Xtensa DSP结构学习
前言
以下是阅读 Xtensa DSP TRM过程记录的一些笔迹
Core
寄存器
| 助记符 | 数量 | 宽度 | 描述 | R/W | 编号 |
|---|---|---|---|---|---|
| AR | 16 | 32 | 通用寄存器 | R/W | - |
| PC | 1 | 32 | 程序计数器 | R/W | - |
| SAR | 1 | 6 | 移位数寄存器 | R/W | 3 |
如果配置了窗口寄存器选项,通用寄存器会 > 16
内存
地址结构:

如果没有MMU,PA = VA
可以看到高2位被无视(如果配置了窗口寄存器选项,高2位用于保存窗口增量),故程序只能在 1G 地址内转跳
指令总结
OPTION
Xtensa是一个高可定制化的处理器,以下是其支持的配置
异常相关选项
异常3选项
看的时候忘了做笔记了,然后我司的DSP使用的也是exception2,这个exception3后面有空再补上吧,反正都差不多。
*异常2选项
状态寄存器


PS
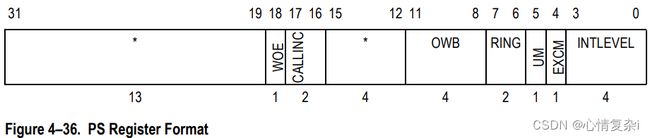
描述如下:
- INTLEVEL:当前中断级别
- EXCM:异常模式
- 0:正常模式
- 1:异常模式
- RING:特权级别(MMU or MPU)
- OWB:旧的窗口基址(Windows)
- CALLINC:等于
CallN的N,使用entry指令去旋转窗口 - WOE:窗口溢出检测是能;0关闭,1开启
EXCCAUSE
异常原因寄存器

可能的值如下:

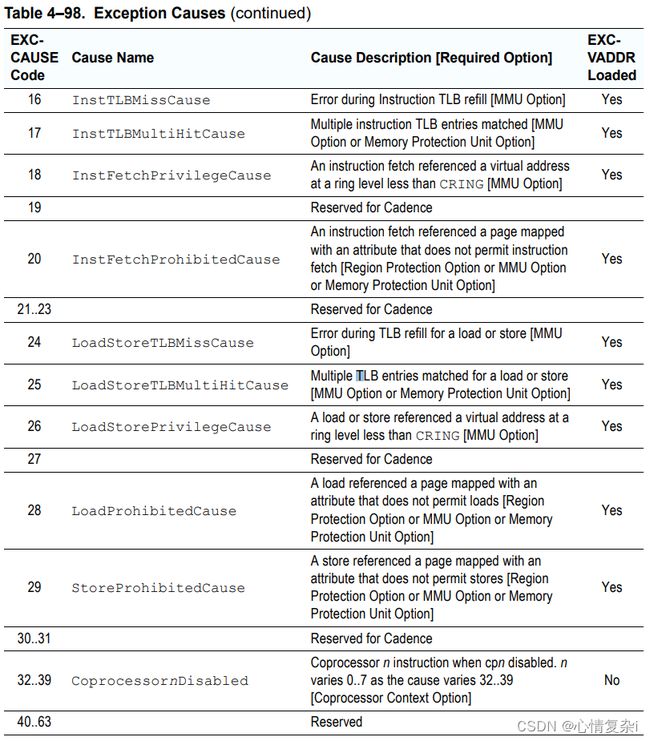
第四列表示是否将出错的地址保存在EXCVADDR寄存器
EXCVADR

EPC
保存出错的PC 地址

- 异常选项只定义了一个EPC寄存器,EPC[1]
- 高优先级Option会拓展该寄存器,EPC[2 … NLEVEL + NNMI]
- 还有个DEPC寄存器用于DoubleExceptionVector,EXECSAVE寄存器留给软件使用,这里就不截图了
NOTE:
- EPC[1],EXECSAVE[1] Exception Option2只提供一个,高优先级中断Option会拓展这2个寄存器 -> EPC[2 … NLEVEL+NMI]
额外指令
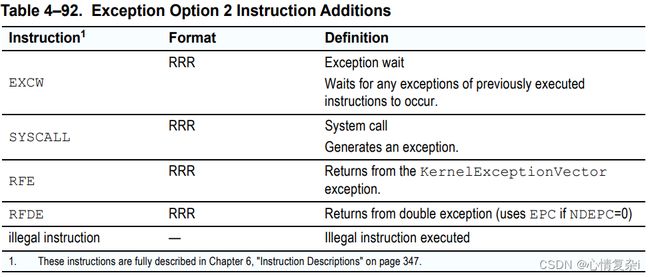
异常
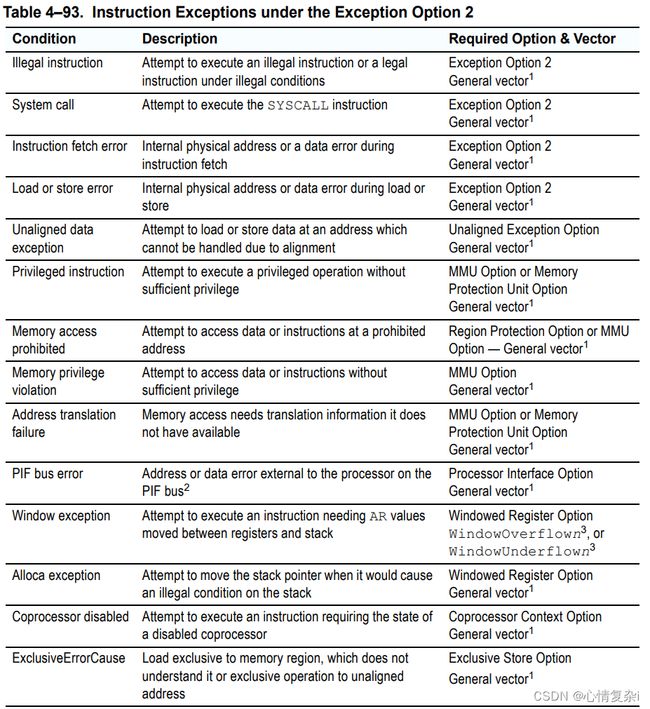
Note:
- 第一列是异常原因,第三列是重定向到的向量
- 通用向量(General vector) = 以下值:
- if PS.EXCM == 1:DoubleExceptionVector
- if PS.EXCM == 0 && PS.UM == 1:UserExceptionVector
- if PS.EXCM == 0 && PS.UM == 0:KernelExceptionVector
中断

Note:
- 第一列是异常原因,第三列是重定向到的向量
- 通用向量(General vector) = 以下值:
- if PS.EXCM == 1:DoubleExceptionVector
- if PS.EXCM == 0 && PS.UM == 1:UserExceptionVector
- if PS.EXCM == 0 && PS.UM == 0:KernelExceptionVector
- NMI优先级 > level[1 … 6] 和 debug
- Level=1是高优先级,Level=2…6是中优先级
调试异常


Note:
- 第一列是异常原因,第三列是重定向到的向量
向量概要
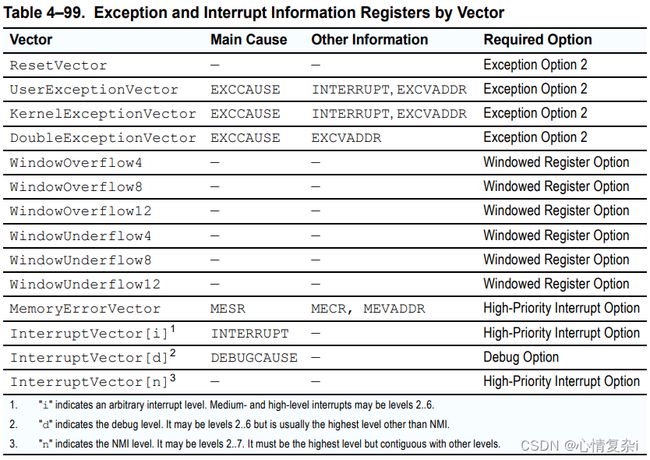
向量返回
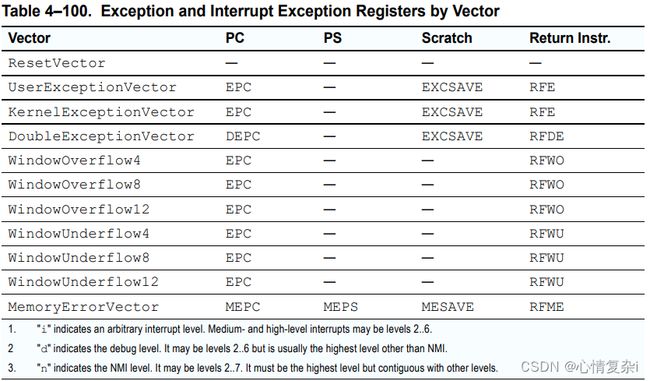
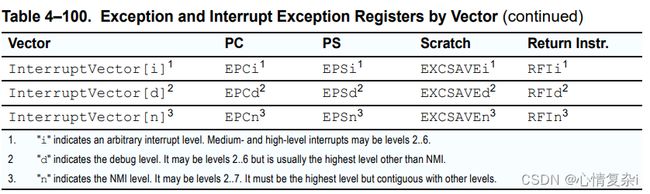
NOTE:
- 第二列:保存出错的地址
- 第三列:保存出错的程序状态
- 第四列:提供给软件使用的临时备份寄存器
- 第五列:对应的返回指令
异常优先级
Cadence只是将异常分组,然后排优先级,同组的优先级未定义,如下:
- Pre-Instruction Exceptions:
- NMI
- 高优先级中断(包括debug中断调试异常)
- Level1中断
- ICOUNT,IBREAK 调试异常
- Fetch Exceptions:
- Instruction-fetch translation errors(tlb丢失,优先级等)
- InstructionFetchErrorCause (指令获取地址/数据错误)
- ECC/parity exception for Instruction-fetch,指令获取的ECC/奇偶校验异常
- Decode Exceptions:
- IllegalInstructionCause
- PrivilegedCause
- SyscallCause (SYSCALL instruction)
- Debug exception for BREAK (BREAK, BREAK.N instructions)
- Execute Register Exceptions:
- Register window overflow
- Register window underflow (RETW, RETW.N instructions)
- AllocaCause (MOVSP instruction)
- CoprocessornDisabledCause
- Execute Data Exceptions:
- Divide by Zero
- PCValueErrorCause
- Execute Memory Exceptions:
- LoadStoreAlignmentCause
- Debug exception for DBREAK
- IHI, PITLB, IPF, or IPFL, or IHU target translation errors
- Load, store, translation errors
- InstructionFetchErrorCause (IPFL target address or data errors)
- LoadStoreAlignmentCause (in the presence of the Hardware Alignment Option)
- ExclusiveErrorCause
- LoadStoreErrorCause (Load or store external address or data errors)
- ECC/parity exception for all accesses except instruction-fetch
向量重定向选项
会把相信分成2个组,静态组和动态组。ResetVector和MemoryErrorVector 在静态组,其余都在动态组。
静态组有2个基地址,默认基址和备份基址;通过 ExternalResetVector 来配置,ExternalResetVector由处理器外部引脚确定状态,处理器在复位时根据引脚来确实使用哪个地址。
- ExternalResetVector == False:则选择2个基址?2个向量不同地址?
- ExternalResetVector == True:选择默认基址,且在复位时从 输入引脚获取备用基址?
动态组使用 VECBASE 寄存器来指定基址
不对齐异常选项
没啥,不对其就产生异常
协处理器上下文选项
跳过,应该用不上
中断选项
实现 level-1 级别中断,最低优先级的中断
提供的寄存器如下:
- PS.INTLEVEL:4bit,控制中断屏蔽级别
- INTENABLE:长度取决于中断数据(level-1中断+高优先级中断+NMI),每个中断t都有个对应的Bit来控制是能
- INTERRUPT:长度取决于中断数据(level-1中断+高优先级中断+NMI),记录每个中断的pending状态
提供的指令:

高优先级中断选项
实现 level2-6级别可配置中断,每个中断都有自己的 EPC[level], EPS[level] ,EXCSAVE[level]寄存器
提供的寄存器:

提供的指令:
RFI:从高优先级中断返回
定时器中断选项
提供的寄存器:

CCOMPARE数量取决于 NCCOMPARE(硬件实现了多少个定时器/比较器)
内存选项
一般Cache功能
基础概念:
- Line:Cache的最小单位
- Index:是指示访问到该Cache所必须的地址信息
- set:如果一个Line有N个地方可以放,被称为
N路集关联 - way:set中line的各个位置的并集称为 ‘way’(有多少个set)
个人理解:
- N路组相联其实,way=2,set不确定,看cache大小,把cache分成2组。
- 组间直接相联,如:4路组相联,4G物理地址,每一G只能访问到某一组
- 组内全相联,如:4路组相联,4G物理地址,每一G能在某一组的任意位置放数据
- 如果way=1,1组相联。所有内存都只能访问到固定一个组;就退化成了全相联了。
- 如果set=1,每个组就一个line,所有内存都只能访问到固定一个Line(因为一个组就一个Line),退化成直接相联
- Tag:确定是哪一路(哪一个tag)
- Set:确定在Set中的哪一个Line
中间跳过一部分cache格式的内容,我们并不关心,也不能设置,都是设计的时候已经决定了。
指令Cache选项
寄存器

指令
- IPF( 指令缓存取址):将指令预取到cache中
- IHI( 指令缓存命中无效):指令名字无效(无效某个指令)
- III(指令缓存索引无效):无效一个index
PS:多半用不上,一般没人动指令cache
指令Cache测试选项
提供了一些指令cache读写指令,如下:

指令Cache Index锁定选项
跳过
分支预测选项
没啥,会在 MEMCTL寄存器有个位控制是能
分支预测测试选项
跳过
数据Cache选项

提供的指令较多,有:
- DPFR, DPFW, DPFRO, DPFWO:一些数据cache的预取读写指令
- DHWB:如果数据存在,并被修改,则将数据回写,并标记为未修改,否则误操作
- DHWBI:如果数据存在,并被修改,则将数据回写,并标记为无效
- DIWB:跟
DHWB类似,只是DHWB指定的是地址,这个指定的是index - DIWBI:跟
DHWBI类似,只是DHWBI指定的是地址,这个指定的是index - DIWBUI.P:P是锁定的意思,操作过程中锁定一行
- DHI:无效指定地址的数据
- DII:无效指定index的数据
MEMCTL寄存器


Note:
- 如果要增大way直接往 DUseWay,DAllocWay,IUseWay 写更大的数即可
- 如果要减少dcache way,先往 DAllocWay 写一个更小的数,然后进入一个循环使用 DIWBUI.P 将数据写回,最后向 DUseWay 写入目标数字
- 上电通常写入一个bit[31:8]=1的数
数据Cache测试选项
添加一些Dcache 读写指令,跳过
数据Cache锁定选项
跳过
预取选项


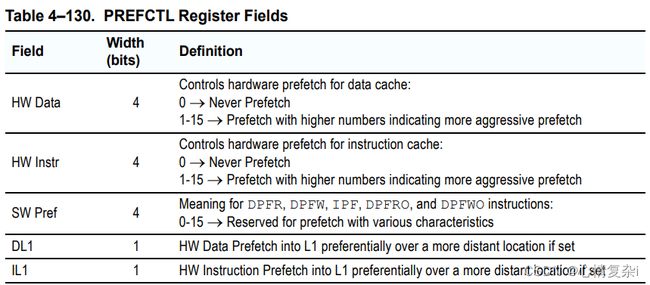
- HW Data,HW Instr:0不预取,1-15,越大预取约主动
- SW Pref:对于 DPFR, DPFW, IPF, DPFRO, and DPFWO 指令保留预取特性?
- DL1,IL1:预取到L1优先级高于较远地方?
快预取选项
就是预取的升级版,一下子预取一个块
提供的寄存器和指令如下:

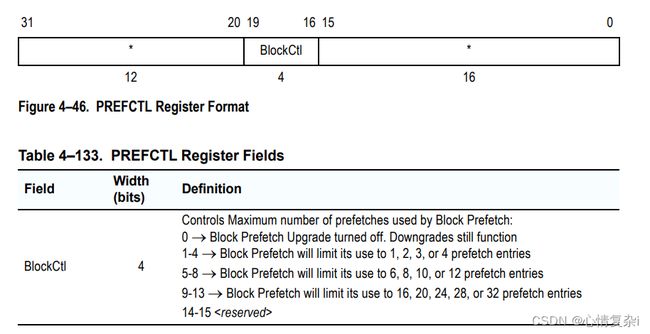
BlockCtl:限制一个block预取,预取多少个实例
通用RAM/ROM选项功能
指令RAM 仅能被L32I, L32I.N, L32R, S32I, S32I.N 指令作为数据引用。
指令ROM 仅能被L32I, L32I.N, L32R 指令作为数据引用
上面2个功能,仅有在 “指令内存访问选项” 配置时可用。
RAM/ROM访问限制如下:

- LSE:在异常2发生load stroe err 或 在异常3发生Invalid Local Memory Access
- IFE:在异常2发生Instruction fetch error 或 在异常3发生Invalid Local Memory Access
iRAM选项
提供一个内部读写指令内存。
一般用于存储指令(没有ICACHE)或 出于性能原因必须有固定访问时间的代码。
仅能被L32I, L32I.N, L32R, S32I, S32I.N 指令访问到。
虽然有提供读写指令,但是官方不建议存放数据,因为访问会比 data RAM/ROM 慢
iROM选项
提供一个内部只读指令内存。
一般用于存储指令(没有ICACHE)或 出于性能原因必须有固定访问时间的代码。因为ROM是只读的,所以只有不需要更改的代码放这里。
指令ROM 仅能被L32I, L32I.N, L32R 指令作为数据加载
虽然有提供读指令,但是官方不建议使用,因为访问会比 data RAM/ROM 慢
指令内存访问选项
打开后可以使用特定的指令访问 iRAM/iRON,也就是上面提到的 L32I, L32I.N, L32R, S32I, S32I.N 指令。
dRAM选项
提供一个内部读写数据内存。
一般用于存储数据(没有DCACHE)或 出于性能原因必须有固定访问时间的数据。
仅能被L32I, L32I.N, L32R, S32I, S32I.N 指令访问到。
虽然有提供读写指令,但是官方不建议存放数据,因为访问会比 data RAM/ROM 慢
dRAM选项
提供一个内部只读指令内存。
一般用于存储数据(没有ICACHE)或 出于性能原因必须有固定访问时间的数据。
XLMI选项
跳过
APB选项
跳过
硬件对齐选项
处理去通过多次读取,合并来处理不对齐访问
内存奇偶校验选项
跳过
内存保护和转换
内存转换概述

- ASID:地址空间标识
- VPN:虚拟地址页号
- PPN:物理地址页号
- TLB:这里表示完成翻译的硬件
具体过程不多累赘了,百度一大堆
地址保护概述
多级递减特权,成为 ring。可通过 RingCount 来配置特权数。
Xtensa 默认特权:ring=0内核,ring=1用户。
Xtensa 支持 3,4等更多特权,但是特权模式切换必须有ring=0来进行。
打开 MPU选项或MMU选项后 RingCount = 1
每个Xtensa ring都有自己的ASID。ring = 0 的 ASID硬件=1,其他级别的ASIO由 RASIO指定。
每个ASID都有一个单独的ring,尽管在同一个环级上可能有很多ASID(ring0除外),这就允许嵌套特权共享。
页面的ring不保存在TLB中;只有ASID被存储。
当在TLB中查找虚拟地址匹配时,会根据记录的ASID去RASID寄存器查找对应的ring。
如果页面的 ring < 处理器当前的特权级别(cring),则拒绝访问,并抛出一个异常(InstFetchPrivilegeCause或LoadStorePrivilegeCause)。
内核在当内核在不同地址空间运行时,通常都会重新分配ASID。
假如 ASIDBits = 8 并且 RingCount = 2,254次切换后会刷新TLB
内存访问过程
略,一般DSP都作为小核集成,都不会配置MMU
区域保护选项
为地址8个512M空间提供保护
异常:
- InstFetchProhibitedCause:区域内不允许取址
- LoadProhibitedCause:区域内不允许load
- StoreProhibitedCause:区域内不允许stroe
提供的指令:

区域转换选项
基于前面的区域保护选项,在地址前3bit增加了虚拟到物理的转换,每一个512M区域都可重定向。
没有提到额外的寄存器或指令
*内存保护单元选项
MPU比前面的保护选项更灵活,但是不带翻译功能
Note:和 区域保护选项,MMU选项冲突
对应异常:


提到的额外寄存器
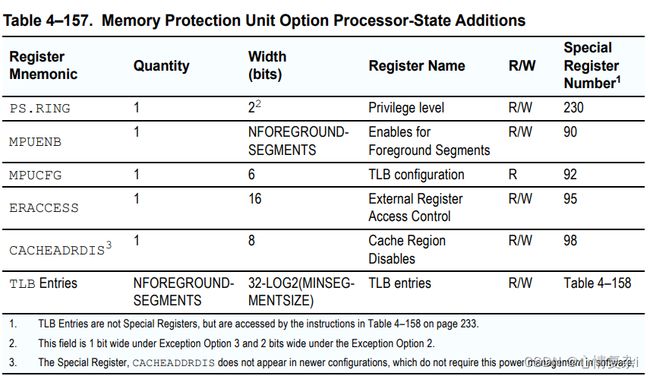
提到的额外指令:


MPU寄存器格式:
- MPUCFG:只读,表示有多少个段被配置
- PMUENB:使能位,每个bit对应一个段。
- ERACCESS:每个bit对应一个REI区域,用来配置是否可访问。
- CACHEADRDIS:每个bit对应一个512M区域,配置是否可cache
内存保护单元选项TLB的结构:
MPU分为前台映射和后台映射。
- 如果匹配到前台映射则使用前台,否则使用后台
- 前台映射提供32个表项,如果2个映射具有相同的最低地址,则优先使用序号高的
- if MPULOCKABLE = false,表项要按地址顺序排列,每个表项地址不能小于前一个的地址,因为有限使用序号高的,如果相同序号低的永远不会被匹配
- if MPULOCKABLE = true,表项不需要按地址顺利排列,序号低的具有高优先级
MPU WPTLB指令地址格式:

- if MPULOCKABLE = false,lock位=1,表示表项不能被修改
- if MPULOCKABLE = true,lock位可以由软件来设置
- MBZ:写入时必须是0
MPU WPTLB指令数据格式

后面大同小异,介绍各条指令的地址,数据格式,具体请参考手册。
Acc rights字段格式如下:


Memory Type字段含义:

用到的字母含义:
- B:=0 non-Bufferable,=1 Bufferable
- C:=0 Write-through,=1 Writeback
- W:=0 no-Write-allocate,=1 Write-allocate
- R:=0 no-Read-allocate,=1 Read-allocate
- I:=0 Outer-shareable,=1 Inner-shareable
- c:同C
- w:同W
- r:同R
MMU选项
跳过
其他选项
*窗口寄存器选项
提供更过物理寄存器,逻辑寄存器不变(16个),在调用子程序的时,仅需改变对应关系(旋转)即可,从而减少寄存器保存。
旋转是已4个寄存器为单位的(4个一组),因此 WindowBase 寄存器位数 = log2(NREGS/4)
在调用时进行旋转可以立即保存一些寄存器,并为被调用的例程提供新的寄存器。每个保存的寄存器在堆栈上都有一个保留位置,如果调用堆栈扩展到足够远,需要重用物理寄存器(溢出),则可以将其保存到该位置。如:32个物理寄存器,16个逻辑寄存器,每次旋转2组(8个),(32-16)/8 = 2 次,当调用深度=3时,就会发现溢出,需要保存物理寄存器了。
WindowStart特殊寄存器:表示哪一组寄存器单元当前缓存在物理寄存器中,而不是保存在堆栈。(正在使用的物理寄存器)
Overflow 异常:访问父函数用到的寄存器导致,该异常保存这些寄存器值,并释放寄存器供使用。
Underflow异常:返回时,如果父寄存器被保存到堆栈中(发生过Overflow 异常)就会触发该异常,该异常将恢复这些值。
旋转支支持4,8,12。故对应异常有:
- WindowOverflow4,WindowUnderflow4
- WindowOverflow8,WindowUnderflow8
- WindowOverflow12,WindowUnderflow12
提供的额外寄存器如下:
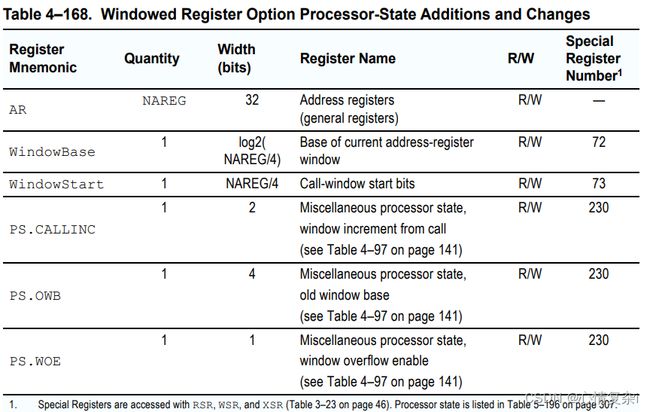
提供的指令如下:

WindowBase 寄存器给出当前的窗口位置,逻辑寄存器[i] = 物理寄存器[i + WindowBase/4]
WindowStart 寄存器显示物理寄存器的状态,每个寄存器对应一个bit。bit由ENTRY设置,retw指令清除
调用、进入和返回机制
- 调用
CALLn/CALLXn指令:旋转n个寄存器(n = 4,8,12)- n -> PS.CALLINC
- AR[n * 4] = (n << 30) | nexPC[29:0]
- 进入
ENTRY s, imm12- AR[PS.CALLINC << 2 | s[1:0] ] = AR[s] - (imm12 << 3)
- WindowsBase += PS.CALLINC
- WindowsStart.Windowsbase = 1
- 返回
RETW/RETW.N- n = AR[0] >> 30
- newpc = PC高2bit | AR[0]低30bit
- WindowsBase -= n
- WindowsBase.owb = 0
可见地址的高2位用来记录窗口增量了,所以只能在 4G/8 = 512M 范围内转跳
窗口子程序调用协议
寄存器ABI:
- a0:返回地址
- a1/sp:堆栈指针
- a2-a7:输入、输出、返回值
仅使用a2、a3保存参数的可以使用CALL4/8/12来保存4,8,12个活动寄存器
使用a2…a7保存参数的只能使用CALL8/12
栈帧结构
栈帧结构如图所示:

基础保存区可以保存4个寄存器值(a0-a3),超过4个部分,将保存至额外区域。该区域可以通过上一个栈帧的sp减去一个固定的偏移得到。
实际的堆栈总比堆栈指针(sp)低16字节
基础保存区保存父函数的a0-a3
父函数的额外保存区保存自己的 a4 … a7(call8)或 a4 … a11(call12)
假设:SP:当前SP
- 上一个 a0 = *(SP-16)
- 上一个 a1 = *(SP-12)(sp就是a1)
- 上一个 a2 = *(SP -8)
- 上一个 a3 = *(SP-4)
- 当前额外保存区 = 上一个SP - 20 = *(*(SP-12) - 20)
- 第一个元素(a7) 上一SP - 20 - 0 = *(*(SP-12) - 20)
- 第二个元素(a6) 上一SP - 20 - 4 = *(*(SP-12) - 24)
- 第三个元素(a5) 上一SP - 20 - 8 = *(*(SP-12) - 28)
- 第四个元素(a4) 上一SP - 20 - 12 = *(*(SP-12) - 32)
栈帧结构对我们分析异常情况有帮助,我们这里在多讲一下,下面以call8为例。
下面是官方该处的参考处理程序:
; call[j]是调用者,call[j+1]是被调用者, call[j+1]会用到父函数的寄存器,故发生溢出中断
WindowOverflow4:
s32e a0, a5, -16 ; save a0 to call[j+1]’s frame
s32e a1, a5, -12 ; save a1 to call[j+1]’s frame
s32e a2, a5, -8 ; save a2 to call[j+1]’s frame
s32e a3, a5, -4 ; save a3 to call[j+1]’s frame
rfwo
WindowUnderflow4:
l32e a0, a5, -16 ; restore a0 from call[i+1]’s frame
l32e a1, a5, -12 ; restore a1 from call[i+1]’s frame
l32e a2, a5, -8 ; restore a2 from call[i+1]’s frame
l32e a3, a5, -4 ; restore a3 from call[i+1]’s frame
rfwu
WindowOverflow8:
; 未旋转,故 a[0 .. 7] 当前函数的寄存器; a[a8 .. 15] 子函数的寄存器
; 将 a0-a3 保存操 call[j+1] 的基础保存区
s32e a0, a9, -16 ; 保存 a0 到 call[j+1] 栈上
s32e a1, a9, -12 ; save a1 to call[j+1]’s frame
s32e a2, a9, -8 ; save a2 to call[j+1]’s frame
s32e a3, a9, -4 ; save a3 to call[j+1]’s frame
; 将 a4-a7 保存到 call[j+1] 的额外保存区
l32e a0, a1, -12 ; 从call[j]的基础保存区或者上一个sp
s32e a4, a0, -32 ; save a4 to call[j]’s extra save area
s32e a5, a0, -28 ; save a5 to call[j]’s extra save area
s32e a6, a0, -24 ; save a6 to call[j]’s extra save area
s32e a7, a0, -20 ; save a7 to call[j]’s extra save area
rfwo
WindowUnderflow8:
; 已旋转,故 a[0 .. 7] 当前函数的寄存器; a[a8 .. 15] 子函数的寄存器
; 从 当前SP的基础保存区 恢复 父函数的 a0-a3
l32e a0, a9, -16 ; restore a0 from call[i+1]’s frame
l32e a1, a9, -12 ; restore a1 from call[i+1]’s frame
l32e a2, a9, -8 ; restore a2 from call[i+1]’s frame
l32e a3, a9, -4 ; restore a3 from call[i+1]’s frame
; 从 上一个SP 的额外保存区恢复寄存器值
l32e a7, a1, -12 ; a7 <- call[i-1]’s sp
l32e a4, a7, -32 ; restore a4 from call[i]’s frame
l32e a5, a7, -28 ; restore a5 from call[i]’s frame
l32e a6, a7, -24 ; restore a6 from call[i]’s frame
l32e a7, a7, -20 ; restore a7 from call[i]’s frame
rfwu
WindowOverflow12:
s32e a0, a13, -16 ; save a0 to call[j+1]’s frame
l32e a0, a1, -12 ; a0 <- call[j-1]’s sp
s32e a1, a13, -12 ; save a1 to call[j+1]’s frame
s32e a2, a13, -8 ; save a2 to call[j+1]’s frame
s32e a3, a13, -4 ; save a3 to call[j+1]’s frame
s32e a4, a0, -48 ; save a4 to end of call[j]’s frame
s32e a5, a0, -44 ; save a5 to end of call[j]’s frame
s32e a6, a0, -40 ; save a6 to end of call[j]’s frame
s32e a7, a0, -36 ; save a7 to end of call[j]’s frame
s32e a8, a0, -32 ; save a8 to end of call[j]’s frame
s32e a9, a0, -28 ; save a9 to end of call[j]’s frame
s32e a10, a0, -24 ; save a10 to end of call[j]’s frame
s32e a11, a0, -20 ; save a11 to end of call[j]’s frame
rfwo
WindowUnderflow12:
l32e a0, a13, -16 ; restore a0 from call[i+1]’s frame
l32e a1, a13, -12 ; restore a1 from call[i+1]’s frame
l32e a2, a13, -8 ; restore a2 from call[i+1]’s frame
l32e a11, a1, -12 ; a11 <- call[i-1]’s sp
l32e a3, a13, -4 ; restore a3 from call[i+1]’s frame
l32e a4, a11, -48 ; restore a4 from end of call[i]’s frame
l32e a5, a11, -44 ; restore a5 from end of call[i]’s frame
l32e a6, a11, -40 ; restore a6 from end of call[i]’s frame
l32e a7, a11, -36 ; restore a7 from end of call[i]’s frame
l32e a8, a11, -32 ; restore a8 from end of call[i]’s frame
l32e a9, a11, -28 ; restore a9 from end of call[i]’s frame
l32e a10, a11, -24 ; restore a10 from end of call[i]’s frame
l32e a11, a11, -20 ; restore a11 from end of call[i]’s frame
rfwu
处理器接口选项
处理器接口选项添加了一个总线接口,供内存访问使用,这些内存访问是本地内存以外的位置。 它用于可缓存地址(第 169 页到第 186 页)的缓存未命中,以及缓存绕过内存访问。也可以通过处理器接口选项添加的总线接口配置从外部对本地存储器的直接存储器访问。 直接存储器访问可以是最高带宽的最高优先级,也可以是最高效率的中间优先级。
额外异常

Narrow PC选项
Narrow PC选项的目的是通过PC的高位以及所有寄存器(如EPC或LBEG)来降低处理器功率和门数,这些寄存器包含PC值,强制为一个常量,因此没有静态或动态功耗,也没有实现中的失败。一种新的例外条件使这种减少成为可能。
略…
线程指针选项
线程指针选项提供了一个额外的寄存器,以方便操作系统和工具实现线程本地存储。寄存器可以通过RUR和WUR读取和写入。该寄存器是无特权的,在重置后是未定义的。
额外寄存器
| 助记符 | 数量 | 宽度(bits) | 寄存器名 | R/W | 寄存器编号 |
|---|---|---|---|---|---|
| THREADPTR | 1 | 32 | Thread pointer | R/W | User 231 |
处理器ID选项
在某些应用程序中,有多个Xtensa处理器从同一个指令内存中执行,因此需要区分不同的处理器。
这个选项允许系统逻辑通过读取PRID寄存器为每个处理器提供一个标识。
每个处理器的PRID值通常在 [0 … nprocessor -1],但这不是必需的。prd寄存器复位后是不变的。
额外寄存器
| 助记符 | 数量 | 宽度(bits) | 寄存器名 | R/W | 寄存器编号 |
|---|---|---|---|---|---|
| PRID | 1 | 32 | Processor Id | R | 235 |
CSR 奇偶校验选项
CSR奇偶校验选项将奇偶校验位和奇偶校验检查添加到处理器中实现定义的一组控制和状态寄存器。 当启用检查并检测到奇偶校验错误时,停止处理器。
额外寄存器
| 助记符 | 数量 | 宽度(bits) | 寄存器名 | R/W | 寄存器编号 |
|---|---|---|---|---|---|
| CSRPCTL | 1 | 3 | CSR Parity Control | R/W | 118 |
CSRPCTL寄存器位域:

具体含义:
| 助记符 | 宽度(bits) | 定义 |
|---|---|---|
| Enable | 1 | 启用奇偶校验检查和相关的奇偶校验错误暂停 |
| Test | 1 | 使能测试模式 |
| Parity | 1 | 在测试模式下,设置时读取或写入的奇偶校验错误 |
安全模式位选项
安全模式位选项添加到PS寄存器,当设置时表示非安全模式,当清除时表示安全模式。
异常、中断和重置总是进入安全模式。
本地内存的已定义区域只能在安全模式下访问,该模式可用于外部总线上的未缓存事务。
安全模式位选项状态改变:
| 条件 | PS.NSM(PS[12]) | PS.PNSM(PS[23]) |
|---|---|---|
| 上电/复位 | 1’b01’b0 | 1’b0 |
| 窗口溢出/下溢 | Unchanged | Unchanged |
| 除窗口溢出/下溢外的中断或异常 | 1’b01’b0 | PS.NSM |
| RFE or RFDE | PS.NSM ? 1’b1 : PS.PNSM | 1’b1 |
| RFI[i] | PS.NSM ? 1’b1 : EPS[i][12] | PS.NSM ? 1’b1 : EPS[i][23] |
| RFME | PS.NSM ? 1’b1 : MEPS[12] | PS.NSM ? 1’b1 : MEPS[23] |
| RFDO or RFDD | PS.NSM ? 1’b1 : EPS[dbg][12] | PS.NSM ? 1’b1 : EPS[dbg][23] |
| RFWO or RFWU | Unchanged | Unchanged |
| WSR.PS or XSR.PS | Unchanged | PS.NSM ? 1’b1 : source[23] |
note:
- RFE/RFDE:return form exception/return from double exception
- REI:return from interrupt
部分IRAM/IROM和DataRAM可以被为安全区域。
只有在PS.NSM == 0时,处理器才能访问这些安全区域,否则产生异常。
该异常与可能产生的类似内存保护违例相同。如果从总线端口可以访问这些内存,那么内存的安全区域将产生错误响应,除非总线事务明确表示它是安全事务。
所有其他对这些内存安全区域的访问都将导致某种错误,并且不会成功。IRAM/IROM和DataRAM的部分在配置时被选择为安全区域。
调试选项
调试选项实现指令计数和断点异常,以便通过软件或外部硬件进行调试。该选项使用之前在高优先级中断选项中定义的中断级别。在某些实现中,一些调试中断可能不会被PS. INTLEVEL屏蔽
额外寄存器
| 助记符 | 数量 | 宽度(bits) | 描述 | R/W | 编号 |
|---|---|---|---|---|---|
| ICOUNT | 1 | 2,32 | 指令计数 | R/W | 236 |
| ICOUNTLEVEL | 1 | 4 | 指令计数级别 | R/W | 237 |
| IBREAKA | NIBREAK | 32 | 指令断点地址 | R/W | 128-129 |
| IBREAKENABLE | 1 | NIBREAK | 指令断电使能bit | R/W | 96 |
| DBREAKA | NDBREAK | 32 | 数据断点地址 | R/W | 144-145 |
| DBREAKC | NDBREAK | 8 | 数据断点控制 | R/W | 160-161 |
| DEBUGCAUSE | 1 | 10 | 上次调试异常的原因 | R | 233 |
| DDR3 | 1 | 32 | 调试数据寄存器 | R/W | 104 |
额外指令
| 指令 | 格式 | 定义 |
|---|---|---|
| BREAK | RRR | 断点 |
| BREAK.N | RRRN | 指令某个断点 |
| LDDR32.P | RRR | 从内存加载DDR寄存器 |
| SDDR32.P | RRR | 存储DDR寄存器到内存 |
DEBUGCAUSE 寄存器
DEBUGCAUSE寄存器包含一个编码值,给出处理器接收调试异常的原因。是否设置了所有适用的位,或者是否在存在高优先级条件时检测不到低优先级条件,这是实现特定的。
位域:
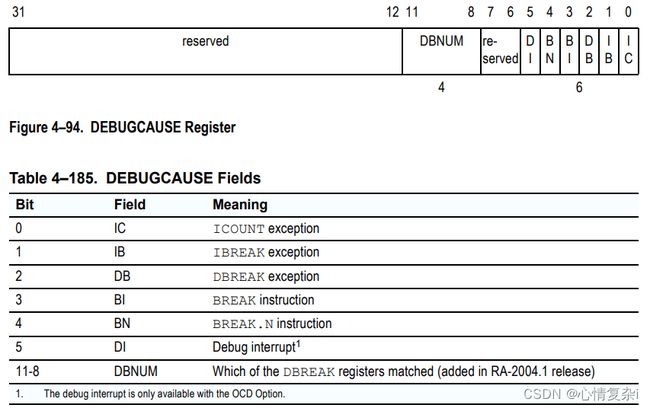
使用断点
BREAK 和 BREAK.N 分别是 是24位和16位指令。
它们在执行时会触发一个 DEBUGLEVEL 异常,且 DEBUGCAUSE 位3或4的置位。
软件可以用断点指令替换一条指令,以便在执行到达被替换的指令时将控制转移到调试监视器。
BREAK 和 BREAK.N 不能用于在 ROM 里的代码,因为ISA提供了一个 可配置的指令地址断点寄存器
处理器还提供可配置数量的数据地址断点寄存器。每个断点指定处理器地址空间中1到64字节之间的两个大小的字节块的自然对齐幂,以及断点是否应该发生在加载或存储或两者上。 覆盖的字节块的最低地址放置在 DBREAKA 寄存器之一中。 被覆盖的字节块的大小放在相应的 DBREAKC 寄存器的低位中,而 DBREAKC 寄存器的高两位包含指示哪些访问类型应该引发异常的指示。 每个可能的块大小的设置显示在下表中。
DBREAKA[i]5…0 下的“x”值允许为该大小指定任何自然对齐的地址。 未定义 DBREAKC 和 DBREAKA 的其他组合的结果。

匹配规则
(if load then DBREAKC[i].30 else DBREAKC[i].31) and
(DBREAKA[i] >= (0x3FFFFFF || DBREAKC[i].5..0 and vAddr)) and
(DBREAKA[i] <= (0x3FFFFFF || DBREAKC[i].5..0 and (vAddr+sz-1)))
sz 是内存访问中的字节数。
也就是内存访问的第一个字节跟最后一个字节会被 0x3FFFFFF || DBREAKC[i].5..0 屏蔽?
调试异常
通常 DEBUGLEVEL 设置为 NLEVEL(可屏蔽中断的最高优先级)。
某些情况下可以被设置为低于 NLEVEL 的级别
指令计数
当 CINTLEVEL < ICOUNTLEVEL 时,ICOUNT寄存器会对指令进行计数,引发异常的指令不会增加ICOUNT。
当 ICOUNT 增加到 0 ,会产生一个ICOUNT异常,ICOUNT异常优先于其他异常。
例如,当 ICOUNTLEVEL 为 1 时,ICOUNT 在发生中断或异常时停止计数,并在返回时重新开始计数。既不是未执行的指令,也不是返回增量 ICOUNT,而是重新执行指令。通过这种机制,无论中断与否,都可以使指令数相同。
指令计数可用于实现单步或多步。对于可重复的程序,也可以用来确定故障点的指令数,并允许程序重新运行到故障点之前的某个点,以便通过跟踪或步进直接观察故障。
ICOUNTLEVEL 设置为 1 会导致单步执行忽略异常和中断,而将其设置为 DEBUGLEVEL 则允许程序员调试异常和中断处理程序。只有当 PS.INTLEVEL 或 PS.EXCM 足够高以至于在更改前后,ICOUNT 都不会递增时,才应修改 ICOUNTLEVEL 寄存器。
调试寄存器:
