分布式文件与分布式存储系统学习总结(持续更新)
存储系统知识
Write Ahead Log
- 问题引入
存储系统在运行过程中,每时每刻都在发生数据更新。如对文件数据的CRUD.
对于中心控制节点来说,这些都会涉及到metadata的更新操作。
为了保持元数据和文件数据的状态一致性,系统所有对数据的操作对应的元数据变更都应该要持久化到元数据db中。
那假如这个metadata db是在外存的,那么是否意味着高频的io操作?是否可以引入延时写入的方法?
Write Ahead Log
核心意思:在把metadata的变更操作写到持久稳定的db之前,会预写入一个log中,然后再由另外的操作把log apply到外部持久的db中。
当系统要处理大量的事务操作的时候,WAL与实时同步db相比效率会更高。
WAL的日志还可以在利于数据库的事务回滚。
WAL执行细节
WAL不记录metadata本身,而是记录进行的操作的log

数据库的操作记录,首先会写到内存的buffer中,当buffer满或者人工触发flush的时候,会把事务数据写出到WAL的log中。
系统在每次完成一个操作的时候,同时会把改动应用到memory和WAL的buffer内,再由buffer 写到外存的metadata db中。
当老的WAL被apply到元数据db的时候,可以用commitId来标识当前最新的事务。所以整个过程可以理解为做一次checkpoint,即当前db的状态+WAL = 新的db状态
Write ahead log
分布式存储系统知识
分布式存储要解决的问题:
1.数据分布
如何把数据分布到多台服务器才能够保证数据分布均匀?数据分布到多台服务器后,如何实现跨服务器的读写操作?
2.一致性
如何把数据的多个副本复制到多台服务器并且保证一致性?
3.容错
如何检测服务器故障?如何自动把出现故障的服务器的数据和服务迁移到集群中的其他服务器?
4.负载均衡
新增的服务器和集群正常运行过程中如何实现自动负载均衡?数据迁移过程如何保证不影响已有事务?
5.事务与并发控制
如何实现分布式事务?实现多版本并发控制?
6.压缩与解压缩
如何根据数据特点设计合理的压缩算法?
分布式存储分类
-
非结构化数据
-
结构化数据
-
半结构化数据
介于非结构化数据和结构化数据之间,HTML文档属于半结构化数据。其与结构化数据最大的区别在于,半结构化数据模式结构和内容混在一起
分布式文件系统
存储大量的图片,照片,视频等非结构化数据对象,叫做Blob(Big binary object data)
分布式文件系统用于存储Blob对象,块存储或者大文件存储。
我们首先定义分布式文件系统的基本存储单元为数据块chunk
文件系统内按照chunk来组织数据,每个数据块的大小大致相同。每个chunk可以包括多个Blob对象或者定长块,一个大文件也可以拆分为多个chunk。
这些chunk会分散到存储的集群中。
用户对存储数据的操作实际上会映射为底层数据块的操作。
分布式键值系统
用于存储关系简单的半结构化数据,提供基于Primary Key的CRUD
分布式表格系统
存储较为复杂的半结构化数据,支持扫描某个主键范围,以表格为单位组织数据,每个表格包括很多行,通过主键来标识其中一行。
分布式数据库
典型的系统包括MYSQL数据库分片集群。
Ceph
Kubernetes中pod数据的持久化可以利用Ceph
Ceph提供了对象存储,块存储和CephFs文件系统存储三个功能。
-
对象存储
最简单的Key-Value存储,还有S3,Gluster -
块存储
接口通常以QEMU Driver或者Kernel Module方式存在。 -
文件存储
支持POSIX接口,与传统文件系统如Ext4同属于一个类型。
Ceph架构
在虚拟化中,比较常用的是Ceph的块设备存储,Ceph集群可以提供一个raw格式的块存储作为虚拟机实例的硬盘
Ceph相比其他存储优势在于,可以充分利用存储节点上的计算能力,存储每一个数据的时候,都会通过计算得出这个数据存储的位置,尽量把数据分布均衡。
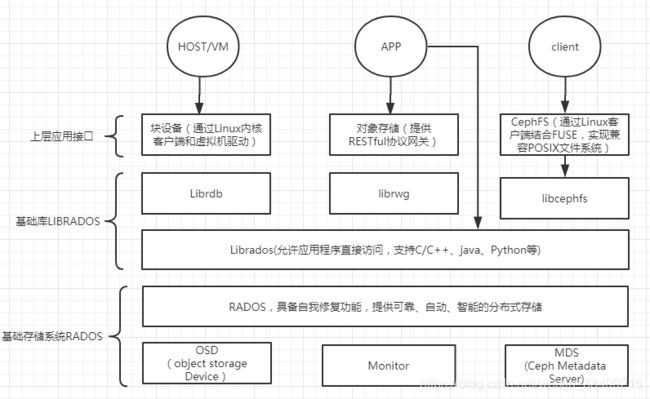
- Ceph的核心组件
Ceph OSD:
Object Storage Device,主要功能是存储,复制,平衡和恢复数据,一块硬盘或者硬盘的一个分区对应一个OSD,由OSD来进行对硬盘存储的管理。
架构实现:
1.物理磁盘驱动器
2.Linux文件系统(XFS,Ext4,BTRFS)
3.Ceph OSD
OSD还有一个Journal盘
写数据到Ceph集群的时候,先把数据写到Journal盘中,每隔一段时间再把journal盘中的数据刷写到文件系统中。
为了使得读写时延更小,Journal盘一般采用SSD,这给予文件系统足够的时间来合并写入磁盘,可以说Journal盘就相当于一个缓存。
Ceph Monitor:
负责监视Ceph集群,维护Ceph集群的健康状态,同时维护Ceph集群中的MAP.
这些MAP是RADOS的数据结构,存储着集群中所有成员,关系,属性等信息以及数据的转发。当用户需要存储数据到Ceph集群的时候,OSD首先需要通过Monitor来获取最新的Map图,然后根据Map图和object id计算出数据最终的存储位置。
Ceph MDS:
保存的是文件系统服务的元数据。对象存储和块存储不需要这个服务。
底层架构是RADOS,作为Ceph的核心,用户数据的存储最终是靠其进行
RADOS由OSD和Monitor组成

LIBRADOS: 操控RADOS的第三方库
RADOSGW: 一套RESTFUL网关
RBD:通过Linux内核客户端和QEMU/KVM驱动提供分布式的块设备
CEPH FS: 一个兼容POSIX的文件系统
Ceph如何保持数据均衡分布?
对象存储中,数据和object的关系:
用户要把数据存储到Ceph集群的时候,存储的数据会分割成多个object,每一个object都会有一个object id,object是Ceph存储的最小单元。
object和pg的关系:一个pg包含了多个object,每一个object都会映射到某个特定的pg中。
pg与osd关系: pg需要通过映射到osd区存储,一个pg可以映射到多个osd,其中一个副本为主副本,其余的都是从副本
pg与pgp关系
pgp个数关系到pg的分布
一个pool可能包含多个pg,一个pg可能包含多个obj
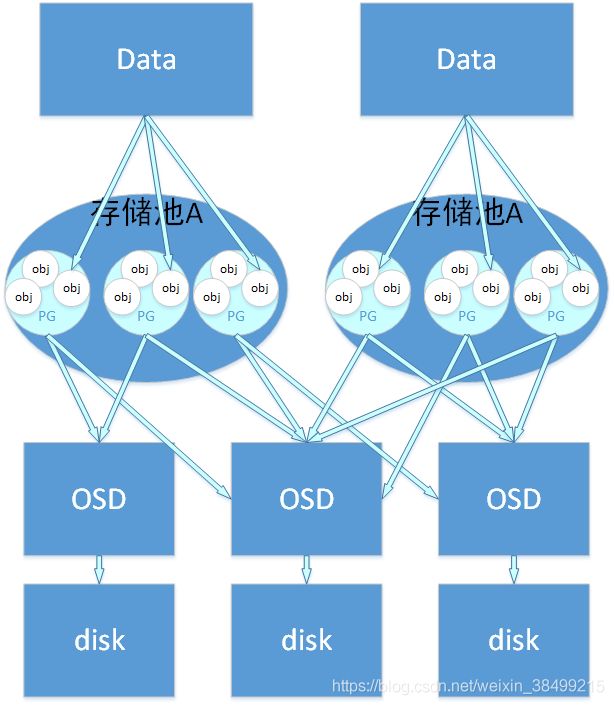
Ceph可以使用CRUSH算法来根据存储设备的权重来计算数据对象的分布。
权重设计会根据磁盘的容量和读写速度来设置。
CRUSH是根据Cluster Map,数据分布策略和一个随机数来决定数据最终的存储位置
ref
https://www.cnblogs.com/luohaixian/p/8087591.html
Linux文件系统
inode
文件存储在硬盘上,硬盘的最小存储单位叫做扇区,每个扇区会存储512byte
操作系统在读取硬盘的时候,不会一个个扇区读取,而是会一次性连续读取多个扇区,多个扇区组成一个block。也就是说读取硬盘的时候是按照块来读的。
块通常是8个sector组成一个block。
文件数据都存储在block中,所以我们还必须要找到一个地方存储文件的metadata,如文件的创建日期,大小,创建者等。
那么存储文件metadata的区域叫做inode,中文叫作"索引节点"
每一个文件都有一个对应的inode
inode内容
Size 文件的字节数
Uid 文件拥有者的User ID
Gid 文件的Group ID
Access 文件的读、写、执行权限
文件的时间戳,共有三个:
Change 指inode上一次变动的时间
Modify 指文件内容上一次变动的时间
Access 指文件上一次打开的时间
Links 链接数,即有多少文件名指向这个inode
Inode 文件数据block的位置
Blocks 块数
IO Blocks 块大小
Device 设备号码
inode 大小
inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统会把硬盘分成两个区域。一个是数据区,存放文件数据,另外一个是inode区,存放inode。
inode的数量在格式化的时候就已经给定了
一般每1KB或者2KB就会设置一个inode,那么在一块1GB的硬盘中,每个inode的节点大小为128字节,每1KB就设置为inode,那么inode table大小就会达到128MB.
如果inode花光了,就无法再硬盘上创建新文件了。
inode号码
操作系统怎么识别不同的文件?
用inode号码,linux是不使用文件名而是用inode号码来识别文件的。文件名只是inode便于识别的别称。
用户通过文件名打开文件的步骤:
1.系统先找到这个文件名对应的inode号码
2.通过inode号码找到inode信息
3.根据inode信息找到文件数据所在的block,读取数据
目录文件
在linux中,目录也是一种文件,打开目录实际上就是打开文件。
目录文件包含什么呢?
包含一系列目录项的列表,每个目录项由两部分组成:所包含文件的文件名,以及该文件名对应的inode号码
硬链接
linux中多个文件可以同时指向一个inode,这意味着可以用不同的文件名访问同样的文件内容。
其中一个文件对内容进行修改,会影响到所有文件名。
删除一个文件名,不会影响另外一个文件名的访问。
inode信息中有一项叫做连接数,记录着指向inode文件名的总数。
当inode==0的时候,表名没有文件名指向这个inode,系统会回收这个inode号码,以及其对应的block区域。
目录文件中的"链接数",创建目录的时候会在目录产生".“和”…"两个目录项。
前者的inode就是当前目录的inode,等同于当前目录的hard link
"…“的inode就是当前目录的父目录的inode号码,等同于父目录的"hard link”
所以任何一个目录的"hard link"总数,总是等于2+其子目录总数
软连接
文件A和文件B的inode号码不一样,但是读取A的时候,系统会自动将访问者导向文件B。
无论打开什么文件,最终读取的都是文件B,称A为文件B的软连接或者符号链接。
因为文件A指向的是文件B的文件名,而不是B的inode,B的连接数不会因此发生变化
ext4 extent
对于文件系统,每个文件都会对应一系列的磁盘块。
那这个文件逻辑块号和磁盘块号的映射关系就存储在inode中。
一个文件的逻辑块号是连续的,磁盘块号不一定连续。
ext4文件系统采用extent来保存文件逻辑块号和磁盘块号的关系
ext4中的一个inode可以直接存放4个extent.
逻辑块号和磁盘块号有点像虚拟地址和物理地址的关系
ext4怎么把一个filename和一个inode绑定在一起?
- inode存放文件元数据,没有存放filename
- 所以必然存在一个文件,保存着filename和inode之间的对应关系。
- 这个对应关系保存在目录文件的block中

但如果目录层数太多,不可能对于每个路径都要读取对应目录文件来找到是否有目录文件。所以在内存中有DEntry目录缓存,存放文件路径和其对应数据信息的对应关系。(/home 和 文件名和inode号的表)
Linux VFS
- superblock: 文件系统信息
- 索引节点对象: inode 存储着文件元数据
- 目录项对象 DEntry: 提供目录缓存
- 文件对象 File: 一个文件描述符对应一个打开的文件
文件的实现
文件是如何在存储器上实现的?即研究外村分配方式与文件存储空间的管理。
- 外存分配方式
指的是如何为文件分配磁盘块?
两种方式:静态分配和动态分配
前者是在文件建立的时候,一次性分配所需的全部空间
后者是可以根据动态增长的文件长度进行分配,甚至可以一次分配一个物理块。
常见的分配方法:
1.连续分配
优点是查找速度快,缺点就是容易产生碎片
预先分配空间的时候其实是要用户事先知道空间的大小

2.链接分配
适用于用户事先不知道文件的大小,则采用连接分配方式。
链接分配解决了连续分配的所有问题。采用链接分配,每个文件是磁盘块的链表;磁盘块可能会散布在磁盘的任何地方。目录包括文件第一块和最后一块的指针。例如,一个有5块的文件可能从块 9 开始,然而是块 16、块 1、块 10,最后是块 25(图 2)。每块都有下一块的一个指针。用户不能使用这些指针。因此,如果每块有 512 字节,并且磁盘地址(指针)需要 4 字节,则用户可以使用 508 字节。
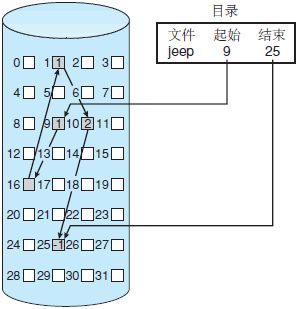
缺点: 不能随机访问盘块
3.索引分配
每个文件都有自己的索引块,这是一个磁盘块地址的数组。索引块的第 i 个条目指向文件的第 i 个块。目录包含索引块的地址(图 4)。当查找和读取第 i 个块时,采用第 i 个索引块条目的指针。

ref
http://c.biancheng.net/view/1302.html
磁盘调度算法
-
先来先服务算法
没啥好说的 -
SSTF(最短寻道时间优先)算法
选择与当前磁头所在的磁道距离最近的请求作为下一次服务的对象
磁盘移动臂的方向会随时改变,可能会引起饥饿现象 -
电梯调度扫描算法
在磁头前进方向上查找最短寻找时间的请求,只有在前进方向上没有请求的时候,才调转方向 -
循环扫描算法
规定磁头单向移动,自里向外,到了最外就重新从里触出发,对于每个磁道来说都是公平的
ref
inode介绍
ext4介绍