DDR基础知识点汇总
文章目录
-
- 文档推荐
- DDR颗粒的电路图来源
-
- DDR3 SDRAM电路结构高清图
- DDR4 SDRAM电路结构高清图
- DDR3-1866控制器/PHY/颗粒之间的带宽关系
- channel > DIMM > rank > chip > bank > row/column
- DDR页和行的概念理解
- DDR3 8Bit数据预取技术的理解
- DDR burst相关概念
- DDR SDRAM的时序参数和读写访问过程
- 计算DDR容量的方法
- DDR控制器架构
- DDR自动刷新和自刷新,以及与预充电的关系
- DDR 扰码解码:obfuscation Scamble.
- ZQC和ODT意义
- Write Leveling是什么?
文档推荐
- ddr3/4等协议eetop.cn_JESD79-3F.pdf
- 【理解SDRAM颗粒的入门中文手册,强烈推荐】eetop.cn_高手进阶,终极内存技术指南——完整.pdf
- 【理解DRAM电路结构和时序参数】https://linux.codingbelief.com/zh/memory/dram/dram_storage_cell.html
DDR颗粒的电路图来源
可以去网站搜索镁光DDR4 SDRAM关键词。
找出micron DDR4 SDRAM datasheet.pdf ,点击相关链接
上面网址资料应该更全,但是速度太慢。下面网址速度更快:https://pdf.ic37.com/
网上很多图非常不清楚,下面给一张DDR3和DDR4的高清图。
DDR3 SDRAM电路结构高清图

DDR4 SDRAM电路结构高清图

DDR3-1866控制器/PHY/颗粒之间的带宽关系
举例,DDR3-1866,意味着芯片与颗粒之间的传输速率是1866bps(单指一根DDR数据信号线,一般DDR3芯片引脚是32bit),
芯片PHY的DDR管脚信号线对应的时钟频率是1866/2=933MHz,因为上下边沿采样原理。
假设芯片接口,DDR数据位宽支持32bit,那么,
控制器如果是128bit数据位宽,那么时钟频率是=(1866*32)/ 128 = 466MHz。
channel > DIMM > rank > chip > bank > row/column
channel (对应多个DDR控制器)> DIMM(内存插槽) > rank(一次访问位宽决定,也成物理bank) > chip(1个chip大多是4bit/8bit/16bit等,组成一个rank,配合完成一次访问的位宽要求。这就是颗粒) > bank(颗粒里的logic-bank,DDR3一般对应8个bank存储体) > row/column
DDR页和行的概念理解
- DDR logic bank的row就是行,对应行地址选中等。
- DDR页的概念,是针对刷新或者访问来说的,举例,一个rank可能有4个chip组成,一个chip里可能有8个bank,每一个bank有N个行。页指的是一个rank里每个chip,所有bank的一个行地址;注意不是一行,是多行,行数是chip数目*bank数目。
- 所以,DDR页,可以讲为一个rank里每个chip的行地址
- (ps:在一个rank里,每个chip的地址是相同的。因为多个chip组成一个总数据位宽。DDR接口的cs信号,虽然叫chip select,其实是rank(一组chip)的 select)。
- DDR页的概念,后续会讲到页命中、页miss等,跟cache page原理一样。
DDR3 8Bit数据预取技术的理解
参考文章:
土老冒谈硬件 深度解析DDR3内存新特性
- SDRAM最开始是时钟下降沿采样,数据传输速率和频率是1:1关系,即一个周期可传输1bit数据;
- DDR1,采用时钟双边沿采样,即上升沿、下降沿都采样。一个时钟周期可传输2bit数据,这个时候,就叫预取2bit技术了(因为一拍需要预取2bit数据)。可知预取2bit技术的基础,就是双边沿采样。
- DDR2,预取4bit。
- DDR3,预取8bit。举例,DDR3-800内存的存储核心频率其实仅有100MHz,其输入/输出时钟频率为400MHz,利用双边沿采样技术,有效数据传输频率则为800MHz。
预取bit的意思,我理解就是一个时钟周期时间内,从DDR存储cell能够做到取出多少bit数据。如果一次预取16bit,DDR传输速率就又翻倍了。
一般,协议里称为8n prefetch。这个n,我理解就是DQ位宽。所以一个DDR3 16bit SDRAM内存颗粒,其一次读写访问的数据量是8*16=128bit。
DDR burst相关概念
BL,是burst length。对应预取bit数目,DDR3对应的BL是8
BC,是burst chop,中文理解是burst剁开切开,是为了兼容DDR2的burst length为4的情况。DDR3兼容DDR2时,8个burst,只保留前面4个burst有意义,后面4个burst内容无异议被mask掉。
DDR SDRAM的时序参数和读写访问过程
链接文章的时序讲解,图和文字很生动。时序参数和读写访问过程,结合在一起描述的。
https://linux.codingbelief.com/zh/memory/dram/dram_timing.html?q=#additive-latency

DDR2-800内存的标准时序:5-5-5-18,
DDR3-800内存的标准时序则达到了6-6-6-15
DDR3-1066为7-7-7-20
DDR3-1333更是达到了9-9-9-25
这4个数字的含义依次为:CAS Latency(简称CL值)内存CAS延迟时间,这也是内存最重要的参数之一,一般来说内存厂商都会将CL值印在产品标签上。
第二个数字是RAS-to-CAS Delay(tRCD),代表内存行地址传输到列地址的延迟时间。第三个则是Row-precharge
Delay(tRP),代表内存行地址选通脉冲预充电时间。第四个数字则是Row-active Delay(tRAS),代表内存行地址选通延迟。
除了这四个以外,在AMD K8处理器平台和部分非Intel设计的对应Intel芯片组上,如NVIDIA nForce 680i SLI芯片组上,还支持内存的CMD 1T/2T Timing调节,CMD调节对内存的性能影响也很大,其重要性可以和CL相比。
这些参数越低,代表延迟越小。但是系统出了DDR3芯片之外,还有颗粒、PCB板等,需要综合考虑,DDR3延迟不一定比DDR2慢。
一、影响性能的主要时序参数
所谓的影响性能是并不是指SDRAM的带宽,频率与位宽固定后,带宽也就不可更改了。但这是理想的情况,在内存的工作周期内,不可能总处于数据传输的状态,因为要有命令、寻址等必要的过程。但这些操作占用的时间越短,内存工作的效率越高,性能也就越好。
非数据传输时间的主要组成部分就是各种延迟与潜伏期。通过上文的讲述,大家应该很明显看出有三个参数对内存的性能影响至关重要,它们是tRCD、CL和tRP。每条正规的内存模组都会在标识上注明这三个参数值,可见它们对性能的敏感性。
以内存最主要的操作——读取为例。tRCD决定了行寻址(有效)至列寻址(读/写命令)之间的间隔,CL决定了列寻址到数据进行真正被读取所花费的时间,tRP则决定了相同L-Bank中不同工作行转换的速度。现在可以想象一下读取时可能遇到的几种情况(分析写入操作时不用考虑CL即可):
1、要寻址的行与L-Bank是空闲的。也就是说该L-Bank的所有行是关闭的,此时可直接发送行有效命令,数据读取前的总耗时为tRCD+CL,这种情况我们称之为页命中(PH,Page Hit)。
2、要寻址的行正好是前一个操作的工作行,也就是说要寻址的行已经处于选通有效状态,此时可直接发送列寻址命令,数据读取前的总耗时仅为CL,这就是所谓的背靠背(Back to Back)寻址,我们称之为页快速命中(PFH,Page Fast Hit)或页直接命中(PDH,Page Direct Hit)。
3、要寻址的行所在的L-Bank中已经有一个行处于活动状态(未关闭),这种现象就被称作寻址冲突,此时就必须要进行预充电来关闭工作行,再对新行发送行有效命令。结果,总耗时就是tRP+tRCD+CL,这种情况我们称之为页错失(PM,Page Miss)。
显然,PFH是最理想的寻址情况,PM则是最糟糕的寻址情况。上述三种情况发生的机率各自简称为PHR——PH Rate、PFHR——PFH Rate、PMR——PM Rate。因此,系统设计人员(包括内存与北桥芯片)都尽量想提高PHR与PFHR,同时减少PMR,以达到提高内存工作效率的目的。
计算DDR容量的方法

由图可以归纳出:
- bank有8个;对应BA[2:0];
- 行地址有15bit;列地址有10-3=7bit(其中低3bit不会用于列寻址);
- 每个bank的数据量
每个bank的数据量 =行列单元存储bit数=2^15 * 2^7 * 128bit=512Mbit
【这个128bit是怎么搞的,最开始理解一个存储cell的容量,就是数据信号线位宽16bit。这里DDR3是指预取8bit技术,8*16bit=128bit,一个地址对应8个预取pre-fetch的16bit数据。可以这样理解,DQ数据线宽是16bit,每一根DQ数据信号线,支持预取8次。】
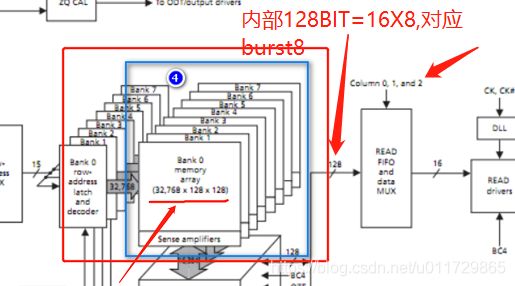
4. 所以,内存颗粒的容量= 8 * 512bit = 4Gbit=512MB,根据DDR数据信号线位宽,描述上图产品的规格,即256 * 16bit。
DDR控制器架构
DDR控制器功能简介
- 对DDR存储颗粒进行初始化;
- AXI等总线简单读写,和 DDR存储颗粒复杂的读写时序,做相互转换。让DDR IP使用者,可以像操作RAM一样操作DDR。
- 控制器要产生DDR颗粒需要的周期性的刷新指令,不需要用户的干预。
- DDR控制器接收的请求,一般没有顺序性,访问DDR颗粒的数据传输中,存在大量非数据的传输,即保证DDR颗粒时序的命令配置信息传输。会导致DDR带宽利用率低。因此,出现指令调度和重排序设计。
图摘自《DDR3存储控制器的设计与实现_彭陈.caj》

一些理解点:
- DDR控制器负责配置远程DDR颗粒的命令过程;穿插在数据传输里;占用一部分带宽;
- DDR控制器,输入是SOC总线读写请求;输出是DFI接口请求(图中称为配置请求,或者存储请求)。其中DFI接口通过PHY连接芯片外的DDR颗粒。
- DDR控制器需要访问调度,主要是因为颗粒是多bank的,跨bank的访问请求,会增加latency,减少带宽有效数据传输效率。
- 当前参与项目的DDR控制器,接收的SOC总线读写请求接口,会有多个。因为SOC总线用的NOC架构,有打包解包过程,对latency影响较大。如有latency性能要求,则需要直接在DDR控制器里进行类似数据总线的请求调度。
DDR自动刷新和自刷新,以及与预充电的关系
DDR的最小存储单元电路形式是电容,是通过充放电,实现0,1值存储。
如果长时间维持1值,会因为电路漏电特性,把电容里的电荷释放掉。
所以出现自动刷新概念,把DDR里的数据再次充电刷新一次,目的是保留DDR存储值。
根据协议定义,可知bank里的一行最大自动刷新间隔是7.8us;一个bank最大自动刷新间隔是64ms。由此,常见设计,一个bank的行数是8192。因为协议推导出的最大bank行数=64ms/7.8us=8205。
也就是说,DDR控制器需要每次7.8us时,做一次自动刷新的指令。
self-refresh和auto-refresh的区别,个人理解。
- 自动刷新是指控制器必须参与发起每一个自动刷新请求。适合正常工作的时候,由控制器来主导刷新操作。
- 自刷新是指控制器只发起刷新开始和结束两个请求。适合休眠,DRAM颗粒自己负责刷新操作。
- 自动刷新和自刷新,接口指令是类似的,除了CKE为低表明自刷新开始。
预充电和刷新,都是为了保持电荷存储,做出的电路重写动作。
- 预充电是针对一个bank或者所有bank的一行的操作;是伴随读写命令操作之后执行的。
- 刷新是同时对所有bank的所有行操作。
DDR 扰码解码:obfuscation Scamble.
意义是对DDR数据进行加密。
一个实践的方法是芯片TRNG产生伪随机数,然后跟真实数据XOR实现。
ZQC和ODT意义
- DDR3新增管脚ZQ,接高精度240欧姆。意义是提供精准电阻参考,该电阻对芯片内温度不敏感。ZQC,就暗示ZQ电阻的calibration校准。
- ODT,是利用ZQ电阻值,实现精确的阻抗匹配。保证DDR PHY + PCB走线 + DDR SDRAM这一个系统数据通路的信号完整性,比如解决信号反射问题等。具体详见:《聊一聊DDR3中的ODT(On-die termination)》
- 总之,ZQC和ODT一起,在不同温度下,解决信号的完整性问题。
另外,关于ZQ校准,有两个命令:ZQCL (ZQ CALIBRATION LONG )和ZQ CALIBRATION SHORT (ZQCS)
- ZQCL主要用于系统上电初始化和器件复位,一次完整的ZQCL需要512个时钟周期,在随后(初始化和复位之后),校准一次的时间要减少到256周期。
- ZQCS在正常操作时跟踪连续的电压和温度变化,ZQCS需要64个时钟周期。
Write Leveling是什么?
Write Leveling的功能是调整DRAM颗粒端DQS信号和CLK信号边沿对齐。
只有使用了fly-by的情况下需使能write leveling。
所谓的fly-by 布线,指地址、命令和时钟(下图黄色单词看不清楚,是clk/addr/command的意思)的布线依次经过每一颗DDR memory芯片。而dq和dqs作了点到点的连接。VTT表示这些信号都接了ODT端接电阻。fly-by 结构相对于T布线,有助于降低同步切换噪声(Simultaneous Switching Noise)。
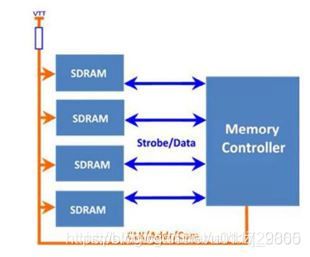
备注:下图是T型布线。

参考文章:
https://blog.csdn.net/tbzj_2000/article/details/88304245