SQL Server事物日志
文章目录
- 一、事物日志作用
- 二、事务日志原理
- 三、事物日志管理
-
- 3.1 事物日志监控
- 3.2 事物日志收缩
一、事物日志作用
每个 SQL Server 数据库都具有事务日志,用于记录所有事务以及每个事务对数据库所做的修改。事物日志的作用主要如下:
- WAL事务预提交,减少了脏页刷盘的IO消耗,极大的提高了数据库性能
- 崩溃恢复,当数据库发生意外宕机,数据库启动时会进行崩溃恢复的流程,会先读取事务日志进行前滚,将数据恢复到崩溃前的状态;然后进行回滚操作,对事务日志中未提交的事务进行rollback,以此保证数据库中数据的一致性
- 还原数据库至指定的时间点,当数据库出现误操作等故障时,可通过完整备份+差异备份/日志备份进行数据恢复,将数据恢复故障前的时间点
- 高可用性和灾难恢复解决方案: Always On 可用性组、数据库镜像和日志传送
对于内存中的脏页的刷盘主要有以下两种方式:
- 检查点会周期性扫描内存数据将脏页进行刷盘
- 当数据库内存达到高水位后,LazyWriter也会将内存中脏页进行刷盘
二、事务日志原理
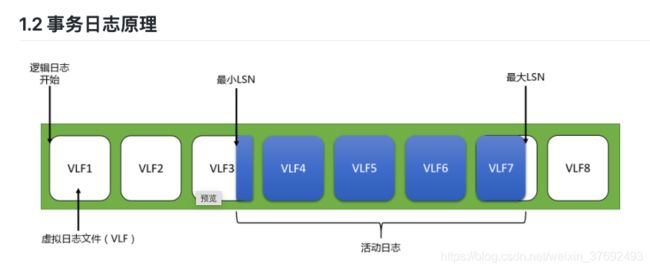
如上图,SQL Server的日志由多个虚拟日志文件(Vitual Log Files(VLF))组成,事务日志被截断的基本单位是VLF而不是数据页,对于事务日志中的日志记录都有自己的逻辑序列号(LSN)进行标记。
1、事物日志状态分类
- 活动(Alive):这个状态的VLF是活动的,因为它至少包含活动日志部分的一条记录,因此它需要被回滚或其他目的。这个状态的VLF是不活动的,但没被截断或备份,空间不可以重用。
- 可恢复(Recoverable):这个状态的VLF是不活动的,但没被截断或备份,空间不可以重用。
- 可重用(Reusable):这个状态的VLF是不活动的,它已被截断或备份,空间可以重用。
- 未使用(Unused):这个状态的VLF是不活动的,在它里面还没有被记录的日志记录。
2、事务日志截断
事物日志截断是以VLF为单位来做截断的,日志截断可以释放日志文件的空间,以便由事务日志重新使用。若事物日志长时间不截断会导致事物日志的不断增长,直至磁盘空间打满。在生产环境中,我们必须做好事物日志的监控,周期性对事物日志进行截断。
3、事物日志自动截断的场景:
- 当数据库处于恢复模式为简单恢复模式时,当每次checkpoint时都会将活动的VLF进行截断,变为可重用状态
- 当数据库处于完整/大容量恢复模式时,只有当进行事务日志备份后,才会将已经备份后的VLF进行截断,变为可重用状态
事物日志的截断并不会减少事物日志物理文件的大小,而是清理出一些可重用空间以供新的事物日志写入进行复用。若想要对事物日志的物理文件大小进行收缩,需要进行专门的日志收缩操作。
三、事物日志管理
3.1 事物日志监控
1、查看当前数据库事物日志文件大小以及日志使用率等
SELECT a.name [文件名称] ,cast(a.[size]*1.0/128 as decimal(12,1)) AS [文件大小(MB)] ,
CAST( fileproperty(s.name,'SpaceUsed')/(8*16.0) AS DECIMAL(12,1)) AS [日志使用空间(MB)] ,
CAST( (fileproperty(s.name,'SpaceUsed')/(8*16.0))/(s.size/(8*16.0))*100.0 AS DECIMAL(12,1)) AS [日志空间使用率%] ,
CASE WHEN A.growth =0 THEN '文件大小固定,不会增长' ELSE '文件将自动增长' end [增长模式] ,CASE WHEN A.growth > 0 AND is_percent_growth = 0
THEN '增量为固定大小' WHEN A.growth > 0 AND is_percent_growth = 1 THEN '增量将用整数百分比表示' ELSE '文件大小固定,不会增长' END AS [增量模式] ,
CASE WHEN A.growth > 0 AND is_percent_growth = 0 THEN cast(cast(a.growth*1.0/128as decimal(12,0)) AS VARCHAR)+'MB'
WHEN A.growth > 0 AND is_percent_growth = 1 THEN cast(cast(a.growth AS decimal(12,0)) AS VARCHAR)+'%' ELSE '文件大小固定,不会增长' end AS [增长值(%或MB)] ,
a.physical_name AS [文件所在目录] ,a.type_desc AS [文件类型]
FROM sys.database_files a
INNER JOIN sys.sysfiles AS s ON a.[file_id]=s.fileid
LEFT JOIN sys.dm_db_file_space_usage b ON a.[file_id]=b.[file_id] ORDER BY a.[type]
2)监控事物日志状态
select name,log_reuse_wait,log_reuse_wait_desc from sys.databases;
| log_reuse_wait | log_reuse_wait_desc | 说明 |
|---|---|---|
| 0 | NOTHING | 当前有一个或多个可重复使用的虚拟日志文件 (VLF)。 |
| 1 | CHECKPOINT | 自上次日志截断之后,尚未生成检查点,或者日志头尚未跨一个虚拟日志 (VLF) 文件移动。 (所有恢复模式)这是日志截断延迟的常见原因。 |
| 2 | LOG_BACKUP | 在截断事务日志前,需要进行日志备份。 (仅限完整恢复模式或大容量日志恢复模式)完成下一个日志备份后,一些日志空间可能变为可重复使用。 |
| 3 | ACTIVE_BACKUP_OR_RESTORE | 数据备份或还原正在进行(所有恢复模式)。 |
| 4 | ACTIVE_TRANSACTION | 事务处于活动状态(所有恢复模式):长时间运行的事务将阻止所有恢复模式下的日志截断,包括简单恢复模式。在该模式下事务日志一般在每个自动检查点截断。这是日志截断延迟的常见原因。 |
| 5 | DATABASE_MIRRORING | 数据库镜像暂停,或者在高性能模式下,镜像数据库明显滞后于主体数据库。 (仅限完整恢复模式) |
| 6 | REPLICATION | 在事务复制过程中,与发布相关的事务仍未传递到分发数据库。 (仅限完整恢复模式) |
| 7 | DATABASE_SNAPSHOT_CREATION | 正在创建数据库快照。 (所有恢复模式)这是日志截断延迟的常见原因,通常也是主要原因。 |
| 8 | LOG_SCAN | 发生日志扫描。 (所有恢复模式)这是日志截断延迟的常见原因,通常也是主要原因。 |
| 9 | AVAILABILITY_REPLICA | 可用性组的辅助副本正将此数据库的事务日志记录应用到相应的辅助数据库。 (完整恢复模式) |
| 10 | - | 仅供内部使用 |
| 11 | - | 仅供内部使用 |
| 12 | - | 仅供内部使用 |
| 13 | OLDEST_PAGE | 如果将数据库配置为使用间接检查点,数据库中最早的页可能比检查点日志序列号 (LSN) 早。 在这种情况下,最早的页可以延迟日志截断。 (所有恢复模式) |
| 14 | OTHER_TRANSIENT | 当前未使用此值。 |
| 16 | XTP_CHECKPOINT | 需要执行内存中 OLTP 检查点。对于内存优化表,如果上次检查点后事务日志文件变得大于 1.5 GB(包括基于磁盘的表和内存优化表),则执行自动检查点 |
3.2 事物日志收缩
1、事物日志打满解决策略
生产环境中我们一般建议使用“FULL”恢复模式,但是在FULL恢复模式下需要我们周期性的对数据库以及事物日志进行备份,避免事物日志因无法被截断而导致事物日志文件不断增大。当事物日志文件打满的情况,我们可以有如下解决策略:
- 删除其他无效文件来释放磁盘空间以便事物日志文件可继续增长
- 备份事物日志文件,,如果该数据库从未进行过日志备份,则必须对事物日志文件进行两次备份后才可保证数据库引擎将日志截断到上次备份的点,以便可以对截断日志进行收缩(生产环境强烈建议备份与数据库数据/日志存储在不同的文件系统上)
- 将事物日志文件移动到其他磁盘空间充裕的文件系统下
- 可参考:https://docs.microsoft.com/zh-cn/sql/relational-databases/databases/move-database-files?view=sql-server-2017
- 在其他磁盘添加新的日志文件
- 可参考:https://docs.microsoft.com/zh-cn/sql/relational-databases/databases/add-data-or-log-files-to-a-database?view=sql-server-2017
- 若事物日志文件未设置自动增长,可手动增加事物日志文件大小或者手动设置自增长属性
- 长时间运行的事务会导致事务日志填满,可尝试完成或终止长时间运行的事物
- sys.dm_tran_database_transactions。 此动态管理视图返回有关数据库级事务的信息。 对于长时间运行的事务,最需要注意的列包括:第一条日志记录的时间 (database_transaction_begin_time)、事务的当前状态 (database_transaction_state)和事务日志中开始记录的 日志序列号 (LSN)(database_transaction_begin_lsn)。
- DBCC OPENTRAN。 通过此语句,您可以标识该事务所有者的用户 ID,因此可以隐性地跟踪该事务的源以得到更加有序的终止(将其提交而非回滚)。
- kill connection_id 结束进程,事物进行回滚
2、如何进行事物日志文件收缩?
在FULL/大容量日志恢复模式下,只有对事物日志进行备份后,才可对事物日志文件进行截断,截断后才可手动对事物日志文件进行一定的收缩处理;对于simple的恢复模式,数据库引擎会在每次checkpoint或者日志备份后自动对事物日志进行截断,一般情况下事物日志文件不会太大。另外对于日志收缩,事物日志文件不能小于一个VFL大小。
1)直接对事物日志文件进行收缩
USE AdventureWorks2012;
GO
DBCC SHRINKFILE (AdventureWorks2012_Log, 1);
GO
2)将数据库恢复模式设置为 SIMPLE 来截断该文件
USE AdventureWorks2012;
GO
-- Truncate the log by changing the database recovery model to SIMPLE.
ALTER DATABASE AdventureWorks2012
SET RECOVERY SIMPLE;
GO
-- Shrink the truncated log file to 1 MB.
DBCC SHRINKFILE (AdventureWorks2012_Log, 1);
GO
-- Reset the database recovery model.
ALTER DATABASE AdventureWorks2012
SET RECOVERY FULL;
GO