【IVIF:引入注意力机制:GAN:双鉴别器】
AttentionFGAN: Infrared and Visible Image Fusion Using Attention-Based Generative Adversarial Networks
( AttentionFGAN:使用基于注意的生成对抗网络进行红外和可见光图像融合)
在本论文中,我们将多尺度注意机制集成到GAN的生成器和鉴别器中,以融合红外和可见光图像 (AttentionFGAN)。多尺度注意机制不仅旨在捕获全面的空间信息,以帮助生成器关注红外图像的前景目标信息和可见图像的背景细节信息,而且还将判别器更多地集中在注意区域而不是整个输入图像上。 AttentionFGAN的生成器由两个多尺度注意力网络和一个图像融合网络组成。两个多尺度注意网络分别捕获红外图像和可见光图像的注意图,因此融合网络可以通过更多地关注源图像的典型区域来重建融合图像。此外,采用两个鉴别器来强制融合结果分别从红外和可见光图像中保留更多的强度和纹理信息。此外,为了保留源图像中更多的注意力区域信息,设计了一种注意力损失函数。
介绍
我们提出了一种新颖的红外和可见光图像融合方法,该方法采用了基于注意力的生成对抗网络,称为AttentionFGAN。AttentionFGAN的生成器由两个多尺度注意力网络 (infraredmulti-scale attence network和visible multi-scale attence network) 和一个图像融合网络 (fusion network) 组成。在多尺度注意网络中,由于大型对象空间信息不能用单尺度特征表示,我们首先利用卷积神经网络提取源图像的深度特征,并采用多尺度空间池化方案从深度特征中捕获综合的空间信息。然后受类激活图 (CAM)的启发,对多尺度注意力网络进行了训练,以学习每个特征的权重,以强调重要特征而忽略不相关的特征。此外,为了获得最典型的特征信息,我们通过注意力映射操作将重新加权的深度特征图组合在一起,以计算注意力图。最后,将注意力图与源图像连接起来,以帮助融合网络更多地关注判别区域并重建融合图像。具体而言,融合网络可以更多地关注红外图像中存在的前景目标信息,也可以更多地关注可见图像中存在的典型背景细节或特征。在AttentionFGAN中设计了两个鉴别器来计算源图像与融合结果之间的Wasserstein距离,因为多对抗性网络可以迫使生成图像同时保留来自源图像的更有意义的信息,并且可以避免单个对抗性体系结构造成的信息丢失。在图像融合过程中,我们鼓励融合图像与红外图像具有相似的像素强度,以保留热辐射信息。此外,还将多尺度注意力机制引入到鉴别器中,以限制鉴别器更多地关注注意力区域而不是整个输入图像。我们还发现,在融合结果和源图像之间设计注意力损失有助于保留源图像中更多的注意力区域信息。
贡献
1)我们将多尺度注意机制引入生成器和鉴别器。多尺度注意机制可以帮助发生器感知红外和可见光图像中最有区别的区域。具体来说,融合结果不仅可以保留红外图像中存在的更多前景目标信息,而且可以保留可见图像中存在的丰富背景细节或特征。多尺度注意力机制可以将鉴别器更多地集中在注意力区域而不是整个输入图像上,从而提高我们方法的性能。
2)提出了一种多尺度注意网络来提取红外图像和可见光图像的注意图,该网络首先通过对每个深层特征进行多尺度空间池化操作来捕获综合的空间信息,因为单尺度特征不能表示存在于大型对象中的所有必要的空间信息,然后,还对多尺度注意力网络进行了训练,以学习每个特征的权重,以使最终的注意力地图更多地关注典型区域或细节信息。
3)为了从源图像中保留更多的注意力区域信息,我们基于鉴别器设计了融合图像和源图像之间的注意力损失。理想情况下,当鉴别器无法将融合的结果与源图像区分时,鉴别器的输入应具有相同的注意图。因此,我们惩罚来自第一Discriminator_ir 的红外图像的注意力图和融合图像注意力图之间的差异,以及来自第二 Discriminator_vis的融合结果的注意力图和融合图像注意力图之间的差异。
4)在三个公共可用的红外和可见图像数据集上进行了广泛的实验。实验结果表明,AttentionFGAN可以增强红外图像中存在的前景目标信息,并突出可见图像中存在的背景细节信息。此外,通过定性和定量比较,AttentionFGAN优于其他最先进的方法。
相关工作
FusionGAN
FusionGAN旨在通过在生成器和鉴别器之间建立对抗性博弈来融合红外和可见光图像。详细地说,FusionGAN中的发生器可以产生具有主要红外强度和可见梯度的融合图像。此外,为了保留来自可见图像的更多细节信息,将生成的图像和可见图像发送到鉴别器,以使生成的图像与可见图像具有相同的数据分布。生成器的损失函数定义如下:

其中第一项表示对抗性损失,而另一项表示所生成的图像If和源图像 (Ir,Iv) 之间的内容损失。N表示生成的图像的数量,c是一个软标签,用来欺骗鉴别器,H和w表示输入图像的高度和宽度,▽表示梯度操作,||• ||F表示矩阵Frobenius范数。
WGAN
WGAN使用Wasserstein距离代替jensenshannon (JS) 散度来计算真实数据与生成数据之间的差异,与原始GAN相比,这可以使训练过程更加稳定。详细地说,可以分配鉴别器的权重,并使权重位于一个紧凑的空间内。然而,由于梯度爆炸和消失,权重裁剪方法仍然导致模型难以收敛。因此,Gulrajani等人用梯度惩罚改进了WGAN如下:

其中前两个项表示Wasserstein距离估计,最后一个项表示梯度惩罚因子,〜x表示沿连接生成数据和实际数据对的直线均匀采样,而 μ 表示惩罚系数。
Attention Mechanism in Deep Network
注意力机制首先被引入机器翻译任务,现在已经成为人工智能中的一个重要概念,因为它可以提高神经网络的可解释性,否则被认为是黑盒模型。注意机制首先访问整个输入序列以计算输入序列的权重,然后将权重引入输入序列以选择性地关注重要部分。此外,注意机制也可以用人类生物系统来解释,因为人类视觉系统倾向于更多地关注最重要的信息而忽略其他无关的信息。因此,注意力机制现在已经在自然语言处理,语音识别和计算机视觉的应用中发挥了重要作用。在自然语言处理领域,注意力机制已用于处理机器翻译,问答和情感分析的任务。Ma等人提出了一种新颖的基于方面的针对性情感分析方法,该方法改进了具有层次关注机制的长短期记忆 (LSTM) 网络,并将情感相关概念作为模型训练的输入。在语音识别领域,注意机制有助于模型更多地关注问题的相关部分,也可以提高视觉问答任务的性能。Lu等人同时采用视觉注意和问题注意,提出了一种新颖的视觉问答共同注意模型。在计算机视觉领域,注意机制已广泛应用于图像分类和图像分割中,Wang等人提出了一种通过堆叠注意模块来提高对象识别性能的剩余注意网络,并设计了注意模块来计算注意感知特征。
方法
Framework Overview
AttentionFGAN的目标是训练一个生成器,该生成器可以产生信息丰富的融合图像。此外,融合图像是如此逼真,以至于鉴别器无法将其与源图像区分开。AttentionFGAN由两个鉴别器和一个生成器组成,AttentionFGANn的框架如图2所示:

在生成器中,我们设计了两个多尺度注意网络 (红外多尺度注意网络和可见多尺度注意网络) 和一个图像融合网络 (融合网络)。两个多尺度注意力网络旨在分别生成红外和可见光图像的注意力图。然后,注意图可以帮助融合网络更多地关注红外图像中存在的前景目标信息,并更多地关注可见图像中存在的典型背景细节或特征。此外,在ttentionFGANn中使用了两个鉴别器 (称为Discriminator _ ir和Discriminator _ vis) 来计算源图像与融合结果之间的Wasserstein距离。在训练过程中,分别应用Discriminator_ir和Discriminator _vis来区分红外和可见光图像中的融合结果。因此,Discriminator _ ir和Discriminator _ vis可以强制融合的结果同时保留来自红外和可见光的信息。我们还将多尺度注意力机制引入到鉴别器中,以限制他们更多地关注注意力区域而不是整个输入图像。此外,WGAN应用于我们的方法中,因为它可以提高我们的方法在训练步骤中的性能。
Architecture of Generator
AttentionFGAN的生成器如图2的蓝色块所示。生成器中有两个多尺度注意网络 (红外多尺度注意网络和可见多尺度注意网络) 和一个图像融合网络。红外和可见光图像由不同的传感器捕获,并具有不同的方式。因此,红外和可见光图像关注同一场景的不同方面,需要设计两个注意网络来分别计算红外图像的注意图 (attention_ir) 和可见光图像的注意图 (attention_vis)。基于此,通过两个多尺度注意网络计算attention_ir和attention _vis,然后将attention _ir,attention _vis和源图像在通道维度上串联, 以帮助融合网络从红外图像中保留更多的前景目标信息,并从可见图像中捕获丰富的背景细节信息。
Multi-Scale Attention Network
多尺度注意网络旨在计算一个注意地图,以帮助生成器和鉴别器更多地关注辨别区域,多尺度注意网络的体系结构如图3所示:


在多尺度注意网络中,应用卷积神经网络 (conv网络) 提取源图像的特征,然后将最后两个激活图作为深度特征。而且,由于源图像总是包含大型对象的变形,单尺度特征无法提取所有必要的空间信息。因此,我们引入了多尺度机制,以通过不同的内核大小捕获多尺度特征,以执行全局平均池化。但是,在每次池化规模操作之后,都有太多的功能,以选择性地更多地关注重要功能而忽略不相关的功能。我们鼓励网络学习根据每个功能的全局信息重新加权所有功能。经过全局平均汇集操作,全局信息具有全局接受度。因此,受类激活图 (CAM) 的启发,对多尺度注意力网络进行了训练,

通过捕获权重Wk s,我们首先对多尺度特征采用上采样操作Hup,以使它们与输入具有相同的大小,然后在Wk s和上采样的特征之间实现信道乘法,以强调更重要的特征,而忽略不太有用的特征。基于此,我们计算跨通道维度的层中每个空间位置中重新加权特征的值的总和,如下所示:

通过归一化操作计算每个比例特征的注意图Fs。然后,为了捕获全面的空间注意力,将不同比例的注意力图以通道方式串联起来,然后我们采用最大选择策略在注意力映射操作中更多地关注可区分的空间位置,以计算最终的注意力图。
Architecture of Discriminator
所提出的方法包含两个鉴别器,并且在Fig.2的绿色块中显示了鉴别器的体系结构。第一个鉴别器用于区分融合结果与红外图像,第二个鉴别器旨在区分融合结果与可见光图像。两个鉴别器具有相同的网络结构,但它们不共享参数。在训练过程中,鉴别器应更加注意注意区域的信息。因此,我们引入多尺度注意力机制来将鉴别器的注意力更多地限制在注意力区域而不是整个输入图像上。更具体地说,首先将鉴别器的输入图像发送到多尺度注意力网络中,以计算注意力图。然后将注意力图和输入图像串联在通道维度中,以帮助鉴别器专注于最具鉴别力的内容。为了提高我们方法的性能,我们使用WGAN来计算源图像与融合结果之间的Wasserstein距离。请注意,GAN是为了解决二进制分类问题而实现的,WGAN旨在计算两个图像之间的wasserstein距离,这应该被视为回归问题。因此,在损失的计算中删除了log函数,并删除了鉴别器中的最后一个sigmoid层。
Loss Function of Generator
生成器的损失函数由三部分组成: 对抗损失、内容损失和注意力损失:

1) Content Loss:
内容丢失鼓励生成器产生具有与红外图像相似的数据分布的图像。此外,红外传感器通过捕获物体发出的热辐射对热源敏感,并且红外图像中的内容由像素强度表征。因此,我们强制融合的结果具有与红外图像相似的像素强度。
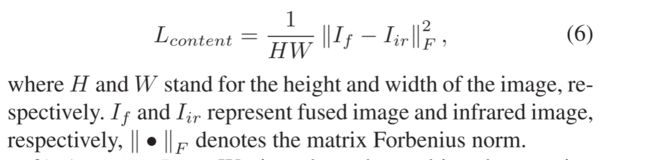
2) Attention Loss:
我们将多尺度注意力机制引入鉴别器,以从输入图像中提取注意力图。当鉴别器无法将融合的结果与源图像区分时,鉴别器的两个输入应具有相同的注意区域。例如,最终融合的结果应保留足够的红外图像的典型信息,然后当鉴别器无法区分融合的图像和红外图像时,融合的结果和红外图像应具有相同的注意图。因此,为了从源图像中保留更多的注意力区域信息,我们设计了融合图像和源图像之间的注意力损失,它惩罚了来自第一 Discriminator _ir的融合结果的注意图和红外图像的注意图之间的差异,以及来自第二 Discriminator鉴别器 _vis的融合结果的注意图和可见光图像的注意图之间的差异。

3) Multi-Adversarial Loss:
在 AttentionFGANn中,我们设计了两个鉴别器,以强制融合的结果分别保留来自红外和可见光的更多信息。因此,对抗性损失有两个部分,即生成器和第一鉴别器(Discriminator_ ir)之间的对抗性损失,这个鉴别器可以将融合的结果与红外图像区分开。生成器和第二鉴别器 (Discriminator_vis) 之间的对抗性损失,用于将融合的结果与可见图像区分开。多对抗性损失的表述如下:

Loss Function of Discriminator
生成图像包含一些有意义的信息,因为我们将红外图像和可见图像串联作为输入。现有的基于GAN的方法仅设计了一个鉴别器,并且它们可能会丢失图像中存在的某些信息,而这些信息不作为鉴别器的输入。因此,我们在AttentionFGAN中组织了两个判别器,判别器的损失公式如下:

其中LDir/vis代表Dir和Dvis的损失,右手的左两个项表示wasserstein距离估计。最后一项表示网络正则化的梯度惩罚,pir/vis表示红外和可见图像的数据分布,φ 定义为正则化参数。