【爬虫进阶】猿人学任务六之回溯(难度3.0)
目录
- 前言
- 分析
- 扣代码
- Js改写
- 代码过程
- 结果
前言
本文讲解猿人学web题目第6题,内容难点如下:颜文字,JSUnFuck
分析
-
打开题目网站,F12,点击XHR,找出数据接口
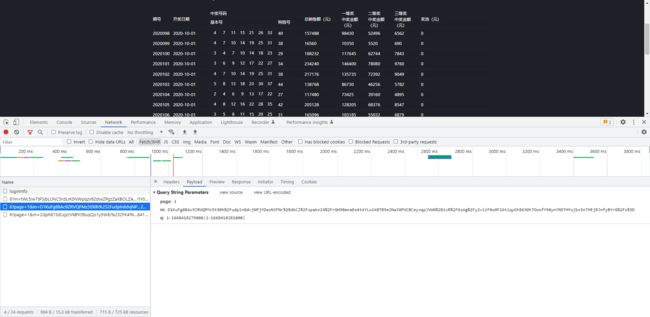
-
看到请求参数这里,m是加密的,q是两个时间戳
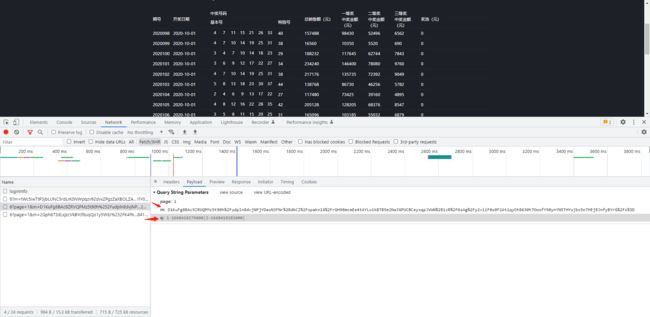
-
全局搜索加密参数,发现不好找,那我们从调用栈入手
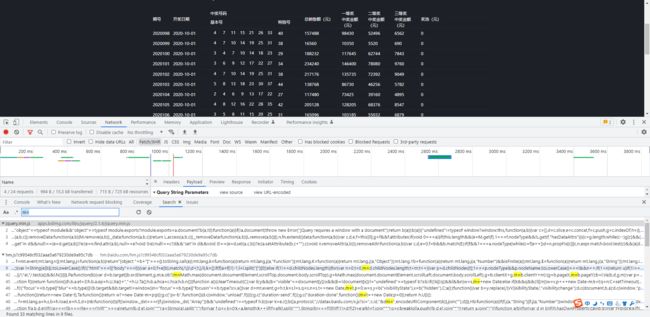
-
前面两个jQuery直接跳过,从第三个开始找

-
进来之后,格式化一下代码,发现m参数就在这里,打上断点,看看怎么事
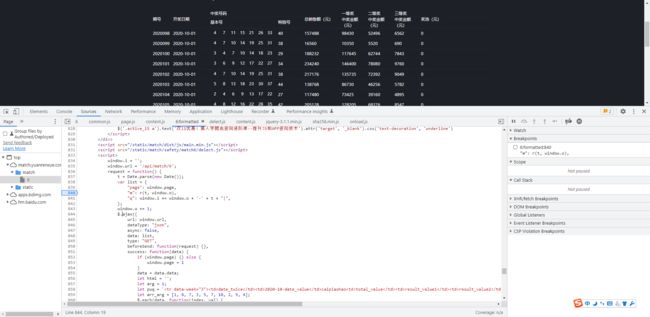
-
F11单步跟一下,跳转进来
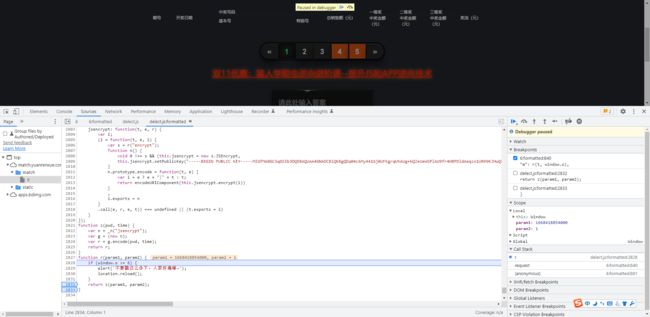
-
我们在r这里打一点断点,F8跟一下,r与m值一致!
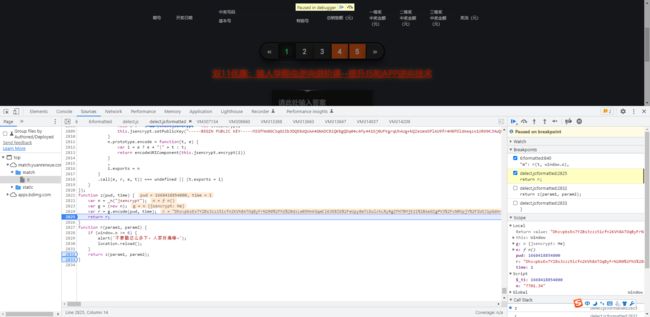
-
调式过程中,发现上面有一个颜文字,解密工具(链接)
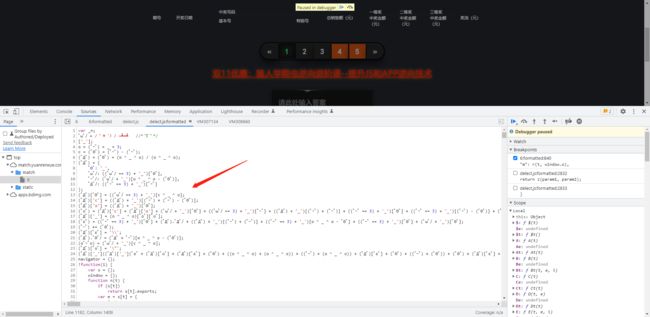
-
解密结果如下:

-
继续调式发现一个JsUnFuck,一直卡这里过不去,解密工具(链接)
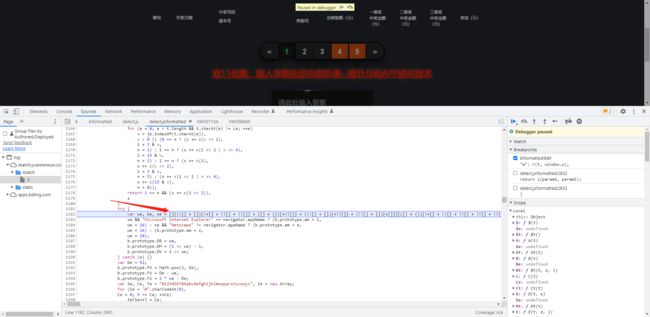
-
解密结果为false

-
最后有个window无效置空

-
q比较简单,就是一个时间戳,直接用python还原一下,就不多说明了!
扣代码
直接将整个代码拿下来
Js改写
把解密后的代码加进去
window = global;
var _n;
window.o = 1;
navigator = {};
try {
var we, ke, xe = false;
xe && "Microsoft Internet Explorer" == navigator.appName ? (b.prototype.am = i,
we = 26) : xe && "Netscape" != navigator.appName ? (b.prototype.am = e,
we = 26) : (b.prototype.am = s,
we = 28),
b.prototype.DB = we,
b.prototype.DM = (1 << we) - 1,
b.prototype.DV = 1 << we;
} catch (e) {
}
把无效置空删掉
function r(param1, param2) {
param1 = parseInt(param1);
param2 = parseInt(param2);
return z(param1, param2);
}
代码过程
import requests
import execjs
class test(object):
def __init__(self):
self.url = "https://match.yuanrenxue.com/api/match/6"
def get_res(self):
Headers = {
"user-agent": "yuanrenxue.project"
}
# 打开文件加载js
with open('案例.js', 'r', encoding='utf-8') as f:
jsCode = f.read()
Func = execjs.compile(jsCode.replace(u'\xa0', u''))
all_sum = 0
for j in range(1, 6):
import time
t = int(time.time()) * 1000
m = Func.call('r', t, 1)
q = '1' + '-' + str(t) + "|"
params = {
"page": str(j),
"m": m,
"q": q
}
# print(params)
res = requests.get(self.url, headers=Headers, params=params)
for data in res.json()['data']:
print(data)
all_sum += data['value'] + data['value'] * 23
print(all_sum)
if __name__ == '__main__':
d = test()
d.get_res()
结果
点关注不迷路,本文若对你有帮助,烦请三连支持一下 ❤️❤️❤️
各位的支持和认可就是我最大的动力❤️❤️❤️