条件控制。
即使数据量很少(不超过5万),模型经过训练后条件控制生成的效果也很好。“锁定模型”和“可训练副本”通过一个1×1的卷积层连接,名叫“0卷积层”。0卷积层的权重和偏置初始化为0,这样在训练时速度会非常快,接近微调扩散模型的速度。
实现效果
这里我们直接拿博主“海辛Hyacinth”的分享做一个展示。


推理加速
以 V100 测试为准, 测试存在一定波动,总体趋势稳定。
▐ oneFlow
深度学习算法原型开发阶段需要快速修改和调试,动态图执行(Eager mode)最优。但在部署阶段,模型已经固定,计算效率更为重要,静态图执行(Lazy mode,define and run)可以借助编译器做静态优化来获得更好的性能。因此,推理阶段主要使用静态图模式。
最近,PyTorch 升级到2.0引入了 compile() 这个API,可以把一个模型或一个Module从动态图执行变成静态图执行。OneFlow里也有一个类似的机制,不过接口名是 nn.Graph(),它可以把传入Module转成静态图执行模式。
OneFlowStableDiffusionPipeline.from_pretrained 能够直接使用 PyTorch 权重。
OneFlow 本身的 API 也是和 PyTorch 对齐的,因此 import oneflow as torch 之后,torch.autocast、torch.float16 等表达式完全不需要修改。
上述特性使得 OneFlow 兼容了 PyTorch 的生态,这不仅在 OneFlow 对 Stable Diffusion 的迁移中发挥了作用,也大大加速了 OneFlow 用户迁移其它许多模型,比如在和 torchvision 对标的 flowvision 中,许多模型只需通过在 torchvision 模型文件中加入 import oneflow as torch 即可得到。
体验
将 HuggingFace 中的 PyTorch Stable Diffusion 模型改为 OneFlow 模型,
import oneflow as torch
from diffusers import OneFlowStableDiffusionPipeline as StableDiffusionPipeline
model_id |
显卡 |
speed pytorch |
speed oneflow |
rt pytorch |
rt oneflow |
memory |
output [default] |
sd-v1.5 |
V100 |
13 it/s |
21 it/s |
2.3s |
1.8s |
6362 M |
512 * 512 |
sd-v2.1-base |
V100 |
16 it/s |
24.5 it/s |
2.2s |
1.7s |
6650 M |
512 * 512 |
sd-v2.1 |
V100 |
3 it/s |
9 it/s |
7.8s |
3.6s |
7198 M |
768 * 768 |

NSFW 处理
输入验证:利用集团 KFC 能力,对“涉黄涉暴等”进行屏蔽。
利用提供的 safety_checker 检验,NSFW 图片进行置黑处理。

可能用到的工具
BLIP:输入图片,生成对图片的描述,用于制作训练模型的数据集工具
https://github.com/salesforce/BLIP
DeepDanbooru,输入图片,生成对图片的描述 Tags,用于制作训练模型的数据集工具
https://github.com/KichangKim/DeepDanbooru
Birme: 图片裁剪的工具,用于制作训练模型的数据集
链接:https://www.birme.net/
Real-ESRGAN: 图片超分辨工具
链接:https://github.com/xinntao/Real-ESRGAN

应用场景
▐ 淘系商品生成

▐ 风格迁移

▐ 艺术创作

▐ 一键试妆
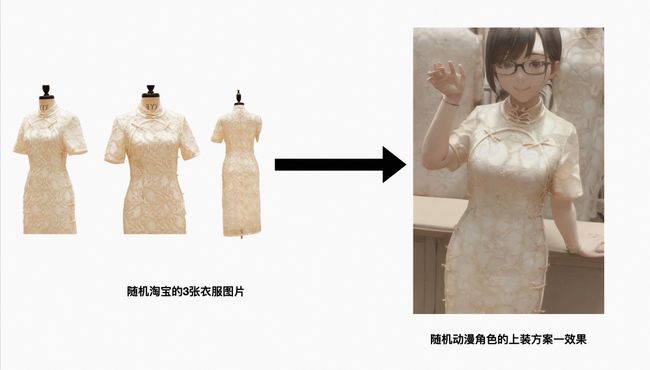
▐ 指定风格的场景制作




▐ 视频制作
视频来源:达摩院
场景制作
人物建模
剧本设计
语音合成
动画渲染
▐ 垂类领域-家装设计

多轮迭代、门槛较高

参考文献
https://baijiahao.baidu.com/s?id=1754603075856631603&wfr=spider&for=pc
https://blog.csdn.net/qq_25737169/article/details/78857724
https://github.com/Oneflow-Inc/oneflow/
https://ata.alibaba-inc.com/articles/244236
https://github.com/CompVis/stable-diffusion
https://github.com/Oneflow-Inc/oneflow
https://my.oschina.net/oneflow/blog/6087116
https://blog.csdn.net/air__Heaven/article/details/128835719
An image is worth one word: Personalizing text-to-image generation using textual inversion.
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation.
Adding Conditional Control to Text-to-Image Diffusion Models

团队介绍
我们是大淘宝技术行业与商家技术前端团队,主要服务的业务包括电商运营工作台,商家千牛平台,服务市场以及淘系的垂直行业。团队致力于通过技术创新建设阿里运营、商家商业操作系统,打通新品的全周期运营,促进行业垂直化运营能力的升级。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法