基于CIFAR10数据集的识别网络应用(pytorch)
学习pytorch的过程中搞了一个小小的应用,和大家分享分享。
数据集
数据集:CIFAR10
该数据集共有60000张彩色图像,这些图像是32*32,分为10个类,每类6000张图。这里面有50000张用于训练,构成了5个训练批,每一批10000张图;另外10000用于测试,单独构成一批。测试批的数据里,取自10类中的每一类,每一类随机取1000张。抽剩下的就随机排列组成了训练批。注意一个训练批中的各类图像并不一定数量相同,总的来看训练批,每一类都有5000张图。

代码
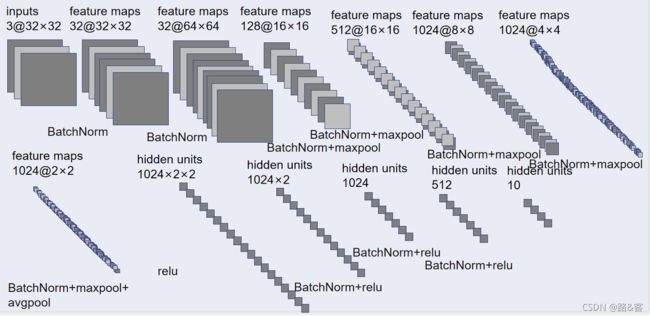
model.py
from torch import nn
from torchvision import transforms
import torch as t
import torchvision
from torch.utils.data import DataLoader
device = t.device("cuda:0") #用GPU训练模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.sque = nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.BatchNorm2d(32),
nn.Conv2d(32,64,5,1,2),
nn.BatchNorm2d(64),
nn.Conv2d(64,128,5,1,2),
nn.BatchNorm2d(128),
nn.MaxPool2d(2),
nn.Conv2d(128,512, 5, 1, 2),
nn.BatchNorm2d(512),
nn.MaxPool2d(2),
nn.Conv2d(512,1024, 5, 1, 2),
nn.BatchNorm2d(1024),
nn.MaxPool2d(2),
nn.AvgPool2d(2),
nn.Flatten(),
nn.ReLU(),
nn.Linear(1024*2*2,1024*2),
nn.BatchNorm1d(1024*2),
nn.ReLU(),
nn.Linear(1024 * 2, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Linear(512,10)
)
def forward(self,x):
x = self.sque(x)
return x
#下载训练集,测试集
train_data = torchvision.datasets.CIFAR10(root="./data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="./data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#加载训练集,测试集
train_dataloader = DataLoader(train_data,batch_size=32)
test_dataloader = DataLoader(test_data,batch_size=32)
net = Net()
net = net.to(device)
loss_fn = nn.CrossEntropyLoss() #损失函数采用交叉熵函数
loss_fn = loss_fn.to(device)
learning_rate = 1e-2
optimizer = t.optim.SGD(net.parameters(),lr=learning_rate) #采用随机梯度下降训练
total_train_step = 0
total_test_step = 0
epoch = 20
for i in range(epoch):
print("第{}轮训练开始:".format(i+1))
#开始训练
net.train()
for data in train_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = net(imgs)
loss = loss_fn(outputs,targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step,loss.item()))
#评估模型
net.eval()
total_test_loss = 0
total_accuracy = 0
with t.no_grad():
for data in test_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = net(imgs)
loss = loss_fn(outputs,targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集的Loss:{}".format(total_test_loss)) #这里用的是整体loss所以会很大
print("整体测试集的正确率:{}".format(total_accuracy/test_data_size))
if i > 12:
t.save(net,"test3_CIFAR10_{}.pth".format(i+1))
print("模型已保存")
这里记住训练最好的模型,后面好采用。


test.py
from torch import nn
from torchvision import transforms
import torch as t
import torchvision
from torch.utils.data import DataLoader
from PIL import Image
image_path = "../imgs/cat.jpg" #cat.jpg是我自己在网上找的图片
lei = image_path.split(".")[2].split("/")[2] #把cat.jpg中的cat提取出来作为后续实际结果
image = Image.open(image_path)
print(image)
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
#把图片转为32*32大小的(数据集中的图片用的是32*32的,应匹配)
image = transform(image)
image = t.reshape(image,(1,3,32,32))
print(image.shape)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.sque = nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.BatchNorm2d(32),
nn.Conv2d(32,64,5,1,2),
nn.BatchNorm2d(64),
nn.Conv2d(64,128,5,1,2),
nn.BatchNorm2d(128),
nn.MaxPool2d(2),
nn.Conv2d(128,512, 5, 1, 2),
nn.BatchNorm2d(512),
nn.MaxPool2d(2),
nn.Conv2d(512,1024, 5, 1, 2),
nn.BatchNorm2d(1024),
nn.MaxPool2d(2),
nn.AvgPool2d(2),
nn.Flatten(),
nn.ReLU(),
nn.Linear(1024*2*2,1024*2),
nn.BatchNorm1d(1024*2),
nn.ReLU(),
nn.Linear(1024 * 2, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Linear(512,10)
)
def forward(self,x):
x = self.sque(x)
return x
model = t.load("test3_CIFAR10_18.pth",map_location=t.device('cpu')) #导入之前下好的模型(用GPU训练的模型要转为CPU的,才能预测)
print(model)
model.eval()
with t.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
icon = {0:"airplane",
1:"automobile",
2:"bird",
3:"cat",
4:"deer",
5:"dog",
6:"frog",
7:"horse",
8:"ship",
9:"truck"}
print(output.argmax(1).item())
for key,value in icon.items():
if output.argmax(1).item() == key:
print("预测类型为:" + value)
print("实际类型为:" + lei)
结果:

