CUDA-NVIDIA-冬令营004
CUDA进阶之路
- 指令,算法层面优化。如何更有效地调用CUDA线程。
- 存储,数据的存储优化。
- 硬件提升。
- 成熟的工具库。
一、Memory
按权限分:
Constant cache & Texture cache:
对HOST端可读可写;对线程,只读。
除了以上两个对线程只读,其余都是可读可写,但是共享程度有所区别。
- Global Memory:
对所有线程开放,可读可写。 - Shared Memory (per block)
同一个线程块内所有线程可读可写 - Local Memory & Registers (per thread)
对同一个线程可读可写
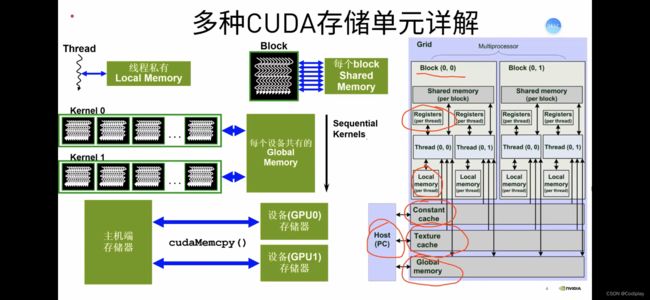
按物理位置分:
- On-board(DRAM)内存
Local、Global、Constant、Texture Memory - On-chip(GPU)缓存、寄存
cache,Multiprocessor(Registers & Shared Memory)
1、Registers
GPU最快的寄存器,kernel中没有特殊声明的自动变量都是放在寄存器中。
- 寄存器变量是每个线程私有的,一旦thread结束,寄存器变量就会失效。
- 寄存器是稀有资源,省着点用,让更多的block驻留在SM中,增加Occupancy硬件占用率(SM有十份资源,一个block占用5个资源,就能一次跑两个;但如果一个block占用6个,SM就得浪费4份资源)
- 不同设备架构,数量不同 --maxrregcount 可以设置大小
2、Shared Memory
用__shared__修饰符修饰的变量存放在shared memory:
- On-chip(非常快,接近registers)
- 拥有 很高 的bandwidth 和 很低 的 latency
- 同一个block共享同一块shared memory
- 涉及
__syncthreads()同步问题 - 需要节省着用,不然会限制活动warp的数量
3、Local Memory
很少显示的去设置和使用,在数据、数据结构不够大的情况下。若Register不够了,会用local memory来替代。
更多在以下情况使用:
- 无法确定索引大小(为某个常量)的数组。
- 会消耗太多寄存器空间的大型结构或数组。
- 内核使用了多于可用寄存器的任何变量。(称之为寄存器溢出)
--ptxas-options=-v
4、Constant Memory
固定内存空间 驻留在设备内存中(DRAM),并缓存在固定缓存中(constant cache):
- 范围全局,对所有kernel可见,只读。
- 当一个warp中所有thread都从同一个Memory地址读取数据时,即要读取的数据都相同时。constant Memory表现会非常好,会触发广播机制。
5、Texture Memory
和Constant Memory类似。驻留在设备内存中,且有一个只读cache。专门为那些在内存访问模式中存在大量空间局部性(Spatial Locality)的图形应用程序设计的。即,一个Thread读取的位置和邻近Thread读取的位置“非常接近”
- 有个缓存cache的好处就是,一些情况下相比从芯片外的DRAM上获取数据,纹理缓存可以通过减少内存请求来提高带宽。

6、Global Memory
空间最大,latency最高,GPU最基础的memory
需要
涉及一个问题, 每次是给一连串连续的数据,如果采用行读取,对于A来说,A0,1,A0,2,A0,3来说没人读取就浪费了。如果后面的数据也被相邻的线程使用,效率就会变得更高。需要数据被读取的时候保持:连续线程访问读取连续的数据。称之为:memory transaction对齐,合并访存。
可以的看到在一个step里,一个iteration下每个线程是读取哪些数据。可以看到按列读取的时候,iteration更短。

二、如何运用shared memory优化程序
最常用的为shared memory。
Shared memory可以被设置成16KB,32KB,48KB,剩下的交给L1缓存。
带宽可以使32b or 64bit
shared memory是block级别的,而register是thread级别的
而划分为逻辑块banks就是让shared memory更细分,变成thread级别的,而且比register更牛逼的是,他可以共享!
Shared memory可以被多个线程同时访问,为了克服访问瓶颈。shared memory划分为32个逻辑块banks。
bank具有的物理特性:
1、冲突:一个bank每个周期只能响应一个warp的一个地址申请 ——> 如果同一个warp中的不同线程访问同一个bank中的不同地址(两个必要条件),那么就会发生冲突,called Bank Conflict,这是最低效的。
2、广播:bank也有广播机制。当一个warp中的所有线程访问同一地址的共享内存时,会触发一个广播机制到中所有线程,这是最高效的。
3、多播:允许多个线程同时访问一个bank中的一个地址。
shared memory有两大功能:
- 当成一个buffer来使用,作为两块内存转移的中介cache。
- 某一个数据在慢速的memory(global memory)中被多次被使用,先将这块数据拷贝到shared memory中,再从shared memory中读,加快速度。
Bank Conflict
一个BLOCK里面做bank和warp的映射,sData的大小是BLOCKSIZE。需要做到同一时间内同一个warp不能有不同线程能对应同一个bank。
一个warp是按线程编号顺序的一个32线程集合。
线程按行排,和bank方向一致,即可避免bank冲突。
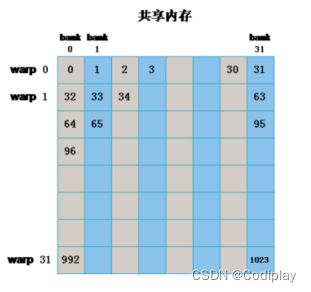
//全局中取一个block大小的数据,可由matrix[index]索引到该数据
int ix = blockDim.x * blockIdx.x + threadIdx.x;
int iy = blockDim.y * blockIdx.y + threadIdx.y;
int index = iy * nx + ix; //因为在全局中存储方式是行优先,所以还是iy * nx + ix
__shared__ float sData[BLOCKSIZE][BLOCKSIZE];
if(ix < nx & iy < ny) {
sData[threadIdx.y][threadIdx.x] = matrix[index];
// 将全局的matrix[index]的值放到新设定的sData中的矩阵中去,
// 选择行优先的放法,线程按行排。
__syncthreads();
matrixTest[index] = sData[threadIdx.y][threadIdx.x];
// 当多个线程(束)一起寻址时,不会发生bank conflict
}
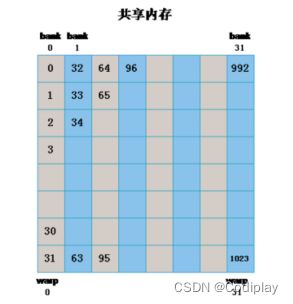
若线程按列排,
以上代码,索引原矩阵项不变,即matrix[index]还是原来的(因为原来访问的该怎么访问怎么访问)
唯一需要改的就是在shared memory中线程的排列把sData[threadIdx.y][threadIdx.x]改为sData[threadIdx.x][threadIdx.y]就可以实现下面的排列:
想要解决Bank Conflict只需要把sData[BLOCKSIZE][BLOCKSIZE]改为sData[BLOCKSIZE][BLOCKSIZE + 1],索引threadIdx.x和threadIdx.y 不变。使得造成一个大小的偏移(如果想造成一行的偏移?两个大小的偏移?都可以同理可得)
同样的道理 a[3][4] 和 b[4][5]
索引下标为相同的(2,3),但是偏移量不同。线性矩阵存储本质还是线性的。
8 * 9 ——> 9 * 8
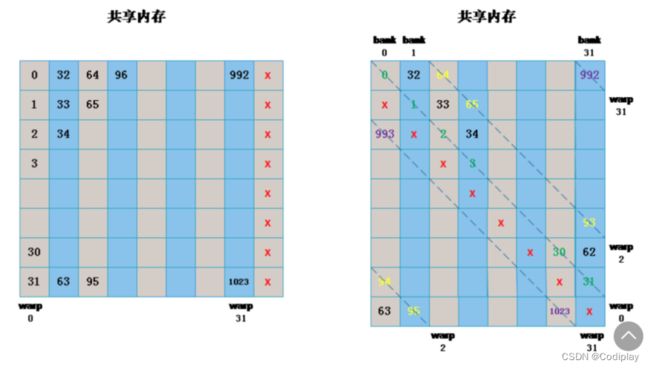
最终代码:
//全局中取一个block大小的数据,可由matrix[index]索引到该数据
int ix = blockDim.x * blockIdx.x + threadIdx.x;
int iy = blockDim.y * blockIdx.y + threadIdx.y;
int index = iy * nx + ix; //因为在全局中存储方式是行优先,所以还是iy * nx + ix
__shared__ float sData[BLOCKSIZE][BLOCKSIZE + 1];
if(ix < nx & iy < ny) {
sData[threadIdx.x][threadIdx.y] = matrix[index];
// 将全局的matrix[index]的值放到新设定的sData中的矩阵中去,
// 选择行优先的放法,线程按行排。
__syncthreads();
matrixTest[index] = sData[threadIdx.x][threadIdx.y];
// 当多个线程(束)一起寻址时,不会发生bank conflict
}
三、用shared memory优化矩阵运算
当今矩阵运算速度的限制集中在访存的限制,我们的思想是把某些经常被访问的位置的元素在global memory的访存操作转移到对shared memory上,从而优化矩阵运算
如果想用shared memory就不得不面对以下几个问题:
- shared memory本身的大小限制(每次走一个block大小)
- 同步问题(__syncthreads)
- bank conflict问题(选用行优先)
想象着有序地(同步)进行如下操作:
1、把左侧矩阵的当前sub这个block放到tile_a中,上方矩阵放到tile_b中。
2、同步(等待都按行写入后,再进行下面的操作)
3、该block内的行列进行点积操作,并存储到局部变量tmp中。
4、同步(等待都进行完点积运算后,再写下一个block)
具体注释看代码:
naive的矩阵乘和shared memory优化版本,对比着看。
#define BLOCK_SIZE 16
__global__ void gpu_matrix_mult(int *a,int *b, int *c, int m, int n, int k)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int sum = 0;
if( col < k && row < m) // m * k
{
for(int i = 0; i < n; i++) // m * n n * k ——> m * k
{
sum += a[row * n + i] * b[i * k + col];
// m * n n * k
}
c[row * k + col] = sum;
}
}
__global__ void gpu_matrix_mult_shared(int *d_a, int *d_b, int *d_result, int n) // 只需要传入n这个参数
{
__shared__ int tile_a[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int tile_b[BLOCK_SIZE][BLOCK_SIZE];
//方阵中 BLOCK_SIZE = blockDim.x = blockDim.y
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int tmp = 0;
int idx;
for (int sub = 0; sub < gridDim.x; ++sub) // 每次走一个block大小的"步"(受限于shared_memory大小),能走gridDim.x步。(grid由block构成)
{
// 别忘了需要避免Bank Conflict,选用行优先存入tile_a分块矩阵中。
// 比上面的gpu_matrix_mult多了下面四行代码,实现将d_a复制到tile_a的操作
idx = row * n + sub * BLOCK_SIZE + threadIdx.x;
// 单看a中对应的矩阵块、
// 上方共row行,一行n个矩阵块,所以idx += row * n
// 前面(左侧)共有sub个block_size大小的block,threadIdx.x表示在该block内的哪个位置
tile_a[threadIdx.y][threadIdx.x] = row<n && (sub * BLOCK_SIZE + threadIdx.x)<n? d_a[idx]:0;
idx = (sub * BLOCK_SIZE + threadIdx.y) * n + col;
// 单看b对应的矩阵块
// 上方共有sub * BLOCK_SIZE大小的block,threadIdx.y表示在该block的哪个位置,两个加起来表示上方共这么多行
// col 表示矩阵块左侧有多少个单位。
tile_b[threadIdx.y][threadIdx.x] = col<n && (sub * BLOCK_SIZE + threadIdx.y)<n? d_b[idx]:0;
__syncthreads(); //等所有都放到tile矩阵中后才能保证下方加的tile中的值是对应的元素
for (int k = 0; k < BLOCK_SIZE; ++k) // 对tile_a进行读取。对于线程(row,col)要多次读取block_size大小的一行和一列
{
tmp += tile_a[threadIdx.y][k] * tile_b[k][threadIdx.x];
}
__syncthreads(); //等这一组blcok加完之后才能进行下一个block,要不然提前进入了会导致加错
}
// tmp是在register内的,线程级别的。里面存储了几个block步乘加的所有值,最后写到该位置对应的结果矩阵中。
if(row < n && col < n)
{
d_result[row * n + col] = tmp;
}
}
main函数(套路性):
int main(int argc, char const *argv[])
{
int m=1000;
int n=1000;
int k=1000;
int *h_a, *h_b, *h_c, *h_cc, *h_cs;
CHECK(cudaMallocHost((void **) &h_a, sizeof(int)*m*n));
CHECK(cudaMallocHost((void **) &h_b, sizeof(int)*n*k));
CHECK(cudaMallocHost((void **) &h_c, sizeof(int)*m*k));
CHECK(cudaMallocHost((void **) &h_cc, sizeof(int)*m*k));
CHECK(cudaMallocHost((void **) &h_cs, sizeof(int)*m*k));
cudaEvent_t start, stop,stop_share;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventCreate(&stop_share));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = 1;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = 0;
}
}
int *d_a, *d_b, *d_c, *d_c_share;
CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n));
CHECK(cudaMalloc((void **) &d_b, sizeof(int)*n*k));
CHECK(cudaMalloc((void **) &d_c, sizeof(int)*m*k));
CHECK(cudaMalloc((void **) &d_c_share, sizeof(int)*m*k));
CHECK(cudaEventRecord(start));
// copy matrix A and B from host to device memory
CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice));
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m,n,k);
CHECK(cudaMemcpy(h_c, d_c, (sizeof(int)*m*k), cudaMemcpyDeviceToHost));
//cudaThreadSynchronize();
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
gpu_matrix_mult_shared<<<dimGrid, dimBlock>>>(d_a, d_b, d_c_share, n);
CHECK(cudaMemcpy(h_cs, d_c_share, (sizeof(int)*m*k), cudaMemcpyDeviceToHost));
CHECK(cudaEventRecord(stop_share));
CHECK(cudaEventSynchronize(stop_share));
float elapsed_time, elapsed_time_share;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
CHECK(cudaEventElapsedTime(&elapsed_time_share, stop, stop_share));
printf("Time_global = %g ms.\n", elapsed_time);
printf("Time_share = %g ms.\n", elapsed_time_share);
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
//cpu_matrix_mult(h_a, h_b, h_c, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cs[i*k + j] - 0)>(1.0e-10))
{
printf("hcs: %d hc: %d ",h_cs[i*k + j], h_c[i*k + j]);
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory
CHECK(cudaFree(d_a));
CHECK(cudaFree(d_b));
CHECK(cudaFree(d_c));
CHECK(cudaFreeHost(h_a));
CHECK(cudaFreeHost(h_b));
CHECK(cudaFreeHost(h_c));
return 0;
}
实验结果:

附:杂谈,便于理解的小知识
读、写、算
cuda core —— 64 物理上同时最多有64个线程并行
逻辑上有很多个线程都可以并行
越来越多的是sm,这个级别的,是sm这个级别。cuda core 多的话同步的代价比较大。
越来越多种类的cuda core 一开始只有int 单精 双精
后来有Tensor core 、 transformer core ?
核函数,int a,b,c 都是在寄存器中的。
超过要补0。因为你选的一个tile_width不一定整除。

编写程序的时候,一个kernel核函数实际上就是最小的一个线程级别的函数。我们只需要管这个线程要实现怎样的操作即可,对于我们写这个函数来说硬件如何实现是透明的。
n个线程同时并行,实现并行运算。一个kernel实际上会启动很多线程,这些线程是逻辑上并行的,但是在物理层却并不一定。
这其实和CPU的多线程有类似之处,多线程如果没有多核支持,在物理层也是无法实现并行的。逻辑上和单核CPU一样,虽然只有一个核,但是还能实现多线程。
但是呢,硬件组织这些线程是有一定硬件逻辑在的。比如规划一个grid中如何组织block,一个block中如何组织线程。
然后对应着物理硬件层面,每个core某一刻只能对应一个thread,每32个thread构成一个warp,warp的意义是什么?block,一个block共享shared memory