大数据—Hadoop(十九)_ 生产调优手册_02、HDFS(2)_集群压测、多目录
文章目录
- 1、HDFS—集群压测
-
- 1.1 压测准备工作
-
- 1.1.1 目的
- 1.1.2 准备工作
- 1.1.3 测试网速
- 1.2 测试HDFS写性能
-
- 1.2.1 命令
- 1.2.2 结果
- 1.3 测试HDFS读性能
-
- 1.3.1 命令
- 1.3.2 结果
- 2、HDFS—多目录
-
- 2.1 NameNode多目录配置(了解)
-
- 2.1.1 多目录概念
- 2.1.2 具体配置
- 2.1.3 结果
- 2.2 DataNode多目录配置(重要)
-
- 2.2.1 概念
- 2.2.2 配置
- 2.2.3 结果
- 2.3 集群数据均衡之磁盘间数据均衡
-
- 2.3.1 概念
- 2.3.2 配置
- 2.3.2 结果
1、HDFS—集群压测
1.1 压测准备工作
1.1.1 目的
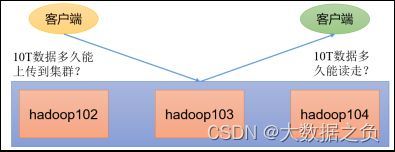
计算出HDFS读写速度
读写速度主要受网络和磁盘的影响
1.1.2 准备工作
我们先将虚拟机的网络统一设置成 100 mbps
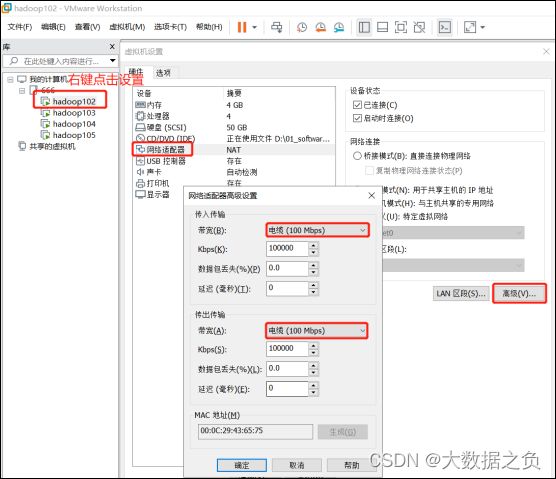
100 mbps = 12.5 m/s
因为 1字节 = 8比特
1.1.3 测试网速
[atguigu@hadoop102 ~]$ cd /opt/software/
[atguigu@hadoop102 software]$ python -m SimpleHTTPServer
Serving HTTP on 0.0.0.0 port 8000 ...
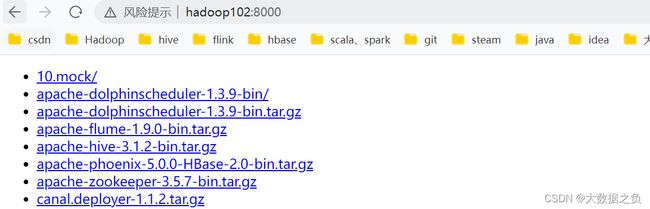
将当前目录内容暴漏出去,供外界下载使用
下载网址:hadoop102:8000
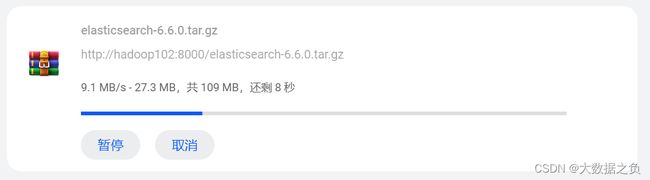
双击下载文件,可以看到下载速度会比 12.5m/s 稍微慢一点,在 10 m/s 左右
1.2 测试HDFS写性能
1.2.1 命令
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
- /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar
官方专门用于压测的Jar包 tests - TestDFSIO
测试HDFS的读写性能 - -write
测试写性能 - -nrFiles 10
当前服务器3台4核 总共12核
测试文件的总个数:9-12
目的:保证每台服务器都有MapTask任务启动 - -fileSize 128MB
每个文件大小
128MB
1.2.2 结果
2021-02-09 10:43:16,853 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Date & time: Tue Feb 09 10:43:16 CST 2021
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Number of files: 10
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Total MBytes processed: 1280
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Throughput mb/sec: 1.61
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Average IO rate mb/sec: 1.9
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: IO rate std deviation: 0.76
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Test exec time sec: 133.05
2021-02-09 10:43:16,854 INFO fs.TestDFSIO:
- Number of files: 10
生成mapTask数量 - Total MBytes processed
单个map处理的文件大小 - Throughput mb/sec 1.61 (压测后的速度)
1.61 * 20 ≈ 32M/s
20 = 上传 10个文件 * 3个副本 - 10个文件(在本地上传,如果是远程访问集群,按照30计算) - 三台服务器的带宽:12.5 + 12.5 + 12.5 = 37.5 m/s
写入速度 ≈ 服务器的带宽
证明所有网络资源已经用完 - 如果写入速度远远小于带宽,可以考虑换成固态硬盘或者增加磁盘个数
1.3 测试HDFS读性能
1.3.1 命令
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
-read 测试读性能
1.3.2 结果
2022-10-30 19:22:01,467 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
2022-10-30 19:22:01,467 INFO fs.TestDFSIO: Date & time: Sun Oct 30 19:22:01 CST 2022
2022-10-30 19:22:01,467 INFO fs.TestDFSIO: Number of files: 10
2022-10-30 19:22:01,467 INFO fs.TestDFSIO: Total MBytes processed: 1280
2022-10-30 19:22:01,467 INFO fs.TestDFSIO: Throughput mb/sec: 1921.92
2022-10-30 19:22:01,467 INFO fs.TestDFSIO: Average IO rate mb/sec: 1956.22
2022-10-30 19:22:01,467 INFO fs.TestDFSIO: IO rate std deviation: 266.42
2022-10-30 19:22:01,467 INFO fs.TestDFSIO: Test exec time sec: 22.07
2022-10-30 19:22:01,468 INFO fs.TestDFSIO:
压测后的速度:Throughput 1921.92 mb/sec
2、HDFS—多目录
2.1 NameNode多目录配置(了解)
2.1.1 多目录概念
- 在本台服务器上将配置多个NameNode目录,每个目录存放的数据内容一致
- 每个目录下存放的内容相同,增加了可靠性
- NameNode真正的高可用是使用HA + ZK
- 当hadoop102挂了,NameNode依然会挂,生产环境下可以不用配置多目录,不是真正意义上的高可用
2.1.2 具体配置
- 编写配置文件
hdfs-site.xml
<property>
<name>dfs.namenode.name.dirname>
<value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2value>
property>
core-default.xml
<property>
<name>hadoop.tmp.dirname>
<value>/tmp/hadoop-${user.name}value>
<description>A base for other temporary directories.description>
property>
hadoop.tmp.dir 默认是存放在linux系统tmp目录下(默 保存一个月)
core-site.xml
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop-3.1.3/datavalue>
property>
之前安装Hadoop时,我们修改了临时文件存放路径
注意:如果每台服务器节点的磁盘情况不同,配置配完之后,可以选择不分发
- 停止集群
[atguigu@hadoop102 hadoop]$ myhadoop.sh stop
- 删除三台节点的data和logs中所有数据
NameNode多目录一般是在集群使用前配置好,不然就不配置了
[atguigu@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs/
[atguigu@hadoop103 hadoop-3.1.3]$ rm -rf data/ logs/
[atguigu@hadoop104 hadoop-3.1.3]$ rm -rf data/ logs/
- 格式化NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hdfs namenode -format
- 启动集群
[atguigu@hadoop102 hadoop]$ myhadoop.sh start
2.1.3 结果
[atguigu@hadoop102 dfs]$ cd /opt/module/hadoop-3.1.3/data/dfs
[atguigu@hadoop102 dfs]$ ll
总用量 12
drwx------ 3 atguigu atguigu 4096 10月 31 11:22 data
drwxrwxr-x 3 atguigu atguigu 4096 10月 31 11:22 name1
drwxrwxr-x 3 atguigu atguigu 4096 10月 31 11:22 name2
[atguigu@hadoop102 dfs]$ ll name1/current/
总用量 1052
-rw-rw-r-- 1 atguigu atguigu 690 10月 31 11:23 edits_0000000000000000001-0000000000000000009
-rw-rw-r-- 1 atguigu atguigu 1048576 10月 31 11:23 edits_inprogress_0000000000000000010
-rw-rw-r-- 1 atguigu atguigu 394 10月 31 11:21 fsimage_0000000000000000000
-rw-rw-r-- 1 atguigu atguigu 62 10月 31 11:21 fsimage_0000000000000000000.md5
-rw-rw-r-- 1 atguigu atguigu 804 10月 31 11:23 fsimage_0000000000000000009
-rw-rw-r-- 1 atguigu atguigu 62 10月 31 11:23 fsimage_0000000000000000009.md5
-rw-rw-r-- 1 atguigu atguigu 3 10月 31 11:23 seen_txid
-rw-rw-r-- 1 atguigu atguigu 216 10月 31 11:21 VERSION
[atguigu@hadoop102 dfs]$ ll name2/current/
总用量 1052
-rw-rw-r-- 1 atguigu atguigu 690 10月 31 11:23 edits_0000000000000000001-0000000000000000009
-rw-rw-r-- 1 atguigu atguigu 1048576 10月 31 11:23 edits_inprogress_0000000000000000010
-rw-rw-r-- 1 atguigu atguigu 394 10月 31 11:21 fsimage_0000000000000000000
-rw-rw-r-- 1 atguigu atguigu 62 10月 31 11:21 fsimage_0000000000000000000.md5
-rw-rw-r-- 1 atguigu atguigu 804 10月 31 11:23 fsimage_0000000000000000009
-rw-rw-r-- 1 atguigu atguigu 62 10月 31 11:23 fsimage_0000000000000000009.md5
-rw-rw-r-- 1 atguigu atguigu 3 10月 31 11:23 seen_txid
-rw-rw-r-- 1 atguigu atguigu 216 10月 31 11:21 VERSION
检查name1和name2里面的内容,发现一模一样
2.2 DataNode多目录配置(重要)
2.2.1 概念
- 配置原因: 随着业务线数据量的增多,原先服务器上的硬盘满了,需要增加硬盘
- 和NameNode不一样,不能删除原来的数据
- 新增加的目录内容和之前目录中的内容不一致,但都是用来存储数据的
2.2.2 配置
hdfs-site.xml
<property>
<name>dfs.datanode.data.dirname>
<value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2value>
property>
core-site.xml
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop-3.1.3/datavalue>
property>
之前安装Hadoop时,我们修改了临时文件存放路径
core-default.xml
<property>
<name>hadoop.tmp.dirname>
<value>/tmp/hadoop-${user.name}value>
<description>A base for other temporary directories.description>
property>
hadoop.tmp.dir 默认是存放在linux系统tmp目录下(默认 保存一个月)
注意:如果每台服务器节点的磁盘情况不同,配置配完之后,一般不分发
停止集群
[atguigu@hadoop102 hadoop]$ myhadoop.sh stop
启动集群
[atguigu@hadoop102 hadoop]$ myhadoop.sh start
2.2.3 结果
[atguigu@hadoop102 dfs]$ cd /opt/module/hadoop-3.1.3/data/dfs
[atguigu@hadoop102 dfs]$ ll
总用量 20
drwx------ 3 atguigu atguigu 4096 10月 31 13:27 data
drwx------ 3 atguigu atguigu 4096 10月 31 13:27 data1
drwx------ 3 atguigu atguigu 4096 10月 31 13:27 data2
drwxrwxr-x 3 atguigu atguigu 4096 10月 31 13:27 name1
drwxrwxr-x 3 atguigu atguigu 4096 10月 31 13:27 name2
多出来data1 、 data2两个目录
向集群提交文件
hadoop fs -put wcinput/word.txt /
会发现两个文件夹下数据内容不一致,data1有数据,data2没有,不均衡,下节会讲如何处理数据均衡
[atguigu@hadoop102 dfs]$ ll data1/current/BP-97718552-192.168.10.102-1667186515016/current/finalized/subdir0/subdir0/
总用量 8
-rw-rw-r-- 1 atguigu atguigu 45 10月 31 13:30 blk_1073741825
-rw-rw-r-- 1 atguigu atguigu 11 10月 31 13:30 blk_1073741825_1001.meta
[atguigu@hadoop102 dfs]$ ll data2/current/BP-97718552-192.168.10.102-1667186515016/current/finalized/
总用量 0
2.3 集群数据均衡之磁盘间数据均衡
2.3.1 概念
- 生产环境下,如果新增了一块磁盘,我们需要把老磁盘的数据分一部分给新磁盘,做到数据均衡
- 3.X 新特性
- 只针对于一台服务器
2.3.2 配置
(1)生成均衡计划
hdfs diskbalancer -plan hadoop102
(2)执行均衡计划
hdfs diskbalancer -execute hadoop102.plan.json
(3)查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop102
(4)取消均衡任务
hdfs diskbalancer -cancel hadoop102.plan.json
2.3.2 结果
[atguigu@hadoop102 ~]$ hdfs diskbalancer -plan hadoop102
2022-10-31 17:25:15,422 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-10-31 17:25:15,576 INFO planner.GreedyPlanner: Starting plan for Node : hadoop102:9867
2022-10-31 17:25:15,576 INFO planner.GreedyPlanner: Compute Plan for Node : hadoop102:9867 took 9 ms
2022-10-31 17:25:15,576 INFO command.Command: No plan generated. DiskBalancing not needed for node: hadoop102 threshold used: 10.0
No plan generated. DiskBalancing not needed for node: hadoop102 threshold used: 10.0
我只有一块磁盘,不会生成计划