Slurm集群调度策略详解(1)-主调度
slurm集群调度策略详解(1)-主调度
HPC高性能集群
概述
高性能计算机一般由计算单元、互联通信、高速存储、监控诊断、基础架构、操作系统、编译器、运行环境、开发工具等多个软硬件子系统组成。从资源管理系统的角度,高性能计算机中的节点按逻辑功能可分为管理节点、登录节点、计算节点和存储节点;节点之间通过网络联接。如下图

登陆节点:和普通用户交互的主要节点。主要用来接受用户的 ssh 连接和文件传送,同时可以用来编译程序,修改代码和通过任务管理系统提交任务到计算节点。登陆节点还可细分为最外侧的负责 VPN 对接外网和入流量分流负载均衡的节点,以及普通的用来浏览文件编译程序提交任务的节点,和负责高带宽大文件传输的专用节点等。
管理节点:普通用户无法登陆,一般具有单独的管理网络,作业管理,资源分配等功能。还可细分为提供资源管理软件,提供账户管理,提供数据库后端,提供监控软件后端等不同功能的节点。分类越细,高可用就越好。每一种功能,还可以进一步包括主节点和备用从节点,从而防止单点故障。
计算机点:用来进行计算任务的节点,占据了集群中的绝大多数节点。还可细分为不同硬件特性的计算节点。比如大内存节点用来解决内存瓶颈的问题,现在最大内存可达 `3T`。又比如多 `GPU` 节点,用来进行机器学习等任务。还有具有本地固态硬盘的节点,用来满足需要高速 IO 的计算任务的需求等等。
存储节点:通过网络文件系统,共享给登陆节点和计算节点使用。通常与这些节点通过高速互联网络,比如 `InfiniBand` 相连接,带给用户调用本地文件的速度。还可细分为存储元数据的节点,存储文件内容的节点,备份数据的节点等。
调度系统架构
集群建好之后为了防止资源不受控制,则需要引入调度系统来进行统一的管理,常见的调度系统有目前市面上主流调度器有四大流派: LSF/SGE/Slurm/PBS。
调度系统是面向集群的操作系统其本质是解决资源请求的无限性和资源的有限性之间的矛盾;典型的调度系统架构如下
-
主控服务Server:主要负责资源和作业的监控和管理功能。
-
调度服务Scheduler:主要负责定义和执行调度策略,包括配额管理。
-
计算代理Agent:主要负责监控资源状态,以及作业的启停和监控。
-
存储服务Database:主要负责用户和作业信息的存储
-
访问接口:用户访问系统的统一入口。

常见调度策略
调度服务解决各种细节问题的实现方法称之为调度算法或调度策略。常见的各种调度算法:先到先服务、短作业优先、多因子优先级、抢占策略、高响应比、时间片轮转等等。
| 参数 | 描述 |
|---|---|
| 先来先服务 | 每次调度都是从排队作业队列中选择一个或多个最先进入该队列的作业 |
| 短作业优先 | 设定一个作业窗口,优先调度作业窗口内作业运行时间最短的作业 |
| 非抢占式高优先级调度 | 调度前会对所有排队作业按照优先级进行排序,调度时会按照优先级从高到底的顺序调度作业,只要作业启动,该作业便一直执行下去,直到执行完成 |
| 抢占式高优先级调度 | 这种方式同样在调度前会对所有排队作业按照优先级进行排序,调度时会按照优先级从高到底的顺序调度作业,但在作业执行期间,只要又出现了另一个优先级更高的作业,作业调度程序就立即取消或者挂起当前运行作业(原优先权最高的作业)的执行,重新将资源分配给新到的优先级最高的作业。 |
| 高响应比优先调度算法 | 在批处理系统中,短作业优先算法是一种比较好的算法,其主要的不足之处是长作业的运行得不到保证。可以通过引入动态优先级算法,作业随着等待时间增加而增加作业的优先级,从而保证了长作业在等待一定时间后能够得到调度 |
| 时间片轮转法 | 系统将所有的就绪进程按先来先服务的原则排成一个队列,每个作业都能够执行,但是在一个时间片内只能执行一个或几个作业,时间片一到,便切换到下一个作业运行,这样就可以保证在给定的时间内所有作业能运行。 |
| 多级反馈队列调度算法 | 是目前操作系统调度算法中被公认的一种较好的调度算法。它可以满足各种类型进程的需要,既能使高优先级的作业得到响应又能使短作业(进程)迅速完成。 |
在集群作业和在计算资源的调度中除了以上的先来先服务,高优先级,抢占等还有公平调度、资源预留、回填调度等
| 参数 | 描述 |
|---|---|
| 公平调度 | 每个用户设定不同的权重,一个作业的优先级与用户数量、用户权重以及该用户运行的作业数决定,从用户的角度考虑的公平原则 |
| 资源预留 | 在集群使用过程中可以单独拿出一批资源根据需要设置预留,预留时要设置预留的时间段,资源数量,允许提交的用户以及预留类型,预留的资源只能被指定的指定用户使用,且预留资源不再参与该分区其他用户作业的调度。 |
| 回填调度 | 由于资源的有限性可能会给高优先级作业在未来一段时间预留资源,这时空闲资源预留会造成资源浪费,而回填调度在不延迟任何较高优先级作业运行的前提下,会尝试低优先级的作业能否回填掉空闲资源上运行,提交资源利用率。 |
slurm集群调度系统
Slurm是一个开源,高度可扩展的集群管理工具和作业调度系统,可以简单理解为一个多机的资源和任务管理系统。主要以下提供三种关键功能:
**资源分配:**在特定时间段内为用户分配计算资源,进行独占或非独占访问权限,以便他们可以执行作业。简单的说就是为用户作业提供对计算资源的授权和分配。
**作业管理:**它提供了对节点上的作业节进行启动、执行和监控作业的框架。
**作业调度:**通过管理待处理作业的队列来仲裁资源的争用。例如根据优先级或不同当调度策略调整资源的分配顺序。
Slurm调度系统中针对作业的调度主要有三种,主调度,回填调度,GANG调度,这篇文章主要针对主调度进行解析
主调度
Slurm旨在对作业提交或完成以及配置更改等事件执行快速而简单的调度尝试(非全量调度)。在这些事件触发的调度事件期间,将考虑default_queue_depth(默认值为100)数量的作业。在由sched_interval定义的较低频率间隔中,将考虑对所有作业进行调度。在这两种情况下,一旦一个分区中的任何作业或作业数组任务处于排队状态,该分区中的任何其他作业都不会被调度。一个更全面的调度尝试通常由回填调度插件完成。
主调度参数
SchedulerType配置参数指定要使用的调度器插件。选项有sched/backfill(执行回填调度)和sched/builtin(试图在每个分区/队列中严格按照优先级顺序调度作业)。还有一个SchedulerParameters配置参数,可以指定范围很广的参数,如下表所述。
| 参数 | 描述 |
|---|---|
| sched_interval | 控制两次全量调度之间的间隔时间,默认值是60秒。设置为-1将禁用主调度循环。 |
| max_sched_time | 主调度循环在退出之前最多执行多长时间(以秒为单位)。如果配置了一个值,请注意所有其他Slurm操作将在此时间段内被推迟。确保该值低于MessageTimeout的一半才会有效。主调度时间不宜过长,2-3秒合适 |
| default_queue_depth | 调度作业队列的深度,当一个正在运行的作业完成或发生其他例行操作时,尝试调度的默认作业数(即队列深度),此参数在slurm19版本和slurm20版本的使用有所区别,默认值为100个任务。由于这种情况经常发生,所以相对较小的数目通常是最好的。 |
| partition_job_depth | 在Slurm的主调度逻辑中,从每个分区/队列尝试调度的默认作业数(即队列深度),同上如果太小导致后面其他用户作业调度不上,设置太大导致只调度一个分区其他分区饿死,此参数的处理代码slurm19版本和slurm20版本也有所区别,19版本当分区调度作业数量到达限制之后不会改变作业状态,但是20版本会改变作业状态 |
| sched_min_interval | 主调度循环执行和测试排队作业的频率,单位为微秒。调度程序在每次可能启动作业的事件(例如作业提交、作业终止等)发生时都以有限的方式运行。如果这些事件以很高的频率发生,调度器可以非常频繁地运行,如果不使用此选项,则会消耗大量资源。此选项指定从一个调度周期结束到下一个调度周期开始之间的最短时间。值为0将禁用调度逻辑间隔的节流。缺省值是2微秒。 |
| assoc_limit_stop | 如果设置,作业由于关联限制而无法启动,那么将作业所在分区加入分区黑名单,不要尝试在该分区中启动任何低优先级的作业。 |
| defer | 如果设置则不要尝试在作业提交或有作业运行完成时单独调度作业。对于高吞吐量计算非常有用。 |
| bf_min_age_reserve | 回填调度预留时间参数,当高优先级作业因空闲资源未成功运行,且排队的时间不满足bf_min_age_reserve回填预留的条件,则主调度不会将该作业所在分区加入分区黑名单 |
| bf_min_prio_reserve | 回填调度预留优先级参数,当高优先级作业因空闲资源未成功运行,同时作业优先级不满足bf_min_prio_reserve回填预留的条件,则主调度不会将该作业所在分区加入分区黑名单 |
| batch_sched_delay | 批处理作业的调度可以延迟多长时间,单位为秒。这在高吞吐量的环境中非常有用,在这种环境中,批处理作业以非常高的速率提交(即使用sbatch命令),并且希望减少在提交时调度每个作业的开销。缺省值为3秒。 |
| sched_max_job_start | 主调度逻辑在任何一次执行中启动的作业的最大数量。默认值为0,没有限制。 |
分区黑名单:由于主调度会优先保证高优先级作业的运行,所以当一个高优先级作业因为空闲资源不足而未能运行,调度系统会将作业所在分区拉入分区黑名单,后续该分区低优先级的作业不能再参与调度,但是这些作业会累加到调度默认队列深度和分区作业深度
主调度调度流程
主调度调度流程分为两种sched/builtin和sched/backfill,
sched/builtin:按顺序依次调度,这种调度类型按照PriorityType的设置分为两种,当设置priority/basic时是按照作业提交时间的顺序也就是FIFO调度作业,当设置priority/multifactor时它按优先级顺序调度作业,而作业最终优先级会考虑多种因素,其计算方式如下。
//When not FIFO scheduling, jobs are prioritized in the following order:
//1. Jobs that can preempt
//2. Jobs with an advanced reservation
//3. Partition PriorityTier
//4. Job priority
//5. Job submit time
//6. Job ID
job_ptr->prio_factors->priority_age *= (double)weight_age;
job_ptr->prio_factors->priority_assoc *= (double)weight_assoc;
job_ptr->prio_factors->priority_fs *= (double)weight_fs;
job_ptr->prio_factors->priority_js *= (double)weight_js;
job_ptr->prio_factors->priority_part *= (double)weight_part;
job_ptr->prio_factors->priority_qos *= (double)weight_qos;
if (weight_tres && job_ptr->prio_factors->priority_tres) {
double *tres_factors = NULL;
tres_factors = job_ptr->prio_factors->priority_tres;
tmp_tres = _get_tres_prio_weighted(tres_factors);
}
priority = job_ptr->prio_factors->priority_age
+ job_ptr->prio_factors->priority_assoc
+ job_ptr->prio_factors->priority_fs
+ job_ptr->prio_factors->priority_js
+ job_ptr->prio_factors->priority_part
+ job_ptr->prio_factors->priority_qos
+ tmp_tres
+ (double)(((int64_t)job_ptr->prio_factors->priority_site)
- NICE_OFFSET)
- (double)(((int64_t)job_ptr->prio_factors->nice)
- NICE_OFFSET);
如果分区中的任何作业不能被调度,则该分区中的任何低优先级作业都不会被调度。由于分区限制(例如,时间限制)或关闭/耗尽节点而不能运行的作业是一个例外。在这种情况下,低优先级的作业可以被启动,而不会影响高优先级的作业。
sched/backfill:用于回填调度模块,以扩充默认的主调度。回填调度将启动低优先级作业,如果这样做不延迟任何高优先级作业的预期启动时间。回填调度的有效性取决于用户设定作业时限,否则所有作业的时限相同,无法回填。为了提高调度效率一般集群都会配置sched/backfill
作业筛选流程
作业调度之前,调度系统会对所与主调度相关的参数进行解析,且将所有排队的作业按照优先级从高到低的顺序进行排序并构建作业队列,调度时作业会按照优先级从高到低的顺序出栈,出栈后的作业会经过调度参数和作业本生的筛选,最终进入调度作业节点选择启动环节如下图所示。
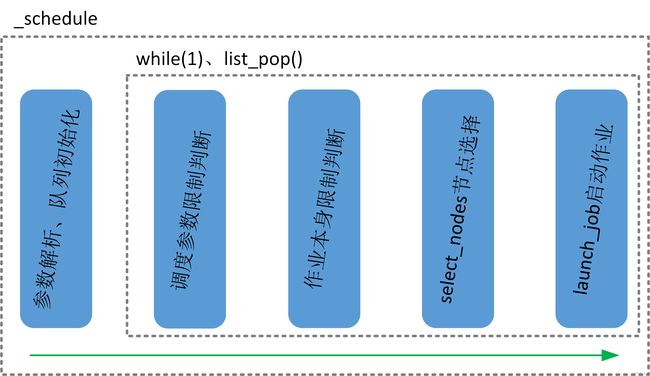
在调度参数限制相关的判断中,会对调度时间、本次调度启动的作业数量、本次调度的作业数量、每个分区调度的作业数量、调度系统最大rpc数量、hetjob作业等进行判断,其中分区到达设定数值之后会修改作业排队状态直接跳过本作业的调度过程,调度时间、本次调度启动的作业数量、调度系统最大rpc数量和本次调度的作业数量到达限制之后会直接退出本次调度。
除了调度参数限制相关的判断还有作业本身限制的判断,会对作业是否在其他分区运行,是否为hetjob作业(主调度不负责hetjob作业的调度),作业所在分区是否已经加入分区黑名单,作业的QOS是否满足,运行时间是否满足等,如果作业未通过筛选会直接跳过该作业的调度,继续调度下一个作业。
经过以上筛选,作业符合现在启动的条件,作业会进入select_nodes函数为作业分配节点资源,如果分配成功则调用launch_job启动作业,如果空闲资源不能满足作业需求则跳过该作业调度下一个作业。
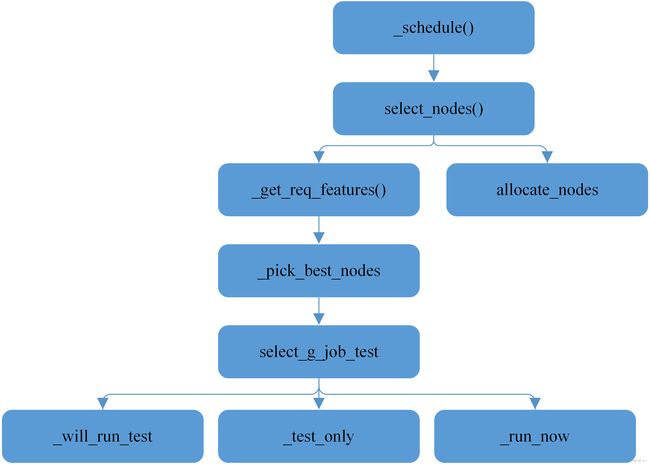
select_nodes节点选择流程
select_nodes函数主要负责将当前空闲资源与作业申请资源进行配,如果匹配成功则能满足作业运行要求,具体流程如下图
流程解析
-
构建具有必要配置的节点表(node_set_ptr:包含slurm_node.conf中所有节点);每个表格条目包括它们的权重、节点列表、特征等;
-
调用_pick_best_nodes,从满足作业规格的所有节点的权重顺序列表中,选择“最佳”以供使用;
-
如果指定了必需的节点列表,则确定隐式必需的处理器和节点数;
-
确定表示了多少不相交的必需“feature”(例如“FS1 | FS2 | FS3”);
-
对于每个feature:查找匹配的节点表条目,识别可用的节点(空闲或共享),并将它们添加到bitmap中;
-
select_g_job_test(),根据拓扑和/或工作负载选择其中的“最佳”; 最佳”定义为连续节点的最小数量,或者如果共享资源,则使用类似大小的作业共享资源。
-
如果现在无法满足请求,请对存在于任何状态(DOWN DRAINED ALLOCATED)的节点列表执行select_g_job_test(),以确定是否能够满足请求;
-
-
调用allocate_nodes,执行实际分配节点;
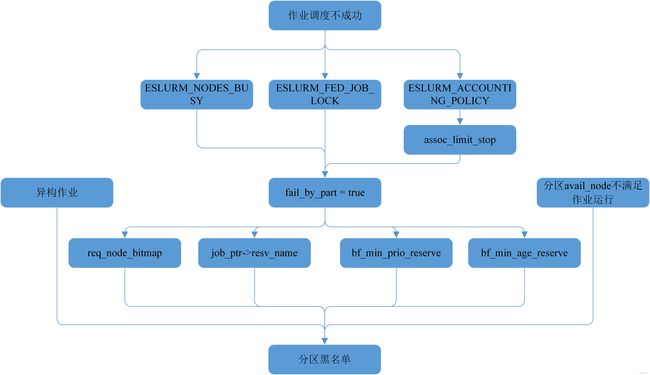
分区黑名单流程
主调度为了保证高优先级作业优先运行引入了分区黑名单的机制,其主干流程如下图
流程解析
-
主调度不能运行异构作业,如果是异构作业直接加入分区黑名单
-
分区avail节点不满足作业运行条件直接加入
-
作业调度不成功
- 空闲资源不足将fail_by_part设置为true
- 获取作业锁失败将fail_by_part设置为true
- 用户配额限制并且设置了assoc_limit_stop参数fail_by_part设置为true
- 如果fail_by_part设置为true之后有几种方式可以将fail_by_part设置为false
-w制定资源则将指定的资源从avail排除将fail_by_part设置为false
- 如果是预约的作业将此预约加入分区黑名单将fail_by_part设置为false
- 未满足bf_min_age_reserve时间预留将fail_by_part设置为false
- 为满足bf_min_prio_reserve优先级预留将fail_by_part设置为false
最终如果fail_by_part为true则将作业所在分区加入分区黑名单,如果为false则不加入
主调度函数调用关系
函数调用关系
主调度是在slurmctld服务启动时单独开一个线程负责调度作业,函数调用关系如表,schedule函数入口有很多,不同入口调用被分为全量调度和非全量调度
main // controller.c
_slurmctld_background //主大循环,做很多事情
schedule //还处理延迟调度操作
_schedule // 调度核心部位
select_nodes // 主要是选择合适节点
srun_allocate // 处理srun提交的作业
OR
launch_job // 处理sbatch提交的作业
全量调度
全量调度的入口是通过sched_interval参数进行控制,一般设置较大,但是调度是最全面的,代码如下,如果当前时间和上一次全量调度时间间隔大于sched_interval时,会将full_queue设置为true,然后调用schedule函数,full_queue为true是全量调度,在调度过程中不会考虑default_queue_depth的值,也不会因为default_queue_depth受限而退出。
_slurmctld_background()
{
…
while (1) {
bool call_schedule = false, full_queue = false;
…
if (difftime(now, last_full_sched_time) >= sched_interval) {
call_schedule = true;
full_queue = true;
job_sched_cnt = 0;
last_full_sched_time = now;
}
if (call_schedule) {
now = time(NULL);
last_sched_time = now;
bb_g_load_state(false); /* May alter job nice/prio */
if (schedule(full_queue))
last_checkpoint_time = 0; /* force state save */
set_job_elig_time();
}
}
}
非全量调度
- 没有设置defer时,当一个作业完成会调用非全量调度代码如下,此时传入的变量为0代表非全量调度,调度时会考虑default_queue_depth的参数,一般default_queue_depth参数设置的比较小,非全量调度会简单调度几个作业之后就会退出
_slurm_rpc_epilog_complete()
{
…
/* Functions below provide their own locking */
if (!(msg->flags & CTLD_QUEUE_PROCESSING) && run_scheduler) {
/*
* In defer mode, avoid triggering the scheduler logic
* for every epilog complete message.
* As one epilog message is sent from every node of each
* job at termination, the number of simultaneous schedule
* calls can be very high for large machine or large number
* of managed jobs.
*/
if (!LOTS_OF_AGENTS && !defer_sched)
(void) schedule(0); /* Has own locking */
schedule_node_save(); /* Has own locking */
schedule_job_save(); /* Has own locking */
}
}
- 当有作业需要调度时,也会触发非全量调度,这个的激活方式有很多,下面事件都会使job_sched_cnt变量增加,当job_sched_cnt有值且距上次调度的时间间隔超过了batch_sched_delay则会触发一次非全量调度,代码如下
_slurmctld_background()
{
…
while (1) {
bool call_schedule = false, full_queue = false;
…
if (difftime(now, last_full_sched_time) >= sched_interval) {
…
}else {
if (job_sched_cnt &&
(difftime(now, last_sched_time) >=
batch_sched_delay)) {
call_schedule = true;
job_sched_cnt = 0;
}
}
if (call_schedule) {
now = time(NULL);
last_sched_time = now;
bb_g_load_state(false); /* May alter job nice/prio */
if (schedule(full_queue))
last_checkpoint_time = 0; /* force state save */
set_job_elig_time();
}
}
}
触发job_sched_cnt变量增加的事件
1. _start_stage_in
2. _reset_buf_state
3. _reconfigure_slurm //更新配置
4. _slurmctld_background //主循环
5. _fed_mgr_job_allocate_sib
6. _has_deadline
7. _slurm_rpc_allocate_resources //分配资源
8. _slurm_rpc_node_registration //节点注册
9. _slurm_rpc_reconfigure_controller //更新配置
10. _slurm_rpc_submit_batch_job //sbatch提交作业
11. _slurm_rpc_update_job //update更新作业信息
12. _slurm_rpc_update_node //更新节点状态或信息
13. _slurm_rpc_update_partition //更新分区配置
14. _slurm_rpc_resv_create //创建预留
15. _slurm_rpc_resv_update //更新预留
16. _slurm_rpc_resv_delete //删除预留
17. _slurm_rpc_suspend //挂起作业
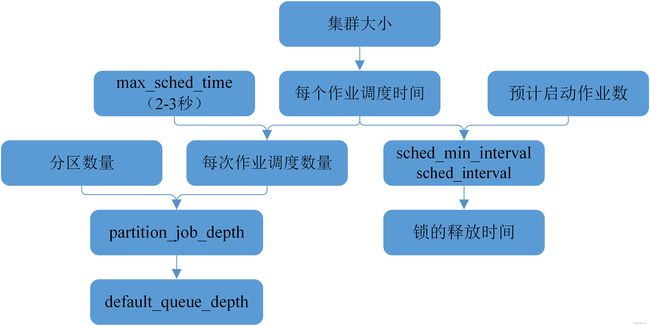
主调度参数优化方案
主调度各个配置参数生效位置

各个参数在调度中不同的位置发挥不同的作业,但是相互之间有着间接的联系,在不场景下可以通过不同的参数对调度进行限制,参数优化方案如下
-
根据集群规模用户数量分区复杂度能得到每个作业调度时间
-
最大调度时间不能设置太长也不能设置太短,建议设为3秒,3秒是有点长但是平时作业量少调度一般不是因为超时退出,所以主调度那锁的时间会小于3秒
-
一个作业调度时间知道了,最大调度时间知道了就可以求出一次调度能够调度成功的作业数
-
结合分区数量控制分区深度,数值可以根据集群的调度情况来定,比如一个作业的完整调度时间为0.06秒max_sched_time设置为2(一次调度大约30个作业),limit受限的作业每个也需要0.015秒(一次调度大约130个),而分区黑名单或者分区深度达到后直接改状态不怎么耗时,所以分区深度设置太大会导致因为调度超时退出参数不起作用,设置太小又会导致效率太低,可能会因为分区被拉入分区黑名单将分区深度顺序打满,需要保证当作业量大时会因为分区深度受限而调度其他作业,不能因为设置太大导致其他分区饿死
-
根据分区数量分区深度合理设置非全量调度深度
-
根据每个作业调度时间以及预期作业启动数量能够对调度最小时间间隔和时间间隔进行设定,调度的频率和数量不是关键,关键是调度的质量和启动的作业数,调度间隔时间可以适当增大,根据预期启动作业数计算出做小间隔时间,比如一个小时预期启动2万个作业,每秒启动15个,每次调度2秒(3600/(sched_min_interval+2))*30=2000;sched_min_interval=3.4
总结
-
主调度是slurm调度系统中的最主要调度策略,要保证集群响的应速度、吞吐量、调度速率和资源的高效利用。
-
主调度还要保证高优先级的作业是优先运行的,所以作业队列是按照优先级进行调度。
-
众多的调度参数可以对主调度的流程加以限制,各个参数之间存在间接关联性,合理的设计调度参数会对集群的调度效率和集群资源的高效利用有很大的帮助
Slurm调度系统是当前调度系统中少有的开源且成熟的调度系统,但是仍然有少量bug的存在,且不能完全覆盖所有的用户场景,如果您有问题请加入社区讨论。社区以Slurm为切入口讨论HPC相关问题,致力于守卫中国HPC集群稳定运行,推广国产调度器助力中国HPC进步。联系方式请见评论区。