FoundationDB :一个支持分布式、事务、架构解藕的 k/v存储系统
文章目录
-
- 0 前言
- 1 架构设计
-
- 1.1 设计原则
- 1.2 系统接口
- 1.3 架构
-
- 1.3.1 Control Plane
- 1.3.2 Data Plane
- 1.3.3 Read-Write Separation
- 1.3.4 配置变更和选举流程
- 1.4 事务管理
-
- 1.4.1 端到端的事务处理流程
- 1.4.2 事务冲突检测
- 1.4.3 日志协议
- 1.4.4 事务系统的Recovery
- 2. 模拟测试框架
- 3. 性能
- 4 总结
0 前言
FoundationDB 是苹果公司从2009年开始,开发了十多年的分布式k/v 存储系统。
拥有如下几个亮点:
- 架构完全解藕,目前来看其架构可以说将解藕做到了极致。内部主要拥有三个子系统:常驻内存的事务管理系统、分布式存储系统、内置的分布式配置系统。每一个子系统都能够独立提供可扩展、高可用以及分区容错的能力。
- 模拟测试框架,类似pingcap 的kaos-mesh。这个测试框架是十多年前专门为fdb 设计的,其设计经过严格的证明,能够将最为严苛的场景中的异常模拟出来,模拟分布式/事务/存储场景中可能出现的无数的异常。每一个fdb新特性都会通过这个模拟测试框架上的测试之后才能上线,所以 fdb 稳定性极为可靠。
- k/v API 简单,且功能完备。能够很好得被集成到上层应用之中(关系型、文档型、对象存储、图存储)。
因为其有好的架构设计 以及 强大的稳定性保障,所以fdb 被广泛应用到了 苹果内部的存储系统之中,而且 被 snowflake 当做了自己的元数据存储(云原生数仓稳定性要求极高)。
FoundationDB 的设计目标是 称为能够支持各种上层应用场景的分布式存储引擎。
原因如下两点:
- 当时业界主流的nosql 系统为了迎合用户的需求(应用中不一定需要关系型的数据访问模式),比如 云服务场景对存储系统的需求是 可扩展、高可用、支持网络分区、同时提供一部分的数据模型,这样能够让使用云服务的用户快速去做应用侧的功能高迭代,所以 nosql 系统为了保障性能,牺牲了事务能力,仅需要提供最终一致的一致性模型即可,所以像是 Cassandra , CouchBase 这样的系统他们的应用场景非常有限。
- 关系型数据库存储仍然占大头,但是他们底层存储架构设计和上层应用耦合度过高,每一个数据库的存储和SQL 层都是绑定的(MYSQL, ORCLE 不论是事务管理 还是 存储, 整个系统都是高度耦合的),底层存储层并没有办法通用,对于想要做自己业务场景的数据存储公司来说成本极高。
综合以上两点,苹果公司在当时设计了足够通用的分布式存储引擎,整个FoundationDB的 设计 以及 代码实现是能够看到苹果公司是真的在认真做一款分布式存储底座,至少国内公司不会让一个团队几年时间制作一个simulator 来证明整个产品的架构设计和稳定性都是满足要求的。
不过因为 FoundationDB 社区建设的不是很好,像是一些技术文档更新有版本差或者不完善(RedWood存储引擎设计),而且代码注释比较少,研究起来会费劲很多,不过并不影响它本身是一个非常值得学习的分布式事务型的k/v存储底座。
本文通过 FDB 在 2021年 SIGMOD 发表的 FoundationDB: A Distributed Unbundled Transactional Key
Value Store 来简单介绍一下 fdb的设计架构,这篇论文是 sigmod 的 2021的best paper。
1 架构设计
1.1 设计原则
- 分治(解藕)。将事务管理子系统独立出来,并且为每一个子系统内部设置了不同的角色 来提供不同的事务管理能力:时间戳管理、处理事务提交、冲突检测、事务日志管理(REDO/UNDO)等。除了事务相关的,还将分布式系统需要的 过载保护、负载均衡 以及 异常恢复 等功能 也会由独立的角色去完成。
- 让异常成为常态。异常情况在分布式系统中是非常常见的,fdb 的处理方式不是写很多发生异常情况之后如何处理的的代码逻辑,而是通过检测到异常之后主动关闭系统。这样就能够将异常处理交给recover 来做,对recover 的恢复速度就提出了非常严苛的要求,发生异常之后的recovery 能够尽可能少的体现在上层用户的可用性上是非常重要的。
- 快速检测异常并快速恢复。这个原则也是上一个 让异常成为常态 原则的基础。希望能够快速检测到异常,并且快速恢复,在 fdb 的生产集群中 整个流程的 MTTR(Mean-Time-To-Recovery) 时间 是在 5秒之内完成的。
- 模拟测试体系。用来做fdb的可靠性验证 以及 fdb 的开发者的工程能力 和代码质量。
1.2 系统接口
fdb 提供了一些基操作单k/v 以及 批量k/v的接口:
- set()
- get()
- getRange()
- clear()

 事务场景,这一些操作会暂时缓存到客户端,只有在事务调用 commit 之后才会被持久化,为客户端提供的是 read your write语义。
事务场景,这一些操作会暂时缓存到客户端,只有在事务调用 commit 之后才会被持久化,为客户端提供的是 read your write语义。
1.3 架构
一个fdb 集群 逻辑上 主要由两部分组成:
- Control plane。管理整个fdb 集群的系统元数据。
- Data plane。处理事务 和 数据存储。
基本形态如下:

每一个部分内部又有一些逻辑上的小组件组成,充当各自系统内部的角色。
1.3.1 Control Plane
这一部分内部主要是用来之久化系统关键路径的元数据,比如 transaction system中 coordinator的配置信息。
这里简单介绍一下 control plane 中 coordinators 的作用,它们是这一层的主要角色,监管整个集群的各个服务运行的状态,不同的 coordinator 之间是通过 disk paxos group 达成共识的。
每一个 coordinator 是一个 fbserver进程,包括后面提到的其他的角色,都是统一的fb进程,只是采用的是对应角色的配置。
这一些通过 disk paxos 运行的coordinators 会选出来一个主进程(leader) 叫做 ClusterController,这个 类似leader的角色功能主要是:
- 监控整个集群 所有在运行的服务状态
- 选择三个服务进程:
a. Sequencer 用于data plane 事务系统 分配 read 和 commit 版本(时间戳)
b. DataDistributor 用户监控集群服务的状态,探测是否有异常节点 以及 监控 StorageServers 之间的数据分布情况,并做数据均衡。
c. Ratekeeper 主要为整个集群提供流控能力,做过载保护。
选择出来的这三个进程如果异常挂了,会由 ClusterController 重新选择,重新制定一些 fbserver进程代替这个角色。
1.3.2 Data Plane
所有 OLTP 型的负载处理都会在这一层中。这里 foundationdb 也采用了完全解藕的架构设计,从上面的图中可以看到,主要分为了三个部分:
- Distributed transaction system(TS),用于处理内存中的事务。
- Log system(LS),通过 WAL(write-ahead-log) 持久化 TS 中的事务数据。
- Distributed storage system(SS),提供 数据存储 以及 读能力。
TS 事务系统 中有几个 角色比较重要:
- 一个 Sequencer,这个就是 ClusterController 选择出来的一个角色。用于一致性读 以及 事务提交时分配时间戳。
- 多个 Proxies,为 client 提供 mvcc读 以及 协调事务提交。
- 多个 resolvers 用于事务之间做冲突检测。
LS 日志系统的总体角色像是提供 复制、分片、分布式持久化队列 的能力。每一个 “持久化队列” 保存的事一个 StorageServe 的 WAL 数据。
SS 由多个 StorageServe 组成,这个服务进程是整个fdb 集群中最多的,主要用于服务自客户端的读请求,每一个 StorageServe 会按照 range (有序的)存储分片数据。StorageServer 核心部分就是存储引擎了,每一个 SS 都会有一个引擎实例。
目前 FoundationDB 7.1 版本 支持的存储引擎如下:

默认的存储引擎用的是SQLite,不过FoundationDB 在其之上为适配多版本做了一些修改(SQLite 是 B-tree 存储引擎,不支持多版本,FDB 为其支持了多版本,同时增加了更快的RangeDelete 以及 异步API 接口);除了 SQLite 之外 还支持了 Memory , RocksDB(目前还在试验中,没有上生产环境),RedWood 存储引擎 。
可以简单说一下 RedWood 存储引擎是 FoundationDB 因为 SQLite的一些问题,而为自己设计的存储引擎。因为SQLite 不支持多版本(FDB 写入的k/v 都会带有自己的版本,比如 同一个user key “key1" ,会有 key1-10, key1-11, key1-13等多个版本),而且因为 B-tree 的COW 更新方式对内存和性能都有非常大的影响,并且不能友好的支持前缀压缩。对FDB来说还是在设计上很难大幅度优化的,所以他们开发了一个适合自己场景的存储引擎 RedWood,关于RedWood 存储引擎的介绍后续会专门写一篇 该引擎的设计背景以及基本实现原理。
1.3.3 Read-Write Separation
因为 FoundationDB 灵活的架构解藕,让来自客户端的读写可以被不同的组件去调度,从而实现了可扩展的读写分离。
来自客户端的读请求可以直接被 分片到某一个 SS 进程,随着 SS 服务数量的扩张,客户端读请求的性能也是线性增加的。
客户端下发的写请求则会被一系列进程处理,像是 Proxies, Resolvers 做事务提交和冲突检测。这里MVCC 的数据会存放到 SS 中。
在整个系统中存在的三个单例进程 : Sequencer、DataDistributor、RateKeeper 因为只管理元数据,所以并不会成为系统的性能瓶颈。
1.3.4 配置变更和选举流程
在FDB中, 所有的用户数据以及大多数的系统元数据都会被存储到 SS中。 SS 中 每一个服务进程的元数据则会被持久化到 LS(Log Servers) 中,LS 的配置数据则会被放在 Coordinators 中。而 Coordinator 则使用的是 disk paxos来保持共识的,如果 Coordinator 中的 “Leader” ClusterController 异常/未选举,则 会通过 diskpaxos 选择一个新的 ClusterController,这个新的 “Leader” 首先会选择一个 Sequencer 单例角色,sequencer 从 旧的 LS 读取 LS原本的配置信息,并生成一个新的 TS 和 LS。接下来 就是 事务系统中的 Proxies 会从 旧的 LS 读取系统元数据 (包括 SS 的元数据) 进行恢复。 sequencer 会等到新的 TS 完成事务数据恢复 会 将新的 LS配置写入到 所有的 coordinators 。
整个Cluster 角色选举 从 ClusterController 开始到完成各个组件的恢复就都做完了,到此才能为客户端提供读写服务。
1.4 事务管理
1.4.1 端到端的事务处理流程
事务处理从读写两方面展开描述:
- 对于读事务来说,客户端会先从 TS 的 Proxies 中的一个获取一个 read version(时间戳),Proxy 会和 Sequencer进行交互 并 获取到当前系统最新提交的版本,Proxy 将获取到的版本返回给客户端。客户端可能会调度多次读请求到 SS,并获取到他们想要的小于等于这个版本的value数据。
- 对于写事务来说,客户端下发的写请求会先缓存到客户端本地,并不会和FDB 集群的角色有交互。客户端下发提交请求的时候,提交 rpc 会被发送到 Proxies 中的一个 并等待提交结果的返回。如果提交失败,客户端可能会重试。
关于写事务 中 TS 的 Proxy 提交流程如下图,3.1, 3.2 ,3.3 共三步

- 3.1 proxy 向 sequencer 请求一个新的commit version,要比已经存在的 read version 和 commit version都大。sequencer 看起来像是一个中心授时器,能够提供百万级别的 版本生成能力。
- 3.2 proxy 拿到新的版本 之后会发送给 resolvers 对 commit keys sets 做冲突检测,使用的是OCC的方式(提交的时候菜进行),主要检测的是读写冲突,即是否有其他的事务在读当前commit 得这一些keys。如果所有的resolvers 都返回没有冲突,则返回给Porxy可以进行最后的提交阶段;如果有冲突,则返回Proxy当前事务终止。
- 3.3 Porxy 将提交事务发送到 LogServers 中进行持久化。一个事务在 LS 中完成提交的前提是所有的 LogServers 都向 Proxy 返回成功,并将提交的 commited version 发送给sequencer 用于推进下一次的 commit version。 最后返回给Client 提交成功。 于此同时,SS 会从 LogServer 异步拉取 transaction logs 进行 REDO(因为在 fdb 中 logserver 保存的是提交成功的事务日志,所以并不是 undo log),将事务操作数据 重新执行,持久化到 SS 的本地存储中。
1.4.2 事务冲突检测
如上流程中,Proxy 拿到 sequencer 分配的大于 read version 以及 最新的 commit version的一个version 之后会将当前事务要提交的事务交给 resolvers 做冲突检测,这里是事务处理性能的关键,也是整个事务系统最为容易出现性能瓶颈的地方。FDB 这里在 resolvers 上实现的冲突检测算法是无锁的,大体算法流程如下:

lastCommit 是每一个 resolver 维护的一个历史提交记录 ,通俗来说是一个 map(在fdb 的实现中是一个 支持多版本的skiplist,类似 rocksdb 的 WriteBatchWithIndex),保存的是这段时间内提交的key-ranges 和 它们的commit versions 之间的映射。
对于要提交的事务 Tx 在冲突检测中的输入由两部分组成: R w R_w Rw 表示要修改的key range集合, R r R_r Rr 表示要读的key的集合。
- 1-5 行代码 用于 T x T_x Tx 中的读 和 lastCommited 中的写进行冲突检测。主要从 R r R_r Rr 中取出 事务 T x T_x Tx 内部的读请求的key-ranges,拿着这一些 range 中的key对应的read version 去和 lastCommit 中的历史key 版本进行比较,如果历史版本有更新的当前key - r 的version,则终止。否则,继续向下执行。
- 没有读写冲突,则将当前的 R w R_w Rw 中的修改的key range 添加到 lastCommitted,用于后续事务的读写冲突检测。
详细代码实现是在 SkipList.cpp中,每一个冲突检测函数内部 逻辑还是比较多的,感兴趣的同学可以看一下。

论文中提到每一个resolver 的 TPS 上限能够很容易达到 280k,而且是一个fbserver 作为 resolver,实际的生产环境单机可以部署多个resolver(正常情况这种高CPU负载的肯定会部署在不同机器上,实际的key 空间经过分片之后肯定是分布在不同机器上的),这样的单机事务能力还是比较强的。
1.4.3 日志协议
上面提到了 resolver 做冲突检测的基本流程,这里就到了 Proxy 日志提交的最后一步,也就是持久化事务日志到 LogServers 中。
基本过程如下图:
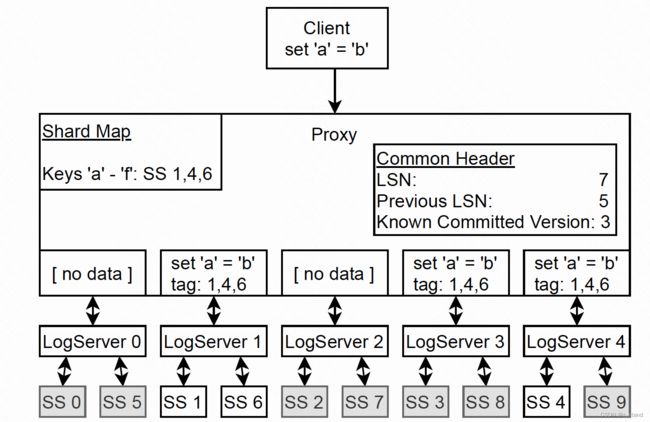
- Proxy 根据事务要修改的key 查询在 proxy 进程内存中的 shard map,确认这个key 所在的 StorageServer,如上要修改的key 是’a’,则确认包含 a 的range 的 storageServer 分别是 1, 4,6.
- Proxy 会和 1, 4, 6 StorageServer 建立连接,每一个StorageServer 会有对应的 LogServer 调度请求(前面说过,一个LogServer 可能和多个 StorageServer 对应,类似持久化队列, SS 从 LS中取请求本地执行持久化操作)。
- Proxy 向对应的LS 发送事务处理请求。SS 1和 6 对应 LS 1,SS4 对应 LS4。同时为了保证高可用,还会将 当前请求
set a=b发送一份到 LS3。 - LS 1, 3, 4 在完成本地的持久化之后会向 Proxy 发送完成 rpc,Proxy 会对本地的 Know commmited version (KCV) 进行更新。
- 将 LS 中的数据持久到 SS中是异步操作。SS 会从 对应的 LS 中 拉取 redo log,SS 中的持久化方式是利用 batch commit,即 通过 redo log重放的请求会先在内存中进行batch,达到阈值/时间之后才会批量提交,这样的group commit的提交方式对 i/o 更为友好。存在的问题也很明显,如果 StorageServer 挂了,内存中缓存的一部分操作就会丢失 或者 是一个事务只提交了一半 ,所以还需要 Recovery 以及 recovery过程中的 rollback能力。
1.4.4 事务系统的Recovery
在 FDB 中,Recovery 过程成本非常低,因为其解藕架构设计 没有 checkpoint,recovery 的时候不需要重放 redo 或者 undo log。只需要保证一个非常简单的原则,Recovery 的过程中对 redo log的处理流程还是和之前一样就好了,即异步拉取 LS 中的 redo即可,完全不会对整个 Recovery的性能产生影响。
上文的 Proxy 在 LS 系统中持久化 redo log的时候也说到 SS 会异步得拉取 redo log进行本地的 group commit操作。所以如果整个事务系统进行重启的时候,根本不需要等到所有的 redo 都被提交到 SS中,而是重新像 1.3.4 小节中描述的,只需要保证选择出新的 TS 和 LS即可,过程中只是一些配置信息的相互交互。新的 TS 和 LS 系统 ready之后就可以接受用户请求了, 至于 Recovery 之前 SS 没有完成恢复的 redo log 可以重新异步得从 TS 拉取恢复就可以,这个过程是一个后台操作,对Recovery的性能不会有太大的影响。
所以FDB 这样的解藕设计能够提供非常快速的 recovery能力,这样整个系统就可以将这个能力发挥出来,即出现异常之后不需要复杂的异常处理逻辑,而是快速进行Recovery,Recovery过程中恢复系统的正常执行的逻辑。
2. 模拟测试框架
FDB 利用自己编写的一套 支持并发原语 actor model 模型 的异步编程框架 Flow 搭建了自己的模拟测试框架。包括 模拟磁盘I/O,网络,系统时间 以及 随机数生成器。
这个模拟测试框架并不是一个工业级落地产品,却是拥有功能完全一样的模拟测试系统,对于一个做分布式存储底座的公司来说想要花费以年为单位的时间先做一个测试框架来证明后续产品的架构优势以及稳定性是否达到预期 成本是非常高的。这一点,苹果公司可以说是业界标杆了,是真的在做一个工业级的通用强一致分布式存储底座。FDB 的强大稳定性成为 snowflake 这样公司首选。除了社区管理不够完善之外,真的可以有很多分布式设计的细节值得学习借鉴,只是需要去花时间深入研究代码。

在模拟测试中,FDB 能够利用 Flow 模型快速模拟多个 fbserver 在自己所属的角色中利用模拟的IO ,网络,时钟 进行交互,从而达到和生产环境类似的运行延时/形态。
正常体系的运行过程中 会通过 Fault Injector 不断得随机注入异常(磁盘/IO 异常,机器重启,网络分区等等) + 随机 workload 能够非常高效准确得完成在分布式场景下的各种极端运行场景的稳定性测试,发现的bug 都能被复现、进一步分析 从而修复。
而且 FDB 生产代码开发之前是先开发的 Simulator,因为Simulator 无法覆盖到 引入的 thirdparty(不是用Flow 实现的),所以他们就拒绝引入thirdparty,完全使用自己的 Flow 实现了 rpc 系统(fbrpc),共识系统(disk paxos) 以及 分布式配置管理系统(coordinators)。
3. 性能
这里主要展示一下关键性能。
1.机器数量的增加,吞吐的变化情况如下

无论是 纯读/纯写 还是读写混合,性能都是随着机器数量的增加而增加。因为读事务的链路比较短,clients 除了拿read version的时候和 TS 进行交互之外,带着IO的读请求都是 client 直接和 SS 进行交互,所以读性能平均比写性能好很多。
2.吞吐和延时情况如下

图a 展示了请求处理的带宽可以随着 ops 的增加而线性增加,即吞吐是线性的。
图b 展示了延时情况,随着ops 的增加 在10w 量级以下,读平均延时不到1ms, GetReadVersion(Client 读的时候会从 TS 的Proxy 上请求一个 read version)1ms 左右, GetReadVersion比Read 延时会高一些,因为它需要Proxy和 Sequencer 进行 rpc 交互,相比于读直接和SS进行交互来说链路稍短一些;commit 链路会更长一些,涉及到持久化数据到logserver,平均延时在10w 一下的时候大概到几个ms。
在 10w-100w以及 100w 以上的 ops情况下,这几个操作的平均延时都会增加。对于commit来说,ops越大,其处理链路的复杂度会更高,尤其是 Resolvers做冲突检测好事比较长。
3.Recovery 性能
这个性能是FDB 百TB生产集群的 几百次配置变更时间分布(主要是recovery时间),其中90% 以上的变更恢复时间都在 3.08s-5.28s 之间。因为Recovery 对于完全解藕的FDB集群来说仅仅是恢复一些 TS / LS 的元数据,SS的恢复并不参与到主恢复流程中,它只负责异步从LS中拉取REDO,而且这段期间并不会影响读(读请求是client 直接和SS进行交互),也就是这段时间的恢复主要是对读写事务的提交有影响,读写事务会阻塞 直到恢复之后由 client重发。

4 总结
- FDB 极致解藕的架构设计 为整个分布式事务型的kv存储 性能提升和优化提供了保障。每一个角色可以单独分配服务器资源,极大得保障了不同用户场景下的用户性能需求:读写事务较多,增加 TS resovlers 服务;读请求多,增加 StorageServers数量即可。而且利用解藕架构设计 能够提供 Fast Recovery能力。
- 基于Flow搭建的Simulator 测试体系,极大得保障了整个FDB 服务的 稳定性。FDB给出的数据:近几年FDB 生产环境线上部署了几十万个实例,还从来没有发生 corruption 问题。
- 前面两个可以说FDB最大的吸引力,后面支持的一些分布式事务型的k/v 存储能力 都是基本功能的保障,像是 支持全球部署,SSI 隔离级别,存储引擎(SQLite,RedWood,RocksDB 支持)等等,保障了FDB 可以作为一个生产级别的分布式kv底座。